SDR 재평가 왜 SI SDR이 더 신뢰할까
본 논문은 기존 BSS_eval 툴킷의 SDR 측정 방식이 단일 채널 음성 분리·향상 작업에서 부적절하게 사용되어 과대평가되는 문제점을 지적한다. 저자는 채널 변형을 허용하는 기존 정의를 비판하고, 스케일을 고려한 단일 계수만을 이용하는 SI‑SDR(Scale‑Invariant SDR)과 스케일을 벌점에 포함하는 SD‑SDR을 제안한다. 여러 실험을 통해 SI‑SDR이 원본 SDR보다 왜곡에 더 민감하고 해석이 직관적임을 보이며, 기존 SDR이…
저자: Jonathan Le Roux, Scott Wisdom, Hakan Erdogan
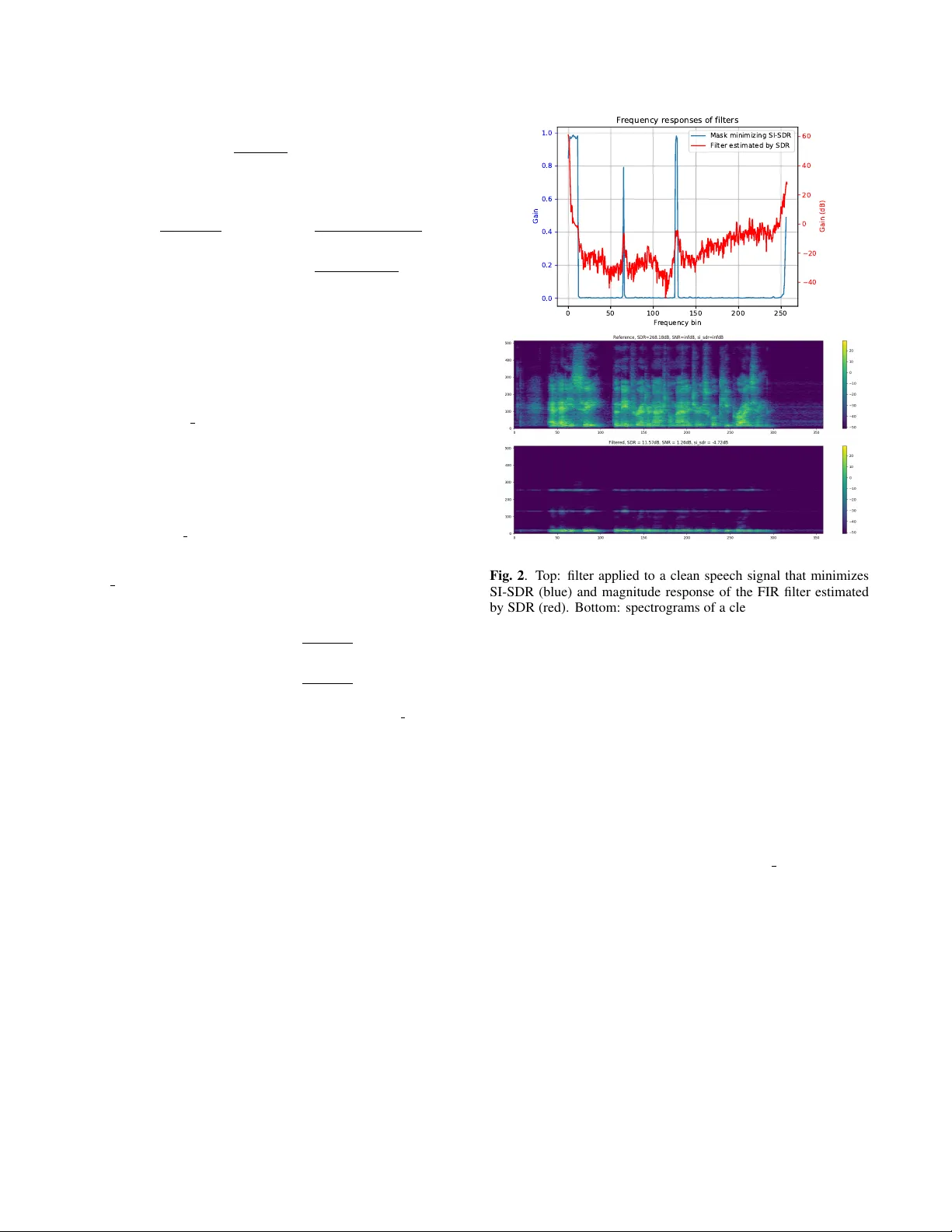
본 논문은 지난 10년간 음성 향상·소스 분리 분야에서 광범위하게 사용되어 온 BSS_eval 툴킷의 SDR 측정 방식이 단일 채널 상황에서 근본적인 한계를 가지고 있음을 지적한다. BSS_eval은 원본 신호와 추정 신호 사이의 차이를 평가하기 위해 두 가지 주요 함수(bss_eval_sources, bss_eval_images)를 제공한다. bss_eval_sources는 512‑tap FIR 필터를 이용해 레퍼런스를 자유롭게 변형하도록 허용하는데, 이는 각 알고리즘이 만든 추정값에 맞춰 레퍼런스를 최적화할 수 있게 하여, 실제 청취 품질과 무관하게 높은 SDR을 얻을 수 있는 구조적 허점이다. 예를 들어, 저주파·고주파 차단 필터를 적용해 신호의 일부 주파수를 0으로 만들더라도, 레퍼런스에 동일한 필터를 적용하면 거의 무한대에 가까운 SDR이 산출된다. 반면 bss_eval_images는 채널 오류를 ISR로 보고, SDR을 단순 SNR로 계산하지만, 스케일(게인) 차이를 고려하지 않아 추정 신호를 임의로 확대·축소함으로써 SNR을 인위적으로 높일 수 있다. 이러한 문제는 특히 논문들에서 0.1 dB 수준의 차이를 근거로 성능 우위를 주장하는 경우에 심각한 오해를 초래한다.
