Play as You Like: Timbre-enhanced Multi-modal Music Style Transfer
Style transfer of polyphonic music recordings is a challenging task when considering the modeling of diverse, imaginative, and reasonable music pieces in the style different from their original one. To achieve this, learning stable multi-modal repres…
Authors: Chien-Yu Lu, Min-Xin Xue, Chia-Che Chang
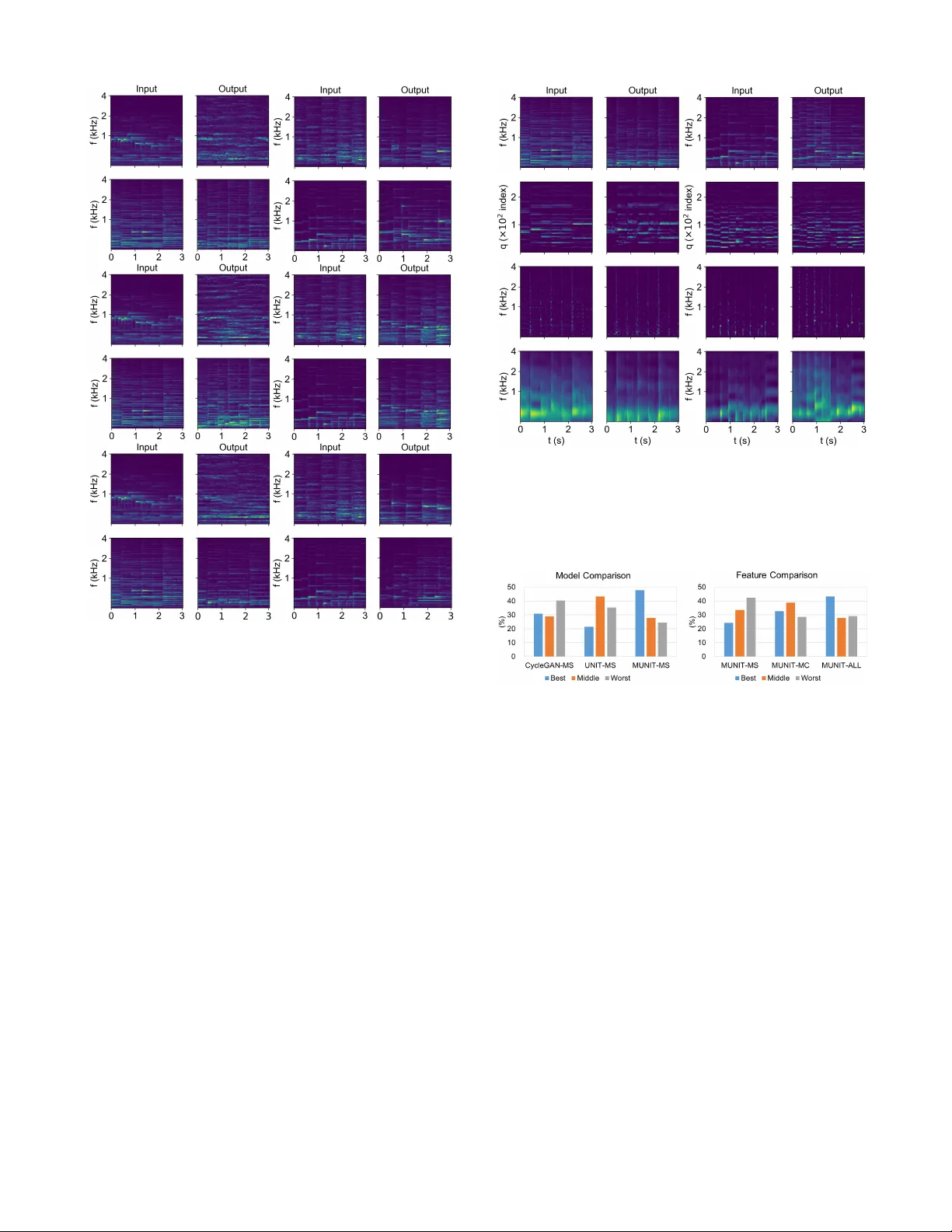
Play as Y ou Like: T imbr e-enhanced Multi-modal Music Style T ransfer Chien-Y u Lu, 1 ∗ Min-Xin Xue, 1* Chia-Che Chang, 1 Che-Rung Lee, 1 Li Su 2 1 Department of Computer Science, National Tsing-Hua Univ ersity , Hsinchu, T aiwan 2 Institute of Information Science, Academia Sinica, T aipei, T aiwan { j19550713, liedownisok, chang810249 } @gmail.com, cherung@cs.nthu.edu.tw , lisu@iis.sinica.edu.tw Abstract Style transfer of polyphonic music recordings is a challenging task when considering the modeling of div erse, imaginative, and reasonable music pieces in the style different from their original one. T o achiev e this, learning stable multi-modal rep- resentations for both domain-variant (i.e., style) and domain- in variant (i.e., content) information of music in an unsuper- vised manner is critical. In this paper, we propose an unsu- pervised music style transfer method without the need for parallel data. Besides, to characterize the multi-modal dis- tribution of music pieces, we employ the Multi-modal Un- supervised Image-to-Image T ranslation (MUNIT) framework in the proposed system. This allows one to generate diverse outputs from the learned latent distributions representing con- tents and styles. Moreover , to better capture the granularity of sound, such as the perceptual dimensions of timbre and the nuance in instrument-specific performance, cognitively plau- sible features including mel-frequency cepstral coefficients (MFCC), spectral dif ference, and spectral en velope, are com- bined with the widely-used mel-spectrogram into a timber- enhanced multi-channel input representation. The Relativistic av erage Generative Adversarial Networks (RaGAN) is also utilized to achiev e fast con vergence and high stability . W e conduct experiments on bilateral style transfer tasks among three different genres, namely piano solo, guitar solo, and string quartet. Results demonstrate the adv antages of the pro- posed method in music style transfer with improv ed sound quality and in allowing users to manipulate the output. Introduction The music style transfer problem has been receiving increas- ing attention in the past decade (Dai and Xia, 2018). When discussing this problem, typically we assume that music can be decomposed into two of its attributes, namely content and style , the former being domain-inv ariant and the latter domain-variant. This problem is therefore considered as to modify the style of a music piece while preserving its con- tent. Howe ver , the boundary that distinguishing content and style is highly dynamic; different objecti ve functions in tim- bre, performance style or composition are related to differ - ent style transfer problems (Dai and Xia, 2018). Traditional ∗ The first two authors are with equal contrib ution. Copyright c 2019, Association for the Advancement of Artificial Intelligence (www .aaai.or g). All rights reserved. style transfer methods based on feature interpolation (Cae- tano and Rodet, 2011) or matrix factorization (Driedger , Pr ¨ atzlich, and M ¨ uller, 2015; Su et al., 2017) typically need a parallel dataset containing musical notes in the target- domain style, and ev ery note has a pair in the source do- main. In other words, we need to specify the content attribute element-wisely , and make style transfer be performed in a supervised manner . Such restriction highly limits the scope that the system can be applied. T o achie ve higher -lev el map- ping across domains, recent approaches using deep learning methods such as the generativ e adversarial networks (GAN) (Goodfellow et al., 2014) allo w a system to learn the content and style attributes directly from data in an unsupervised manner with extra flexibility in mining the attributes rele- vant to content or style (Ulyanov and Lebede v , 2016; Bohan, 2017; W u et al., 2018; V erma and Smith, 2018; Haque, Guo, and V erma, 2018; Mor et al., 2018). Beyond the problem of unsupervised domain adaptation, there are still technical barriers concerning realistic mu- sic style transfer applicable for various kinds of music. First, previous studies can still hardly achie ve multi-modal and non-deterministic mapping between different domains. Howe ver , when we transfer a piano solo piece into guitar solo, we often e xpect the outcome of the guitar solo to be adjustable , perhaps with various fingering styles, brightness, musical texture, or other sound quality . Second, the trans- ferred music inevitably undergoes de gradation of perceptual quality such as severely distorted musical timbre; this in- dicates the need of a better representation for timbre infor- mation. Although man y acoustic correlates of timbre have been verified via psychoacoustic e xperiments (Grey, 1977; Alluri and T oiviainen, 2010; Caclin et al., 2005) and also been used in music information retrie val (Lartillot, T oivi- ainen, and Eerola, 2008; Peeters et al., 2011), they are rarely discussed in deep-learning-based music style transfer prob- lems. This might be because of sev eral reasons: some acous- tic correlates are incompatible to the format of modern deep learning architectures; rawer data inputs such as wav eforms and spectrograms are still