Stochastic Adaptive Neural Architecture Search for Keyword Spotting
The problem of keyword spotting i.e. identifying keywords in a real-time audio stream is mainly solved by applying a neural network over successive sliding windows. Due to the difficulty of the task, baseline models are usually large, resulting in a …
Authors: Tom Veniat, Olivier Schw, er
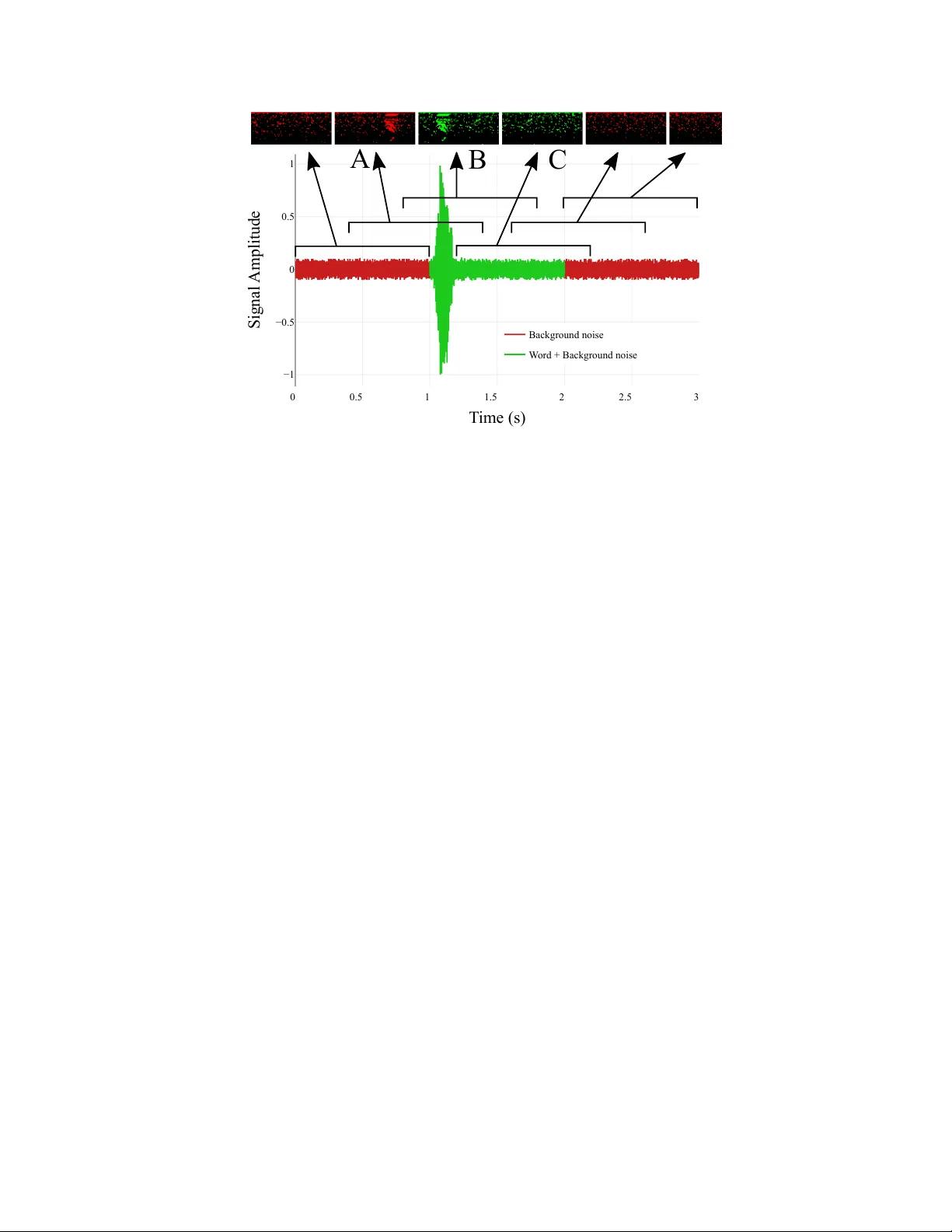
Stochastic Adaptiv e Neural Ar chitectur e Search f or K eyword Spotting T om Véniat † , Olivier Schw ander † , and Ludovic Denoyer † , * † Sorbonne Univ ersité, LIP6, F-75005, Paris, France * Facebook AI Research {tom.veniat, olivier.schwander}@lip6.fr denoyer@fb.com Abstract The problem of keyword spotting i.e. identifying keywords in a real-time audio stream is mainly solved by applying a neural network ov er successiv e sliding windows. Due to the difficulty of the task, baseline models are usually large, resulting in a high computational cost and energy consumption le vel. W e propose a new method called SANAS (Stochastic Adaptive Neural Architecture Search) which is able to adapt the architecture of the neural network on-the-fly at inference time such that small architectures will be used when the stream is easy to process (silence, lo w noise, ...) and bigger networks will be used when the task becomes more dif ficult. W e sho w that this adapti ve model can be learned end-to-end by optimizing a trade-of f between the prediction performance and the av erage computational cost per unit of time. Experiments on the Speech Commands dataset [ 16 ] sho w that this approach leads to a high recognition le vel while being much faster (and/or energy sa ving) than classical approaches where the network architecture is static. 1 Introduction and Related W ork Neural Networks (NN) are kno wn to obtain very high recognition rates on a large v ariety of tasks, and especially ov er signal-based problems like speech recognition [ 1 ], image classification [ 7 , 11 ], etc. Ho wever these models are usually composed of millions of parameters in v olved in millions of operations and hav e high computational and energy costs at prediction time. There is thus a need to increase their processing speed and reduce their energy footprint. From the NN point of view , this problem is often viewed as a problem of network architecture discov ery and solved with Neural Architecture Search (NAS) methods in which the search is guided by a trade-of f between prediction quality and prediction cost [ 6 , 8 , 15 ]. Recent approaches in volv e for instance Genetic Algorithms [ 10 , 11 ] or Reinforcement Learning [ 20 , 21 ]. While these models often rely on expensi ve training procedures where multiple architectures are trained, some recent works ha ve proposed to simultaneously discov er the architecture of the netw ork while learning its parameters [ 8 , 15 ] resulting in models that are fast both at training and at inference time. But in all these w orks, the disco vered architecture is static i.e. the same NN being re-used for all the predictions. When dealing with streams of information, reducing the computational and energy costs is of crucial importance. F or instance, let us consider the ke yword spotting 1 problem which is the focus of this paper . It consists in detecting keywords in an audio stream and is particularly relev ant for virtual assistants which must continuously listen to their environments to spot user interaction requests. This 1 See