이를 해결하기 위해 저자는 두 가지 새로운 지표를 제안한다. 첫 번째는 Scale‑Invariant SDR(SI‑SDR)이다. SI‑SDR은 추정 신호와 원본 신호 사이의 직교 투영을 통해 최적 스케일 계수 α를 구하고, 스케일된 레퍼런스와 추정 신호 사이의 잔차 에너지만을 오류로 취급한다. 수식적으로는 α = (ŝᵀs) / ‖s‖² 로 정의되며, SI‑SDR = 10·log₁₀(‖αs‖² / ‖αs – ŝ‖²) 로 계산된다. 이는 BSS_eval 버전 2.1의 bss_decomp_gain과 동일한 결과를 제공하면서, 512‑tap FIR 필터 대신 단일 스칼라만을 사용하므로 계산이 매우 효율적이다. 두 번째는 Scale‑Dependent SDR(SD‑SDR)이다. SD‑SDR은 스케일 차이를 오류에 포함시켜, α가 1이 아닌 경우에도 벌점을 부여한다. 구체적으로는 SD‑SDR = 10·log₁₀(‖αs‖² / ‖s – ŝ‖²) 로 정의되며, 이는 SNR에 10·log₁₀(α²) 를 더한 형태가 된다.
또한, 기존 BSS_eval이 제공하는 SIR·SAR의 정의가 직관적이지 못하고, SDR·SIR·SAR 사이에 간단한 로그 관계가 성립하지 않는 문제를 지적한다. 저자는 SI‑SIR과 SI‑SAR를 새롭게 정의하여, e_res를 인터페이스 성분(e_interf)과 아티팩트 성분(e_artif)으로 직교 분해하고, 각각에 대해 10·log₁₀(‖e_target‖² / ‖e_interf‖²) 와 10·log₁₀(‖e_target‖² / ‖e_artif‖²) 로 측정한다. 이 정의에 따르면 SI‑SDR, SI‑SIR, SI‑SAR는 로그 도메인에서 선형 관계 10^(–SI‑SDR/10) = 10^(–SI‑SIR/10) + 10^(–SI‑SAR/10) 를 만족한다.
실험에서는 세 가지 대표적인 실패 사례를 제시한다. 첫 번째는 SI‑SDR을 최소화하도록 설계된 STFT 마스크가 신호의 대부분을 차단함에도 불구하고, 기존 SDR은 11 dB 이상의 높은 값을 유지한다는 점이다. 이는 레퍼런스에 동일한 마스크를 적용함으로써 오류를 회피하는 구조적 결함을 보여준다. 두 번째는 주파수 대역을 점진적으로 삭제하는 실험으로, SDR은 대역을 거의 전부 삭제해도 10~15 dB 수준을 유지하거나 오히려 상승한다. 반면 SI‑SDR·SD‑SDR·SNR은 삭제 비율이 증가할수록 단조롭게 감소하여 실제 품질 저하를 정확히 반영한다. 세 번째는 밴드스톱 필터의 이득을 변화시켜 노이즈 억제 효과를 평가하는 실험이다. 여기서 SDR은 이득이 작아질수록 지속적으로 상승해, 잡음이 많이 억제될수록 오히려 좋은 점수를 주는 역설적 현상이 나타난다. 반면 SI‑SDR과 SNR은 최적 이득(≈0.5)에서 최고점을 찍으며, SD‑SDR은 다운스케일링을 벌점으로 포함해 약간 높은 이득에서 최적을 찾는다.
마지막으로 단일 채널 스피커 독립 음성 분리 작업에 SI‑SDR과 기존 SDR을 적용해 비교한다. 실험 결과, SI‑SDR은 알고리즘 간 성능 차이를 일관되게 반영하고, 작은 개선도 정확히 포착한다. 반면 기존 SDR은 스케일 변동이나 주파수 대역 삭제에 민감하게 반응하지 않아, 실제 청취 품질과 무관한 높은 점수를 부여한다.
결론적으로, 논문은 BSS_eval 툴킷의 SDR이 단일 채널 음성 처리에서 신뢰할 수 없는 지표임을 입증하고, 계산이 간단하면서도 직관적인 SI‑SDR·SD‑SDR을 새로운 표준으로 제안한다. 이는 향후 연구에서 평가 지표 선택에 중요한 가이드라인을 제공하며, 특히 딥러닝 기반 음성 향상·분리 모델의 객관적 성능 비교에 큰 도움이 될 것이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기