preferred to rev eal the strength of deep learning; and ev en, an e xact theory of those acoustic correlates on human perception is still not clear in cognitiv e science (Siedenburg, Fujinaga, and McAdams, 2016; Au- couturier and Bigand, 2013). For this issue, a recently pro- posed method in (Mor et al., 2018) adopts the W aveNet (V an Den Oord et al., 2016), the state-of-the-art wa veform gener- ator on raw wa veform data to generate realistic outputs for various kinds of music with a deterministic style mapping, at the expense of massi ve computing po wer . T o address these issues, we consider the music style trans- fer problem as learning a multi-modal conditional distribu- tion of style in the target domain gi ven only one unpaired sample in the source domain. This is similar to the Multi- modal Unsupervised Image-to-Image T ranslation (MUNIT) problem, where a principled frame work proposed in (Huang et al., 2018) is employed in our system. During training, cog- nitiv ely plausible timbre features including mel-frequency cepstral coefficients (MFCC), spectral difference, and spec- tral en velope, all designed to have the same dimension with mel-spectrogram, are combined together into a multi- channel input representation in the timbre space. Since these features have close-form relationship with each other , we introduce a ne w loss function, named intrinsic consistency loss , to keep the consistency among the channel-wise fea- tures in the target domain. Experiments show that with such extra conditioning on the timbre space, the system does achiev e better performance in terms of content preservation and sound quality than those using only the spectrogram. Moreov er , comparing to other style transfer methods, the proposed multi-modal method can stably generate diverse and realistic outputs withs improved quality . Also, in the learned representations, some dimensions that disentangle timbre can be observed. Our contrib utions are two-fold: • W e propose an unsupervised multi-modal music style transfer system for one-to-man y generation. T o the best of our knowledge, this have not been done before in music style transfer . The proposed system further allo ws music style transfer from scratch, without massive training data. • W e design multi-channel timbre features with the pro- posed intrinsic consistency loss to improv e the sound quality for better listening experience of the style- transferred music. Disentanglement of timbre character- istics in the encoded latent space is also observed. Related W orks Generative Adversarial Networks Since its inv ention in (Goodfellow et al., 2014), the GAN has shown amazing results in multimedia content generation in variant domains (Y u et al., 2017; Gw ak et al., 2017; Li et al., 2017). A GAN comprises tw o core components, namely the generator and the discriminator . The task of the generator is to fool the discriminator , which distinguishes real samples from generated sample. This loss function, named adversar - ial loss , is therefore implicit and is defined only by the data. Such a property is particularly powerful for generation tasks. Domain Adaptation Recent years has witnessed considerable success in un- supervised domain adaptation problems without parallel data, such as image colorization (Larsson, Maire, and Shakhnarovich, 2016; Zhang, Isola, and Efros, 2016) and image enhancement (Chen et al., 2018). T wo of the most popular methods that achieve unpaired domain adaptation could be the CycleGAN (Zhu et al., 2017a) and the Unsuper- vised Image-to-Image T ranslation Networks (UNIT) (Liu, Breuel, and Kautz, 2017) frame work, the former introduce the cycle consistency loss to train with unpaired data and the other is to learn a joint distrib ution of images in different domains. Ho wev er , most of these transfer models are based on a deterministic or one-to-one mapping. Therefore, these models are unable to generate di verse outputs when given the data from source domain. One of the earliest attempts on multi-modal unsupervised translation could be (Zhu et al., 2017b), which aims at capturing the distribution of all possible outputs, that means, a one-to-many mapping that maps a single input into multiple outputs. T o handle multi- modal translation, two possible methods are: adding random noise to the generator , or adding dropout layer into the gen- erator for capturing the distribution of outputs. Ho wev er , these methods still tend to generate similar outputs since the generator is easy to ignoring random noise and addi- tional dropout layers. In this paper, we use a disentangled representation frame work, MUNIT (Huang et al., 2018), for generating high-quality and high-div ersity music pieces with unpaired training data. Music Style T ransfer The music style transfer problem has been inv estigated for decades. Broadly speaking, the music being transferred can be either audio signals or symbolic scores (Dai and Xia, 2018). In this paper, we focus on the music style transfer of audio signals, where its domain-in variant content typi- cally refer to the structure established by the composer (e.g., mode, pitch, or dissonance) 1 , and its domain-variant style refers to the interpretation of the performer (e.g., timbre, playing styles, expression). W ith such ab undant implications of content and style, the music style transfer problem encompasses extensi ve ap- plication scenarios, including audio mosaicking (Driedger , Pr ¨ atzlich, and M ¨ uller, 2015), audio antiquing (V ¨ alim ¨ aki et al., 2008; Su et al., 2017), and singing v oice con version (K obayashi et al., 2014; W u et al., 2018), to name but a few . Recently , moti vated by the success of image style trans- fer (Gatys, Ecker , and Bethge, 2016), using deep learn- ing for music or speech style transfer on audio signals has caught wide attention. These solutions can be roughly cate- gorized into two classes. The first class takes spectrogram as input and feeds it into conv olutional neural networks (CNN), recurrent neural networks (RNN), GAN or autoen- coder (Haque, Guo, and V erma, 2018; Donahue, McAuley , and Puckette, 2018). Cycle consistency loss has also been applied for such features (W u et al., 2018; Hosseini-Asl et al., 2018). The second class takes raw waveform as input and feed it into autoregressiv e models such as W aveNet (Mor et al., 2018). Unlike the classical approaches, the deep learning approaches pay less attention to the lev el of signal process- 1 Although the instrumentation process is usually done by the composer , especially in W estern classical music, we presume that the timbre (i.e., the instrument chosen for performance) is deter- mined by the performer . ing, and tends to overlook timbre-related features that are psychoacoustically meaningful in describing music styles. One notable exception is (V erma and Smith, 2018), which took the de viation of temporal and frequency energy en- velopes respectiv ely from the style audio into the loss func- tion of the network, and demonstrated promising results. Data Representation W e discuss the audio features before introducing the whole framew ork of the proposed system. W e set two criteria of choosing features for our system input. First, all the features can be of the same dimension, so as to facilitate a CNN- based multi-channel architecture, where one feature occupy one input channel. In other words, the channel-wise features represent the colors of sound; this is similar to the case of image processing, where three colors (i.e., R, G, and B) are also taken as channel-wise input. Second, the chosen fea- tures should be related to music perception or music signal synthesis. The features verified to be highly correlated to one or more attributes of musical timbre through perceptual ex- periments are preferred more. As a result, we consider the following four data representations: 1) mel-spectrogram, 2) mel-frequency cepstral coef ficients (MFCC), 3) spectral dif- ference, and 4) spectral en velope. Consider an input signal x := x [ n ] where n is the index of time. Giv e a N -point window function h for the compu- tation of the short-time Fourier transform (STFT): X [ k , n ] := N − 1 X m =0 x [ m + nH ] h [ m ] e − j 2 πkm N . (1) where k is the frequency index. The sampling rate is f s = 22 . 05 kHz. W e consider the power spectr ogram of x be- ing the γ -power of the magnitude part of the STFT , namely | X | γ . In this paper we set γ = 0 . 6 , a v alue that well approx- imate the perceptual scale based on the Stev ens power law (Stev ens, 1957). The mel-spectrogram ¯ X [ f , n ] := M | X | γ is the power spectrogram mapped into the mel-frequency scale with a filterbank. The filterbank M has 256 over - lapped triangular filters ranging from zero to 11.025 kHz, and the filters are equally-spaced in the mel scale: mel := 2595 log 10 ( f / 700 + 1) . MFCC is represented as the discrete cosine transform (DCT) of the mel-spectrum: C [ q , n ] := F − 1 X f =0 ˜ X [ f , n ] cos π N f + 1 2 q . (2) where q is the cepstral index and F = 256 is the number of frequency bands. The MFCC has been one of the most widely used audio feature ranging from a wide div ersity of tasks including speech recognition, speaker identification, music classification, and many others. Traditionally , only the first few coefficients of the MFCC are used, as these co- efficients are found relev ant to timbre-related information. High-quefrency coef ficients are then related to pitch. In this work, we adopt all coef ficients for end-to-end training. The spectr al dif fer ence is a classic feature for musical on- set detection and timbre classification. It is highly relev ant to the attack in the attack-decay-sustain-release (ADSR) en- velope of a note. The spectral dif ference is represented as ∆ ˜ X [ f , n ] := ReLU( ˜ X [ f , n + 1] − ˜ X [ f , n ]) (3) where ReLU refers to a rectified linear unit that discards the energy-decreasing parts in the time-frequency plane. The ac- cumulation of spectral difference ov er the frequency axis is the well-known spectr al flux for musical onset detection. The spectral en velope Y can be loosely estimated through the in verse DCT of the first η elements of the MFCC, which represents the slow-v arying counterpart in the spectrum: Y [ f , n ] := η X q =0 C [ q , n ] cos π N q + 1 2 f , (4) where η is the cutof f cepstral index . In this paper we set η = 15 . The spectral en velope has been a well-known factor in timbre and is widely used in sound synthesis []. These data representations emphasize dif ferent aspects of timbre, and at the same time able to act as a channel for joint learning. Proposed Method Consider the style transfer problem from two domains X and Y . x ∈ X and y ∈ Y are two samples from X and Y , respectiv ely . Assume that the latent spaces of the two do- mains are partially shared: each x is generated by a con- tent code c ∈ C shared by both domains and a style code s ∈ S in the individual domain. Inferring the marginal dis- tributions of c and s , namely p ( c ) and p ( s ) , respectively , therefore allows one to achiev e one-to-many mapping be- tween X and Y . This idea was first proposed in the MUNIT framew ork (Huang et al., 2018). T o further improv e its per- formance and to adapt to our problem formulation, we make two extensions. First, to stabilize the generation result and speed up the conv ergence rate, we adopt the Relativistic av- erage GAN (RaGAN) (Jolicoeur-Martineau, 2018) instead of the for the con ventional GAN component for generation. Second, considering the relation between the channel-wise timbre features, we introduce the intrinsic consistency loss to pertain the relation between the output features. Overview Fig. 1 conceptually illustrates the whole multi-mdoal music style transfer architecture. It contains encoders E and gen- erators G for domains X and Y , namely E X , E Y , G X , and G Y . 