Section 3 for a formal description. Preprint. W ork in progress. g θ z 1 h θ H 2 Γ 2 Φ 2 h θ H K Γ K [ . . . ] y 2 ^ y K ^ x K x 2 z 2 z K g θ Φ K − 1 [ . . . ] ( ∘ E , ) f θ H K x K ( ∘ E , ) f θ H 2 x 2 g θ z 0 h θ H 1 Γ 1 Φ 1 y 1 ^ x 1 ( ∘ E , ) f θ H 1 x 1 Figure 1: SANAS Architectur e . At timestep t , the distribution Γ t is generated from the previous hidden state, Γ t = h ( z t , θ ) . A discrete architecture H t is then sampled from Γ t and e valuated o ver the input x t . This e valuation gi ves both a feature vector Φ( x t , θ , E ◦ H t ) to compute the next hidden state, and the prediction of the model ˆ y t using f ( z t , x t , θ , E ◦ H t ) . Dashed edges represent sampling operations. At inference, the architecture which has the highest probability is chosen at each timestep. requires detecting when a word is pronounced, which word has been pronounced and able to run quickly on resource-limited de vices. Some recent works [ 2 , 12 , 13 ] proposed to use con volutional neural networks (CNN) in this streaming conte xt, applying a particular model to successi ve sliding windows [ 12 , 13 ] or combining CNNs with recurrent neural networks (RNN) to keep track of the context [ 2 ]. In such cases, the resulting system spends the same amount of time to process each audio frame, irrespectiv e of the content of the frame or its context. Our conjecture is that, when dealing with streams of information, a model able to adapt its architecture to the dif ficulty of the prediction problem at each timestep – i.e. a small architecture being used when the prediction is easy , and a larger architecture being used when the prediction is more difficult – would be more efficient than a static model, particularly in terms of computation or energy consumption. T o achiev e this goal, we propose the SAN AS algorithm (Section 2.3): it is, as f ar as we kno w , the first architecture search method producing a system which dynamically adapts the architecture of a neural network during prediction at each timestep and which is learned end-to-end by minimizing a trade-of f between computation cost and prediction loss. After learning, our method can process audio streams at a higher speed than classical static methods while keeping a high recognition rate, spending more prediction time on complex signal windo ws and less time on easier ones (see Section 3). 2 Adaptive Neural Ar chitecture Search 2.1 Pr oblem Definition W e consider the generic problem of stream labeling where, at each timestep, the system recei ves a datapoint denoted x t and produces an output label y t . In the case of audio streams, x t is usually a time- frequency feature map, and y t is the presence or absence of a giv en ke yword. In classical approaches, the output label y t is predicted using a neural network whose architecture 2 is denoted A and whose parameters are θ . W e consider in this paper the recurrent modeling scheme where the context x 1 , y 1 , ....., x t − 1 , y t − 1 is encoded using a latent representation z t , such that the prediction at time t is made computing f ( z t , x t , θ , A ) , z t being updated at each timestep such that z t +1 = g ( z t , x t , θ , A ) - note that g and f can share some common computations. For a particular architecture A , the parameters are learned o ver a training set of labeled sequences { ( x i , y i ) } i ∈ [1 ,N ] , N being the size of the training set, by solving: θ ∗ = arg min θ 1 N N X i =1 # x i X t =1 ∆( f ( z t , x t , θ , A ) , y t ) where # x i is the length of sequence x i , and ∆ a differentiable loss function. At inference, giv en a new stream x , each label ˆ y t is predicted by computing f ( x 1 , ˆ y 1 , ....., ˆ y t − 1 , x t , θ ∗ , A ) , where ˆ y 1 . . . ˆ y t − 1 2 a precise definition of the notion of architecture is giv en further . 