대규모 환경 잡음 임베딩을 활용한 보이지 않는 환경에서의 음성 향상
본 논문은 두 가지 핵심 전략으로 보이지 않는 환경에서의 음성 향상 성능을 크게 높인다. 첫째, 동일 환경에서 별도로 녹음한 잡음 샘플을 임베딩하여 메인 향상 네트워크에 주입한다. 둘째, 학습 단계에서 16,784개의 서로 다른 잡음 환경을 사용해 데이터 규모를 확대한다. 실험 결과, 잡음 임베딩과 대규모 잡음 데이터 모두가 사전 학습된 음성 인식기의 단어 오류율(WER)을 34.04 %에서 최종 모델은 15.46 %로 감소시켰으며, PESQ·…
저자: Gil Keren, Jing Han, Bj"orn Schuller
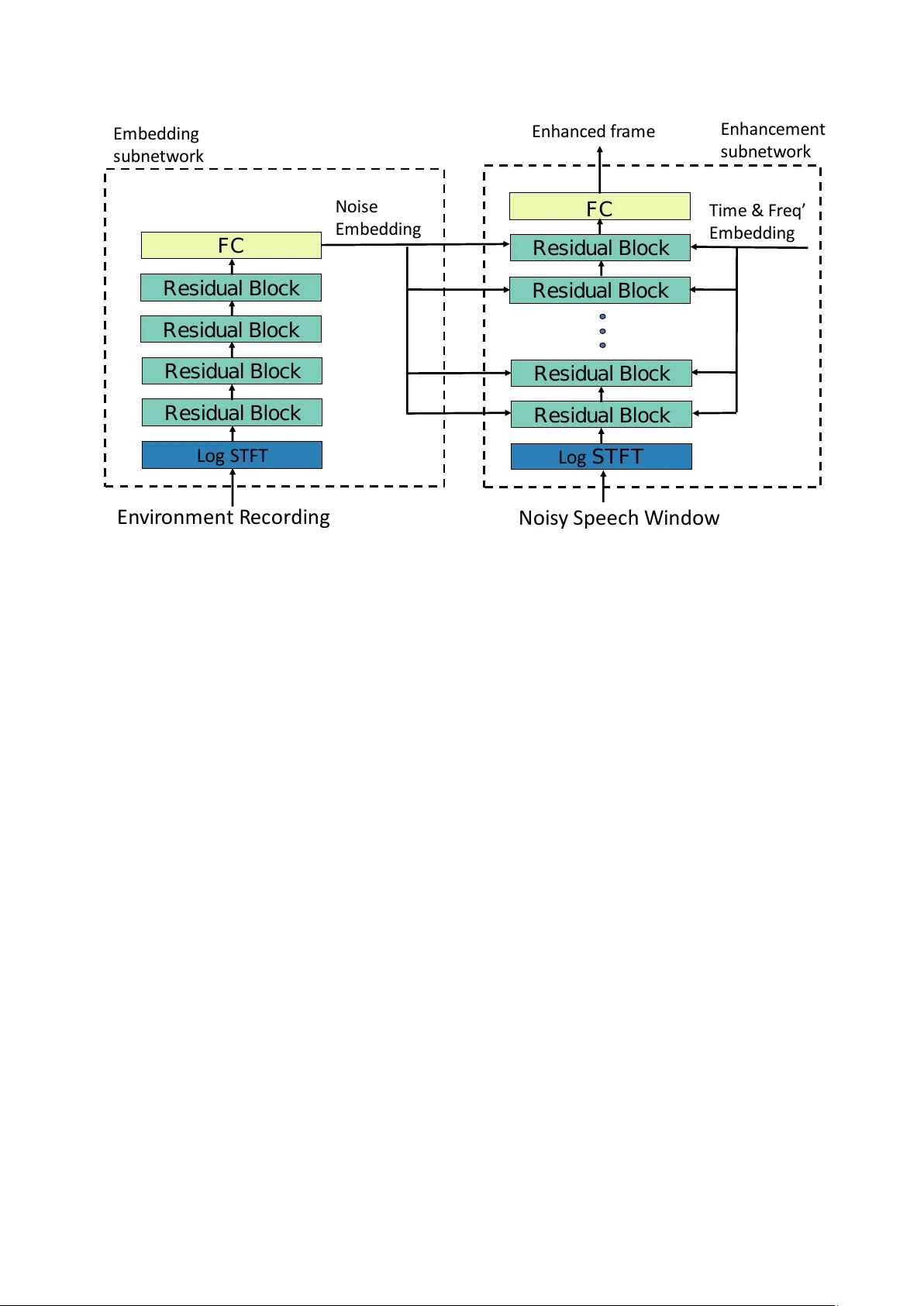
본 논문은 실생활에서 마주치는 다양한 환경 잡음에 대해 사전 학습된 음성 향상 모델이 보이지 않는(미지의) 환경에서도 강인하게 동작하도록 두 가지 주요 전략을 제안한다. 첫 번째 전략은 **환경 잡음 임베딩**이다. 동일한 환경에서 잡음만을 별도로 녹음한 짧은 클립을 네트워크에 입력해 512‑차원 임베딩 벡터를 생성한다. 이 임베딩은 메인 향상 서브네트워크의 모든 convolution 레이어에 선형 변환 후 더해져, 각 레이어가 현재 환경의 잡음 특성을 직접 반영하도록 만든다. 이렇게 하면 기존의 noise‑aware 입력(예: 평균 잡음 스펙트럼)보다 더 풍부하고 구체적인 환경 정보를 제공할 수 있다.