2 E encodes a music piece into a style code s and a content code c . G decodes c and s into the transferred re- sult, where c and G are from different domains and s in the tar get domain is sampled from a Gaussian distribution z ∈ N (0 , 1) . For example, the process v = G Y ( c x , s y ) where s y ∈ N (0 , 1) transfer x in domain X to v in domain Y . Similarly , the process transferring y in domain Y to u in domain X is also shown in Fig. 1. The system has two main netw orks, cross-domain transla- tion and within-domain reconstruction, as shown in the left 2 Since the transfer task is bilateral, we will ignore the subscript if we do not specifically mention X or Y domains. F or example, G refers to either G X or G Y Figure 1: The proposed multi-modal music style transfer system with intrinsic consistency regularization L ic . Left: cross- domain architecture. Right: self-reconstruction. and the right of Fig. 1, respecti vely . The cross-domain trans- lation network uses GANs to match the distribution of the transferred features to the distribution of the features in the target domain. It means, discriminators D should distinguish the transferred samples from the ones truly in the target do- main, and G needs to fool D by capturing the distrib ution of the target domain. By adopting the Chi-Square loss (Mao et al., 2017) in the GANs, the resulting adversarial loss, L adv , is represented as: L adv = L x adv + L y adv = E c y ∼ p ( c y ) ,z ∼N [( D X ( G X ( c y , z ))) 2 ] + E x [( D X ( x ) − 1) 2 ] + E c x ∼ p ( c x ) ,z ∼N [( D Y ( G Y ( c x , z )) 2 ] + E y [( D Y ( y ) − 1) 2 ] , (5) where p ( c y ) is a marginal distribution from which c y is sampled. Besides, we expect that the content code of a gi ven sample should remain the same after cross-domain style transfer . This is done by minimizing the content loss ( L c ): L c = L c x + L c y = | c y − ˆ c x | 1 + | c x − ˆ c y | 1 , (6) where | · | is the l 1 -norm, c y ( c x ) is the content code be- fore style transfer , and ˆ c x ( ˆ c y ) is the content code after style transfer . Similarly , we also expect the style code of the trans- ferred result to be the same as the one sampled before style transfer . This is done by minimizing the style loss L s : L s = L s x + L s y = | z x − ˆ s x | 1 + | z y − ˆ s y | 1 , (7) where ˆ s x and ˆ s y are the transferred style codes, and z x and z y are two input style codes sampled from N (0 , 1) . Finally , the system also incorporates self-reconstruction mechanism, as shown in the right of Fig. 1. For example, G X should be able to reconstruct x from the latent codes ( c x , s x ) that E X encodes. The reconstruction loss is L r = L x r + L y r = | x − ˆ x | 1 + | y − ˆ y | 1 , (8) where ˆ x and ˆ y are the reconstructed features of x and y , respectiv ely . RaGAN One of our goals is to translate music pieces into the target domain with improved sound quality . T o do this, we adopt the recently-proposed Relati vistic av erage GAN (RaGAN) (Jolicoeur-Martineau, 2018) as our GAN training methodol- ogy to generate high quality and stable outputs. RaGAN is different from other GAN architectures in that in the training stage, the generator not only captures the distrib ution of real data, but also decreases the probability that real data is real. The RaGAN discriminator is designed as D ( x ) = σ ( Q ( x ) − E x f ∼ Q Q ( x f )) if x is real , σ ( Q ( x ) − E x r ∼ P Q ( x r )) if x is fake , (9) where σ ( · ) is the sigmoid function, Q is the layer before the sigmoid output layer of the discriminator, and x is the input data. P is the distribution of real data, Q is the distrib ution of fake data. x r and x f denote real and fake data, respecti vely . Intrinsic Consistency Loss T o achieve one-to-man y mapping, the MUNIT framew ork deprecates the cycle consistency loss that is only applica- ble in one-to-one settings. W e needs extra ways to guaran- tee the robustness of the transferred features. By noticing that the multi-channel features are all deriv ed from the mel- spectrogram with closed forms, we propose a new regular- ization term to guide the transferred features to be with the same closed-form relation. In other words, the intrinsic rela- tions among the channels should remain the same after style transfer . First, the MFCC channel should remain the DCT of the mel-spectrogram: L MFCC = L MFCC u + L MFCC v = | u MFCC − DCT( u ms ) | 1 + | v MFCC − DCT( v ms ) | 1 . (10) where u MFCC is the transferred MFCC and u ms is the trans- ferred mel-spectrogram. Similar loss functions can also be Figure 2: Illustration of pre-processing and post processing on audio signals. The power -scale spectrogram and the phase spectrogram Φ are deriv ed from the short-time Fourier transform X . T o reconstruct the generated mel-spectrogram u ms , the NNLS optimization and the original phase spectrogram Φ are used to get