2 + Input MFCC features Convolution2 Lin1 Shortcut Lin2 Shortcut Lin1 Lin2 Classifier Shortcut Lin3 Output Convolution1 Φ t x t y t ^ Figure 2: SANAS architecture based on cnn-trad-fpool3 [ 12 ]. Edges between layers are sampled by the model. The highlighted architecture is the base model on which we ha ve added shortcut connections. Conv1 and Con v2 hav e filter sizes of (20,8) and (10,4). Both hav e 64 channels and Con v1 has a stride of 3 in the frequenc y domain. Linear 1,2 and the Classifier hav e 32, 128 and 12 neurons respectiv ely . Shortcut linears all ha ve 128 neurons to match the dimension of the classifier . are the predictions of the model at previous timesteps. In that case, the computation cost of each prediction step solely depends on the architecture and is denoted C ( A ) . 2.2 Stochastic Adapti ve Architectur e Search: Principles W e propose no w a dif ferent setting where the architecture of the model can change at each timestep depending on the context of the prediction z t . At time t , in addition to producing a distribution ov er possible labels, our model also maintains a distribution over possible architectures denoted P ( A t | z t , θ ) . The prediction y t being no w made following 3 f ( z t , x t , θ , A t ) and the context update being z t +1 = g ( z t , x t , θ , A t ) . In that case, the cost of a prediction at time t is now C ( A t ) , which also includes the computation of the architecture distribution P ( A t | z t , θ ) . It is important to note that, since the architecture A t is chosen by the model, it has the possibility to learn to control this cost itself. A budgeted learning problem can thus be defined as minimizing a trade-off between prediction loss and av erage cost. Considering a labeled sequence ( x, y ) , this trade-of f is defined as : L ( x, y , θ ) = E {A t } # x X t =1 [∆( f ( z t , x t , θ , A t ) , y t ) + λC ( A t )] where A 1 , ..., A # x are sampled following P ( A t | z t , θ ) and λ controls the trade-off between cost and prediction efficienc y . Considering that P ( A t | z t , θ ) is differentiable, and follo wing the deri vation schema proposed in [ 5 ] or [ 15 ], this cost can be minimized using the Monte-Carlo estimation of the gradient. Gi ven one sample of architectures A 1 , ..., A # x , the gradient can be approximated by: ∇ θ L ( x, y , θ ) ≈ # x X t =1 ∇ θ log P ( A t | z t , θ ) L ( x, y , A 1 , ..., A # x , θ ) + # x X t =1 ∇ θ ∆( f ( z t , x t , θ , A t ) , y t ) where L ( x, y , A 1 , ..., A # x , θ ) = # x X t =1 [∆( f ( z t , x t , θ , A t ) , y t ) + λC ( A t )] In practice, a variance correcting v alue is used in this gradient formulation to accelerate the learning as explained in [17, 18]. 2.3 The SAN AS Model W e no w instantiate the previous generic principles in a concrete model where the architecture search is cast into a sub-graph discov ery in a large graph representing the search space called Super -Network as in [15]. 3 f is usually a distribution o ver possible labels. 