키워드 스포팅을 위한 확률적 적응 신경망 구조 탐색
SANAS는 실시간 오디오 스트림에서 키워드 탐지를 수행하면서, 입력의 난이도에 따라 네트워크 구조를 동적으로 선택하는 방법이다. RNN 기반 컨텍스트를 이용해 매 타임스텝마다 가능한 서브그래프(아키텍처) 분포를 생성하고, 베르누이 샘플링으로 경량 혹은 복합 구조를 선택한다. 손실 함수에 예측 오차와 FLOPs 비용을 가중합한 λ 파라미터를 포함시켜, 정확도와 연산량 사이의 트레이드오프를 학습한다. Speech Commands 데이터셋 실험에서…
저자: Tom Veniat, Olivier Schw, er
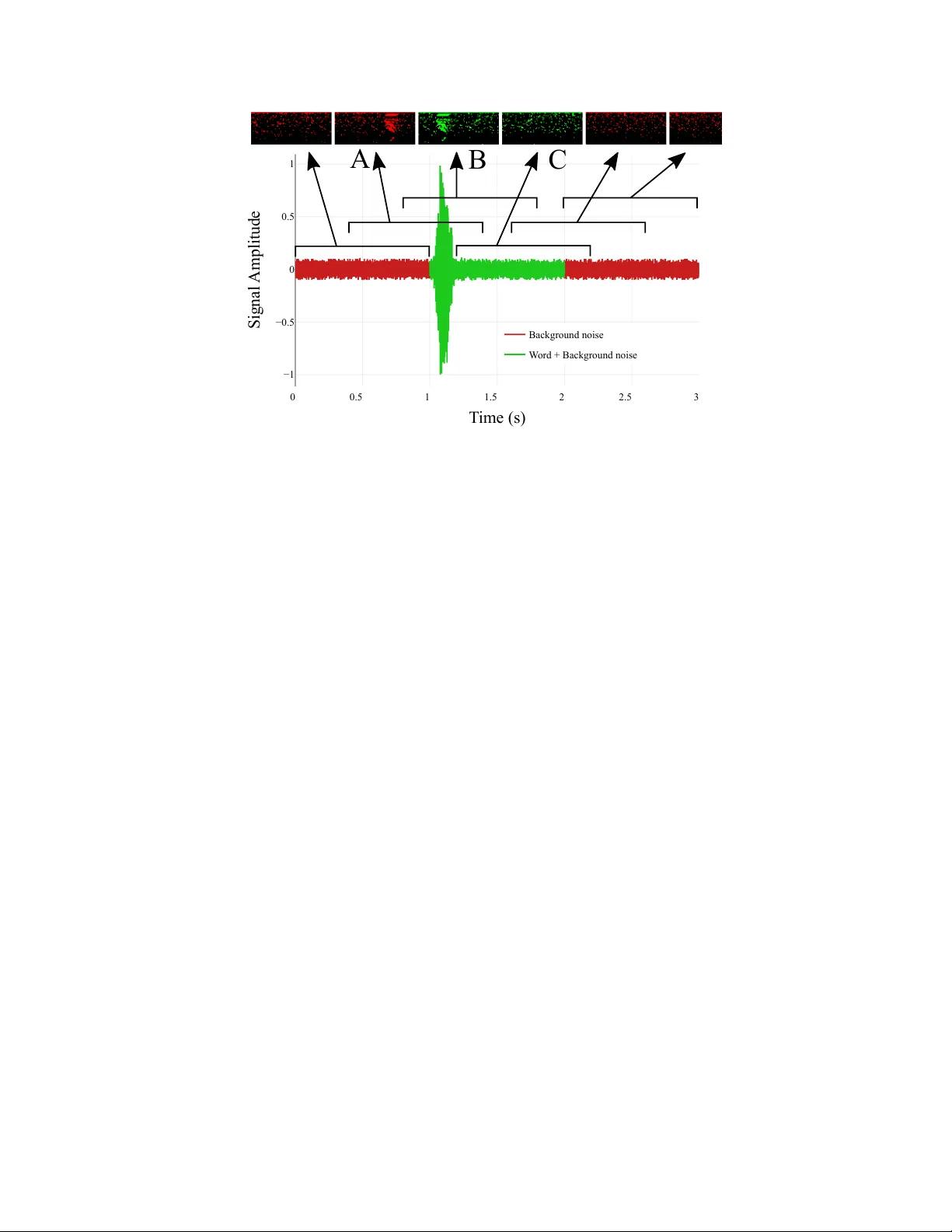
본 논문은 실시간 오디오 스트림에서 키워드 스포팅을 수행하면서, 입력 신호의 난이도에 따라 신경망 구조를 동적으로 조절하는 새로운 방법인 SANAS(Stochastic Adaptive Neural Architecture Search)를 제안한다. 기존의 키워드 스포팅 시스템은 고정된 네트워크 구조를 사용해 모든 프레임에 동일한 연산량을 소모한다. 이는 배경 잡음이나 무음 구간에서도 불필요한 계산을 발생시켜 에너지 효율성을 저하시킨다. SANAS는 이러한 문제를 해결하기 위해, 매 타임스텝마다 현재 컨텍스트를 요약하는 은닉 상태 zₜ 를 RNN(GRU)으로 유지하고, 이 은닉 상태를 기반으로 아키텍처 분포 Γₜ 를 생성한다. Γₜ 는 Super‑Network(전체 후보 그래프)의 각 에지에 대한 활성화 확률을 나타내며, 베르누이 샘플링을 통해 실제 사용될 서브그래프 Hₜ 를 선택한다. 선택된 서브그래프 Aₜ = E ∘ Hₜ 는 해당 타임스텝의 입력 xₜ 에 대해 예측 ŷₜ 와 다음 은닉 상태 zₜ₊₁ 을 계산하는 데 사용된다.
학습 목표는 예측 손실과 연산 비용을 동시에 최소화하는 것이다. 손실 함수는 L = ∑ₜ
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기