a stable reconstructed signal via the ISTFT . designed for spectral difference and spectral en velope: L ∆ = L u ∆ + L v ∆ = | u ∆ − ∆ u ms | 1 + | v ∆ − ∆ v ms | 1 . (11) L env = L u env + L v env = | u env − IDCT(DCT( u ms ) : η ) | 1 + | v env − IDCT(DCT( v ms ) : η ) | 1 . (12) That means, the transferred spectral difference (e.g., u ∆ ) should remain as the spectral difference of the transferred mel-spectrogram (e.g., ∆ u ms ). The case of spectral env e- lope is also similar . The total intrinsic consistency loss is L ic = λ MFCC L MFCC + λ ∆ L ∆ + λ env L env , (13) and the full objectiv e function L of our model is min E X ,E Y ,G X ,G Y max D X ,D Y L ( E x , E y , G x , G y , D x , D y ) = L adv + λ c L c + λ s L s + λ r L r + L ic , (14) where λ adv , λ S and λ recon are hyper-parameters to recon- struction loss. Signal Reconstruction The style-transferred music signal is reconstructed from the mel-spectrogram and the phase spectrogram Φ of the input signal. This is done in the follo wing steps. First, since the mel-spectrogram ¯ X is nonnegati ve, we can con vert it back to a linear-frequenc y spectrogram through the mel-filterbank M using the nonnegati ve least square (NNLS) optimization: X ∗ = arg min X k ¯ X − MX k 2 2 subject to X 0 . (15) The resulting magnitude spectrum is therefore ˆ X := X ∗ (1 /γ ) . Then, the complex-v alued time-frequency rep- resentation ˆ X e j Φ is processed by the in verse short-time Fourier transform (ISTFT), and the final audio is obtained. The process dealing with wa veforms is illustrated in Fig. 2. Implementation details The adopted networks are mostly based on the MUNIT im- plementation except for the RaGAN in adversarial training. The model is optimized by adam, with the batch size being one, and with the learning rate and weight decay rate being both 0.0001. The regularization parameters in (13) and (14) are: λ r = 10 , λ s = λ c = 1 , and λ MFCC = λ ∆ = λ env = 1 . The sampling rate of music signals is f s = 22 . 05 kHz. The window size and hop size for STFT are 2048 and 256 sam- ples, respectiv ely . The dimension of the style code is 8. Experiment and Results In the experiments, we consider two music style transfer tasks using the following e xperimental data: 1. Bilateral style transfer between classical piano solo (Noc- turne Complete W orks performed by Vladimir Ashke- nazy) and classical string quartet (Bruch’ s Complete String Quartet). 2. Bilateral style transfer between popular piano solo and popular guitar solo (data of both domains consists in 34 piano solos (8,200 seconds) and 56 guitar solos (7,800 seconds) covered by the pianists and guitarists on Y ouT ube. Please see supplementary materials for details). In brief, there are four subtasks in total: piano to guitar (P2G), guitar to piano (G2P), piano to string quartet (P2S), and string quartet to piano (S2P). For each subtask, we ev aluate the proposed system in tw o stages, the first being the comparison to baseline models and the second the comparison to baseline features. For the two baseline models, we consider CycleGAN (Zhu et al., 2017a) and UNIT (Liu, Breuel, and Kautz, 2017), which are both competiti ve unsupervised style transfer netw orks. Note that the two baseline models allow only one-to-one map- ping. F or the features, we consider using mel-spectrogram only (MS), mel-spectrogram and MFCC (MC), and all four features (ALL). For simplicity , we do not exhaust all possi- ble combinations of these settings. Instead, we consider the following fi ve cases: CycleGAN-MS, UNIT -MS, MUNIT - MS, MUNIT -MC, and MUNIT -ALL. These cases suffice the comparison on both feature and model. Subjectiv e tests were conducted to e valuate the style transfer system from human’ s perspectiv e. F or each sub- task, one input music clip is transferred using the above fiv e settings. CycleGAN and UNIT both generate one output sample, and for MUNIT -based methods, we randomly select three style codes in the target domain and obtain three output samples. This results in a huge amount of listening samples, so we split the test into six different questionnaires, three of them comparing models and the other three three comparing features. By doing so, only one out of the three MUNIT - based output needs to be selected in a questionnaire. A par- ticipant only needs to complete one randomly selected ques- tionnaire to finish one subjectiv e test. In each round, a subject first listens to the original music clip, then its three style-transferred versions using different models (i.e., CycleGAN, UNIT , MUNIT) or different fea- Figure 3: Comparison of the input (original) and out- put (transferred) mel-spectrograms for CycleGAN-MS (the upper two ro ws), UNIT -MS (the middle two ro ws), and MUNIT -MS (the lower tw o ro ws). The four subtasks demonstrated in every two rows are: P2S (upper left), S2P (upper right), P2G (lower left), and G2P (lo wer right). tures (i.e., MS, MC, ALL). F or each transferred version, the subject is asked to score three problems from 1 (lo w) to 5 (high). The three problems are: 1. Success in style transfer (ST): how well does the style of the transferred version match the tar get domain, 2. Content preserv ation (CP): how well does the content of the transferred version match the original v ersion, and 3. Sound quality (SQ): how good is the sound. After the scoring process, the subject is asked to choose the best and the worst version according to her/his personal view on style transfer . This part is a preference test. Subjective Evaluation T able 1 shows the Mean Opinion Scores (MOS) of the listen- ing test collected from 182 responses. First, by comparing the three models, we can see that CycleGAN performs best Figure 4: Illustration of the input (original) and output (transferred) feature using MUNIT -ALL of on P2G (the left two columns) and G2P (the right two columns). From top to bottom: mel-spectrogram, MFCC, spectral difference, and spectral en velope. Figure 5: Results of the preference test. Left: comparison of models. Right: comparison of features. The y-axis is the ratio that each setting earns the best, middle, or the worst ranking from the listeners. in content preservation after domain transfer , possibly be- cause of the strength of the cycle consistency loss in match- ing the target domain directly at the feature le vel. On the other hand, MUNIT outperforms the other two models in terms of style transfer and sound quality . Second, by comparing the features, we can see that using ALL fea- tures outperforms others by 0.1 in the a verage sound quality score. For content preserv ation and style transfer, howe ver , the number of feature is rather insensitiv e. While MUNIT - based methods get the highest scores in style transfer , which shows learning a multi-modal conditional distribution bet- ter generates realistic style-transfered output, we can’t see the relation between multi-channel features and style trans- fer quality . Howe ver , the sound quality ev aluation shows that MUNIT -ALL conducts the best sound quality . The above results indicate an unsurprising trade-off be- tween style transfer and content preservation. The ov er- T able 1: The mean opinion score (MOS) of various style transfer tasks and settings. From top to bottom: CycleGAN-MS, UNIT -MS, MUNIT -MS, MUNIT -MC, MUNIT -ALL. See the supplementary material for details about the details of ev aluation. T ask P2G G2P P2S S2P A verage Model Feature ST CP SQ ST CP SQ ST CP SQ ST CP SQ ST CP SQ CycleGAN MS 2.89 4.27 2.56 2.66 4.17 2.57 2.85 3.51 2.33 3.21 4.01 3.10 2.90 3.99 2.64 UNIT MS 2.85 4.07 2.80 2.57 3.83 2.20 2.83 3.62 2.28 3.39 3.90 2.88 2.91 3.85 2.54 MUNIT MS 2.97 3.98 2.64 3.06 3.91 2.48 2.88 3.45 2.43 3.55 3.56 2.88 3.12 3.72 2.61 MUNIT MC 3.30 4.07 3.14 2.80 3.56 2.42 2.77 3.32 2.27 3.47 3.44 2.92 3.09 3.60 2.69 MUNIT ALL 3.55 4.12 3.13 2.95 4.02 2.97 2.12 3.11 1.93 3.76 3.70 3.25 3.09 3.74 2.82 Figure 6: Con verted mel-spectrograms from a piano music clip in the P2G task with the 6th dimension of the sampled style code varying from -3 to 3. The horizontal axis refers to time. Audio samples are a vailable in the supplementary material. all ev aluation of listeners’ preference on those music style transfer systems could be better seen from the preference test result. The results are shown in Fig. 5. For the compar- ison of models, up to 48% of listeners view MUNIT -MS as the best, and only 24% of listeners views it as the worst. On the other side, CycleGAN-MS gets the most “worst” votes and MNUIT -MS gets the least. For the comparison of fea- tures, 43% of the listeners vie w MUNIT -ALL as the best, and at the same time 42% of the listeners view MUNIT -MS as the w orst. These results demonstrate the superiority of the proposed method ov er other baselines. Illustration of Examples Fig. 3 compares the input and output mel-spectrograms among different models and tasks. From t he illustrations one may observe that all the models generate some characteris- tics related to the target domain. For example, we observe that in the P2S task, there are vibrato notes in the output, and in the P2G task, the high-frequency components are sup- pressed. More detailed feature characteristics can be seen in Fig. 4 where all the four features in an P2G task are shown. For the output in guitar solo style, one may further observe longer note attacks shown in the spectral difference, and less high-frequency parts in spectral en velope, both of which are indeed characteristics of guitar . Style Code Interpolation W e then in vestigate ho w a specific dimension of the style code can affect the generation result. Fig. 6 shows a series of P2G examples with interpolated style codes. For a se- lected style code z ∈ N (0 , 1) , we linearly interpolate the 6th dimension of z , z [6] , with a value from -3 to 3, and gen- erate a series of music pieces based on these modified style code. Interestingly , results show that when z [6] increases, the high-frequency parts decreases. In this case, z [6] can be related to some timbre features such as spectral centr oid or brightness . This phenomena indicates that some of the style code elements do disentangle the characteristics of timbre. Conclusion W e ha ve presented a nov el method to transfer a music pieces into multiple pieces in another style. W e ha ve shown that the multi-channel features in the timbre space and the regular- ization of the intrinsic consistenc y loss among them improve the sound quality of the transferred music pieces. The multi- modal frame work also match the target domain distribution better than previous approaches. In comparison to other style transfer methods, our proposed method is one-to-many , sta- ble, and without the need of paired data and pre-trained model. The learned representation of style is also adjustable. These findings suggest further studies on disentangling tim- bre characteristics, utilizing the findings from psychoacous- tics on the perceptual dimension of music styles, and the speeding up of the music style transfer system. Codes and listening examples of this work are announced on- line at: https://github .com/ChienY uLu/Play-As-Y ou-Lik e- T imbre-Enhanced-Multi-modal-Music-Style-T ransfer References Alluri, V ., and T oiviainen, P . 2010. Exploring perceptual and acoustical correlates of polyphonic timbre. Music P er cep- tion: An Inter disciplinary Journal 27(3):223–242. Aucouturier , J.-J., and Bigand, E. 2013. Sev en problems that keep mir from attracting the interest of cognition and neuroscience. J ournal of Intelligent Information Systems 41(3):483–497. Bohan, O. B. 2017. Singing style transfer . http://madebyoll.in/posts/singing_ style_transfer/ . Caclin, A.; McAdams, S.; Smith, B. K.; and W insberg, S. 2005. Acoustic correlates of timbre space dimensions: A confirmatory study using synthetic tones. The Journal of the Acoustical Society of America 118(1):471–482. Caetano, M. F ., and Rodet, X. 2011. Sound morphing by feature interpolation. In Pr oc. IEEE ICASSP , 22–27. Chen, Y .-S.; W ang, Y .-C.; Kao, M.-H.; and Chuang, Y .-Y . 2018. Deep photo enhancer: Unpaired learning for im- age enhancement from photographs with gans. In CVPR , 6306–6314. Dai, S., and Xia, G. 2018. Music style transfer issues: A position paper . In the 6th International W orkshop on Mu- sical Metacr eation (MUME) . Donahue, C.; McAuley , J.; and Puckette, M. 2018. Synthe- sizing audio with generative adversarial networks. arXiv pr eprint arXiv:1802.04208 . Driedger , J.; Pr ¨ atzlich, T .; and M ¨ uller , M. 2015. Let it bee- tow ards nmf-inspired audio mosaicing. In ISMIR , 350– 356. Gatys, L. A.; Ecker , A. S.; and Bethge, M. 2016. Image style transfer using con volutional neural networks. In IEEE CVPR , 2414–2423. Goodfellow , I. J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; W arde-Farley , D.; Ozair , S.; Courville, A. C.; and Bengio, Y . 2014. Generativ e adversarial nets. In NIPS , 2672– 2680. Grey , J. M. 1977. Multidimensional perceptual scaling of musical timbres. the Journal of the Acoustical Society of America 61(5):1270–1277. Gwak, J.; Cho y , C. B.; Gar g, A.; Chandraker , M.; and Sav arese, S. 2017. W eakly supervised generati ve adversarial networks for 3d reconstruction. CoRR abs/1705.10904. Haque, A.; Guo, M.; and V erma, P . 2018. Con- ditional end-to-end audio transforms. arXiv preprint arXiv:1804.00047 . Hosseini-Asl, E.; Zhou, Y .; Xiong, C.; and Socher , R. 2018. A multi-discriminator cyclegan for unsupervised non-parallel speech domain adaptation. arXiv pr eprint arXiv:1804.00522 . Huang, X.; Liu, M.-Y .; Belongie, S.; and Kautz, J. 2018. Multimodal unsupervised image-to-image translation. In ECCV . Jolicoeur-Martineau, A. 2018. The relativistic discrimina- tor: a key element missing from standard GAN. CoRR abs/1807.00734. K obayashi, K.; T oda, T .; Neubig, G.; Sakti, S.; and Naka- mura, S. 2014. Statistical singing voice con version with direct wa veform modification based on the spectrum dif- ferential. In INTERSPEECH . Larsson, G.; Maire, M.; and Shakhnarovich, G. 2016. Learn- ing representations for automatic colorization. In Pr oc. ECCV , P art IV , 577–593. Lartillot, O.; T oiviainen, P .; and Eerola, T . 2008. A matlab toolbox for music information retrie val. In Data analysis, machine learning and applications . Springer . 261–268. Li, Y .; Liu, S.; Y ang, J.; and Y ang, M. 2017. Generativ e f ace completion. In CVPR , 5892–5900. Liu, M.; Breuel, T .; and Kautz, J. 2017. Unsu- pervised image-to-image translation networks. CoRR abs/1703.00848. Mao, X.; Li, Q.; Xie, H.; Lau, R. Y . K.; W ang, Z.; and Smol- ley , S. P . 2017. Least squares generativ e adversarial net- works. In ICCV , 2813–2821. Mor , N.; W olf, L.; Polyak, A.; and T aigman, Y . 2018. A univ ersal music translation network. arXiv preprint arXiv:1805.07848 . Peeters, G.; Giordano, B. L.; Susini, P .; Misdariis, N.; and McAdams, S. 2011. The timbre toolbox: Extracting au- dio descriptors from musical signals. The Journal of the Acoustical Society of America 130(5):2902–2916. Siedenbur g, K.; Fujinaga, I.; and McAdams, S. 2016. A comparison of approaches to timbre descriptors in music information retrie val and music psychology . Journal of New Music Resear ch 45(1):27–41. Stev ens, S. S. 1957. On the psychophysical law . Psycholo g- ical r evie w 64(3):153. Su, S.-Y .; Chiu, C.-K.; Su, L.; and Y ang, Y .-H. 2017. Au- tomatic conv ersion of pop music into chiptunes for 8-bit pixel art. In Pr oc. IEEE ICASSP , 411–415. IEEE. Ulyanov , D., and Lebedev , V . 2016. Singing style transfer . https://dmitryulyanov.github. io/audio- texture- synthesis- and- style- transfer/ . V ¨ alim ¨ aki, V .; Gonz ´ alez, S.; Kimmelma, O.; and Parvi- ainen, J. 2008. Digital audio antiquing-signal process- ing methods for imitating the sound quality of histori- cal recordings. Journal of the Audio Engineering Society 56(3):115–139. V an Den Oord, A.; Dieleman, S.; Zen, H.; Simonyan, K.; V inyals, O.; Grav es, A.; Kalchbrenner , N.; Senior, A. W .; and Kavukcuoglu, K. 2016. W av enet: A generativ e model for raw audio. In SSW , 125. V erma, P ., and Smith, J. O. 2018. Neural style transfer for audio spectograms. CoRR abs/1801.01589. W u, C.-W .; Liu, J.-Y .; Y ang, Y .-H.; and Jang, J.-S. R. 2018. Singing style transfer using cycle-consistent bound- ary equilibrium generativ e adversarial networks. arXiv pr eprint arXiv:1807.02254 . Y u, L.; Zhang, W .; W ang, J.; and Y u, Y . 