3 0 0.5 1 1.5 2 2.5 3 − 1 − 0.5 0 0.5 1 T ime (s) Signal Amplitude Background noise W ord + Background noise A B C Figure 3: Example of labeling using the method presented in section 3. T o build the dataset, a ground noise (red) is mixed with randomly located words (green). The signal is then split in 1s frames ev ery 200ms. When a frame contains at least 50% of a word signal, it is labeled with the corresponding word (frame B and C – frame A is labeled as bg-noise ). Note that this labeling could be imperfect (see frame A and C). NAS with Super-Netw orks (static case): A Super-Network is a directed acyclic graph of layers L = { l 1 , ...l n } , of edges E ∈ { 0 , 1 } n × n and where each e xisting edge connecting layers i and j ( e i,j = 1 ) is associated with a (small) neural network f i,j . The layer l 1 is the input layer while l n is the output layer . The inference of the output is made by propagating the input x ov er the edges, and by summing, at each layer le vel, the v alues coming from incoming edges. Gi ven a Super -Network, the architecture search can be made by defining a distribution matrix Γ ∈ [0 , 1] n × n that can be used to sample edges in the network using a Bernoulli distribution. Indeed, let us consider a binary matrix H sampled follo wing Γ , the matrix E ◦ H defines a sub-graph of E and corresponds to a particular neural-network architecture which size is smaller than E ( ◦ being the Hadamard product). Learning Γ thus results in doing architecture search in the space of all the possible neural networks contained in Super-Netw ork. At inference, the architecture with the highest probability is chosen. SANAS with Super -Networks: Based on the pre viously described principle, our method proposes to use a RNN to generate the architecture distribution at each timestep – see Figure 1. Concretely , at time t , a distribution o ver possible sub-graphs Γ t = h ( z t , θ ) is computed from the context z t . This distribution is then used to sample a particular sub-graph represented by H t ∼ B (Γ t ) , B being a Bernoulli distribution. This particular sub-grap E ◦ H t = A t corresponds to the architecture used at time t . Then the prediction ˆ y t and the ne xt state z t +1 are computed using the functions f ( z t , x t , θ , E ◦ H t ) and g ( z t , Φ( x t , θ , E ◦ H t ) , θ ) respectiv ely , where g ( z t , ., θ ) is a classical RNN operator like a Gated Recurrent Unit[ 3 ] cell for instance and Φ( x t , θ , E ◦ H t ) is a feature vector used to update the latent state and computed using the sampled architecture A t . The learning of the parameters of the proposed model relies on a gradient-descent method based on the approximation of the gradient provided pre viously , which simultaneously updates the parameters θ and the conditional distribution o ver possible architectures. 3 Experiments W e train and e v aluate our model using the Speech Commands dataset [ 16 ]. It is composed of 65000 short audio clips of 30 common words. As done in [ 13 , 14 , 19 ], we treat this problem as a classification task with 12 categories: ’yes’, ’no’, ’up’, ’ down’, ’left’, ’ right’, ’on’, ’off ’, ’ stop’, ’go’, ’ bg-noise ’ for background noise and ’ unknown ’ for the remaining words. 