Deep Learning with Differential Privacy
Machine learning techniques based on neural networks are achieving remarkable results in a wide variety of domains. Often, the training of models requires large, representative datasets, which may be crowdsourced and contain sensitive information. Th…
Authors: Martin Abadi, Andy Chu, Ian Goodfellow
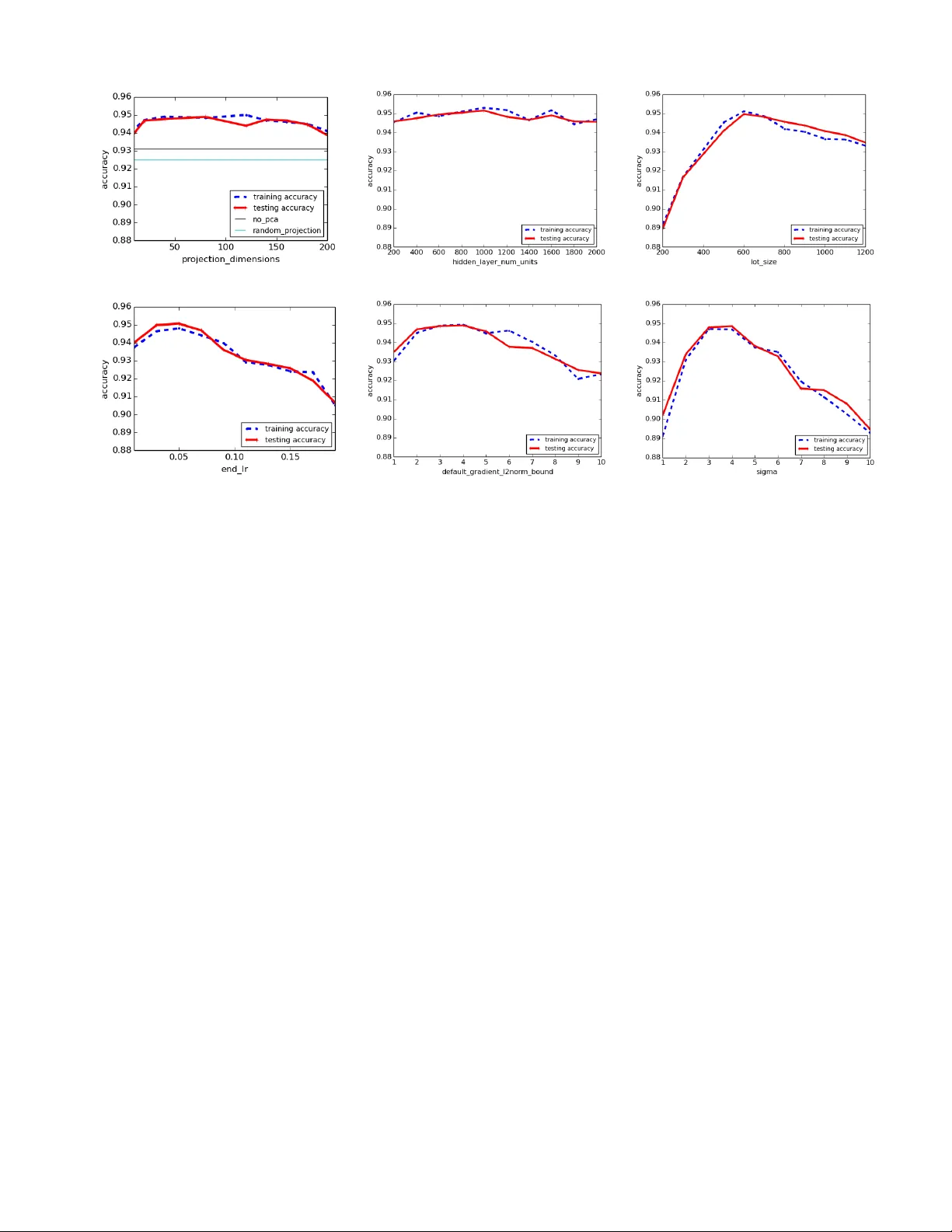
A preliminary vers ion of this paper app ears in the proceedings of the 23rd ACM Confer enc e on Computer and Communication s Se curity (CCS 2016) . This is a full version. Deep Learning with Differential Priv acy Octob er 25, 2016 Mar tín Abadi ∗ Andy Chu ∗ Ian Goodf ellow † H. Brendan McMahan ∗ Ilya Mironov ∗ K unal T alwar ∗ Li Zhang ∗ ABSTRA CT Mac hine learning techniques based on neural net works are ac hieving remark able results in a wide v ariet y of domains. Often, the training of models requires large, representativ e datasets, which may b e cro wdsourced and con tain sensitive information. The models should no t expose priv ate in forma- tion in these datasets. Addressing this goal, we dev elop new algorithmic techniques for learning and a refined analysis of priv acy costs within the framework of differential priv acy . Our implemen tation and exp erimen ts demonstrate that we can train deep neural netw orks with non-conv ex ob jectives, under a modest priv acy budget, and a t a manageable cost in soft w are complexity , training efficiency , and model quality . 1. INTR ODUCTION Recen t progress in neural netw orks has led to impressiv e successes in a wide range of applications, including image classification, language represen tation, mo v e selection for Go, and many more (e.g., [54, 28, 56, 38, 51]). These ad- v ances are enabled, in part, by the av ailability of large and represen tative datasets for training neural netw orks. These datasets are often cro wdsourced, and may conta in sensitive information. Their use requires tec hniques that meet the demands of the applications while offering principled and rigorous priv acy guaran tees. In this paper, we com bine state-of-the-art machine learn- ing metho ds with adv anced priv acy-preserving mechanisms, training neural net wo rks within a mo dest ( “single-digit” ) pri- v acy budget. W e treat mo dels with non-con v ex ob jectives, sev eral lay ers, and tens of thousands to millions of param- eters. (In con trast, previous wo rk obtains strong results on con vex mo dels with smaller n umbers of parameters, or treats complex neural net works but with a large priv acy loss.) F or this purp ose, we develop new algorithmic techniques, a re- fined analysis of priv acy costs within the framework of dif- feren tial priv acy , and careful implemen tation strategies: ∗ Google. † OpenAI. W ork done while at Google. Permission to make digital or hard copies of part or all of this work for personal or classroom use is granted without fee provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. Copyrights for third-party components of this work must be honored. For all other uses, contact the o wner /author(s). CCS’16 October 24-28, 2016, V ienna, Austria c 2016 Copyright held by the o wner/author(s). A CM ISBN 978-1-4503-4139-4/16/10. DOI: http://dx .doi.org/10.1145/2976749.2978318 1. W e demonstrate that, b y tra c king detailed information (higher moments) of the priv acy loss, we can obtain m uc h tigh ter estimates on the ov erall priv acy loss, both asymptotically and empirically . 2. W e improv e the computational efficiency of differen- tially priv ate training by introducing new techniques. These techn iques include efficient algorithms for com- puting gradien ts for individual training examples, sub- dividing tasks into smaller batches to reduce memory footprint, and applying differentially priv ate principal pro jection at the input la y er. 3. W e build on the machine learning framework T ensor- Flo w [3] for training models with differen tial priv acy . W e ev aluate our approac h on tw o standard image clas- sification tasks, MNIST and CIF AR-10. W e chose these t wo tasks because they are based on public data- sets and ha v e a long record of serving as b enc hmarks in machine learning. Our exp erience indicates that priv acy protection for deep neural net works can be ac hiev ed at a mo dest cost in softw are complexity , train- ing efficiency , and mo del quality . Mac hine learning systems often comprise elements that con tribute to protecting their training data. In particular, regularization techniques, whic h aim to av oid ov erfitting to the examples used for training, ma y hide details of those examples. On the other hand, explaining the in ternal rep- resen tations in deep neural net works is notoriously difficult, and their large capacity entails that these representations ma y potentially enco de fine details of at least some of the training data. In some cases, a determined adversary may be able to extract parts of the training data. F or example, F redrikson et al. demonstrated a mo del-in version attack that reco v ers images from a facial recognition system [24]. While the mo del-in version attack requires only “blac k- box” access to a trained mo del (that is, int eraction with the model via inputs and outputs), we consider adv ersaries with additional capabilities, m uch lik e Shokri and Shmatiko v [50]. Our approach offers protection against a strong adversary with full knowledge of the training mec hanism and access to the mo del’s parameters. This protection is attractive, in particular, for applications of machine learning on mobile phones, tablets, and ot her devices. Storing models on- device enables p o wer-efficien t, low-la tency inference, and may con- tribute to priv acy since inference does not require comm u- nicating user data to a cen tral server; on the other hand, w e must assume that the mo del parameters themselves may be exposed to hostile inspection. F urthermore, when we are concerned with preserving the priv acy of one record in the training data, w e allow for the possibilit y that the adversary con trols some or even all of the rest of the training data. In practice, this possibility cannot alwa ys b e excluded, for ex- ample when the data is cro wdsourced. The next section reviews background on deep lea rning and on differen tial priv acy . Sect ions 3 and 4 explain our ap- proac h and implemen tation. Section 5 describes our exper- imen tal results. Section 6 discusses related w ork, and Sec- tion 7 concludes. Deferred pro ofs appear in the Appendix. 2. B A CKGR OUND In this section we briefly rec all the definition of differen tial priv acy , in tro duce the Gaussian mechanism and comp osition theorems, and o verview basic principles of deep learning. 2.1 Differential Privacy Differen tial priv acy [19, 16, 20] constitutes a strong stan- dard for priv acy guarantees for algorithms on aggregate data- bases. It is defined in terms of the application-specific con- cept of adjacen t databases. In our exp erimen ts, for instance, eac h training dataset is a set of image-lab el pairs; we say that tw o of these sets are adjacent if they differ in a single en try , that is, if one image-label pair is presen t in one set and absen t in the other. Definition 1. A randomized mechanism M : D → R with domain D and range R satisfies ( ε, δ )-differentia l priv acy if for any tw o adjacen t inputs d, d 0 ∈ D and for an y subset of outputs S ⊆ R it holds that Pr[ M ( d ) ∈ S ] ≤ e ε Pr[ M ( d 0 ) ∈ S ] + δ. The original definition of ε -differential priv acy do es not in- clude the additive term δ . W e use the v ariant in tro duced by Dw ork et al. [17], whic h allows for the possibility that plain ε -differen tial priv acy is broken with probability δ (which is preferably smaller than 1 / | d | ). Differen tial priv acy has several prop erties that make it particularly useful in applications such as ours: comp osabil- it y , group priv acy , and robustness to auxiliary information. Composability enables mo dular design of mec hanisms: if all the comp onen ts of a mechanism are differentially priv ate, then so is their comp osition. Group priv acy implies graceful degradation of priv acy guaran tees if datasets contain cor- related inputs, such as the ones con tributed by the same individual. Robustness to auxiliary information means that priv acy guaran tees are not affected by any side information a v ailable to the adv ersary . A common paradigm for appro ximating a deterministic real-v alued function f : D → R with a differentially priv ate mec hanism is via additiv e noise calibrated to f ’s sensitivity S f , which is defined as the maxim um of the absolute distance | f ( d ) − f ( d 0 ) | where d and d 0 are adjacent inputs. (The restriction to a real-v alued function is in tended to simplify this review, but is not essential.) F or instance, the Gaussian noise mec hanism is defined by M ( d ) ∆ = f ( d ) + N (0 , S 2 f · σ 2 ) , where N (0 , S 2 f · σ 2 ) is the normal (Gaussian) distribution with mean 0 and standard deviation S f σ . A single applica- tion of the Gaussian mec hanism to function f of sensitivity S f satisfies ( ε, δ )-differen tial priv acy if δ ≥ 4 5 exp( − ( σ ε ) 2 / 2) and ε < 1 [20, Theorem 3.22]. Note that this analysis of the mechanism can b e applied p ost ho c , and, in particular, that there are infinitely many ( ε, δ ) pairs that satisfy this condition. Differen tial priv acy for rep eated applications of additive- noise mechan isms follows from the basic comp osition theo- rem [17, 18], or from adv anced composition theorems and their refinemen ts [22, 32, 21, 10]. The task of keeping trac k of the accum ulated priv acy loss in the course of execution of a comp osite mec hanism, and enforcing the applicable pri- v acy p olicy , can b e p erformed by the privacy ac c ountant , in troduced by McSherry [40]. The basic blueprin t for designing a differentiall y priv ate additiv e-noise mechanism that implemen ts a giv en function- alit y consists of the follo wing steps: appro ximating the func- tionalit y b y a sequen tial composition of b ounded-sensitivit y functions; choosing parameters of additive noise; and per- forming priv acy analysis of the resulting mechanism. W e follo w this approac h in Section 3. 