유연한 음색 제어를 위한 신경망 음악 합성
본 논문은 악보와 악기 정보를 입력으로 받아 원시 오디오 파형을 생성하는 멜투멜(Mel2Mel) 모델을 제안한다. RNN‑기반의 타임스텝 인코더와 학습된 악기 임베딩을 FiLM 레이어로 결합한 뒤, WaveNet 보코더를 이용해 고품질 음악을 합성한다. 임베딩 공간을 활용한 음색 보간·변형이 가능하며, 정량·정성 평가를 통해 합성 품질을 검증한다.
저자: Jong Wook Kim, Rachel Bittner, Aparna Kumar
본 논문은 “Mel2Mel”이라 명명된 신경망 기반 음악 합성 시스템을 제안한다. 시스템은 크게 두 부분으로 구성된다. 첫 번째는 악보와 악기 정보를 입력받아 Mel 스펙트로그램을 예측하는 인코더이며, 두 번째는 예측된 Mel 스펙트로그램을 실제 오디오 파형으로 변환하는 WaveNet 보코더이다.
입력 전처리는 MIDI 파일을 피아노 롤 형태로 변환하는데, 여기서는 88개의 피아노 건반 각각에 대해 온셋(onset)과 프레임(frame) 정보를 별도로 추출한다. 온셋은 노트가 처음 시작되는 시점을, 프레임은 지속되는 동안의 음량(velocity)을 나타낸다. 두 정보를 176차원 벡터로 결합해 시계열 입력 X를 만든다. 이 입력은 1×1 컨볼루션(시간‑분산 Fully‑Connected)으로 차원을 축소한 뒤, FiLM 레이어를 통해 악기 임베딩 t와 결합된다. FiLM 레이어는 t를 두 개의 선형 변환 f, h에 통과시켜 γ와 β를 얻고, 이를 특성 맵 F에 γ·F + β 형태로 적용한다. 첫 FiLM은 LSTM에 들어가기 전, 두 번째 FiLM은 LSTM 출력 직후에 위치해 각각 시간‑도메인과 주파수‑도메인에서 음색 정보를 조절한다.
LSTM은 양방향 구조를 사용한다. 이는 Mel 스펙트로그램이 한 프레임보다 긴 윈도우(1,024 샘플)로 계산되므로, 현재 시점의 스펙트럼이 미래 프레임에도 영향을 받기 때문이다. LSTM 이후 또 다른 1×1 컨볼루션을 거쳐 80채널 Mel 스펙트로그램을 출력한다.
손실 함수는 세 가지 변형을 실험했으며, 로그‑스케일 MSE와 tanh‑log‑abs MSE가 원본 스펙트로그램과 높은 피어슨 상관을 보였다. tanh‑log‑abs는 저에너지 구간에 대한 패널티를 완화해 학습 안정성을 높인다.
WaveNet 보코더는 NVIDIA의 nv‑wavenet2 구현을 기반으로 20‑layer, 최대 dilation = 512 구조를 사용한다. 입력 Mel 스펙트로그램은 2개의 전치 컨볼루션(커널 16, 32, stride 8, 16)으로 업샘플링된다. µ‑law 8‑bit 양자화와 16 kHz 샘플링 레이트를 적용해 원본과 동일한 포맷을 유지한다.
데이터는 10개의 General MIDI 악기를 선택해 FluidSynth와 MuseScore SoundFont로 합성한 3,340개의 트랙(총 221 시간)으로 구성했다. 각 악기는 334개의 트랙을 가지고, 320개는 훈련, 14개는 검증에 사용한다. 추가 실험에서는 100개의 고품질 SoundFont 기반 악기 집합도 구축했다.
Ablation 연구에서는 (1) 온셋·프레임 동시 사용, (2) 첫 FiLM 레이어 유지, (3) 양방향 LSTM 포함이 성능에 가장 크게 기여함을 확인했다. 모델 용량을 늘리면 훈련 손실은 감소하지만 검증 손실이 오히려 상승해 과적합이 발생한다는 점을 발견했다. 이는 모델이 음표 시퀀스를 암기하는 경향을 나타낸다.
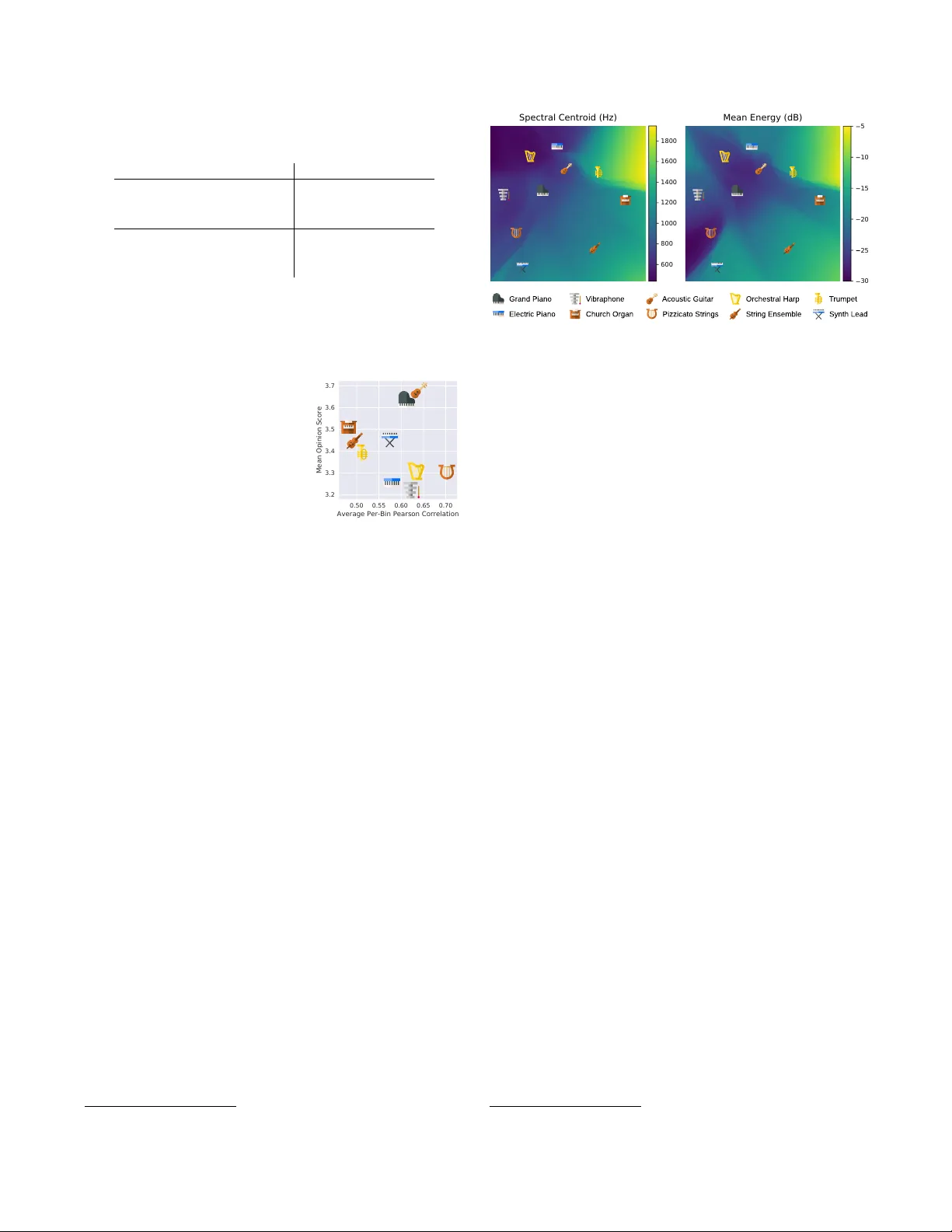
음질 평가는 두 축으로 진행됐다. 첫째, Pearson 상관을 이용해 원본 오디오와 각 단계(µ‑law 인코딩, Ground‑truth Mel → WaveNet, 손실 기반 모델) 사이의 유사성을 정량화했다. 결과는 저주파에서 상관이 낮아 WaveNet의 고정 수용 영역이 저주파 주기를 충분히 포착하지 못함을 보여준다. 둘째, 크라우드소싱 MOS 테스트를 수행해 5점 척도(0.5점 간격)로 청취 품질을 평가했다. 원본은 4.30점, µ‑law 인코딩은 3.88점, Ground‑truth Mel → WaveNet은 3.38점, tanh‑log‑abs MSE 기반 모델은 3.18점, log‑abs MSE는 3.02점, 절대값 MSE는 2.75점을 기록했다.
결과적으로 Mel2Mel은 악기 임베딩을 통해 음색을 연속적으로 조절·보간할 수 있는 유연성을 제공한다. 임베딩은 2차원으로 제한했음에도 시각화와 인터폴레이션 실험에서 의미 있는 음색 변화를 확인했으며, 웹 데모를 통해 실시간 인터랙션이 가능함을 시연한다. 향후 연구 과제로는 (1) 임베딩 차원 확대와 더 풍부한 라벨링, (2) 실제 녹음 데이터를 활용한 사전 학습, (3) 저주파 재현성을 높이기 위한 WaveNet 구조 개선, (4) 다중 악기·다중 트랙을 동시에 다루는 확장 모델 설계 등이 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기