4 Match Correct Wr ong F A FLOPs per frame cnn-trad-fpool3 81.7% 72.8% 8.9% 0.0% 124.6M cnn-trad-fpool3 + shortcut connections 82.9% 77.9% 5.0% 0.3% 137.3M SANAS 61.2% 53.8% 7.3% 0.7% 519.2K 62.0% 57.3% 4.8% 0.1% 22.9M 86.5% 80.7% 5.8% 0.3% 37.7M 86.3% 80.6% 5.7% 0.2% 48.8M 81.7% 76.4% 5.3% 0.1% 94.0M 81.4% 76.3% 5.2% 0.2% 105.4M T able 1: Evaluation of models on 1h of audio from [ 16 ] containing words roughly ev ery 3 seconds with different background noises. W e use the label post processing and the streaming metrics proposed in [ 16 ] to a void repeated and noisy detections. Matched % corresponds to the portion of words detected, either correctly (Correct %) or incorrectly (Wrong %). F A is F alse Alarm . Instead of directly classifying 1 second samples, we use this dataset to generate between 1 and 3 second long audio files by combining a background noise coming from the dataset with a randomly located word (see Figure 3), the signal-to-noise ratio being randomly sampled with a minimum of 5dB. W e thus obtain a dataset of about 30,000 small files 4 , and then split this dataset in train, v alidation and test sets using a 80:10:10 ratio. The sequence of frames is created by taking overlapping windows of 1 second e very 200ms. The input features for each window are computed by e xtracting 40 mel-frequency spectral coef ficients (MFCC) on 30ms frames e very 10ms and stacking them to create 2D time/frequenc y maps. For the ev aluation, we use both the prediction accuracy and the number of operations per frame (FLOPs) v alue. The model selection is made by training multiple models, selecting the best models on the validation set, and computing their performance on the test set. Note that the ’best models’ in terms of both accuracy and FLOPs are the models located on the pareto front of the accuracy/cost v alidation curve as done for instance in [ 4 ]. These models are also ev aluated using the matched, corr ect, wr ong and false alarm (F A) metrics as proposed in [ 16 ] and computed ov er the one hour stream pro vided with the original dataset. Note that these last metrics are computed after using a post-processing method that ensures a labeling consistenc y as described in the reference paper . As baseline static model, we use a standard neural network architecture used for K eyw ord Spotting aka the cnn-tr ad-fpool3 architecture proposed in [ 12 ] which consists in two conv olutional layers followed by 3 linear layers. W e then proposed a SANAS e xtension of this model (see Figure 2) with additional connections that will be adapti vely acti v ated (or not) during the audio stream processing. In the SANAS models, the recurrent layer g is a one-layer GRU [ 3 ] and the function h mapping from the hidden state x t to the distrib ution ov er architecture Γ t is a one-layer linear module follo wed by a sigmoid activation. The models are learned using the AD AM [ 9 ] optimizer with β 1 = 0 . 9 and β 2 = 0 . 999 , gradient steps between 10 − 3 and 10 − 5 and λ in range [ 10 − ( m +1) , 10 − ( m − 1) ] with m the order of magnitude of the cost of the full model. T raining time is reasonable and corresponds to about 1 day on a single GPU computer . Results obtained by various models are illustrated in T able 1 for the one-hour test stream, and in Figure 4 on the test e valuation set. It can be seen that, at a given lev el of accuracy , the SANAS approach is able to greatly reduce the number of FLOPs, resulting in a model which is much more power efficient. For example, with an a verage cost of 37.7M FLOPs per frame, our model is able to match 86.5% of the words, (80.7% correctly and 5.8% wrongly) while the baseline models match 81.7% and 82.9% of the words with 72.8% and 77.9% correct predictions while having a higher budget of 124.6M and 137.3 FLOPs per frame respectiv ely . Moreover , it is interesting to see that our model also outperforms both baselines in term of accurac y , or regarding the metrics in T able 1. This is due to the fact that, kno wing that we have added shortcut connections in the base architecture, our model has a better expressi ve po wer . Note that in our case, ov er-fitting is avoided by the cost 4 tools for building this dataset are av ailable at http://github.com/TomVeniat/SANAS with the open- source implementation. 