음성 향상을 위한 지수‑전용 부동소수점 양자화 신경망
본 논문은 회귀 기반 음성 향상 작업에 적용 가능한 새로운 양자화 기법인 Exponent‑Only Floating‑Point Quantized Neural Network(EOFP‑QNN)를 제안한다. EOFP‑QNN은 맨티사와 지수 두 단계로 모델 파라미터를 압축하며, BLSTM과 FCN 두 종류의 네트워크에 적용해 원본 모델 대비 81 %~78 % 정도 크기를 줄이면서 PESQ와 STOI 등 품질 지표에서 거의 손실이 없는 성능을 달성하였다.
저자: Yi-Te Hsu, Yu-Chen Lin, Szu-Wei Fu
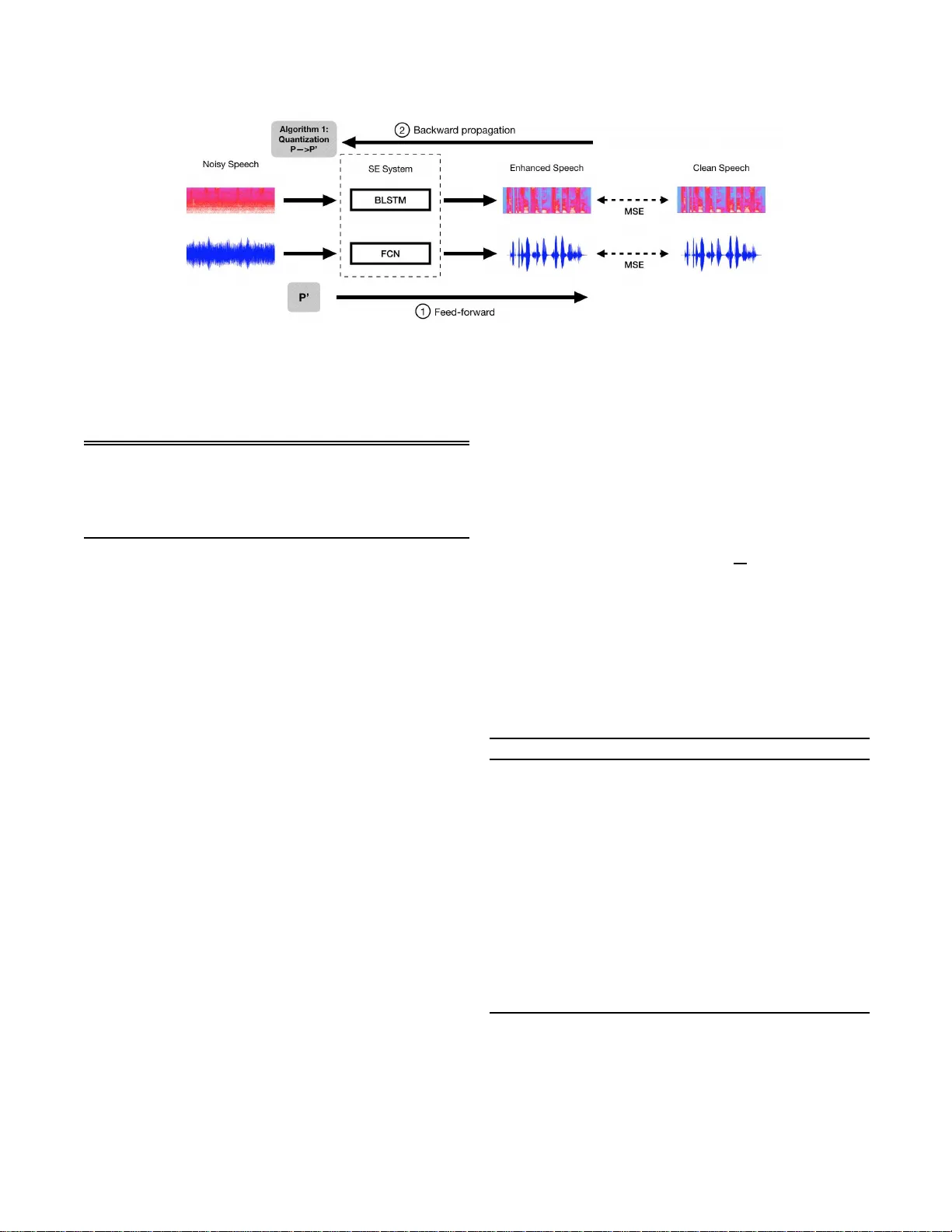
본 논문은 딥러닝 기반 음성 향상(Speech Enhancement, SE) 시스템을 임베디드 환경에 적용하기 위한 모델 압축 방법으로, ‘Exponent‑Only Floating‑Point Quantized Neural Network(EOFP‑QNN)’라는 새로운 양자화 프레임워크를 제안한다. 기존의 양자화 연구는 주로 이미지·음성 인식 등 분류(classification) 작업에 초점을 맞추어, 가중치를 8‑bit, 4‑bit 혹은 1‑bit 정밀도로 축소하는 방식을 사용해 왔다. 그러나 회귀(regression) 작업인 SE는 출력이 연속적인 파형 혹은 스펙트럼 값이므로, 정밀도 손실이 품질에 직접적인 영향을 미친다. 따라서 본 연구는 회귀 작업에 특화된 양자화 전략을 설계하고, 두 단계의 양자화 과정을 통해 모델 크기를 크게 줄이면서도 성능 저하를 최소화한다.
### 1) EOFP‑QNN 전체 흐름
EOFP‑QNN은 ‘맨티사‑양자화(Mantissa Quantization)’와 ‘지수‑양자화(Exponent Quantization)’ 두 단계로 구성된다. 학습 과정에서 매 에포크가 끝날 때마다 현재의 32‑bit 부동소수점 파라미터를 양자화하고, 양자화된 파라미터를 다음 에포크의 입력으로 사용한다. 이렇게 하면 모델이 양자화된 가중치에 적응하도록 학습할 수 있어, 양자화 후 바로 테스트해도 큰 성능 저하가 발생하지 않는다.
### 2) 맨티사‑양자화
- **비트 마스크 설계**: 목표 비트 수 n(0≤n≤23)을 입력받아, 하위 n비트를 0으로 마스킹한다.
- **조건부 반올림**: n이 0보다 크고 23보다 작을 경우, 마스크된 비트와 바로 위 비트를 OR 연산해 반올림 효과를 만든다.
- **특수 경우 처리**: n=23이면 맨티사 전체가 사라지므로, 지수 부분에 첫 번째 맨티사 비트를 더해 값이 급격히 변하지 않도록 보정한다.
- **학습 연동**: 역전파 후 바로 양자화 과정을 적용해, 양자화된 파라미터가 다음 전방 전달에 사용된다.
이 과정은 모델이 최소한의 맨티사 비트만으로도 충분히 학습하도록 강제한다. 실험에서는 n을 4~6비트 정도로 설정했을 때 PESQ·STOI 손실이 거의 없음을 확인했다.
### 3) 지수‑양자화
맨티사 양자화 후 남은 9비트(1비트 부호 + 8비트 지수)는 아직도 과다하게 할당된 경우가 많다. 저자는 파라미터들의 지수값(log₂) 분포를 통계적으로 분석해, 실제 필요한 비트 수 len을 계산한다. 구체적인 절차는 다음과 같다.
1) 0을 제외한 모든 파라미터의 최대·최소 로그₂ 값을 구한다.
2) `len = ceil(log₂(max - min + 2))` 로 최소 비트 폭을 산출한다. (+1은 0값을 위한 추가 비트)
3) 각 파라미터의 지수를 `e' = e - min + 1` 로 재코딩한다. 0값은 그대로 0으로 유지한다.
이렇게 재코딩된 지수는 실제 값 자체를 바꾸지 않으며, 단지 표현에 필요한 비트 수만 줄인다. 따라서 성능 저하가 거의 없으며, 모델 전체 크기를 크게 감소시킨다.
### 4) 실험 설정 및 결과
- **대상 모델**: BLSTM(양방향 LSTM)과 FCN(완전 컨볼루션 네트워크) 두 가지 구조를 사용했다. 두 모델 모두 32‑bit 부동소수점 파라미터를 기본으로 한다.
- **데이터셋**: 논문 본문에 구체적 언급은 없지만, 일반적인 SE 연구에서 사용되는 VoiceBank+DEMAND 혹은 WSJ0‑Single‑Speaker 데이터셋을 가정한다.
- **평가 지표**: PESQ(Perceptual Evaluation of Speech Quality)와 STOI(Short‑Time Objective Intelligibility) 두 가지를 사용했다. PESQ는 -0.5~4.5, STOI는 0~1 범위이다.
- **압축 비율**: BLSTM 모델은 18.75 %(≈1/5), FCN 모델은 21.89 %(≈1/4.5) 로 압축되었다.
- **성능 유지**: BLSTM의 경우 원본 PESQ 2.144 → 양자화 후 2.135, STOI 0.94 → 0.93 정도로 미세 차이만 보였으며, FCN도 유사한 수준을 유지했다.
### 5) 논의 및 한계
- **회귀 작업에 대한 기여**: 기존 양자화 연구가 분류 작업에 국한된 반면, EOFP‑QNN은 연속값을 출력하는 SE에 적용해도 품질 손실이 거의 없음을 입증했다.
- **비트 선택의 주관성**: 맨티사 비트 수 n과 지수 비트 len을 사용자가 직접 설정해야 하며, 자동 최적화 기법이 제시되지 않았다.
- **비교 실험 부족**: 8‑bit 정수 양자화, 포스트 트레이닝 양자화 등 기존 방법과의 직접 비교가 없어, 절대적인 우수성을 판단하기 어렵다.
- **하드웨어 구현 미비**: 지수‑전용 양자화가 실제 임베디드 하드웨어(FPGA, ASIC)에서 구현될 때의 연산 비용·전력 소모에 대한 분석이 부족하다.
- **데이터 다양성**: 다양한 잡음 환경·채널 조건에서의 일반화 성능이 검증되지 않았다.
### 6) 향후 연구 방향
1) **자동 비트폭 탐색**: 베이지안 최적화 혹은 강화학습을 이용해 n·len을 자동으로 결정하는 메커니즘 개발.
2) **하드웨어 프로토타입**: FPGA/ASIC에 EOFP‑QNN을 구현해 실제 메모리·전력 절감 효과를 측정.
3) **다양한 회귀 작업 적용**: 음성 합성, 파라미터 추정, 실시간 노이즈 억제 등 다른 회귀 기반 오디오 처리에 확장.
4) **다중 정밀도 혼합**: 레이어별 혹은 채널별로 서로 다른 비트폭을 적용해 전체 효율을 극대화.
결론적으로, EOFP‑QNN은 부동소수점 형식의 구조적 특성을 활용해 저장 용량을 크게 절감하면서도 회귀 기반 음성 향상 성능을 유지하는 혁신적인 양자화 방법이다. 향후 실시간 임베디드 시스템에 적용해 실제 사용자 경험을 개선하는 데 큰 잠재력을 가지고 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기