두 번째 전략은 **학습 데이터 규모 확대**이다. AudioSet에서 인간 음성·음악을 제외한 2,100,000개의 10초 클립 중 16,784개의 서로 다른 잡음 샘플을 선택하고, Librispeech(360 시간)의 깨끗한 음성과 0, 5, 10, 15, 20, 25 dB의 다양한 SNR로 혼합한다. 이렇게 방대한 잡음 다양성을 학습에 포함함으로써, 모델이 잡음 공간을 연속적인 고차원 분포로 인식하고, 미지의 환경에서도 유사한 특성을 찾아내어 일반화한다는 가설을 검증한다. 실험 결과, 잡음 종류를 200→1,000→16,784로 늘릴 때마다 WER이 21.51 %→20.54 %→16.78 %로 꾸준히 감소했고, PESQ·SegSNR·LSD 등 객관적 품질 지표도 전반적으로 향상되었다.
**모델 아키텍처**는 두 부분으로 구성된다.
1) **임베딩 서브네트워크**: 4개의 residual block(각 block은 2개의 2D‑conv 레이어와 batch‑norm, ReLU로 구성)으로 잡음 클립을 처리한다. 첫 두 block은 8×4 커널·stride = 3×2, 마지막 두 block은 4×4 커널·stride = 1×1·1×2를 사용한다. 채널 수는 64→128→256→512이며, 마지막에 전역 평균 풀링을 수행해 512‑차원 벡터를 얻는다.
2) **향상 서브네트워크**: 8개의 residual block으로 구성되며, 앞 4개 block은 4×4 커널, 뒤 4개는 3×3 커널을 사용한다. 채널 수는 64→128→256→512로 점진적으로 증가한다. 각 convolution 레이어의 출력에 임베딩을 선형 변환해 더하고, 시간·주파수 위치 임베딩(두 개의 50‑dim fully‑connected MLP)도 추가한다. 마지막에 flatten 후 201‑dim fully‑connected 레이어를 거쳐 마스크를 생성하고, 이를 noisy 프레임의 중앙 프레임에 더해 향상된 프레임을 만든다. 손실 함수는 MSE이며, SGD(learning rate = 0.1)로 학습한다.
**데이터 처리**는 모든 오디오를 16 kHz로 샘플링하고, 25 ms 윈도우·10 ms hop으로 STFT를 수행해 201개의 주파수 bin을 얻는다. 로그 스펙트럼에 1e‑7을 더해 로그를 취함으로써 작은 값에 대한 과도한 민감도를 방지한다. 학습 시에는 noisy speech와 noise segment를 각각 n = 200, r = 35 프레임 길이로 잘라 입력한다.
**평가**는 사전 학습된 DeepSpeech(모스키라) 모델을 이용해 WER을 측정하고, PESQ, SegSNR, LSD를 보조 지표로 사용한다. 베이스라인으로는 전통적인 Log‑MMSE와 noise‑aware training(잡음 평균을 추가 입력) 방법을 비교한다. 결과는 다음과 같다.
- Clean speech: WER = 4.21 % (참고)
- Noisy speech (0‑25 dB): WER = 34.04 %
- Log‑MMSE: WER ≈ 35 % (오히려 악화)
- Noise‑aware: WER = 25.30 %
- Ours‑NoEmb (200 noises): WER = 21.51 %
- Ours‑NoEmb (1,000 noises): WER = 20.54 %
- Ours‑NoEmb (All 16,784): WER = 16.78 %
- Ours‑WithEmb (All + embedding): WER = 15.46 %
SNR 별 상세 WER에서도 동일한 추세가 관찰된다. 특히 25 dB 조건에서는 향상된 음성의 WER이 4.05 %로, 원본 깨끗한 음성(4.21 %)보다 낮아, 모델이 미세한 배경 잡음까지 억제하고 음성 신호를 실제보다 더 깨끗하게 만든 것으로 해석된다.
**의의와 한계**:
- **실용성**: 디바이스가 사전에 짧은 환경 잡음 샘플을 녹음하고, 이를 임베딩으로 활용해 실시간으로 음성을 정제할 수 있다.
- **스케일링**: 16,784개의 잡음 환경을 학습에 포함함으로써, 잡음 공간을 충분히 커버하고 unseen 환경에서도 좋은 일반화를 달성한다.
- **제한점**: 현재는 16 kHz, 25 ms 프레임 기반의 스펙트럼 마스크 방식이며, phase 정보를 직접 개선하지 않는다. 또한 임베딩을 얻기 위해 별도의 잡음 녹음이 필요하므로, 완전한 “one‑shot” 상황에서는 적용이 어려울 수 있다.
향후 연구는 (1) phase‑aware 복원, (2) 임베딩을 추정하는 비지도 방법, (3) 더 큰 규모의 멀티채널 잡음 데이터 등을 탐색함으로써, 실제 모바일/IoT 디바이스에 적용 가능한 경량화 모델을 개발하는 방향으로 나아갈 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기