5 0 20 40 60 80 100 120 140 0.4 0.5 0.6 0.7 0.8 SANAS cnn-trad-fpool3 cnn-trad-fpool3 + shor tcuts FLOPs per f rame (millions ) Accuracy Figure 4: Cost accuracy curves. Reported results are computed on the test set using models selected by computing the Pareto front o ver the v alidation set. Each point represents a model. 0 200 400 600 20 40 60 80 100 120 140 down go left no of f on right stop unknown up yes bg-noise Epochs FLOPs per f rame (millions ) Figure 5: T raining dynamics. A verage cost per output label during training. The network is able to find an architecture that solv es the task while sampling notably cheaper architectures when only background noise is present in the frames. minimization term in the objectiv e function, while it occurs when using the complete architecture with shortcuts (see Figure 4). Figure 5 illustrates the average cost per possible prediction during training. It is not surprising to show that our model automatically ’ decides’ to spend less time on frames containing background noise and much more time on frames containing words. Moreo ver , at conv ergence, the model also divides its b udget differently on the dif ferent w ords, for example spending less time on the yes words that are easy to detect. 4 Conclusion W e hav e proposed a new model for keyword spotting where the recurrent network is able to auto- matically adapt its size during inference depending on the dif ficulty of the prediction problem at time t . This model is learned end-to-end based on a trade-off between prediction efficienc y and computation cost and is able to find solutions that keep a high prediction accuracy while minimizing the average computation cost per timestep. Ongoing research includes using these methods on larger super -networks and in vestigating other types of b udgets like memory footprint or electricity consumption on connected devices. 6 Acknowledgments This work has been funded in part by grant ANR-16-CE23-0016 “P AMELA ” and grant ANR-16- CE23-0006 “Deep in France”. References [1] Dario Amodei, Rishita Anubhai, Eric Battenber g, Carl Case, Jared Casper , Bryan Catanzaro, Jingdong Chen, Mike Chrzanowski, Adam Coates, Greg Diamos, Erich Elsen, Jesse Engel, Linxi Fan, Christopher Fougner , T on y Han, A wni Y . Hannun, Billy Jun, P atrick LeGresley , Libby Lin, Sharan Narang, Andrew Y . Ng, Sherjil Ozair, Ryan Prenger , Jonathan Raiman, Sanjeev Satheesh, David Seetapun, Shubho Sengupta, Y i W ang, Zhiqian W ang, Chong W ang, Bo Xiao, Dani Y ogatama, Jun Zhan, and Zhenyao Zhu. Deep speech 2: End-to-end speech recognition in english and mandarin. CoRR , abs/1512.02595, 2015. URL http://arxiv. org/abs/1512.02595 . [2] Sercan Ömer Arik, Markus Kliegl, Re won Child, Joel Hestness, Andre w Gibiansk y , Christopher Fougner , Ryan Prenger , and Adam Coates. Conv olutional recurrent neural networks for small- footprint keyw ord spotting. CoRR , abs/1703.05390, 2017. [3] KyungHyun Cho, Bart van Merrienboer , Dzmitry Bahdanau, and Y oshua Bengio. On the properties of neural machine translation: Encoder -decoder approaches. CoRR , abs/1409.1259, 2014. URL . [4] Gabriella Contardo, Ludovic Denoyer , and Thierry Artières. Recurrent neural networks for adapti ve feature acquisition. In Neural Information Pr ocessing - 23rd International Confer ence, ICONIP 2016, K yoto, J apan, October 16-21, 2016, Pr oceedings, P art III , 2016. [5] Ludovic Denoyer and P atrick Gallinari. Deep sequential neural network. CoRR , abs/1410.0510, 2014. URL . [6] Ariel Gordon, Elad Eban, Ofir Nachum, Bo Chen, Tien-Ju Y ang, and Edward Choi. Morphnet: Fast & simple resource-constrained structure learning of deep netw orks. CoRR , abs/1711.06798, 2017. URL . [7] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. CoRR , abs/1512.03385, 2015. URL . [8] Zehao Huang and Naiyan W ang. Data-dri ven sparse structure selection for deep neural networks. CoRR , abs/1707.01213, 2017. URL . [9] Diederik P . Kingma and Jimmy Ba. Adam: A method for stochastic optimization. CoRR , abs/1412.6980, 2014. URL . [10] Esteban Real, Sherry Moore, Andre w Selle, Saurabh Saxena, Y utaka Leon Suematsu, Quoc V . Le, and Alex Kurakin. Large-scale e volution of image classifiers. CoRR , abs/1703.01041, 2017. URL . [11] Esteban Real, Alok Aggarwal, Y anping Huang, and Quoc V . Le. Regularized ev olution for image classifier architecture search. CoRR , abs/1802.01548, 2018. URL abs/1802.01548 . [12] T ara N. Sainath and Carolina Parada. Con volutional neural netw orks for small-footprint keyword spotting. In INTERSPEECH , pages 1478–1482. ISCA, 2015. [13] Raphael T ang and Jimmy Lin. Deep residual learning for small-footprint keyword spotting. In 2018 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing, ICASSP 2018, Calgary , AB, Canada, April 15-20, 2018 , 2018. [14] Raphael T ang, W eijie W ang, Zhucheng T u, and Jimmy Lin. An experimental analysis of the power consumption of con volutional neural networks for keyword spotting. In 2018 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing, ICASSP 2018, Calgary , AB, Canada, April 15-20, 2018 , 2018. 7 [15] T om V eniat and Ludovic Denoyer . Learning time/memory-ef ficient deep architectures with budgeted super networks. In The IEEE Conference on Computer V ision and P attern Recognition (CVPR) , June 2018. [16] Pete W arden. Speech commands: A dataset for limited-vocab ulary speech recognition. CoRR , abs/1804.03209, 2018. URL . [17] Daan W ierstra, Alexander Förster , Jan Peters, and Jürgen Schmidhuber . Solving deep memory pomdps with recurrent polic y gradients. In Artificial Neural Networks - ICANN 2007, 17th International Confer ence, P orto, P ortugal, September 9-13, 2007, Pr oceedings, P art I , 2007. [18] Ronald J. W illiams. Simple statistical gradient-following algorithms for connectionist rein- forcement learning. Machine Learning , 8:229–256, 1992. doi: 10.1007/BF00992696. URL https://doi.org/10.1007/BF00992696 . [19] Y undong Zhang, Nav een Suda, Liangzhen Lai, and V ikas Chandra. Hello edge: Ke yword spotting on microcontrollers. CoRR , abs/1711.07128, 2017. URL 1711.07128 . [20] Barret Zoph and Quoc V . Le. Neural architecture search with reinforcement learning. CoRR , abs/1611.01578, 2016. URL . [21] Barret Zoph, V ijay V asudev an, Jonathon Shlens, and Quoc V . Le. Learning transferable architectures for scalable image recognition. CoRR , abs/1707.07012, 2017. URL http: //arxiv.org/abs/1707.07012 . 8
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment