차등 개인정보 보호를 통한 딥러닝 학습
본 논문은 차등 개인정보 보호(Differential Privacy) 기법을 딥러닝 훈련 과정에 직접 적용하는 새로운 알고리즘을 제시한다. 기존 방법보다 더 엄밀한 프라이버시 손실 추적인 ‘모멘트 어카운터’를 도입해, 비공개 데이터에 대한 노출을 최소화하면서도 MNIST와 CIFAR‑10에서 경쟁력 있는 정확도를 유지한다.
저자: Martin Abadi, Andy Chu, Ian Goodfellow
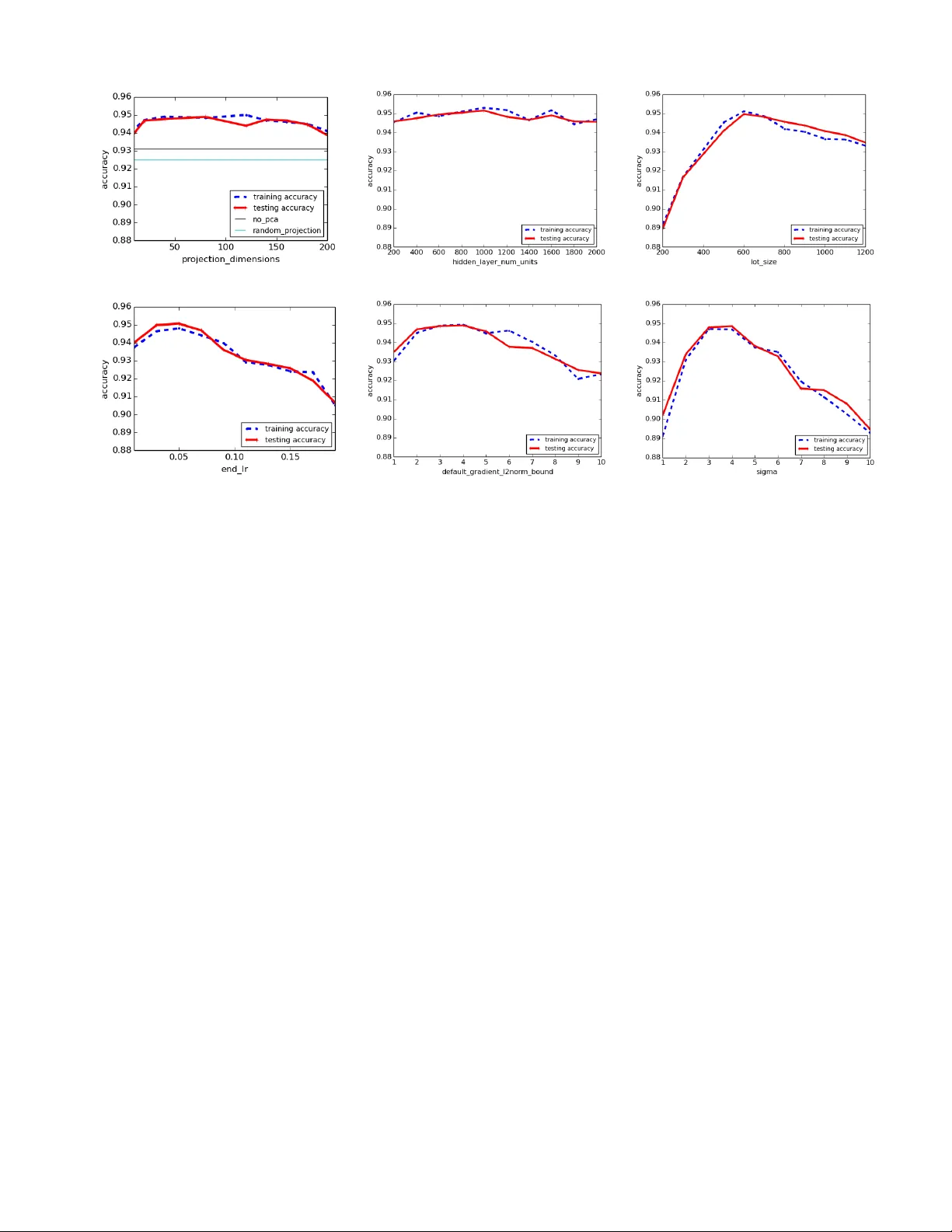
본 논문은 대규모 데이터셋을 활용한 딥러닝 모델 학습 과정에서 발생할 수 있는 개인정보 유출 위험을 차등 개인정보 보호(Differential Privacy, DP) 프레임워크 내에서 해결하고자 한다. 기존 연구들은 주로 모델 파라미터 자체에 노이즈를 추가하거나, 훈련 후에 프라이버시를 보장하는 방법을 제시했지만, 이러한 접근법은 모델 성능 저하가 크거나 프라이버시 손실을 과도하게 보수적으로 추정하는 한계가 있었다. 저자들은 이러한 문제점을 극복하기 위해 **차등 프라이버시 SGD(Private Stochastic Gradient Descent)** 알고리즘을 설계하고, **Moments Accountant**라는 새로운 프라이버시 손실 추적 기법을 도입하였다.
알고리즘은 다음과 같은 흐름을 따른다. 먼저 전체 데이터셋에서 샘플링 비율 q=L/N에 따라 **Lot**을 구성한다. 각 Lot은 여러 개의 작은 배치(batch)로 나뉘어 메모리 사용량을 최소화한다. 각 배치에 대해 손실 함수 L(θ, x)의 그래디언트를 계산하고, 개별 그래디언트의 L2 노름을 사전 정의된 임계값 C로 클리핑한다. 클리핑된 그래디언트를 Lot 내에서 평균한 뒤, 평균값에 σ·C 표준편차를 갖는 가우시안 노이즈를 추가한다. 이렇게 얻어진 노이즈가 포함된 평균 그래디언트를 사용해 학습 파라미터 θ를 업데이트한다.
핵심 이론적 기여는 **Moments Accountant**이다. 기존의 강한 합성 정리(strong composition theorem)는 각 단계의 (ε,δ) 손실을 단순히 합산해 전체 손실을 추정했으며, 이는 단계 수 T가 커질수록 ε가 급격히 증가하는 비효율적인 결과를 초래했다. Moments Accountant는 각 단계에서 발생하는 프라이버시 손실의 고계(moment)를 추적함으로써, 전체 훈련 과정에 대한 (ε,δ) 보장을 더 타이트하게 계산한다. 구체적으로, 샘플링 비율 q와 총 단계 T에 대해 ε = O(q·√T·log(1/δ))를 만족하도록 σ를 설정하면, 전체 훈련이 (ε,δ)-DP를 보장한다. 이는 동일한 σ를 사용했을 때 강한 합성 정리 대비 ε를 약 10배 이상 감소시키는 효과를 제공한다.
실험에서는 TensorFlow 기반 구현을 통해 두 가지 표준 이미지 분류 벤치마크인 **MNIST**와 **CIFAR‑10**에 적용하였다. 실험 설정은 ε≈1, δ=10⁻⁵의 프라이버시 예산을 목표로 하였으며, MNIST에서는 99%에 가까운 정확도, CIFAR‑10에서는 약 84%의 정확도를 달성했다. 이는 기존 차등 프라이버시 딥러닝 방법이 동일한 프라이버시 예산 하에서 보였던 90% 이하의 정확도와 비교해 현저히 높은 성능이다. 또한, Moments Accountant와 강한 합성 정리를 각각 적용했을 때의 ε 차이를 그래프로 제시해, 이론적 이득이 실제 훈련에서도 실현됨을 입증하였다.
논문은 또한 프라이버시 보호가 필요한 모바일·엣지 디바이스 시나리오를 강조한다. 모델 파라미터가 공격자에게 노출될 수 있는 상황에서도, 차등 프라이버시 SGD와 Moments Accountant를 적용하면 개별 데이터 레코드가 모델에 미치는 영향을 수학적으로 제한할 수 있다. 이는 중앙 서버 없이 로컬에서 모델을 학습·배포하는 경우에도 개인정보 보호를 보장하는 실용적인 솔루션으로 평가된다.
결론적으로, 저자들은 (1) 그래디언트 클리핑과 가우시안 노이즈를 결합한 차등 프라이버시 SGD 알고리즘, (2) 프라이버시 손실을 고계 기반으로 정확히 추적하는 Moments Accountant, (3) 레이어별·시간별 파라미터 조정과 Lot 기반 메모리 효율화 기법을 통해, 비공개 데이터에 대한 강력한 프라이버시 보장을 유지하면서도 딥러닝 모델의 성능 저하를 최소화하는 실용적인 프레임워크를 제시하였다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기