2017. Seqgan: Sequence generativ e adversarial nets with policy gradient. In AAAI , 2852–2858. Zhang, R.; Isola, P .; and Efros, A. A. 2016. Colorful image colorization. In Pr oc. ECCV, P art III . Zhu, J.; Park, T .; Isola, P .; and Efros, A. A. 2017a. Un- paired image-to-image translation using c ycle-consistent adversarial networks. CoRR abs/1703.10593. Zhu, J.; Zhang, R.; Pathak, D.; Darrell, T .; Efros, A. A.; W ang, O.; and Shechtman, E. 2017b . T oward multimodal image-to-image translation. In NIPS , 465–476. A ppendices Experiment Data and Listening Examples The data of piano solo and guitar solo for training the style transfer models are collected from the web . For reproducibil- ity , we put the Y ouT ube link of the data we used in the ex- periments into tw o playlists. The links of the playlists are as follows: • The playlist of guitar solo is at: https://goo.gl/ zZv9SS • The playlist of piano solo is at: https://goo.gl/ VbA2rA Besides, the listening examples of the generated style- transferred audio in the four subtasks (i.e., P2G, G2P , P2S, and S2P), along with their original v ersion, are available online at https://goo.gl/BhHzec and the GitHub repository: https://github .com/ChienY uLu/Play-As-Y ou-Like-T imbre- Enhanced-Multi-modal-Music-Style-T ransfer Further Details on Subjective Evaluation In the following we report further details on the subjective ev aluation. Our subjecti ve e valuation process is completed through online questionnaires. 182 people joined our sub- ject test. 23 of them are under 20 years old, 127 of them are between 20 and 29, 21 of them are between 30 and 39, and the rest 11 ones are above 40. W e did not collect the par- ticipants’ gender information, but their background of mu- sic training: 58 of the participants reported themselves as professional musicians. W e take the responses from these 58 subjects as the responses from musicians, and other re- sponses as from non-musicians. As mentioned in the paper, we conducted two sets of experiments, one considering the comparison on models and the other on features. The former compares Cycle- MS, UNIT -MS, and MUNIT -MS, while the latter compares MUNIT -MS, MUNIT -MC, and MUNIT -ALL. That means, the setting MUNIT -MS is ev aluated in both experiments. What we reported in the paper is the av erage result of MUNIT -MS. Though merging the two MUNIT -MS results or not do not affect our conclusion of this paper , we can still see more details when reporting them separately . It is valu- able for further discussion. Based on the above reasons, in the supplementary ma- terial we further report 1) the mean opinion scores (MOS) giv en separately from musicians and non-musicians and 2) the two separated MUNIT -MS results in different scenarios of comparison, as listed in T able 2. T able 2 indicates that, first, musicians tend to rate lo wer scores than non-musicians do in answering the questions in the subjective tests. Second, for most of the questions, the best settings the musicians and non-musicians selected are consistent. F or example, in the P2G subtask, we may see from the P2G columns that both musicians and non-musicians e valuate the MUNIT model to outperform others in ST and SQ, and the CycleGAN is the best in CP . Similar observation can also be found in G2P and P2S subtasks. Second, the two MUNIT -MS results are different. More specifically , the MOS in feature comparison is lower than in the other , since MUNIT -MS is ‘relativ ely’ inferior to the other two features, and relativ ely superior to the other two models. This implies the users’ bias when comparing one setting under different scenario. Finally , there are a subtle disagreement between between musicians and non-musicians when comparing different fea- tures: on a verage, musicians tend to say MC is better than ALL in ST . This is mainly affected by the fact that musi- cians is much more sensitive than non-musicians to the low quality of the P2S results. T able 2: The mean opinion score (MOS) of various style transfer tasks, models, features (Feat), and with consideration of subjects’ background (BG). The “Y/N” on the third column represents whether the subjects report themselves as professional musicians. The upper part of the T able lists the responses of model comparisons, where we hav e 31 musicians and 59 non- musicians. On the other hand, the lo wer part collects the responses of feature comparisons, where we ha ve 27 musicians and 65 non-musicians. Therefore, we have tw o sets of resulting scores for the setting MUNIT -MS. The highest scores from two are in bold font, as we can see, the best settings the musicians and non-musicians selected are consistent for most of the questions. T ask P2G G2P P2S S2P A verage Model Feat BG ST CP SQ ST CP SQ ST CP SQ ST CP SQ ST CP SQ CycleGAN MS Y 2.68 4.06 2.52 2.58 3.84 2.68 2.94 3.29 2.10 3.19 4.00 3.19 2.85 3.80 2.62 N 3.02 4.39 2.61 2.71 4.32 2.53 2.85 3.63 2.47 3.20 3.98 3.03 2.94 4.08 2.66 UNIT MS Y 2.65 3.77 2.68 2.42 3.42 2.23 3.00 3.39 2.39 3.55 3.97 3.03 2.90 3.64 2.58 N 2.95 4.22 2.86 2.64 4.02 2.19 2.76 3.75 2.24 3.32 3.86 2.81 2.92 3.96 2.53 MUNIT MS Y 3.03 3.81 2.77 3.26 3.81 2.74 3.13 3.45 2.55 3.74 3.74 3.00 3.29 3.70 2.77 N 3.14 4.22 2.86 3.34 4.24 2.68 3.17 3.83 2.64 3.69 3.88 2.98 3.33 4.04 2.79 T ask P2G G2P P2S S2P A verage Model Feat BG ST CP SQ ST CP SQ ST CP SQ ST CP SQ ST CP SQ MUNIT MS Y 2.48 3.89 2.22 2.70 3.81 1.93 2.37 3.26 1.96 3.56 3.37 2.70 2.78 3.58 2.20 N 3.00 3.88 2.55 2.86 3.69 2.40 2.72 3.18 2.37 3.34 3.26 2.80 2.98 3.50 2.53 MUNIT MC Y 3.07 3.96 3.15 2.70 3.63 2.19 2.48 3.48 2.07 3.44 3.52 2.74 2.93 3.65 2.54 N 3.42 4.12 3.14 2.86 3.54 2.52 2.88 3.28 2.38 3.49 3.43 3.02 3.16 3.59 2.77 MUNIT ALL Y 3.37 4.19 2.93 2.41 4.04 2.59 1.59 3.15 1.48 3.78 3.81 3.19 2.79 3.80 2.55 N 3.65 4.11 3.22 3.15 4.03 3.12 2.34 3.12 2.12 3.75 3.68 3.29 3.22 3.73 2.94
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment