CLEAR: A Dataset for Compositional Language and Elementary Acoustic Reasoning
We introduce the task of acoustic question answering (AQA) in the area of acoustic reasoning. In this task an agent learns to answer questions on the basis of acoustic context. In order to promote research in this area, we propose a data generation p…
Authors: Jerome Abdelnour, Giampiero Salvi, Jean Rouat
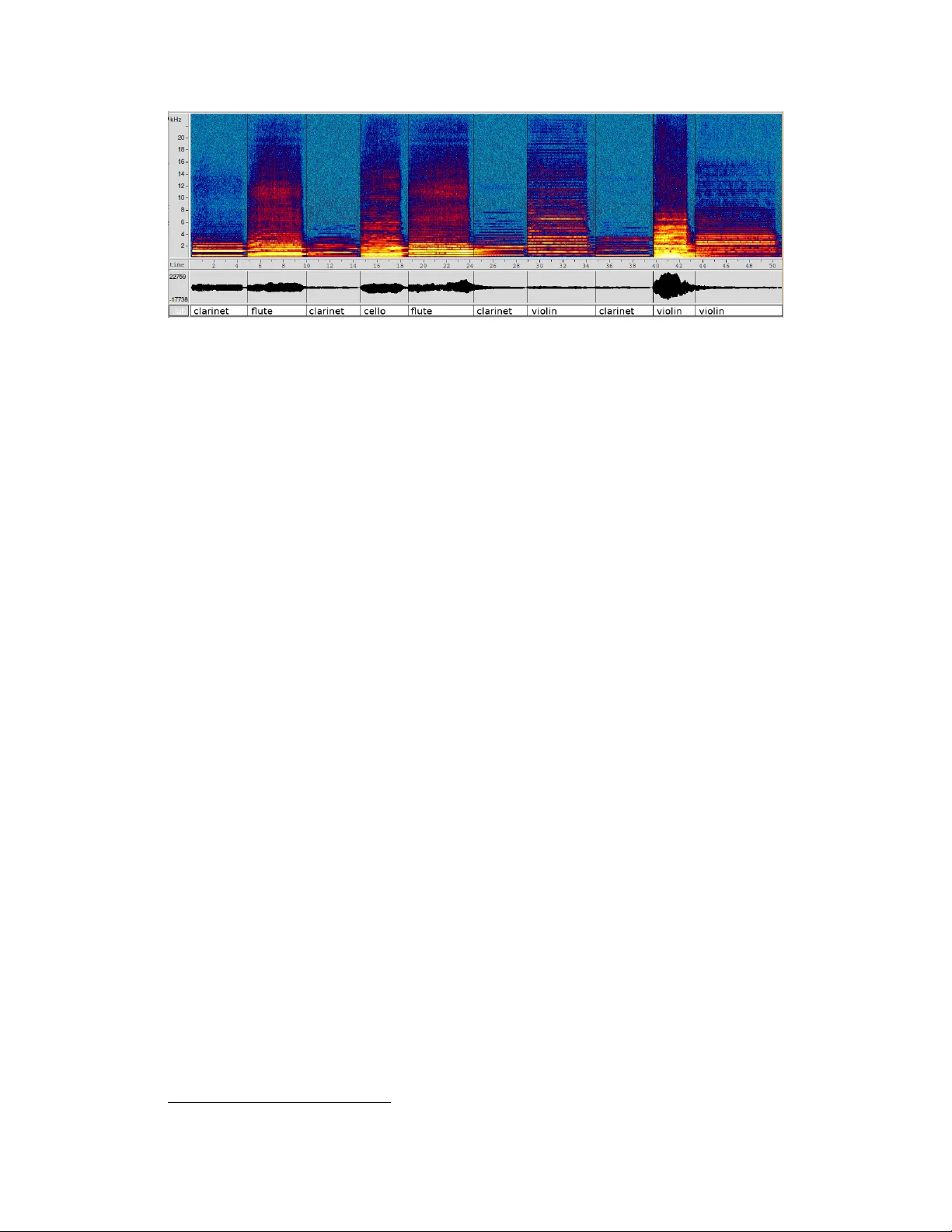
CLEAR: A Dataset f or Compositional Language and Elementary Acoustic Reasoning Jer ome Abdelnour NECO TIS, ECE Dept. Sherbrooke Uni versity Québec, Canada Jerome.Abdelnour @usherbrooke.ca Giampiero Salvi KTH Royal Institute of T echnology EECS School Stockholm, Sweden giampi@kth.se Jean Rouat NECO TIS, ECE Dept. Sherbrooke Uni versity Québec, Canada Jean.Rouat @usherbrooke.ca Abstract W e introduce the task of acoustic question answering (A QA) in the area of acoustic reasoning. In this task an agent learns to answer questions on the basis of acoustic context. In order to promote research in this area, we propose a data generation paradigm adapted from CLEVR [11]. W e generate acoustic scenes by le veraging a bank of elementary sounds. W e also provide a number of functional programs that can be used to compose questions and answers that e xploit the relationships between the attrib utes of the elementary sounds in each scene. W e provide A QA datasets of various sizes as well as the data generation code. As a preliminary experiment to v alidate our data, we report the accuracy of current state of the art visual question answering models when they are applied to the A QA task without modifications. Although there is a plethora of question answering tasks based on text, image or video data, to our kno wledge, we are the first to propose answering questions directly on audio streams. W e hope this contribution will f acilitate the dev elopment of research in the area. 1 Introduction and Related W ork Question answering (QA) problems ha ve attracted increasing interest in the machine learning and artificial intelligence communities. These tasks usually in volve interpreting and answering text based questions in the vie w of some contextual information, often e xpressed in a different modality . T ext-based QA, use text corpora as context ([19, 20, 17, 9, 10, 16]); in visual question answering (VQA), instead, the questions are related to a scene depicted in still images (e.g. [11, 2, 25, 7, 1, 23, 8, 10, 16]. Finally , video question answering attempts to use both the visual and acoustic information in video material as context (e.g. [5, 6, 22, 13, 14, 21]). In the last case, howe ver , the acoustic information is usually expressed in te xt form, either with manual transcriptions (e.g. subtitles) or by automatic speech recognition, and is limited to linguistic information [24]. The task presented in this paper differs from the above by answering questions directly on audio streams. W e ar gue that the audio modality contains important information that has not been exploited in the question answering domain. This information may allow QA systems to answer relev ant questions more accurately , or even to answer questions that are not approachable from the visual domain alone. Examples of potential applications are the detection of anomalies in machinery where the moving parts are hidden, the detection of threatening or hazardous e vents, industrial and social robotics. Current question answering methods require large amounts of annotated data. In the visual domain, sev eral strategies ha ve been proposed to make this kind of data av ailable to the community [11, 2, 25, 7]. Agrawal et al. [1] noted that the way the questions are created has a huge impact on what information a neural network uses to answer them (this is a well kno wn problem that can arise with 32nd Conference on Neural Information Processing Systems, V iGIL W orkshop (NIPS 2018), Montréal, Canada. Question type Example Possible Answers # Y es/No Is there an equal number of loud cello sounds and quiet clarinet sounds? yes, no 2 Note What is the note played by the flute that is after the loud bright D note? A, A#, B, C, C#, D, D#, E, F , F#, G, G# 12 Instrument What instrument plays a dark quiet sound in the end of the scene? cello, clarinet, flute, trumpet, violin 5 Brightness What is the brightness of the first clarinet sound? bright, dark 2 Loudness What is the loudness of the violin playing after the third trumpet ? quiet, loud 2 Counting How man y other sounds have the same brightness as the third violin ? 0–10 11 Absolute Pos. What is the position of the A# note playing after the bright B note? o first–tenth 10 Relativ e Pos. Among the trumpet sounds which one is a F ? Global Pos. In what part of the scene is the clarinet playing a G note that is before the third violin sound? beginning, middle, end (of the scene) 3 T otal 47 T able 1: T ypes of questions with examples and possible answers. The variable parts of each question is emphasized in bold italics. In the dataset many variants of questions are included for each question type, depending on the kind of relations the question implies. The number of possible answers is also reported in the last column. Each possible answer is modelled by one output node in the neural network. Note that for absolute and relative positions, the same nodes are used with dif ferent meanings: in the first case we enumerate all sounds, in the second case, only the sounds played by a specific instrument. all neural network based systems). This motiv ated research [23, 8, 11] on how to reduce the bias in VQA datasets. The complexity around g athering good labeled data forced some authors [23, 8] to constrain their work to yes/no questions. Johnson et al. [11] made their way around this constraint by using synthetic data. T o generate the questions, they first generate a semantic representation that describes the reasoning steps needed in order to answer the question. This giv es them full control ov er the labelling process and a better understanding of the semantic meaning of the questions. They lev erage this ability to reduce the bias in the synthesized data. For example, they ensure that none of the generated questions contains hints about the answer . Inspired by the work on CLEVR [11], we propose an acoustical question answering (A QA) task by defining a synthetic dataset that comprises audio scenes composed by sequences of elementary sounds and questions relating properties of the sounds in each scene. W e pro vide the adapted software for A QA data generation as well as a version of the dataset based on musical instrument sounds. W e also report preliminary experiments using the FiLM architecture deri ved from the VQA domain. 2 Dataset This section presents the dataset and the generation process 1 . In this first version (v ersion 1.0) we created multiple instances of the dataset with 1000, 10000 and 50000 acoustic scenes for which we generated 20 to 40 questions and answers per scene. In total, we generated six instances of the dataset. T o represent questions, we use the same semantic representation through functional programs that is proposed in [11, 12]. 2.1 Scenes and Elementary Sounds An acoustic scene is composed by a sequence of elementary sounds , that we will call just sounds in the follo wing. The sounds are real recordings of musical notes from the Good-Sounds database [3]. W e use fi ve f amilies of musical instruments: cello, clarinet, flute, trumpet and violin. Each record- ing of an instrument has a different musical note (pitch) on the MIDI scale. The data genera- tion process, ho wever , is independent of the specific sounds, so that future versions of the data may include speech, animal vocalizations and environmental sounds. Each sound is described by an n-tuple [Instrument family, Brightness, Loudness, Musical note, Absolute Position, Relative Position, Global Position, Duration] (see T able 1 for a summary of attributes and v alues). Where Brightness can be either bright or dark ; Loudness can be quiet or loud ; Musical note can take any of the 12 values on the fourth octave of the W estern chromatic scale 2 . The Absolute Position gi ves the position of the sound within the acoustic scene (between first and tenth), the Relative Position giv es the position of a sound relativ ely to the other sounds that are in the same cate gory (e.g. “the third cello sound”). Global Position refers 1 A vailable at https://github.com/IGLU- CHISTERA/CLEAR- dataset- generation 2 For this first v ersion of CLEAR the cello only includes 8 notes: C, C#, D, D#, E, F , F#, G. 2 Figure 1: Example of an acoustic scene. W e show the spectrogram, the wa veform and the annotation of the instrument for each elementary sounds. A possible question on this scene could be "What is the position of the flute that plays after the second clarinet?", and the corresponding answer would be "Fifth". Note that the agent must answer based on the spectrogram (or waveform) alone. to the approximate position of the sound within the scene and can be either beginning , middle or end . W e start by generating a clean acoustic scene as following: first the encoding of the original sounds (sampled at 48kHz) is conv erted from 24 to 16 bits. Then silence is detected and removed when the energy , computed as 10 log 10 P i x 2 i ov er windows of 100 msec, falls below -50 dB, where x i are the sound samples normalized between ± 1 . Then we measure the perceptual loudness of the sounds in dB LUFS using the method described in the ITU-R BS.1770-4 international normalization standard [4] and implemented in [18]. W e attenuate sounds that are in an intermediate range of -24 dB LUFS and -30.5 dB LUFS by -10 dB, to increase the separation between loud and quiet sounds. W e obtain a bank of 56 elementary sounds. Each clean acoustic scene is generated by concatenating 10 sounds chosen randomly from this bank. Once a clean acoustic scene has been created it is post-processed to generate a more difficult and realistic scene. A white uncorrelated uniform noise is first added to the scene. The amplitude range of the noise is first set to the maximum v alues allo wed by the encoding. Then the amplitude is attenuated by a factor f randomly sampled from a uniform distribution between -80 dB and -90 dB ( 20 log 10 f ). The noise is then added to the scene. Although the noise is weak and almost imperceptible to the human ear , it guaranties that there is no pure silence between each elementary sounds. The scene obtained this way is finally filtered to simulate room reverberation using SoX 3 . For each scene, a different room re verberation time is chosen from a uniform distribution between [50ms, 400ms]. 2.2 Questions Questions are structured in a logical tree introduced in CLEVR [11] as a functional pr ogram .A functional program, defines the reasoning steps required to answer a question giv en a scene definition. W e adapted the original w ork of Johnson et al. [11] to our acoustical conte xt by updating the function catalog and the relationships between the objects of the scene. For example we added the befor e and after temporal relationships. In natural language, there is more than one way to ask a question that has the same meaning. F or example, the question “Is the cello as loud as the flute?” is equiv alent to “Does the cello play as loud as the flute?”. Both of these questions correspond to the same functional program ev en though their text representation is dif ferent. Therefore the structures we use include, for each question, a functional representation, and possibly many text representations used to maximize language di versity and minimize the bias in the questions. W e have defined 942 such structures. A template can be instantiated using a large number of combinations of elements. Not all of them generate v alid questions. For example "Is the flute louder than the flute?" is in valid because it does not provide enough information to compare the correct sounds regardless of the structure of the scene. Similarly , the question “What is the position of the violin playing after the trumpet?” would be 3 http://sox.sourceforge.net/sox.html 3 ill-posed if there are several violins playing after the trumpet. The same question would be considered degenerate if there is only one violin sound in the scene, because it could be answered without taking into account the relation “after the trumpet”. A v alidation process [11] is responsible for rejecting both ill-posed and degenerate questions during the generation phase. Thanks to the functional representation we can use the reasoning steps of the questions to analyze the results. This would be difficult if we were only using the text representation without human annotations. If we consider the kind of answer , questions can be organized into 9 families as illustrated in T able 1. For example, the question “What is the third instrument playing?” w ould translate to the “Query Instrument” family as its function is to retrie ve the instrument’ s name. On the other hand we could classify the questions based on the relationships they required to be answered. For example, "What is the instrument after the trumpet sound that is playing the C note?" is still a “query_instrument” question, but compared to the previous example, requires more complex reasoning. The appendix reports and analyzes statistics and properties of the database. 3 Preliminary Experiments T o ev aluate our dataset, we performed preliminary experiments with a FiLM network [15]. It is a good candidate as it has been shown to w ork well on the CLEVR VQA task [11] that shares the same structure of questions as our CLEAR dataset. T o represent acoustic scenes in a format compatible with FiLM, we computed spectrograms (log amplitude of the spectrum at re gular intervals in time) and treated them as images. Each scene corresponds to a fixed resolution image because we have designed the dataset to include acoustic scenes of the same length in time. The best results were obtained with a training on 35000 scenes and 1400000 questions/answers. It yields a 89.97% accurac y on the test set that comprises 7500 scenes and 300000 questions. For the same test set a classifier choosing always the majority class w ould obtain as little as 7.6% accuracy . 4 Conclusion W e introduce the ne w task of acoustic question answering (A QA) as a means to stimulate AI and reasoning research on acoustic scenes. W e also propose a paradigm for data generation that is an extension of the CLEVR paradigm: The acoustic scenes are generated by combining a number of elementary sounds, and the corresponding questions and answers are generated based on the properties of those sounds and their mutual relationships. W e generated a preliminary dataset comprising 50k acoustic scenes composed of 10 musical instrument sounds, and 2M corresponding questions and answers. W e also tested the FiLM model on the preliminary dataset obtaining at best 89.97% accuracy predicting the right answer from the question and the scene. Although these preliminary results are very encouraging, we consider this as a first step in creating datasets that will promote research in acoustic reasoning. The following is a list of limitations that we intend to address in future versions of the dataset. 4.1 Limitations and Future Directions In order to be able to use models that were designed for VQA, we created acoustic scenes that hav e the same length in time. This allows us to represent the scenes as images (spectrograms) of fixed resolution. In order to promote models that can handle sounds more naturally , we should release this assumption and create scenes of variable lenghts. Another simplifying assumption (somewhat related to the first) is that e very scene includes an equal number of elementary sounds. This assumption should also be released in future versions of the dataset. In the current implementation, consecuti ve sounds follow each other without o verlap. In order to implement something similar to occlusions in visual domain, we should let the sounds o verlap. The number of instruments is limited to fi ve and all produce sustained notes, although with different sound sources (bo w , for cello and violin, reed vibration for the clarinet, fipple for the flute and lips for the trumpet). W e should increase the number of instruments and consider percussiv e and decaying sounds as in drums and piano, or guitar . W e also intend to consider other types of sounds (ambient and speech, for example) to increase the generality of the data. Finally , the complexity of the task can al ways be increased by adding more attributes to the elementary sounds, adding comple xity to the questions, or introducing dif ferent lev els of noise and distortions in the acoustic data. 4 5 Acknowledgements W e would like to acknowledge the NVIDIA Corporation for donating a number of GPUs, the Google Cloud Platform research credits program for computational resources. Part of this research was financed by the CHIST -ERA IGLU project, the CRSNG and Michael-Smith scholarships, and by the Univ ersity of Sherbrooke. References [1] Aishwarya Agrawal, Dhruv Batra, and Devi Parikh. “Analyzing the behavior of visual question answering models”. In: arXiv preprint arXiv:1606.07356 (2016). [2] Stanislaw Antol, Aishwarya Agra wal, Jiasen Lu, Margaret Mitchell, Dhruv Batra, C Lawrence Zitnick, and Devi Parikh. “Vqa: V isual question answering”. In: Pr oc. of ICCV . 2015, pp. 2425– 2433. [3] Giuseppe Bandiera, Oriol Romani Picas, Hiroshi T okuda, W ataru Hariya, K oji Oishi, and Xavier Serra. “Good-sounds.org: a frame work to e xplore goodness in instrumental sounds”. In: Pr oc. of 17th ISMIR . 2016. [4] Recommendation ITU-R BS.1770-4. Algorithms to measur e audio pr ogramme loudness and true-peak audio level . T ech. rep. Oct. 2015. U R L : https : / / www . itu . int / dms _ pubrec / itu- r/rec/bs/R- REC- BS.1770- 4- 201510- I!!PDF- E.pdf . [5] Jinwei Cao, Jose Antonio Robles-Flores, Dmitri Roussinov, and Jay F Nunamaker. “Automated question answering from lecture videos: NLP vs. pattern matching”. In: Proc. of Int. Conf. on System Sciences . IEEE. 2005, 43b–43b. [6] T at-Seng Chua. “Question answering on large ne ws video archi ve”. In: Pr oc. of ISP A . IEEE. 2003, pp. 289–294. [7] Haoyuan Gao, Junhua Mao, Jie Zhou, Zhiheng Huang, Lei W ang, and W ei Xu. “Are you talking to a machine? dataset and methods for multilingual image question”. In: NIPS . 2015, pp. 2296–2304. [8] Donald Geman, Stuart Geman, Neil Hallonquist, and Laurent Y ounes. “V isual turing test for computer vision systems”. In: Pr oc. of the National Academy of Sciences 112.12 (2015), pp. 3618–3623. [9] Eduard H Hovy, Laurie Gerber, Ulf Hermjakob, Michael Junk, and Chin-Y e w Lin. “Question Answering in W ebclopedia.” In: Proc. of TREC . V ol. 52. 2000, pp. 53–56. [10] Mohit Iyyer, Jordan Boyd-Graber, Leonardo Claudino, Richard Socher, and Hal Daumé III. “A neural netw ork for factoid question answering o ver paragraphs”. In: Pr oc. of EMNLP . 2014, pp. 633–644. [11] Justin Johnson, Bharath Hariharan, Laurens van der Maaten, Li Fei-Fei, C Lawrence Zit- nick, and Ross Girshick. “CLEVR: A Diagnostic Dataset for Compositional Language and Elementary V isual Reasoning”. In: Pr oc. of CVPR . IEEE. 2017, pp. 1988–1997. [12] Justin Johnson, Bharath Hariharan, Laurens van der Maaten, Judy Hoffman, Li Fei-Fei, C Lawrence Zitnick, and Ross Girshick. “Inferring and Ex ecuting Programs for V isual Reason- ing”. In: Pr oc. of ICCV . Oct. 2017, pp. 3008–3017. D O I : 10.1109/ICCV.2017.325 . [13] Kyung-Min Kim, Min-Oh Heo, Seong-Ho Choi, and Byoung-T ak Zhang. “DeepStory: video story qa by deep embedded memory networks”. In: CoRR (2017). arXiv: 1707.00836 . [14] “Movieqa: Understanding stories in movies through question-answering”. In: CVPR . 2016, pp. 4631–4640. [15] Ethan Perez, Florian Strub, Harm De Vries, V incent Dumoulin, and Aaron Courville. “Film: V isual reasoning with a general conditioning layer”. In: CoRR (2017). arXi v: 1709.07871 . [16] Deepak Ra vichandran and Eduard Hovy. “Learning surface text patterns for a question answer - ing system”. In: Pr oc. Ann. Meet. of Ass. for Comp. Ling. 2002, pp. 41–47. [17] Martin M Soubbotin and Sergei M Soubbotin. “Patterns of Potential Answer Expressions as Clues to the Right Answers.” In: Pr oc. of TREC . 2001. [18] Christian Steinmetz. pyLoudNorm . https://github .com/csteinmetz1/pyloudnorm/. [19] Ellen M V oorhees et al. “The TREC-8 Question Answering T rack Report.” In: Pr oc. of TREC . 1999, pp. 77–82. 5 [20] Ellen M V oorhees and Dawn M Tice. “Building a question answering test collection”. In: Pr oc. of Ann. Int. Conf. on R&D in Info. Retriev . 2000, pp. 200–207. [21] Y u-Chieh W u and Jie-Chi Y ang. “A robust passage retriev al algorithm for video question answering”. In: IEEE T rans. Cir cuits Syst. V ideo T echnol. 10 (2008), pp. 1411–1421. [22] Hui Y ang, Lekha Chaisorn, Y unlong Zhao, Shi-Y ong Neo, and T at-Seng Chua. “V ideoQA: question answering on ne ws video”. In: Pr oc. of the ACM Int. Conf. on Multimedia . ACM. 2003, pp. 632–641. [23] Peng Zhang, Y ash Goyal, Douglas Summers-Stay, Dhruv Batra, and De vi Parikh. “Y in and yang: Balancing and answering binary visual questions”. In: Proc. of CVPR . IEEE. 2016, pp. 5014–5022. [24] T ed Zhang, Dengxin Dai, T inne T uytelaars, Marie-Francine Moens, and Luc V an Gool. “Speech-Based V isual Question Answering”. In: CoRR abs/1705.00464 (2017). arXiv: 1705. 00464 . U R L : http://arxiv.org/abs/1705.00464 . [25] Y uke Zhu, Oli ver Groth, Michael Bernstein, and Li Fei-Fei. “V isual7w: Grounded question answering in images”. In: Pr oc. of CVPR . 2016, pp. 4995–5004. 6 A Statistics on the Data Set This appendix reports some statistics on the properties of the data set. W e ha ve considered the data set comprising 50k scenes and 2M questions and answers to produce the analysis. Figure 2 reports the distribution of the correct answer to each of the 2M questions. Figure 3 and 4 reports the distribution of question types and av ailable template types respectiv ely . The fact that those two distrib utions are very similar means that the av ailable templates are sampled uniformly when generating the questions. Finally , Figure 5 shows the distribution of sound attributes in the scenes. It can be seen that most attributes are nearly ev enly distributed. In the case of brightness, calculated in terms of spectral centroids, sounds were divided into clearly bright, clearly dark and ambiguous cases (referred to by "None" in the figure). W e only instantiated questions about the brightness on the clearly separable cases. 7 Bright Dark 0 1 2 3 4 5 6 7 8 9 Cello Clarinet Flute Trumpet Violin Loud Quiet No Y es A A# B C C# D D# E F F# G G# Eighth Fifth First Fourth Ninth Second Seventh Sixth T enth Third Beginning Of The Scene End Of The Scene Middle Of The Scene 0 0.02 0.04 0.06 0.08 Bright Dark 0 1 2 3 4 5 6 7 8 9 Cello Clarinet Flute Trumpet Violin Loud Quiet No Y es A A# B C C# D D# E F F# G G# Eighth Fifth First Fourth Ninth Second Seventh Sixth T enth Third Beginning Of The Scene End Of The Scene Middle Of The Scene 0 0.02 0.04 0.06 0.08 Bright Dark 0 1 2 3 4 5 6 7 8 9 Cello Clarinet Flute Trumpet Violin Loud Quiet No Y es A A# B C C# D D# E F F# G G# Eighth Fifth First Fourth Ninth Second Seventh Sixth T enth Third Beginning Of The Scene End Of The Scene Middle Of The Scene 0 0.02 0.04 0.06 0.08 Brightness Count Instrument Loudness Y es/No Musical Note Position Position Global Frequency Frequency Frequency T raining V alidation T est Figure 2: Distribution of answers in the dataset by set type. The color represent the answer category . 8 Compare Integer Exist Query Brightness Query Instrument Query Loudness Query Musical Note Query Position Absolute Query Position Global Query Position Instrumen t Count 0 0.05 0.1 0.15 0.2 Training V alidation T est Frequency Figure 3: Distribution of question types. The color represent the set type. 9 Compare Integer Exist Query Brightness Query Instrument Query Loudness Query Musical Note Query Position Absolute Query Position Global Query Position Instrumen t Count 0 0.05 0.1 0.15 0.2 T emplate T ype Distribution Frequency Figure 4: Distribution of template types. The same templates are used to generate the questions and answers for the training, validation and test set. 10 Cello Clarinet Flute T rumpet Violin 0 0.05 0.1 0.15 0.2 Bright Dark None 0 0.1 0.2 0.3 0.4 Loud Quiet 0 0.2 0.4 A A# B C C# D D# E F F# G G# 0 0.02 0.04 0.06 0.08 T raining V alidation T est Frequency Frequency Frequency Frequency Instrument Distribution Brightness Distribution Loudness Distribution Note Distribution Figure 5: Distribution of sound attributes in the scenes. The color represent the set type. Sounds with a "None" brightness have an ambiguous brightness which couldn’t be classified as ’Bright’ or ’Dark’. 11
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment