음향 질문 응답을 위한 새로운 데이터셋 CLEAR 소개
본 논문은 음향 질문 응답(AQA)이라는 새로운 과제를 정의하고, CLEVR 방식을 차용해 합성 음향 장면과 그에 대한 질문·답변을 자동 생성하는 CLEAR 데이터셋을 제시한다. 5종 악기 소리와 8가지 속성을 조합해 10개의 음소로 구성된 장면을 만들고, 9가지 질문 유형을 942개의 함수 프로그램 템플릿으로 변환한다. 초기 실험에서는 시각 질문 모델 FiLM을 스펙트로그램 이미지에 적용해 90% 수준의 정확도를 기록했다.
저자: Jerome Abdelnour, Giampiero Salvi, Jean Rouat
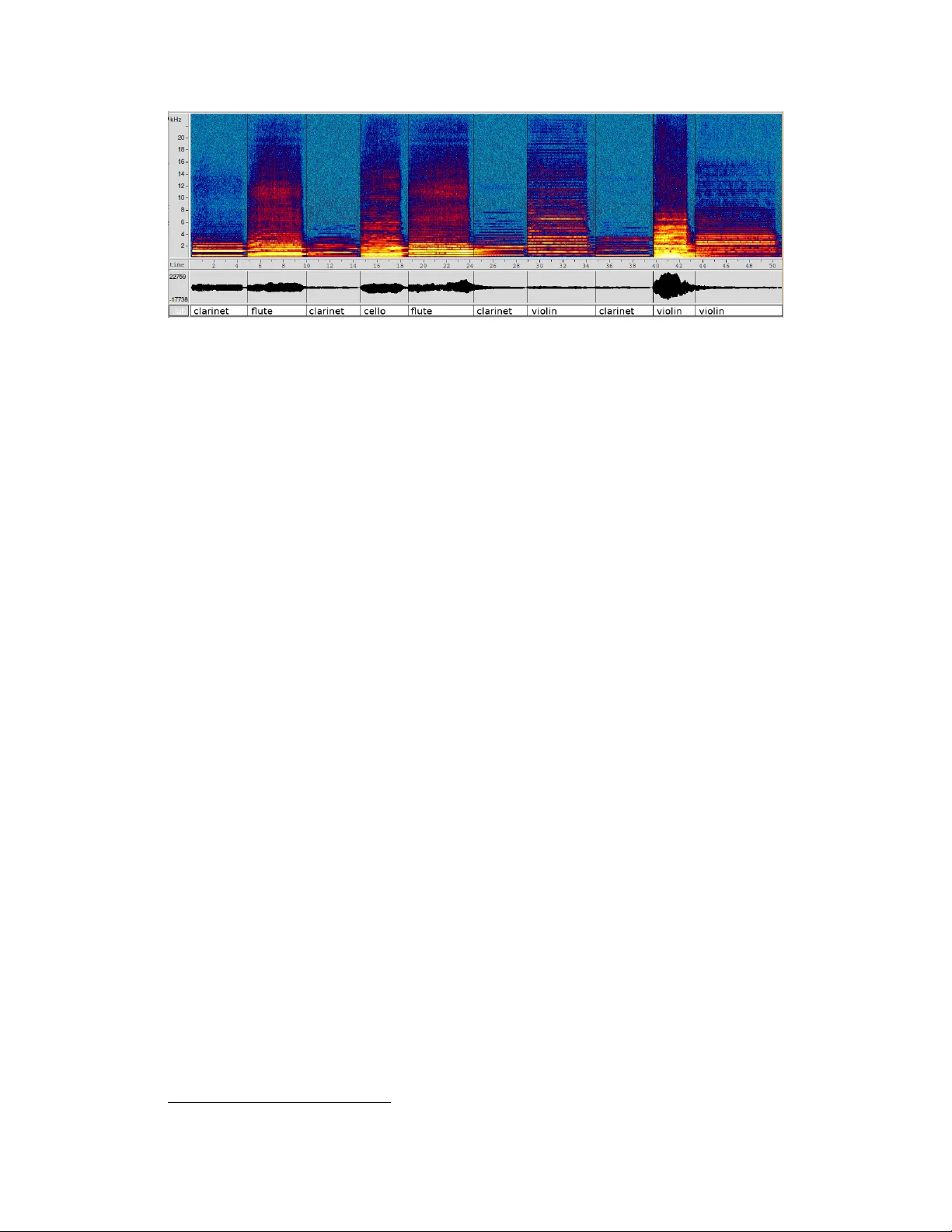
본 논문은 “Acoustic Question Answering”(AQA)이라는 새로운 연구 분야를 제시하고, 이를 위한 대규모 합성 데이터셋 CLEAR를 공개한다. 기존의 질문 응답 연구는 텍스트, 이미지, 비디오 등 시각적·언어적 정보를 중심으로 전개돼 왔으며, 비디오 기반 QA에서도 음향은 주로 자막이나 음성 인식 텍스트 형태로만 활용되었다. 저자들은 이러한 한계를 극복하고, 순수 음향 신호 자체가 담고 있는 풍부한 정보를 직접 활용할 수 있는 QA 과제를 정의한다.
데이터 생성은 CLEVR(시각적 합성 QA)에서 영감을 받아 설계되었다. 먼저 Good‑Sounds 데이터베이스에서 5가지 악기(첼로, 클라리넷, 플루트, 트럼펫, 바이올린)의 지속음을 추출해 56개의 ‘기본 소리’를 만든다. 각 소리는 8개의 속성(악기 종류, 밝기, 음량, 음높이, 절대 위치, 상대 위치, 전역 위치, 지속시간)으로 라벨링된다. 밝기와 음량은 각각 두 가지 이산값으로 제한해 질문 설계 시 조합을 쉽게 만들었다.
음향 장면은 10개의 기본 소리를 무작위로 선택해 순차적으로 연결한다. 연결 전에는 24‑bit→16‑bit 변환, 무음 구간 제거, LUFS 기반 음량 측정·조정 과정을 거쳐 ‘조용’과 ‘큰소리’를 명확히 구분한다. 이후 백색 잡음(‑80~‑90 dB)과 무작위 리버버레이션(50~400 ms)을 추가해 실제 환경과 유사한 노이즈와 잔향을 부여한다. 이 과정에서 각 소리 사이에 완전한 침묵이 없도록 함으로써 모델이 연속적인 스펙트로그램을 학습하도록 설계했다. 현재 버전은 고정 길이(10 초 내외)와 고정 개수(10개 소리)라는 제약을 두어 스펙트로그램을 고정 해상도 이미지로 변환할 수 있게 했다.
질문 생성은 함수 프로그램 기반 템플릿 시스템을 사용한다. 9가지 답변 유형(예/아니오, 음표, 악기, 밝기, 음량, 개수, 절대·상대·전역 위치)과 942개의 템플릿을 정의했으며, 각 템플릿은 변수(예: “두 번째 첼로 소리”, “밝은 D 음”)를 다양한 속성값으로 채워 다수의 자연어 질문을 만든다. 템플릿에 따라 “Is there an equal number of loud cello sounds and quiet clarinet sounds?”와 같은 복합 비교 질문부터 “What is the position of the flute that plays after the second clarinet?”와 같은 순서 기반 질문까지 다양하게 생성된다. 생성 과정에서 질문이 의미적으로 모호하거나 답이 유일하게 결정되지 않는 경우(ill‑posed, degenerate)를 자동 검증 알고리즘이 걸러낸다.
실험에서는 CLEVR에서 성공한 FiLM(Feature-wise Linear Modulation) 모델을 그대로 적용했다. 스펙트로그램을 3채널 이미지로 변환해 입력하고, 질문 텍스트를 임베딩해 결합하였다. 35,000개의 장면(1.4 M 질문)으로 학습한 결과 테스트 셋(7,500 장면, 300,000 질문)에서 89.97% 정확도를 달성했으며, 이는 다수 클래스(7.6%)에 비해 현저히 높은 성능이다. 그러나 모델이 이미지 기반 구조에 의존하기 때문에, 음향 고유의 시간적 연속성, 중첩, 주파수 변동 등을 충분히 활용하지 못한다는 한계가 있다.
저자들은 현재 데이터셋의 제한점을 명시한다. 첫째, 고정 길이·고정 개수·비중첩이라는 설계는 VQA 모델을 그대로 적용하기 위한 편의성에서 비롯된 것이며, 향후 가변 길이와 중첩 소리를 허용해 보다 현실적인 상황을 반영할 계획이다. 둘째, 악기 종류를 5개에서 확대하고, 타악기·피아노·기타·음성·환경 소리 등 다양한 음원 유형을 포함시켜 일반성을 높이겠다. 셋째, 속성 수를 늘리고(예: 음색, 지속시간), 질문 복잡도를 높이며, 다양한 잡음·왜곡 레벨을 도입해 모델의 견고성을 평가하고자 한다.
결론적으로, CLEAR는 음향 기반 추론 연구를 촉진하기 위한 최초의 대규모 합성 QA 데이터셋이며, 초기 실험을 통해 기존 시각 모델이 음향 데이터에도 일정 수준 이상 적용 가능함을 보여준다. 향후 데이터 확장과 새로운 모델 개발을 통해 음향 인지와 추론 분야의 연구가 크게 진전될 것으로 기대한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기