2.2 Deep Learning Deep neural net works, which are remark ably effective for man y machine learning tasks, define parameterized func- tions from inputs to outputs as comp ositions of many lay ers of basic building blo c ks, such as affine transformations and simple nonlinear functions. Commonly used examples of the latter are sigmoids and rectified linear units (ReLUs). By v arying para meters of these blocks, we can “train” suc h a pa- rameterized function with the goal of fitting any given finite set of input/output examples. More precisely , we define a loss function L that represents the p enalt y for mismatching the training data. The loss L ( θ ) on parameters θ is the av erage of the loss ov er the training examples { x 1 , . . . , x N } , so L ( θ ) = 1 N P i L ( θ , x i ). T raining consists in finding θ that yields an acceptably small loss, hopefully the smallest loss (though in practice we seldom expect to reac h an exact global minimum). F or complex netw orks, the loss function L is usually non- con vex and difficult to minimize. In practice, the minimiza- tion is often done b y the mini-batch stochastic gradient de- scen t (SGD) algorithm. In this algorithm, at each step, one forms a batch B of random examples and computes g B = 1 / | B | P x ∈ B ∇ θ L ( θ , x ) as an estimation to the gra- dien t ∇ θ L ( θ ). Then θ is up dated follo wing the gradien t direction − g B to w ards a local minimum. Sev eral systems hav e b een built to support the definition of neural netw orks, to enable efficient training, and then to perform efficient inference (execution for fixed parame- ters) [29, 12, 3]. W e base our work on T ensorFlow, an op en- source dataflow engine released by Go ogle [3]. T ensorFlo w allo ws the programmer to define large computation graphs from basic operators, and to d istribute their execution across a heterogeneous distributed system. T ensorFlow automates the creation of the computation graphs for gradients; it also mak es it easy to batc h computation. 3. OUR APPR O A CH This section describ es the main components of our ap- proac h tow ard differentially priv ate training of neural net- w orks: a differentially priv ate sto c hastic gradient descent (SGD) algorithm, the moments accountan t, and h yp erpa- rameter tuning. 3.1 Differentially Private SGD Algorithm One migh t attempt to protect the priv acy of training data b y w orking only on the final parameters th at result from the training pro cess, treating this process as a blac k box. Un- fortunately , in general, one may not hav e a useful, tight c haracterization of the dependence of these parameters on the training data; adding ov erly conserv ative noise to the pa- rameters, where the noise is selected according to the worst- case analysis, w ould destro y the utilit y of the learned model. Therefore, w e prefer a more sop histicated approac h in whic h w e aim to control the influence of the training data during the training process, sp ecifically in the SGD computation. This approac h has b een follow ed in previo us w orks (e.g., [52, 7]); we mak e sev eral mo dificati ons and extensions, in par- ticular in our priv acy accoun ting. Algorithm 1 outlines our basic metho d for training a model with parameters θ by minimizing the empirical loss function L ( θ ). At each step of the SGD, we compute the gradien t ∇ θ L ( θ , x i ) for a random subset of exa mples, clip the ` 2 norm of each gradien t, compute the av erage, add noise in order to protect priv acy , and take a step in the opp osite direction of this av erage noisy gradient. At the end, in addition to out- putting the mo del, we will also need to compute the priv acy loss of the mechani sm based on the information maintained b y the priv acy accountan t. Next we describe in more detail eac h component of this algorithm and our refinemen ts. Algorithm 1 Differentially priv ate SGD (Outline) Input: Examples { x 1 , . . . , x N } , loss function L ( θ ) = 1 N P i L ( θ , x i ). Parameters: learning rate η t , noise scale σ , group size L , gradient norm bound C . Initialize θ 0 randomly for t ∈ [ T ] do T ake a random sample L t with sampling probabilit y L/ N Compute gradient F or each i ∈ L t , compute g t ( x i ) ← ∇ θ t L ( θ t , x i ) Clip gradient ¯ g t ( x i ) ← g t ( x i ) / max 1 , k g t ( x i ) k 2 C Add noise ˜ g t ← 1 L P i ¯ g t ( x i ) + N (0 , σ 2 C 2 I ) Descen t θ t +1 ← θ t − η t ˜ g t Output θ T and compute the ov erall priv acy cost ( ε, δ ) using a priv acy accoun ting metho d. Norm clipping: Proving the differen tial priv acy guarantee of Algorithm 1 requires bounding the influence of eac h indi- vidual example on ˜ g t . Since there is no a priori bound on the size of the gradient s, we clip each gradien t in ` 2 norm; i.e., the gradien t vector g is replaced by g / max 1 , k g k 2 C , for a clipping threshold C . This clipping ensures that if k g k 2 ≤ C , then g is preserved, whereas if k g k 2 > C , it gets scaled do wn to b e of norm C . W e remark that gradien t clip- ping of this form is a p opular ingredient of SGD for deep net w orks for non-priv acy reasons, though in that setting it usually suffices to clip after a veraging. P er-lay er and time-dep enden t parameters: The pseu- doco de for Algorithm 1 groups all the parameters in to a single input θ of the loss function L ( · ). F or multi-la yer neu- ral net works, w e consider eac h la yer separately , which allows setting different clipping thresholds C and noise scales σ for differen t la yers. Additionally , the clipping and noise param- eters ma y v ary with the n umber of training steps t . In results presen ted in Section 5 w e use constan t settings for C and σ . Lots: Like the ordinary SGD algorithm, Algorithm 1 esti- mates the gradient of L b y computing the gradient of the loss on a group of examples and taking the a verage. This a v- erage provides an unbi ased estimator, the v ariance of which decreases quic kly with the size of the group. W e call suc h a group a lot , to distinguish it from the computational group- ing that is commonly called a b atch . In order to limit mem- ory consumption, we ma y set the batch size m uch smaller than the lot size L , whic h is a parameter of the algorithm. W e p erform the computation in batc hes, then group sev eral batc hes into a lot for adding noise. In practice, for efficiency , the construction of bat c hes and lots is done by randomly p er- m uting the examples and then partitioning them into groups of the appropriate sizes. F or ease of analysis, how ever, we as- sume that each lot is formed b y indep enden tly pick ing eac h example with probabilit y q = L/ N , where N is the size of the input dataset. As is common in the literature, w e normalize the running time of a training algorithm b y expressing it as the num b er of ep o chs , where each ep och is the (expected) num b er of batc hes required to pro cess N examples. In our notation, an epo ch consists of N /L lots. Priv acy accounting: F or differen tially priv ate SGD, an important issue is computing the ov erall priv acy cost of the training. The composability of differential priv acy allo ws us to implemen t an “accounta n t” procedure that computes the priv acy cost at each access to the training data, and accum ulates this cost as the training progresses. Eac h step of training t ypically requires gradien ts at m ultiple lay ers, and the accountan t accumulates the cost that corresp onds to all of them. Momen ts accoun tan t: Muc h research has been devoted to studying the priv acy loss for a particular noise distribu- tion as well as the composition of priv acy losses. F or the Gaussian noise that we use, if we c ho ose σ in Algorithm 1 to be q 2 log 1 . 25 δ /ε , then by standard arguments [20] eac h step is ( ε, δ )-differen tially priv ate with resp ect to the lot. Since the lot itself is a random sample from the database, the priv acy amplification theorem [33, 8] implies that eac h step is ( O ( q ε ) , q δ )-differen tially priv ate with resp ect to the full database where q = L/ N is the sampling ratio per lot and ε ≤ 1. The result in the literature that yields the b est o v erall bound is the strong comp osition theorem [22]. Ho w ev er, the strong comp osition theorem can b e lo ose, and does not take in to account the particular noise distribu- tion under consideration. In our work, we in ven t a stronger accoun ting method, which we call the momen ts accoun tan t. It allows us to prov e that Algorithm 1 is ( O ( q ε √ T ) , δ )- differen tially priv ate for appropriately chosen settings of the noise scale and the clipping threshold. Compared to what one would obtain by the strong composition theorem, our bound is tigh ter in tw o wa ys: it sa ves a p log(1 /δ ) factor in the ε part and a T q factor in the δ part. Since we exp ect δ to b e small and T 1 /q (i.e., eac h example is examined m ultiple times), the sa ving pro vided by our b ound is quite significan t. This result is one of our main con tributions. Theorem 1. Ther e exist c onstants c 1 and c 2 so that given the sampling pr ob ability q = L/ N and the numb er of steps T , for any ε < c 1 q 2 T , Algorithm 1 is ( ε, δ ) -differ ential ly private for any δ > 0 if we cho ose σ ≥ c 2 q p T log (1 /δ ) ε . If w e use the strong comp osition theorem, w e will then need to choose σ = Ω( q p T log (1 /δ ) log ( T /δ ) /ε ). Note that w e sav e a factor of p log( T /δ ) in our asymptoti c b ound. The momen ts accounta n t is b eneficial in theory , as this result indicates, and also in practice, as can b e seen from Figure 2 in Section 4. F or example, with L = 0 . 01 N , σ = 4, δ = 10 − 5 , and T = 10000, we ha ve ε ≈ 1 . 26 using the moments accoun tant. As a comparison, we would get a m uch larger ε ≈ 9 . 34 using the strong comp osition theorem. 3.2 The Moments Accountant: Details The momen ts accoun tant keeps track of a b ound on the momen ts of the priv acy loss random v ariable (defined b e- lo w in Eq. (1)). It generalizes the standard approac h of trac king ( ε, δ ) and using the strong comp osition theorem. While suc h an impro vemen t was known previously for com- posing Gaussian mechanisms, w e sho w that it applies also for comp osing Gaussian mec hanisms with random sampling and can provide muc h tighter estimate of the priv acy loss of Algorithm 1. Priv acy loss is a random v ariable dependent on the ran- dom noise added to the algorithm. That a mec hanism M is ( ε, δ )-differentially priv ate is equiv alent to a certain tail bound on M ’s priv acy loss random v ariable. While the tail bound is v ery useful information on a distribution, comp os- ing directly from it can result in quite lo ose b ounds. W e in- stead compute the log moments of the priv acy loss random v ariable, which comp ose linearly . W e then use the moments bound, together with the standard Marko v inequalit y , to ob- tain the tail bound, that is the priv acy loss in the sense of differen tial priv acy . More sp ecifically , for neigh b oring databases d, d 0 ∈ D n , a mec hanism M , auxiliary input aux , and an outcome o ∈ R , define the priv acy loss at o as c ( o ; M , aux , d, d 0 ) ∆ = log Pr[ M ( aux , d ) = o ] Pr[ M ( aux , d 0 ) = o ] . (1) A c ommon design pattern, whic h w e use extensiv ely in the paper, is to up date the state b y sequentially applying differ- en tially priv ate mech anisms. This is an instance of adaptive c omp osition , whic h we mo del by letting the auxiliary input of the k th mec hanism M k be the output of all the previous mec hanisms. F or a giv en mechani sm M , we define the λ th momen t α M ( λ ; aux , d, d 0 ) as the log of the moment gener ating func- tion ev aluated at the v alue λ : α M ( λ ; aux , d, d 0 ) ∆ = log E o ∼M ( aux ,d ) [exp( λc ( o ; M , aux , d, d 0 ))] . (2) In order to pro ve priv acy guarantees of a mechanism, it is useful to bound all p ossible α M ( λ ; aux , d, d 0 ). W e define α M ( λ ) ∆ = max aux ,d,d 0 α M ( λ ; aux , d, d 0 ) , where the maxim um is taken ov er all p ossible aux and all the neigh b oring databases d, d 0 . W e state the properties of α that we use for the momen ts accoun tant. Theorem 2. L et α M ( λ ) defined as above. Then 1. [Comp osability] Supp ose that a me chanism M c on- sists of a se quenc e of adaptive me chanisms M 1 , . . . , M k wher e M i : Q i − 1 j =1 R j × D → R i . Then, for any λ α M ( λ ) ≤ k X i =1 α M i ( λ ) . 2. [T ail b ound] F or any ε > 0 , the me chanism M is ( ε, δ ) -differ ential ly private for δ = min λ exp( α M ( λ ) − λε ) . In particular, Theorem 2.1 holds when the mec hanisms themselv es are chosen based on the (public) output of the previous mec hanisms. By Theorem 2, it suffices to compute, or b ound, α M i ( λ ) at eac h step and sum them to b ound the moments of the mec h- anism o verall. W e can then u se the tail bound to conv ert the momen ts bound to the ( ε, δ )-differen tial priv acy guarantee. The main challen ge that remains is to b ound the v alue α M t ( λ ) for each step. In the case of a Gaussian mechanism with random sampling, it suffices to estimate the following momen ts. Let µ 0 denote the probability density function (pdf ) of N (0 , σ 2 ), and µ 1 denote the pdf of N (1 , σ 2 ). Let µ be the mixture of tw o Gaussians µ = (1 − q ) µ 0 + q µ 1 . Then w e need to compute α ( λ ) = log max( E 1 , E 2 ) where E 1 = E z ∼ µ 0 [( µ 0 ( z ) /µ ( z )) λ ] , (3) E 2 = E z ∼ µ [( µ ( z ) /µ 0 ( z )) λ ] . (4) In the implementation of the moments accountan t, we carry out numerical in tegration to compute α ( λ ). In ad- dition, w e can sho w the asymptotic b ound α ( λ ) ≤ q 2 λ ( λ + 1) / (1 − q ) σ 2 + O ( q 3 /σ 3 ) . T ogether with Theorem 2, the ab o ve b ound implies our main Theorem 1. The details can b e found in the Appendix. 3.3 Hyperparameter T uning W e identify characteristics of mo dels relev ant for priv acy and, sp ecifically , hyperparameters that we can tune in order to balance priv acy , accuracy , and p erformance. In particu- lar, through exp erimen ts, we observe that model accuracy is more sensitiv e to training parameters suc h as batc h size and noise lev el than to the structure of a neural net work. If we try sev eral settings for the hyperparameters, w e can trivially add up the priv acy costs of all the settings, possibly via the moments accountan t. How ever, since we care only about the setting that gives us the most accurate mo del, we can do b etter, such as applying a version of a result from Gupta et al. [27] restated as Theorem D.1 in the App endix. W e can use insights from theory to reduce the num b er of h yperparameter settings that need to b e tried. While differ- en tially priv ate optimization of conv ex ob jective functions is b est ac hieved using batch sizes as small as 1, non-con vex learning, which is inherently less stable, b enefits from ag- gregation into larger batc hes. At the same time, Theorem 1 suggests that making batches to o large increases the pri- v acy cost, and a reasonable tradeoff is to tak e the num b er of batches p er ep och to be of the same order as the desired n um ber of ep ochs. The learning rate in non-priv ate train- ing is commonly adjusted down wards carefully as the mo del con verges to a lo cal optim um. In con trast, we nev er need to decrease the learning rate to a v ery small v alue, because differen tially priv ate training nev er reaches a regime where it w ould b e justified. On the other hand, in our exp eri- men ts, we do find that there is a small b enefit to starting with a relativ ely large learning rate, then linearly decaying it to a smaller v alue in a few epo c hs, and keeping it constant afterw ards. 4. IMPLEMENT A TION W e hav e implemented the differen tially priv ate SGD al- gorithms in T ensorFlow. The source code is av ailable under an Apac he 2.0 license from gith ub.com/tensorflow/models. F or priv acy protection, we need to “sanitize” the gradien t before using it to up date the parameters. In addition, we need to keep track of the “priv acy spending” b ased on how the sanitization is done. Hence our implementation mainly consists of tw o components: sanitizer , which prepro cesses the gradient to protect priv acy , and privacy_accountant , whic h k eeps track of the priv acy sp ending ov er the course of training. Figure 1 contains the T ensorFlow co de snipp et (in Python) of DPSGD_Optimizer , whic h minimizes a loss function us- ing a differen tially priv ate SGD, and DPTrain , which itera- tiv ely inv okes DPSGD_Optimizer using a priv acy accoun tant to bound the total priv acy loss. In many cases, the neural netw ork model may benefit from the pro cessing of the input by pro jecting it on the principal directions (PCA) or by feeding it through a conv olutional la y er. W e implemen t differen tially priv ate PCA and apply pre-trained con volutional la yers (learned on public data). Sanitizer. In order to achiev e priv acy protection, the sani- tizer needs to perform tw o operations: (1) limit the sensitiv- it y of eac h individual example b y clipping the norm of the gradien t for each example; and (2) add noise to the gradient of a batc h b efore up dating the net work parameters. In T ensorFlow, the gradient computation is batched for performance reasons, yielding g B = 1 / | B | P x ∈ B ∇ θ L ( θ , x ) for a batch B of training examples. T o limit the sensitivity of up dates, we need to access each individual ∇ θ L ( θ , x ). T o this end, w e implemen ted per_example_ gradient op erator in T ensorFlo w, as describ ed b y Goo dfello w [25]. This opera- tor can compute a batch of individual ∇ θ L ( θ , x ). With this implemen tation there is only a mo dest slowdo wn in train- ing, even for larger batch size. Our curren t implemen tation supports batc hed computation for the loss function L , where eac h x i is singly connected to L , allo wing us to handle most hidden la yers but not, for example, con volutional la yers. Once we hav e the access to the p er-example gradient, it is easy to use T ensorFlo w operators to clip its norm and to add noise. Priv acy accoun tant. The main comp onen t in our imple- men tation is PrivacyAccountant which k eeps trac k of pri- v acy sp ending ov er the course of training. As discussed in Section 3, w e implemented the moments accounta n t that ad- ditiv ely accumulates the log of the moments of the priv acy loss at each step. Dep enden t on the noise distribution, one can compute α ( λ ) b y either applying an asymptotic bound, ev aluating a closed-form expression, or applying n umerical class DPSGD_Optimizer(): def __init__(self, accountant, sanitizer): self._accountant = accountant self._sanitizer = sanitizer def Minimize(self, loss, params, batch_size, noise_options): # Accumulate privacy spending before computing # and using the gradients. priv_accum_op = self._accountant.AccumulatePrivacySpending( batch_size, noise_options) with tf.control_dependencies(priv_accum_op): # Compute per example gradients px_grads = per_example_gradients(loss, params) # Sanitize gradients sanitized_grads = self._sanitizer.Sanitize( px_grads, noise_options) # Take a gradient descent step return apply_gradients(params, sanitized_grads) def DPTrain(loss, params, batch_size, noise_options): accountant = PrivacyAccountant() sanitizer = Sanitizer() dp_opt = DPSGD_Optimizer(accountant, sanitizer) sgd_op = dp_opt.Minimize( loss, params, batch_size, noise_options) eps, delta = (0, 0) # Carry out the training as long as the privacy # is within the pre-set limit. while within_limit(eps, delta): sgd_op.run() eps, delta = accountant.GetSpentPrivacy() Figure 1: Co de snipp et of DPSGD_Optimizer and DP- Train . in tegration. The first option would reco ver the generic ad- v anced comp osition theorem, and the latter tw o give a more accurate accoun ting of the priv acy loss. F or the Gaussian mec hanism w e use, α ( λ ) is defined ac- cording to Eqs. (3) and (4). In our implemen tation, we carry out numerical in tegration to compute b oth E 1 and E 2 in those equations. Also we compute α ( λ ) for a range of λ ’s so we can compute the best p ossible ( ε, δ ) v alues using Theorem 2.2. W e find that for the parameters of interest to us, it suffices to compute α ( λ ) for λ ≤ 32. A t any p oin t during training, one can query the priv acy loss in the more interpretable notion of ( ε, δ ) priv acy using Theorem 2.2. Rogers et al. [47] p oin t out risks asso ciated with adaptiv e choice of priv acy parameters. W e a void their attac ks and negative results b y fixing the num b er of iter- ations and priv acy parameters ahead of time. More gen- eral implemen tations of a priv acy accountan t must correctly distinguish betw een tw o mo des of operation—as a priv acy odometer or a priv acy filter (see [47] for more details). Differen tially priv ate PCA. Principal comp onen t analy- sis (PCA) is a useful metho d for capturing the main features of the input data. W e implemen t the differentially priv ate PCA algorithm as describ ed in [23]. More specifically , we tak e a random sample of the training examples, treat them as vectors, and normalize eac h vec tor to unit ` 2 norm to form the matrix A , where eac h vector is a row in the ma- trix. W e then add Gaussian noise to the cov ariance matrix A T A and compute the principal directions of the noisy co- v ariance matrix. Then for each input example we apply the pro jection to these principal directions b efore feeding it in to the neural net work. W e incur a priv acy cost due to running a PCA. How ever, w e find it useful for b oth improving the mo del qualit y and for reducing the training time, as suggested by our exp erimen ts on the MNIST data. See Section 4 for details. Con volutional lay ers. Conv olutional la yers are useful for deep neural netw orks. Ho wev er, an efficient per-example gradien t computation for con volutional lay ers remains a c hal- lenge within the T ensorFlow framework, which motiv ates creating a separate workflo w. F or example, some recent w ork argues that even random con volutions often suffice [46, 13, 49, 55, 14]. Alternativ ely , we explore the idea of learning conv olu- tional lay ers on public data, follo wing Jarrett et al. [30]. Suc h conv olutional la yers can be based on Go ogLeNet or AlexNet features [54, 35] for image mo dels or on pretrained w ord2v ec or GloV e em b eddings in language mo dels [41, 44]. 5. EXPERIMENT AL RESUL TS This section rep orts on our ev aluation of the moments ac- coun tant, and results on tw o p opular image datasets: MNIST and CIF AR-10. 5.1 A pplying the Moments Accountant As shown by Theorem 1, the moments accountan t pro- vides a tighter b ound on the priv acy loss compared to the generic strong comp osition theorem. Here w e compare them using some concrete v alues. The ov erall priv acy loss ( ε, δ ) can b e computed from the noise level σ , the sampling ra- tio of eac h lot q = L/ N (so each ep och consists of 1 /q batc hes), and the num b er of ep ochs E (so the nu m ber of steps is T = E /q ). W e fix the target δ = 10 − 5 , the v alue used for our MNIST and CIF AR exp erimen ts. In our exp erimen t, we set q = 0 . 01, σ = 4, and δ = 10 − 5 , and compute the v alue of ε as a function of the training epo ch E . Figure 2 shows tw o curves corresp onding to, re- spectively , using the strong comp osition theorem and the momen ts accountan t. W e can see that w e get a muc h tigh ter estimation of the priv acy loss by using the momen ts accoun- tan t. F or examples, when E = 100, the v alues are 9 . 34 and 1 . 26 resp ectiv ely , and for E = 400, the v alues are 24 . 22 and 2 . 55 respectively . That is, using the moments b ound, w e achiev e (2 . 55 , 10 − 5 )-differen tial priv acy , whereas previ- ous techniques only obtain the significantly w orse guarantee of (24 . 22 , 10 − 5 ). 5.2 MNIST W e conduct experiments on the standard MNIST dataset for handwritten digit recognition consisting of 60 , 000 train- ing examples and 10 , 000 testing examples [36]. Each exam- ple is a 28 × 28 size gray-lev el image. W e use a simple feed- forw ard neural netw ork with ReLU units and softmax of 10 classes (corresponding to the 10 digits) with cross-entro p y loss and an optional PCA input la yer. Baseline model. Our baseline mo del uses a 60-dimensional PCA pro jection la y er and a single hidden lay er with 1 , 000 hidden units. Us- ing the lot size of 600, w e can reach accuracy of 98 . 30% in about 100 epo c hs. This result is consisten t with what can be ac hieved with a v anilla neural net work [36]. Figure 2: The ε v alue as a function of ep o c h E for q = 0 . 01 , σ = 4 , δ = 10 − 5 , using the strong comp osition theorem and the moments accoun tant resp ectiv ely . Differ entially private model. F or the differentially priv ate v ersion, w e exp erimen t with the same architecture with a 60-d imensional PCA pro jection la y er, a single 1 , 000-unit ReLU hidden lay er, and a lot size of 600. T o limit sensitivity , we clip the gradien t norm of each la y er at 4. W e rep ort results for three c hoices of the noise scale, which w e call small ( σ = 2 , σ p = 4), medium ( σ = 4 , σ p = 7), and large ( σ = 8 , σ p = 16). Here σ represents the noise level for training the neural netw ork, and σ p the noise level for PCA pro jection. The learning rate is set at 0 . 1 initially and linearly decreased to 0 . 052 ov er 10 epo ch s and then fixed to 0 . 052 thereafter. W e hav e also exp erimen ted with m ulti-hidden-lay er netw orks. F or MNIST, we found that one hidden la yer combined with PCA w orks better th an a tw o-la y er netw ork. Figure 3 shows the results for differen t noise leve ls. In eac h plot, we show the evolution of the training and testing accuracy as a function of the n umber of ep ochs as w ell as the corresp onding δ v alue, keeping ε fixed. W e achiev e 90%, 95%, and 97% test set accuracy for (0 . 5 , 10 − 5 ), (2 , 10 − 5 ), and (8 , 10 − 5 )-differen tial priv acy resp ectiv ely . One attractive consequence of applying differentially pri- v ate SGD is the small difference betw een the mo del’s ac- curacy on the training and the test sets, which is consis- ten t with the theoretical argumen t that differen tially priv ate training generalizes well [6]. In contrast, the gap b et ween training and testing accuracy in non-priv ate training, i.e., evidence of o verfitting, increases with the n umber of ep ochs. By using the momen ts accoun tant, we can obtain a δ v alue for any given ε . W e record the accuracy for different ( ε, δ ) pairs in Figure 4. In the fig ure, each curve corresponds to the best accuracy achiev ed for a fixed δ , as it v aries betw een 10 − 5 and 10 − 2 . F or example, we can ac hieve 90% accuracy for ε = 0 . 25 and δ = 0 . 01. As can b e observ ed from the figure, for a fixed δ , v arying the v alue of ε can ha ve large impact on accuracy , but for an y fixed ε , there is less difference with differen t δ v alues. Effect of the parameter s. Classification accuracy is determined by m ultiple factors (1) Large noise (2) Medium noise (3) Small noise Figure 3: Results on the accuracy for differen t noise level s on the MNIST dataset. In all the experiments, the net work uses 60 dimension PCA pro jection, 1 , 000 hidden units, and is trained using lot size 600 and clipping threshold 4 . The noise levels ( σ, σ p ) for training the neural netw ork and for PCA pro jection are set at ( 8 , 16 ), ( 4 , 7 ), and ( 2 , 4 ), resp ectiv ely , for the three exp erimen ts. Figure 4: Accuracy of v arious ( ε, δ ) priv acy v alues on the MNIST dataset. Eac h curve corresponds to a different δ v alue. that m ust b e carefully tuned for optimal performance. These factors include the top ology of the netw ork, the n um ber of PCA dimensions and the num b er of hidden units, as well as parameters of the training procedure suc h as the lot size and the learning rate. Some parameters are sp ecific to priv acy , suc h as the gradien t norm clipping bound and the noise level. T o demonstrate the effects of these para meters, w e manip- ulate them individually , k eeping the rest constan t. W e set the reference v alues as follo ws: 60 PCA dimensions, 1,000 hidden units, 600 lot size, gradient norm b ound of 4, ini- tial learning rate of 0.1 decreasing to a final learning rate of 0.052 in 10 epo c hs, and noise σ equal to 4 and 7 resp ec- tiv ely fo r train ing th e neura l net work parameters and for the PCA pro jection. F or eac h combination of v alues, w e train un til the point at whic h (2 , 10 − 5 )-differen tial priv acy would be violated (so, for example, a larger σ allows more ep o c hs of training). The results are presented in Figure 5. PCA pro jection. In our exp erimen ts, the accuracy is fairly stable as a function of the PCA dimension, with the best results achiev ed for 60. (Not doing PCA reduces ac- curacy by ab out 2%.) Although in principle the PCA pro- jection lay er can b e replaced b y an additional hidden la yer, w e achiev e b etter accuracy by training the PCA la y er sep- arately . By reducing the input size from 784 to 60, PCA leads to an almost 10 × reduction in training time. The re- sult is fairly stable ov er a large range of the noise lev els for the PCA pro jection and consisten tly b etter than the accu- racy using random pro jection, whic h is at ab out 92 . 5% and sho wn as a horizon tal line in the plot. Num b er of hidden units. Including more hidden units mak es it easier to fit the training set. F or non-priv ate train- ing, it is often preferable to use more units, as long as we emplo y techniques to av oid ov erfitting. How ever, for differ- en tially priv ate training, it is not a priori clear i f more hidden units impro v e accuracy , as more hidden units increase the sensitivit y of the gradient, which leads to more noise added at eac h update. Somewhat counterin tuitively , increasing the num b er of hidden units do es not decrease accuracy of the trained model. One p ossible explanation that calls for further analysis is that larger netw orks are more tolerant to noise. This prop- ert y is quite encouraging as it is common in practice to use v ery large net w orks. Lot size. According to Theorem 1, w e can run N /L ep ochs while sta ying within a constan t priv acy budget. Choosing the lot size m ust balance tw o conflicting ob jectiv es. On the one hand, smaller lots allo w running more e po chs , i.e., passes o v er data, impro ving accuracy . On the other hand, for a larger lot, the added noise has a smaller relativ e effect. Our experiments sho w that the lot size has a relatively large impact on accuracy . Empirically , the b est lot size is roughly √ N where N is the num b er of training examples. Learning rate. Accuracy is stable for a learning rate in the range of [0 . 01 , 0 . 07] and peaks at 0.05, as shown in Fig- ure 5(4). How ever, accuracy decreases significantly if the learning rate is to o large. Some additional exp erimen ts sug- gest that, even for large learning rates, w e can reach similar lev els of accuracy b y reducing the noise level and, accord- ingly , by training less in order to av oid exhausting the pri- v acy budget. Clipping b ound. Limiting the gradien t norm has tw o op- posing effects: clipping destro ys the un biasedness of the gra- dien t estimate, and if the clipping parameter is to o small, the av erage clipp ed gradient ma y p oin t in a very different (1) v ariable pro jection dimensions (2) v ariable hidden units (3) v ariable lot size (4) v ariable learning rate (5) v ariable gradient clipping norm (6) v ariable noise lev el Figure 5: MNIST accuracy when one parameter v aries, and the others are fixed at reference v alues. direction from the true gradient. On the other hand, in- creasing the norm b ound C forces us to add more noise to the gradients (and hence th e parameters), since we add noise based on σ C . In practice, a go od wa y to c hoose a v alue for C is by taking the median of the norms of the unclipped gradien ts ov er the course of training. Noise lev el. By adding more noise, the p er-step priv acy loss is prop ortionally smaller, so we can run more ep ochs within a given cum ulative priv acy budget. In Figure 5(5), the x -axis is the noise level σ . The cho ice of this v alue has a large impact on accuracy . F rom the exp erimen ts, we observe the follo wing. 1. The PCA pro jection improv es b oth model accuracy and training p erformance. Accuracy is quite stable o v er a large range of choices for the pro jection dimen- sions and the noise lev el used in the PCA stage. 2. The accuracy is fairly stable ov er the netw ork size. When we can only run smaller num b er of ep ochs, it is more beneficial to use a larger net work. 3. The training parameters, esp ecially the lot size and the noise scale σ , hav e a large impact on the model accuracy . They b oth determine the “noise-to-signal” ratio of the sanitized gradien ts as well as the n umber of ep ochs we are able to go through the data before reac hing the priv acy limit. Our framework allows for adaptiv e con trol of the training parameters, such as the lot size, the gradien t norm b ound C , and noise level σ . Our initial exp erimen ts with decreas- ing noise as training progresses did not show a significan t impro vemen t, but it is interesting to consider more sophis- ticated sc hemes for adaptiv ely choosing these parameters. 5.3 CIF AR W e also conduct exp erimen ts on the CIF AR-10 dataset, whic h consists of color images classified into 10 classes suc h as ships, cats, and dogs, and partitioned into 50 , 000 training examples and 10 , 000 test examples [1]. Each example is a 32 × 32 image with three c hannels (R GB). F or this learning task, nearly all successful netw orks use conv olutional lay ers. The CIF AR-100 dataset has similar parameters, except that images are classified into 100 classes; the examples and the image classes are differen t from those of CIF AR-10. W e use the netw ork architecture from the T ensorFlow con- v olutional neural netw orks tutorial [2]. Eac h 32 × 32 image is first cropp ed to a 24 × 24 one by taking the cen ter patch. The netw ork architec ture consists of tw o conv olutional lay- ers follo wed by tw o fully connected lay ers. The c on v olutional la y ers use 5 × 5 con v olutions with stride 1, follow ed by a ReLU and 2 × 2 max p ools, with 64 channels eac h. Th us the first conv olution outputs a 12 × 12 × 64 tensor for eac h image, and the second outputs a 6 × 6 × 64 tensor. The latter is flattened to a vector that gets fed into a fully connected la y er with 384 units, and another one of the same size. This arc hitecture, non-priv ately , can get to ab out 86% ac- curacy in 500 ep ochs. Its simplicit y mak es it an app ealing c hoice for our work. W e should note how ever that by us- ing deeper netw orks with differen t non-linearities and other adv anced techniques, one can obtain significan tly better ac- curacy , with the state-of-the-art being ab out 96 . 5% [26]. As is standard for such image datasets, we use data aug- mentation during training. F or each training image, w e gen- erate a new distorted image by randomly picking a 24 × 24 patc h from the image, randomly flipping the image along the left-righ t direction, and randomly distorting the bright- ness and the contrast of the image. In each ep och, these (1) ε = 2 (2) ε = 4 (3) ε = 8 Figure 6: Results on accuracy for different noise levels on CIF AR-10. With δ set to 10 − 5 , we ac hieve accuracy 67% , 70% , and 73% , with ε b eing 2 , 4 , and 8 , resp ectiv ely . The first graph uses a lot size of 2,000, (2) and (3) use a lot size of 4,000. In all cases, σ is set to 6 , and clipping is set to 3 . distortions are done independently . W e refer the reader to the T ensorFlow tutorial [2] for additional details. As the con volutional lay ers ha ve shared parameters, com- puting per-example gradients has a larger computational o v erhead. Previous work has shown that con volutional lay- ers are often transferable: parameters learned from one data- set can b e used on another one without retraining [30]. W e treat the CIF AR-100 dataset as a public dataset and use it to train a netw ork with the same architecture. W e use the con volutions learned from training this dataset. Retrain- ing only the fully connected lay ers with this architect ure for about 250 ep ochs with a batch size of 120 gives us appro xi- mately 80% accuracy , which is our non-priv ate baseline. Differ entially private version. F or the differentia lly priv ate v ersion, we use the same ar- c hitecture. As discussed abov e, we use pre-trained con volu- tional lay ers. The fully connected la yers are initialized from the pre-trained netw ork as well. W e train the softmax lay er, and either the top or both fully connected lay ers. Based on looking at gradien t norms, the softmax lay er gradien ts are roughly twice as large as the other tw o la y ers, and we k eep this ratio when w e try clipping at a few different v alues b e- t w een 3 and 10. The lot size is an additional knob that we tune: we tried 600, 2 , 000, and 4 , 000. With these settings, the per-epo ch training time increases from appro ximately 40 seconds to 180 seconds. In Figure 6, we show the ev olution of the accuracy and the priv acy cost, as a function of the num b er of ep ochs, for a few differen t parameter settings. The v arious parameters influence the accuracy one gets, in w a ys not too different from that in the MNIST exp erimen ts. A lot size of 600 leads to p oor results on this dataset and w e need to increase it to 2,000 or more for results rep orted in Figure 6. Compared to the MNIST dataset, where the difference in accuracy b et ween a non-priv ate baseline an d a priv ate mo del is ab out 1.3%, the corresp onding drop in accuracy in our CIF AR-10 exp erimen t is muc h larger (ab out 7%). W e lea ve closing this gap as an interesting test for future research in differen tially priv ate machine learning. 6. RELA TED WORK The problem of priv acy-preserving data mining, or ma- c hine learning, has b een a fo cus of active work in several researc h communities since the late 90s [5, 37]. The exist- ing literature can b e broadly classified along sev eral axes: the class of mo dels, the learning algorithm, and the priv acy guaran tees. Priv acy guarantees. Early wo rks on priv acy-preserving learning w ere done in the framework of secure function ev al- uation (SFE) and secure m ulti-part y computations (MPC), where the input is split b et ween t w o or more parties, and the focus is on minimizing information leak ed during the join t computation of some agreed-to functionalit y . In con- trast, we assume that data is held centrall y , and we are concerned with leak age from the functionality’s output (i.e., the model). Another approach, k -anon ymity and closely related no- tions [53], seeks to offer a degree of protection to underlying data b y generalizing and suppressing certain identifyin g at- tributes. The approach has strong theoretical and empirical limitations [4, 9] that make it all but inapplicable to de- anon ymization of high-dimensional, div erse input datasets. Rather than pursue input sanitization, we keep the under- lying ra w records in tact and p erturb deriv ed data instead. The theory of differential priv acy , which provides the an- alytical framework for our work, has been applied to a large collection of mach ine learning tasks that differed from ours either in the training mec hanism or in the target mo del. The moments accoun tant is closely related to the notion of R ´ en yi differential priv acy [42], whic h proposes (scaled) α ( λ ) as a means of quantifyin g priv acy guarantees. In a concur- ren t and independent work Bun and Steinke [10] introduce a relaxation of differential priv acy (generalizing the wo rk of Dwork and Rothblum [20]) defined via a linear upp er bound on α ( λ ). T aken together, these works demonstrate that the momen ts accoun tant is a useful tec hnique for theo- retical and empirical analyses of complex priv acy-preserving algorithms. Learning algorithm. A common target for learning with priv acy is a class of conv ex optimization problems amenable to a wide v ariety of tec hniques [18, 11, 34]. In concurren t w ork, W u et al. ac hieve 83% accuracy on MNIST via con- v ex empirical risk minimization [57]. T raining multi-la yer neural netw orks is non-conv ex, and t ypically solved b y an application of SGD, whose theoretical guarantees are po orly understoo d. F or the CIF AR neural net work w e incorporate differen- tially priv ate training of the PCA pro jection matrix [23], whic h is used to reduce dimensionalit y of inputs. Mo del class. The first end-to-end differen tially priv ate sys- tem was ev aluated on the Netfl ix Prize dataset [39], a v ersion of a collaborative filtering problem. Although the problem shared many similarities with ours—high-dimensional in- puts, non-con vex ob jectiv e function—the appro ac h tak en b y McSherry and Mironov differed significantly . They iden tified the core of the learning task, effectively sufficien t statistics, that can b e computed in a differen tially priv ate manner via a Gaussian mec hanism. In our approac h no suc h sufficien t statistics exist. In a recent work Shokri and Shmatiko v [50] designed and ev aluated a system for distribute d training of a deep neural net w ork. Participan ts, who hold their data closely , commu- nicate sanitized updates to a central authority . The sani- tization relies on an additiv e-noise mechanism, based on a sensitivit y estimate, which could be improv ed to a hard sen- sitivit y guaran tee. They compute priv acy loss p er param- eter (not for an entire model). By our preferred measure, the total priv acy loss p er participant on the MNIST dataset exceeds sev eral thousand. A different, recent approach tow ards differentially priv ate deep learning is explored b y Phan et al. [45]. This w ork focuses on learning auto encoders. Priv acy is based on p er- turbing the ob jectiv e functions of these autoenco ders. 7. CONCLUSIONS W e demonstrate the traini ng of deep neural net works with differen tial priv acy , incurring a mo dest total priv acy loss, computed ov er entire mo dels with many parameters. In our experiments for MNIST, w e achiev e 97% training accu- racy and for CIF AR-10 we achiev e 73% accuracy , b oth with (8 , 10 − 5 )-differen tial priv acy . Our algorithms are based on a differen tially priv ate v ersion of stochastic gradien t descent; they run on the T ensorFlow softw are library for machine learning. Since our approac h applies directly to gradien t computations, it can b e adapted to many other classical and more recent first-order optimization methods, such as NA G [43], Momen tum [48], AdaGrad [15], or SVRG [31]. A new to ol, whic h may b e of indep enden t interest, is a mec hanism for tracking priv acy loss, the moments accoun- tan t. It p ermits tight automated analysis of the priv acy loss of complex composite mec hanisms that are currently b ey ond the reac h of adv anced composition theorems. A num b er of av enues for further w ork are attractiv e. In particular, w e would lik e to consider other classes of deep net w orks. Our exp erience with MNIST and CIF AR-10 should be helpful, but we see many opp ortunities for new research, for example in applying our tec hniques to LSTMs used for language mo deling tasks. In addition, we would like to ob- tain additional improv ements in accuracy . Many training datasets are muc h larger than those of MNIST and CIF AR- 10; accuracy should benefit from their size. 8. A CKNO WLEDGMENTS W e are grateful to ´ Ulfar Erlingsson and Dan Ramage for man y useful discussions, and to Mark Bun and Thomas Steink e for sharing a draft of [10]. 9. REFERENCES [1] CIF AR-10 and CIF AR-100 datasets. www.cs.toron to.edu/˜kriz/cifar.html. [2] T ensorFlow conv olutional neural netw orks tutorial. www.tensorflo w.org/tutorials/deep cnn. [3] T ensorFlow: Large-scale machine learning on heterogeneous systems, 2015. Soft ware a v ailable from tensorflo w.org. [4] C. C. Aggarwal. On k -anon ymity and the curse of dimensionalit y . In VLDB , pages 901–909, 2005. [5] R. Agraw al and R. Srik ant. Priv acy-preserving data mining. In SIGMOD , pages 439–450. A CM, 2000. [6] R. Bassily , K. Nissim, A. Smith, T. Steinke, U. Stemmer, and J. Ullman. Algorithmic stabilit y for adaptiv e data analysis. In STOC , pages 1046–1059. A CM, 2016. [7] R. Bassily , A. D. Smith, and A. Thakurta. Priv ate empirical risk minimization: Efficien t algorithms and tigh t error bounds. In FOCS , pages 464–473. IEEE, 2014. [8] A. Beimel, H. Brenner, S. P . Kasiviswanathan, and K. Nissim. Bounds on the sample complexit y for priv ate learning and priv ate data release. Machine L e arning , 94(3):401–437, 2014. [9] J. Brick ell and V. Shmatiko v. The cost of priv acy: Destruction of data-mining utilit y in anonymized data publishing. In KDD , pages 70–78. A CM, 2008. [10] M. Bun and T. Steinke. Concentrated differential priv acy: Simplifications, extensions, and low er b ounds. In TCC-B . [11] K. Chaudhuri, C. Monteleoni, and A. D. Sarw ate. Differen tially priv ate empirical risk minimization. J. Machine L e arning R ese ar ch , 12:1069–1109, 2011. [12] R. Collob ert, K. Kavuk cuoglu, and C. F arab et. T orch7: A Matlab-like environmen t for machine learning. In BigL e arn, NIPS Workshop , num b er EPFL-CONF-192376, 2011. [13] D. D. Cox and N. Pinto. Bey ond simple features: A large-scale feature searc h approach to unconstrained face recognition. In F G 2011 , pages 8–15. IEEE, 2011. [14] A. Daniely , R. F rostig, and Y. Singer. T ow ard deep er understanding of neural net works: The pow er of initialization and a dual view on expressivit y . CoRR , abs/1602.05897, 2016. [15] J. Duchi, E. Hazan, and Y. Singer. Adaptive subgradien t metho ds for online learning and sto c hastic optimization. J. Machine L e arning R ese ar ch , 12:2121–2159, July 2011. [16] C. Dwork. A firm foundation for priv ate data analysis. Commun. ACM , 54(1):86–95, Jan. 2011. [17] C. Dwork, K. Kenthapadi, F. McSherry , I. Mirono v, and M. Naor. Our data, ourselv es: Priv acy via distributed noise generation. In EUR OCR YPT , pages 486–503. Springer, 2006. [18] C. Dwork and J. Lei. Differential priv acy and robust statistics. In STOC , pages 371–380. A CM, 2009. [19] C. Dwork, F. McSherry , K. Nissim, and A. Smith. Calibrating noise to sensitivit y in priv ate data analysis. In TCC , pages 265–284. Springer, 2006. [20] C. Dwork and A. Roth. The algorithmic foundations of differen tial priv acy . F oundations and T r ends in The or etic al Computer Scienc e , 9(3–4):211–407, 2014. [21] C. Dwork and G. N. Rothblum. Concen trated differen tial priv acy . CoRR , abs/1603.01887, 2016. [22] C. Dwork, G. N. Rothblum, and S. V adhan. Boosting and differen tial priv acy . In FOC S , pages 51–60. IEEE, 2010. [23] C. Dwork, K. T alw ar, A. Thakurta, and L. Zhang. Analyze Gauss: Optimal bounds for priv acy-preserving principal component analysis. In STOC , pages 11–20. A CM, 2014. [24] M. F redrikson, S. Jha, and T. Ristenpart. Mo del in v ersion attac ks that exploit confidence information and basic coun termeasures. In CCS , pages 1322–1333. A CM, 2015. [25] I. Go odfellow. Efficient per-example gradient computations. CoRR , abs/1510.01799v2, 2015. [26] B. Graham. F ractional max-p ooling. CoRR , abs/1412.6071, 2014. [27] A. Gupta, K. Ligett, F. McSherry , A. Roth, and K. T alwar. Differentially priv ate combinatorial optimization. In SOD A , pages 1106–1125, 2010. [28] K. He, X. Zhang, S. Ren, and J. Sun. Delving deep in to rectifiers: Surpassing h uman-lev el p erformance on ImageNet classification. In ICCV , pages 1026–1034. IEEE, 2015. [29] R. Ierusalimsch y , L. H. de Figueiredo, and W. Filho. Lua—an extensible extension language. Softwar e: Pr actic e and Exp erienc e , 26(6):635–652, 1996. [30] K. Jarrett, K. Kavuk cuoglu, M. Ranzato, and Y. LeCun. What is the b est multi-stage arc hitecture for ob ject recognition? In ICCV , pages 2146–2153. IEEE, 2009. [31] R. Johnson and T. Zhang. Accelerating stochastic gradien t descent using predictiv e v ariance reduction. In NIPS , pages 315–323, 2013. [32] P . Kairouz, S. Oh, and P . Viswanath. The composition theorem for differen tial priv acy . In ICML , pages 1376–1385. A CM, 2015. [33] S. P . Kasiviswanathan, H. K. Lee, K. Nissim, S. Raskhodniko v a, and A. Smith. What can we learn priv ately? SIAM J. Comput. , 40(3):793–826, 2011. [34] D. Kifer, A. D. Smith, and A. Thakurta. Priv ate con vex optimization for empirical risk minimization with applications to high-dimensional regression. In COL T , pages 25.1–25.40, 2012. [35] A. Krizhevsky , I. Sutskev er, and G. E. Hinton. ImageNet classification with deep con volutional neural net w orks. In NIPS , pages 1097–1105, 2012. [36] Y. LeCun, L. Bottou, Y. Bengio, and P . Haffner. Gradien t-based learning applied to do cumen t recognition. Pr o c e e dings of the IEEE , 86(11), 1998. [37] Y. Lindell and B. Pink as. Priv acy preserving data mining. In CR YPTO , pages 36–54. Springer, 2000. [38] C. J. Maddison, A. Huang, I. Sutsk ever, and D. Silver. Mo v e ev aluation in Go using deep conv olutional neural net w orks. In ICLR , 2015. [39] F. McSherry and I. Mirono v. Differen tially priv ate recommender systems: Building priv acy in to the Netflix Prize con tenders. In KDD , pages 627–636. A CM, 2009. [40] F. D. McSherry . Priv acy integrated queries: An extensible platform for priv acy-preserving data analysis. In SIGMOD , pages 19–30. A CM, 2009. [41] T. Mikolo v, K. Chen, G. Corrado, and J. Dean. Efficien t estimation of w ord representations in v ector space. CoRR , abs/1301.3781, 2013. [42] I. Mironov. R´ en yi differential priv acy . Priv ate comm unication, 2016. [43] Y. Nesterov. Intr o ductory L e ctur es on Convex Optimization. A Basic Course . Springer, 2004. [44] J. Pennington , R. So c her, and C. D. Manning. GloV e: Global v ectors for w ord representation. In EMNLP , pages 1532–1543, 2014. [45] N. Phan, Y. W ang, X. W u, and D. Dou. Differential priv acy preserv ation for deep auto-encoders: an application of h uman b eha vior prediction. In AAAI , pages 1309–1316, 2016. [46] N. Pinto, Z. Stone, T. E. Zickler, and D. Co x. Scaling up biologically-inspired computer vision: A case study in unconstrained face recognition on F acebo ok. In CVPR , pages 35–42. IEEE, 2011. [47] R. M. Rogers, A. Roth, J. Ullman, and S. P . V adhan. Priv acy odometers and filters: P ay-as-y ou-go composition. In NIPS . [48] D. E. Rumelhart, G. E. Hinton, and R. J. Williams. Learning represen tations by bac k-propagating errors. Natur e , 323:533–536, Oct. 1986. [49] A. Saxe, P . W. Koh, Z. Chen, M. Bhand, B. Suresh, and A. Ng. On random we igh ts and unsupervised feature learning. In ICML , pages 1089–1096. A CM, 2011. [50] R. Shokri and V. Shmatiko v. Priv acy-preserving deep learning. In CCS , pages 1310–1321. A CM, 2015. [51] D. Silver, A. Huang, C. J. Maddison, A. Guez, L. Sifre, G. v an den Driessche, J. Schritt wieser, I. An tonoglou, V. P anneershelv am, M. Lanctot, S. Dieleman, D. Grewe , J. Nham, N. Kalch brenner, I. Sutsk ever, T. Lillicrap, M. Leac h, K. Ka vukcuoglu, T. Graepel, and D. Hassabis. Mastering the game of Go with deep neural netw orks and tree searc h. Natur e , 529(7587):484–489, 2016. [52] S. Song, K. Chaudhu ri, and A. Sarwa te. Stochastic gradien t descent with differen tially priv ate up dates. In Glob alSIP Confer enc e , 2013. [53] L. Sweeney . k -anon ymit y: A model for protecting priv acy . International J. of Unc ertainty, F uzziness and Know le dge-Base d Systems , 10(05):557–570, 2002. [54] C. Szegedy , W. Liu, Y. Jia, P . Sermanet, S. Reed, D. Anguelo v, D. Erhan, V. V anhouc k e, and A. Rabino vich. Going deeper with conv olutions. In CVPR , pages 1–9. IEEE, 2015. [55] S. T u, R. Ro elofs, S. V enk ataraman, and B. Rec ht. Large scale k ernel learning using block coordinate descen t. CoRR , abs/1602.05310, 2016. [56] O. Viny als, L. Kaiser, T. Ko o, S. Petro v, I. Sutsk ever, and G. E. Hint on. Grammar as a foreign language. In NIPS , pages 2773–2781, 2015. [57] X. W u, A. Kumar, K. Chaudhuri, S. Jha, and J. F. Naugh ton. Differentially priv ate sto ch astic gradien t descen t for in-RDBMS analytics. CoRR , abs/1606.04722, 2016. APPENDIX A. PR OOF OF THEOREM 2 Here we restate and prov e Theorem 2. Theorem 2. L et α M ( λ ) defined as α M ( λ ) ∆ = max aux ,d,d 0 α M ( λ ; aux , d, d 0 ) , wher e the maximum is taken over al l auxiliary inputs and neighb oring datab ases d, d 0 . Then 1. [Comp osability] Supp ose that a mecha nism M c on- sists of a se quenc e of adaptive me chanisms M 1 , . . . , M k wher e M i : Q i − 1 j =1 R j × D → R i . Then, for any λ α M ( λ ) ≤ k X i =1 α M i ( λ ) . 2. [T ail b ound] F or any ε > 0 , the me chanism M is ( ε, δ ) -differ ential ly private for δ = min λ exp( α M ( λ ) − λε ) . Proof. Comp osition of momen ts. F or brevit y , let M 1: i denote ( M 1 , . . . , M i ), and similarly let o 1: i denote ( o 1 , . . . , o i ). F or neighboring databases d, d 0 ∈ D n , and a sequence of outcomes o 1 , . . . , o k w e write c ( o 1: k ; M 1: k , o 1:( k − 1) , d, d 0 ) = log Pr[ M 1: k ( d ; o 1:( k − 1) ) = o 1: k ] Pr[ M 1: k ( d 0 ; o 1:( k − 1) ) = o 1: k ] = log k Y i =1 Pr[ M i ( d ) = o i | M 1:( i − 1) ( d ) = o 1:( i − 1) ] Pr[ M i ( d 0 ) = o i | M 1:( i − 1) ( d 0 ) = o 1:( i − 1) ] = k X i =1 log Pr[ M i ( d ) = o i | M 1:( i − 1) ( d ) = o 1:( i − 1) ] Pr[ M i ( d 0 ) = o i | M 1:( i − 1) ( d 0 ) = o 1:( i − 1) ] = k X i =1 c ( o i ; M i , o 1:( i − 1) , d, d 0 ) . Th us E o 0 1: k ∼M 1: k ( d ) exp( λc ( o 0 1: k ; M 1: k , d, d 0 )) ∀ i < k : o 0 i = o i = E o 0 1: k ∼M 1: k ( d ) " exp λ k X i =1 c ( o 0 i ; M i , o 1:( i − 1) , d, d 0 ) !# = E o 0 1: k ∼M 1: k ( d ) " k Y i =1 exp λc ( o 0 i ; M i , o 1:( i − 1) , d, d 0 ) # (b y independence of noise) = k Y i =1 E o 0 i ∼M i ( d ) exp( λc ( o 0 i ; M i , o 1:( i − 1) , d, d 0 )) = k Y i =1 exp α M i ( λ ; o 1:( i − 1) , d, d 0 ) = exp k X i =1 α i ( λ ; o 1:( i − 1) , d, d 0 ) ! . The claim follo ws. T ail b ound b y moments. The proof is based on the stan- dard Mark ov’s inequality argument used in proofs of mea- sure concen tration. W e ha ve Pr o ∼M ( d ) [ c ( o ) ≥ ε ] = Pr o ∼M ( d ) [exp( λc ( o )) ≥ exp( λε ))] ≤ E o ∼M ( d ) [exp( λc ( o ))] exp( λε ) ≤ exp( α − λε ) . Let B = { o : c ( o ) ≥ ε } . Then for any S , Pr[ M ( d ) ∈ S ] = Pr[ M ( d ) ∈ S ∩ B c ] + Pr[ M ( d ) ∈ S ∩ B ] ≤ exp( ε ) Pr[ M ( d 0 ) ∈ S ∩ B c ] + Pr[ M ( d ) ∈ B ] ≤ exp( ε ) Pr[ M ( d 0 ) ∈ S ] + exp( α − λε ) . The second part follo ws by an easy calculation. The pro of demonstrates a tail b ound on the priv acy loss, making it stronger than differen tial priv acy for a fixed v alue of ε, δ . B. PR OOF OF LEMMA 3 The pro of of the main theorem relies on the following mo- men ts b ound on Gaussian mechanism with random sam- pling. Lemma 3. Supp ose that f : D → R p with k f ( · ) k 2 ≤ 1 . L et σ ≥ 1 and let J b e a sample fr om [ n ] wher e e ach i ∈ [ n ] is chosen indep endently with pr ob ability q < 1 16 σ . Then for any p ositive inte ger λ ≤ σ 2 ln 1 qσ , the me chanism M ( d ) = P i ∈ J f ( d i ) + N (0 , σ 2 I ) satisfies α M ( λ ) ≤ q 2 λ ( λ + 1) (1 − q ) σ 2 + O ( q 3 λ 3 /σ 3 ) . Proof. Fix d 0 and let d = d 0 ∪ { d n } . Without loss of generalit y , f ( d n ) = e 1 and P i ∈ J \ [ n ] f ( d i ) = 0 . Thus M ( d ) and M ( d 0 ) are distributed iden tically except for the first coordinate and hence we hav e a one-dimensional problem. Let µ 0 denote the pdf of N (0 , σ 2 ) and let µ 1 denote the pdf of N (1 , σ 2 ). Thus: M ( d 0 ) ∼ µ 0 , M ( d ) ∼ µ ∆ = (1 − q ) µ 0 + q µ 1 . W e wan t to show that E z ∼ µ [( µ ( z ) /µ 0 ( z )) λ ] ≤ α, and E z ∼ µ 0 [( µ 0 ( z ) /µ ( z )) λ ] ≤ α, for some explicit α to b e determined later. W e will use the same metho d to prov e b oth b ound s. As- sume we hav e tw o distributions ν 0 and ν 1 , and we wish to bound E z ∼ ν 0 [( ν 0 ( z ) /ν 1 ( z )) λ ] = E z ∼ ν 1 [( ν 0 ( z ) /ν 1 ( z )) λ +1 ] . Using binomial expansion, w e hav e E z ∼ ν 1 [( ν 0 ( z ) /ν 1 ( z )) λ +1 ] = E z ∼ ν 1 [(1 + ( ν 0 ( z ) − ν 1 ( z )) /ν 1 ( z )) λ +1 ] = E z ∼ ν 1 [(1 + ( ν 0 ( z ) − ν 1 ( z )) /ν 1 ( z )) λ +1 ] = λ +1 X t =0 λ + 1 t ! E z ∼ ν 1 [(( ν 0 ( z ) − ν 1 ( z )) /ν 1 ( z )) t ] . (5) The first term in (5) is 1, and the second term is E z ∼ ν 1 ν 0 ( z ) − ν 1 ( z ) ν 1 ( z ) = Z ∞ −∞ ν 1 ( z ) ν 0 ( z ) − ν 1 ( z ) ν 1 ( z ) d z = Z ∞ −∞ ν 0 ( z ) d z − Z ∞ −∞ ν 1 ( z ) d z = 1 − 1 = 0 . T o prov e the lemma it suffices to sho w show that for b oth ν 0 = µ, ν 1 = µ 0 and ν 0 = µ 0 , ν 1 = µ , the third term is bounded by q 2 λ ( λ + 1) / (1 − q ) σ 2 and that this b ound dom- inates the sum of the remaining terms. W e will pro ve the more difficult second case ( ν 0 = µ 0 , ν 1 = µ ); the pro of of the other case is similar. T o upper bound the third term in (5), w e note that µ ( z ) ≥ (1 − q ) µ 0 ( z ), and write E z ∼ µ " µ 0 ( z ) − µ ( z ) µ ( z ) 2 # = q 2 E z ∼ µ " µ 0 ( z ) − µ 1 ( z ) µ ( z ) 2 # = q 2 Z ∞ −∞ ( µ 0 ( z ) − µ 1 ( z )) 2 µ ( z ) d z ≤ q 2 1 − q Z ∞ −∞ ( µ 0 ( z ) − µ 1 ( z )) 2 µ 0 ( z ) d z = q 2 1 − q E z ∼ µ 0 " µ 0 ( z ) − µ 1 ( z ) µ 0 ( z ) 2 # . An easy fact is that for any a ∈ R , E z ∼ µ 0 exp(2 az / 2 σ 2 ) = exp( a 2 / 2 σ 2 ). Thus, E z ∼ µ 0 " µ 0 ( z ) − µ 1 ( z ) µ 0 ( z ) 2 # = E z ∼ µ 0 " 1 − exp( 2 z − 1 2 σ 2 ) 2 # = 1 − 2 E z ∼ µ 0 exp( 2 z − 1 2 σ 2 ) + E z ∼ µ 0 exp( 4 z − 2 2 σ 2 ) = 1 − 2 exp 1 2 σ 2 · exp − 1 2 σ 2 + exp 4 2 σ 2 · exp − 2 2 σ 2 = exp(1 /σ 2 ) − 1 . Th us the third term in the binomial expansion (5) 1 + λ 2 ! E z ∈ µ " µ 0 ( z ) − µ ( z ) µ ( z ) 2 # ≤ λ ( λ + 1) q 2 (1 − q ) σ 2 . T o b ound the remaining terms, we first note that b y stan- dard calculus, w e get: ∀ z ≤ 0 : | µ 0 ( z ) − µ 1 ( z ) | ≤ − ( z − 1) µ 0 ( z ) /σ 2 , ∀ z ≥ 1 : | µ 0 ( z ) − µ 1 ( z ) | ≤ z µ 1 ( z ) /σ 2 , ∀ 0 ≤ z ≤ 1 : | µ 0 ( z ) − µ 1 ( z ) | ≤ µ 0 ( z )(exp(1 / 2 σ 2 ) − 1) ≤ µ 0 ( z ) /σ 2 . W e can then write E z ∼ µ " µ 0 ( z ) − µ ( z ) µ ( z ) t # ≤ Z 0 −∞ µ ( z ) µ 0 ( z ) − µ ( z ) µ ( z ) t d z + Z 1 0 µ ( z ) µ 0 ( z ) − µ ( z ) µ ( z ) t d z + Z ∞ 1 µ ( z ) µ 0 ( z ) − µ ( z ) µ ( z ) t d z . W e consider these terms individually . W e rep eatedly make use of three observ ations: (1) µ 0 − µ = q ( µ 0 − µ 1 ), (2) µ ≥ (1 − q ) µ 0 , and (3) E µ 0 [ | z | t ] ≤ σ t ( t − 1)!!. The first term can then be bounded by q t (1 − q ) t − 1 σ 2 t Z 0 −∞ µ 0 ( z ) | z − 1 | t d z ≤ (2 q ) t ( t − 1)!! 2(1 − q ) t − 1 σ t . The second term is at most q t (1 − q ) t Z 1 0 µ ( z ) µ 0 ( z ) − µ 1 ( z ) µ 0 ( z ) t d z ≤ q t (1 − q ) t Z 1 0 µ ( z ) 1 σ 2 t d z ≤ q t (1 − q ) t σ 2 t . Similarly , the third term is at most q t (1 − q ) t − 1 σ 2 t Z ∞ 1 µ 0 ( z ) z µ 1 ( z ) µ 0 ( z ) t d z ≤ q t (1 − q ) t − 1 σ 2 t Z ∞ 1 µ 0 ( z ) exp((2 tz − t ) / 2 σ 2 ) z t d z ≤ q t exp(( t 2 − t ) / 2 σ 2 ) (1 − q ) t − 1 σ 2 t Z ∞ 0 µ 0 ( z − t ) z t d z ≤ (2 q ) t exp(( t 2 − t ) / 2 σ 2 )( σ t ( t − 1)!! + t t ) 2(1 − q ) t − 1 σ 2 t . Under the assumptions on q , σ , and λ , it is easy to c heck that the three terms, and their sum, drop off geometrically fast in t for t > 3. Hence the binomial expansion (5) is dominated by the t = 3 term, which is O ( q 3 λ 3 /σ 3 ). The claim follo ws. T o deriv e Theorem 1, we use the abov e momen ts b ound along with the tail bound from Theorem 2, optimizing ov er the c hoice of λ . Theorem 1. Ther e exist c onstants c 1 and c 2 so that given the sampling pr ob ability q = L/ N and the numb er of steps T , for any ε < c 1 q 2 T , Algorithm 1 is ( ε, δ ) -differ ential ly private for any δ > 0 if we cho ose σ ≥ c 2 q p T log (1 /δ ) ε . Proof. Assume for now that σ , λ satisfy the conditions in Lemma 3. By Theorem 2.1 and Lemma 3, the log mo- men t of Algorithm 1 can b e b ounded as follo ws α ( λ ) ≤ T q 2 λ 2 /σ 2 . By Theorem 2, to guarantee Algorithm 1 to b e ( ε, δ )-differen tially priv ate, it suffices that T q 2 λ 2 /σ 2 ≤ λε/ 2 , exp( − λε/ 2) ≤ δ . In addition, w e need λ ≤ σ 2 log(1 /q σ ) . It is no w easy to verify that when ε = c 1 q 2 T , we can satisfy all these conditions b y setting σ = c 2 q p T log (1 /δ ) ε for some explicit constan ts c 1 and c 2 . C. FR OM DIFFERENTIAL PRIV A CY TO MO- MENTS BOUNDS One can also translate a differen tial priv acy guaran tee into a momen t bound. Lemma C.1. L et M b e ε -differ ential ly private. Then for any λ > 0 , M satisfies α λ ≤ λε ( e ε − 1) + λ 2 ε 2 e 2 ε / 2 . Proof. Let Z denote the random v ariable c ( M ( d )). Then differen tial priv acy implies that • µ ∆ = E [ Z ] ≤ ε (exp( ε ) − 1). • | Z | ≤ ε , so that | Z − µ | ≤ ε exp( ε ). Then E [exp( λZ )] = exp( λµ ) · E [exp( λ ( Z − µ ))]. Since Z is in a b ounded range [ − ε exp( ε ) , ε exp( ε )] and f ( x ) = exp( λx ) is con vex, w e can b ound f ( x ) by a linear in terpolation betw een the v alues at the t w o endp oin ts of the range. Basic calculus then implies that E [ f ( Z )] ≤ f ( E [ Z ]) · exp( λ 2 ε 2 exp(2 ε ) / 2) , whic h concludes the proof. Lemma C.1 and Theorem 2 give a wa y of getting a comp o- sition theorem for differentially priv ate mechanisms, which is roughly equiv alent to unrolling the pro of of the strong composition theorem of [22]. The p o wer of the momen ts ac- coun tant comes from the fact that, for many mechanisms of c hoice, directly b ound ing in the moments giv es a stronger guaran tee than one w ould get by establishing differential priv acy and applying Lemma C.1. D. HYPERP ARAMETER SEARCH Here we state Theorem 10.2 from [27] that we use to ac- coun t for the cost of h yperparameter search. Theorem D.1 (Gupt a et al. [27]). L et M b e an ε - differ ential ly private mechanis m such that for a query func- tion q with sensitivity 1, and a p ar ameter Q , it holds that Pr r ∼ M ( d ) [ q ( d, r ) ≥ Q ] ≥ p for some p ∈ (0 , 1) . Then for any δ > 0 and any ε 0 ∈ (0 , 1 2 ) , ther e is a me chanism M 0 which satisfies the fol lowing pr op erties: • Pr r ∼ M 0 ( d ) h q ( d, r ) ≥ Q − 4 ε 0 log( 1 ε 0 δp ) i ≥ 1 − δ . • M 0 makes ( 1 ε 0 δp ) 2 log( 1 ε 0 δp ) calls to M . • M 0 is ( ε + 8 ε 0 ) -differ ential ly private. Suppose that we ha ve a differen tially priv ate mec hanism M i for each of K c hoices of h yp erparameters. Let ˜ M be the mec hanism that picks a random choice of hyperparameters, and runs the corresp onding M i . Let q ( d, r ) denote the n um- ber of examples from the v alidation set the r lab els correctly , and let Q be a target accuracy . Assuming that one of the h yperparameter settings gets accuracy at least Q , ˜ M satis- fies the pre-conditions of the theorem for p = 1 K . Then with high probability , the mec hanism implied b y the theorem gets accuracy close to Q . W e remark that the pro of of Theo- rem D.1 actually implies a stronger max( ε, 8 ε 0 )-differen tial priv acy for the setting of in terest here. Putting in some num b ers, for a target accuracy of 95% on a v alidation set of size 10,000, we get Q = 9 , 500. Thus, if, for instance, w e allo w ε 0 = 0 . 5, and δ = 0 . 05, w e lose at most 1% in accuracy as long as 100 > 8 ln 40 p . This is satisfied as long as p ≥ 1 6700 . In other words, one can try 6,700 different parameter settings at priv acy cost ε = 4 for the v alidation set. In our exp erimen ts, we tried no more than a h undred settings, so that this b ound is easily satisfied. In practice, as our graphs show, p for our hyperparameter search is sig- nifican tly larger than 1 K , so that a sligh tly smaller ε 0 should suffice.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment