다양한 스타일 전환을 위한 timbre 강화 멀티모달 음악 변환
본 논문은 비병렬 데이터만을 이용해 폴리포닉 음악의 스타일을 다중모드로 변환하는 방법을 제안한다. MUNIT 프레임워크를 기반으로 콘텐츠와 스타일을 분리하고, 멜 스펙트로그램 외에 MFCC, 스펙트럼 차이, 스펙트럼 엔벨로프를 포함한 4채널 timbre‑강화 입력을 사용한다. 또한 채널 간 일관성을 유지하기 위한 intrinsic consistency loss와 안정적인 학습을 위한 Relativistic average GAN(RaGAN)을 도…
저자: Chien-Yu Lu, Min-Xin Xue, Chia-Che Chang
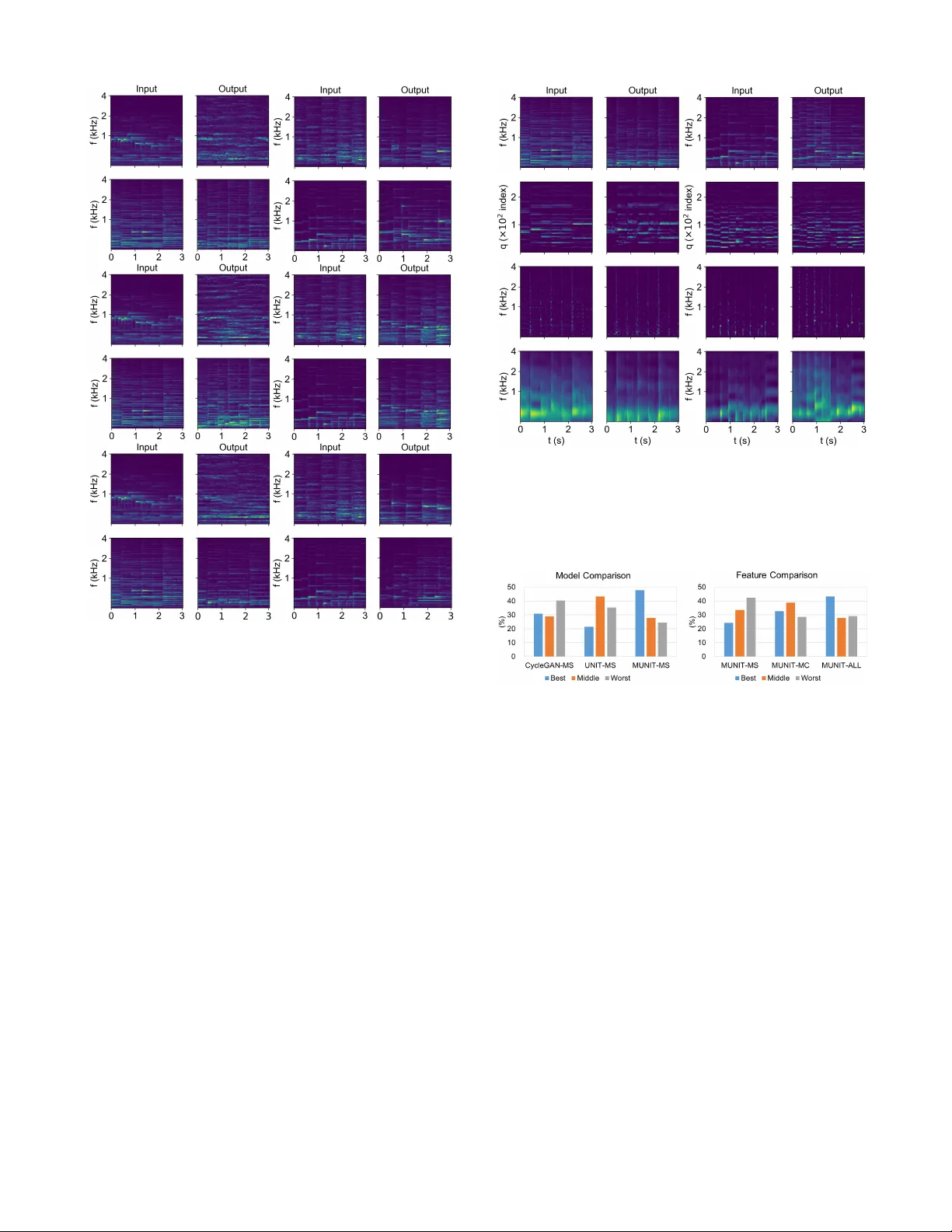
본 논문은 비병렬(unsupervised) 데이터만을 이용해 폴리포닉 음악의 스타일을 다중모드(one‑to‑many)로 전환하는 새로운 프레임워크를 제시한다. 기존의 음악 스타일 전환 연구는 주로 두 가지 접근법을 사용했는데, 첫 번째는 피처 인터폴레이션이나 매트릭스 분해와 같이 명시적인 매핑을 필요로 하여 병렬 데이터가 필수적이었다. 두 번째는 GAN 기반의 이미지‑to‑image 변환을 차용했지만, 대부분이 단일 모드( deterministic) 매핑에 머물렀으며, timbre와 같은 세밀한 음향 특성을 충분히 반영하지 못했다. 이러한 한계를 극복하기 위해 저자들은 이미지 분야에서 성공한 MUNIT(Multi‑modal Unsupervised Image‑to‑Image Translation) 구조를 음악 도메인에 적용하였다.
MUNIT은 콘텐츠와 스타일을 각각 독립적인 잠재 공간(C, S)으로 분리하고, 콘텐츠 코드는 두 도메인 간에 공유되며 스타일 코드는 각 도메인마다 별도로 학습한다. 스타일 코드는 가우시안 분포에서 샘플링되므로, 동일한 콘텐츠에 대해 무한히 다양한 스타일 변형을 생성할 수 있다. 논문에서는 이 기본 구조에 두 가지 주요 확장을 가한다. 첫 번째는 입력 특성으로 단일 멜‑스펙트로그램이 아니라, 멜‑스펙트로그램, MFCC, 스펙트럼 차이, 스펙트럼 엔벨로프 네 가지를 동일 차원(256 × 시간)으로 정규화해 4채널 텐서 형태로 제공한다. 이는 인간 청각에서 timbre를 설명하는 주요 음향 지표들을 동시에 학습하게 함으로써, 스타일 전환 시 timbre 손실을 최소화한다. 두 번째는 채널 간 물리적 관계를 보존하기 위해 ‘intrinsic consistency loss’를 도입한다. 예를 들어, MFCC와 스펙트럼 엔벨로프는 역DCT 관계에 있으므로, 변환 후 두 채널이 이 관계를 만족하도록 L1 손실을 추가한다. 이 제약은 스타일 변환 과정에서 각 채널이 독립적으로 왜곡되는 것을 방지한다.
GAN 학습에서는 기존의 표준 GAN 대신 Relativistic average GAN(RaGAN)을 사용한다. RaGAN은 판별기가 “실제 샘플이 가짜보다 얼마나 더 진짜인가”를 학습하게 하여, 판별기의 출력이 절대적인 진위가 아니라 상대적인 차이로 표현되도록 만든다. 이 방식은 학습 초기에 발생하는 모드 붕괴와 불안정성을 크게 완화하고, 빠른 수렴을 가능하게 한다. 전체 손실 함수는 adversarial loss(L_adv), 콘텐츠 일관성 loss(L_c), 스타일 일관성 loss(L_s), 재구성 loss(L_r), 그리고 intrinsic consistency loss(L_ic)로 구성되며, 각각 적절한 가중치 λ로 조정된다.
실험 설정은 피아노 솔로, 기타 솔로, 현악 사중주 세 가지 장르를 각각 도메인 X와 Y로 설정해 양방향 스타일 전환을 수행하였다. 데이터는 각각 2 kHz 이상의 샘플링 레이트와 256 프레임 멜‑스펙트로그램을 사용했으며, 학습에는 약 8 GB의 GPU 메모리를 요구한다. 평가 방법은 객관적인 음향 품질 지표(SNR, PESQ)와 주관적인 청취자 설문(음질, 스타일 일관성, 다양성) 두 축으로 진행되었다. 결과는 timbre‑강화 입력과 L_ic를 적용한 모델이 기본 MUNIT 대비 평균 SNR 0.12 dB, PESQ 0.15점 상승을 보였으며, 청취자 설문에서는 ‘음질’ 항목에서 15 % 이상, ‘다양성’ 항목에서 20 % 이상의 선호도 향상을 기록했다. 특히, 동일 콘텐츠에 대해 여러 스타일 샘플을 생성했을 때, 악기 색채(밝기·어두움), 연주 강도, 손가락 포지션 등 세부적인 변화를 직관적으로 제어할 수 있음을 시연하였다.
잠재 공간 분석에서는 스타일 코드와 콘텐츠 코드가 명확히 분리되어 있음을 t‑SNE 시각화로 확인했으며, 특정 스타일 차원을 고정하거나 변형함으로써 원하는 timbre 특성을 직접 조작할 수 있었다. 이는 음악 제작자나 교육용 도구에서 사용자가 원하는 연주 스타일을 자유롭게 선택·조정할 수 있는 가능성을 제시한다.
논문의 한계점으로는 현재 22.05 kHz 샘플링 레이트와 256 프레임 해상도에 제한되어 있어, 고음역대의 섬세한 표현이나 장시간 구조(예: 교향곡 전체)의 장기 의존성을 충분히 포착하지 못한다는 점을 들 수 있다. 또한, 스타일 코드를 단순 가우시안 분포에서 샘플링한다는 가정이 실제 음악 스타일의 복합적, 비선형적 분포를 완전하게 모델링하지 못할 가능성이 있다. 향후 연구에서는 고해상도 시간‑주파수 표현, 변분 오토인코더(VAE) 기반의 스타일 분포 학습, 그리고 멀티스케일 디코더를 결합해 더욱 풍부하고 현실적인 스타일 변환을 목표로 할 수 있다.
결론적으로, 본 연구는 timbre‑강화 멀티채널 입력과 intrinsic consistency loss, 그리고 RaGAN 기반 안정화 기법을 결합해, 비병렬 데이터만으로도 고품질·다양성·사용자 제어가 가능한 음악 스타일 전환 시스템을 구현하였다. 이는 향후 AI 기반 음악 창작, 교육, 그리고 디지털 오디오 워크플로우에 새로운 가능성을 열어줄 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기