Scaling Speech Enhancement in Unseen Environments with Noise Embeddings
We address the problem of speech enhancement generalisation to unseen environments by performing two manipulations. First, we embed an additional recording from the environment alone, and use this embedding to alter activations in the main enhancemen…
Authors: Gil Keren, Jing Han, Bj"orn Schuller
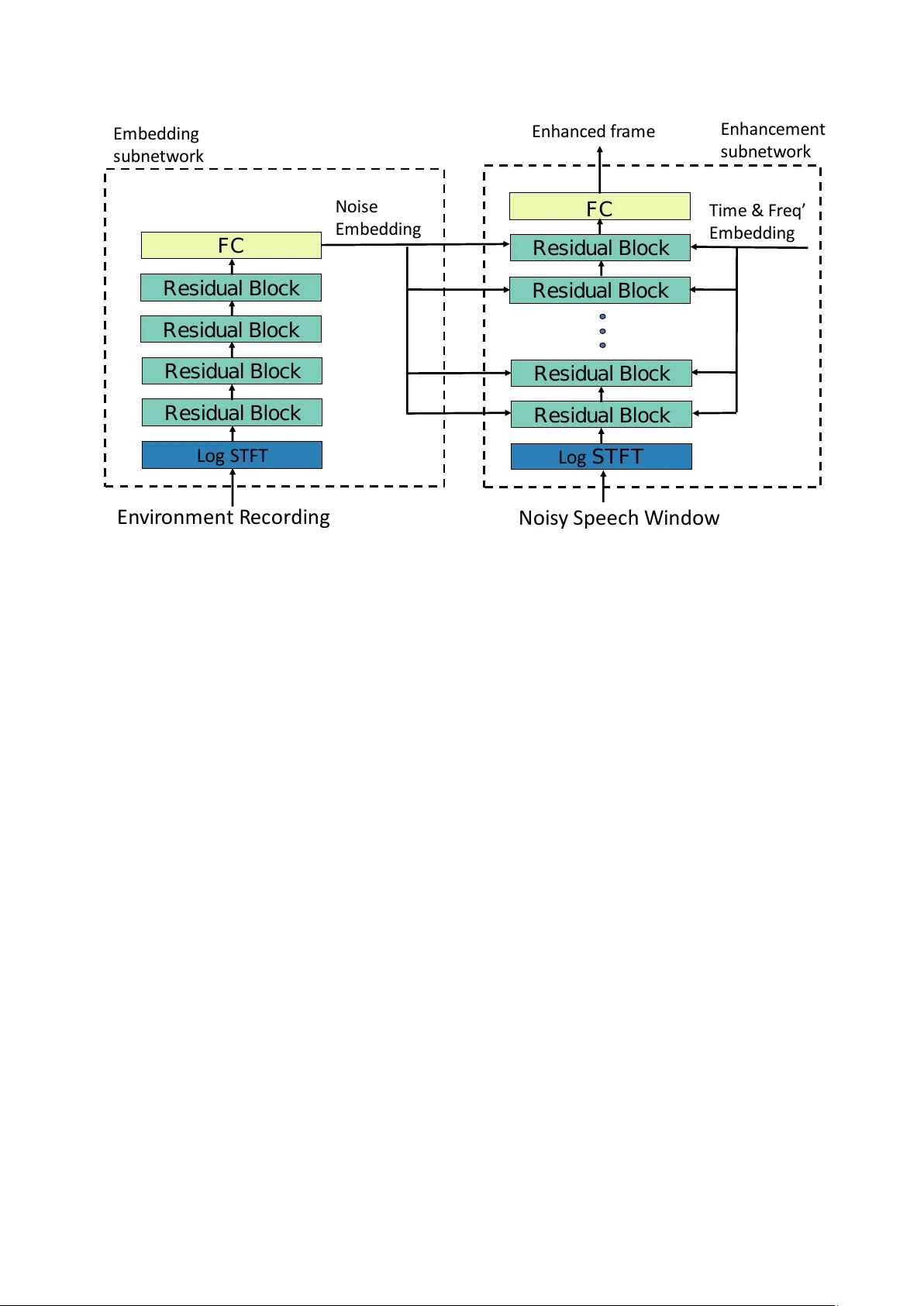
Scaling Speech Enhancement in Unseen En vir onments with Noise Embeddings Gil K er en 1 , Jing Han 1 , Bj ¨ orn Schuller 1 , 2 1 ZD.B Chair of Embedded Intelligence for Health Care and W ellbeing, Uni versity of Augsb urg, Germany 2 GLAM – Group on Language, Audio & Music, Imperial College London, UK cruvadom@gmail.com Abstract W e address the problem of speech enhancement generalisa- tion to unseen environments by performing two manipulations. First, we embed an additional recording from the en vironment alone, and use this embedding to alter activ ations in the main enhancement subnetwork. Second, we scale the number of noise en vironments present at training time to 16,784 different en vironments. Experiment results sho w that both manipulations reduce word error rates of a pretrained speech recognition sys- tem and improve enhancement quality according to a number of performance measures. Specifically , our best model reduces the word error rate from 34.04% on noisy speech to 15.46% on the enhanced speech 1 . 1. Introduction Speech processing in e veryday life presents the challenge of ob- taining good model performance across a large variety of en- vironments. In fact, the v ariety of real-world en vironments is large enough to assume that a speech processing model would be required to perform well in unseen environments that do not closely resemble the ones present during its training stage. While many existing approaches to speech enhancement focus on a small number of en vironments or environments that are similar to each other [1, 2, 3], in contrast, in this work we aim at designing a speech enhancement model that performs well across a large v ariety of en vironments, many of which could be considerably different from the ones seen at training time. T o this end, we explore two methods we expect to con- tribute to speech enhancement generalisation to unseen envi- ronments. First, inspired by one-shot learning models [4], we do not think of the noise en vironments used in this work as dis- tinct unrelated categories, but rather as samples from a lar ge space that contains all noise en vironments. In this setting, good speech enhancement in an unseen noise en vironment would amount to generalising to an unseen point in the noise en vi- ronments space. Therefore, to facilitate good generalisation in this space, we scale up the training set size to include noises from 16,784 different en vironments, mixed with 360 hours of clean speech and different Signal-to-Noise Ratios (SNRs). As the number of en vironments seen during training is large, we expect those environments to share some properties with the unseen test environments, that may assist in the enhancement process. Moreov er , we hypothesise that providing the network with an additional recording of the same environment may assist the network in identifying which frequenc y components need to be remov ed and which need to be enhanced. Specifically , we con- dition our model on an additional recording that contains no 1 Enhanced audio samples can be found in https: //speechenhancement.page.link/samples speech, from the same environment as the noisy speech seg- ment. A dedicated subnetw ork processes this additional record- ing to create a noise embedding , that is in turn injected to all layers of the main enhancement subnetwork. This is a plausible scenario, as enhancement devices may record an en vironment noise sample just before recording the noisy speech. In experiments, we show that both manipulations result in better speech enhancement compared to baseline methods, as measured by the W ord Error Rate (WER) of a pretrained speech recognition system, as well as a number of objecti ve e valuation metrics. Specifically , while WER on noisy speech with SNR of 0-25 dB was 34.04%, using our enhancement model with as lit- tle as 200 training noise en vironments and no noise embeddings reduced WER for unseen noise en vironments to 21.51%. Scal- ing up the the number of training noise environments to 16,784 managed to reduce WER to 16.78%. Finally , using the noise embeddings computed from additional en vironment recordings reduced WER to 15.46%. 2. Data generation As motiv ated above, we aim to improve audio enhancement generalisation to unseen en vironments by training an enhance- ment model with a large number of en vironment noises. T o this end, we mix clean speech utterances from the Librispeech cor- pus [5] with different noise recordings from the recently pub- lished Audio Set [6]. The Audio Set corpus contains 2,100,000 audio segments of 10 seconds extracted from Y ouT ube videos, manually anno- tated in a multi-label manner for a hierarchical ontology of 632 audio categories, cov ering a wide range of human and animal sounds, musical instruments and genres, and common ev ery- day environmental sounds. Audio Set contains recordings of a large number noises with great di versity over noise sources and recording conditions, therefore is challenging and may be a good approximation of the set of noises coming from natu- ral everyday environments. W e use noises from all categories in Audio Set’ s ontology , excluding noises that are labelled as ‘Human sounds’ or ‘Music’ (as those may contain speech). The clips were selected randomly , in a manner that balances between the amount of noises from each of the top categories in the on- tology . W e found that a small portion of the noises that were not labelled as containing human speech did contain utterances of human speech anyway . T o make sure that at test time we enhance audio from un- seen en vironments, each noise segment is assigned to either the training, validation or test set. In total, in our training set we use 16,784 different recordings of different en vironments/noises, 656 in the validation set and 740 in the test set. The clean speech utterances we mix with environment noises were taken from the Librispeech corpus. The corpus is freely available for downloading, and includes a train, v alidation and test splits. The Librispeech training set is comprised of 360 hours of audio L o g S T F T Re s i d u a l B l o c k FC Re s i d u a l B l o c k Res i d u a l B l o c k Res i d u a l B l o c k E n v i r o n m en t R ec o r d i n g N o i s y S p eec h W i n d o w L o g S T F T Re s i d u a l B l o c k FC Re s i d u a l B l o c k Res i d u a l B l o c k Res i d u a l B l o c k N o i s e E m b e d d i n g E m b e d d i n g s u b n e tw o r k T i m e & F r e q ’ E m b e d d i n g E n h an c e m e n t s u b n e tw o r k E n h an c e d f r am e Figure 1: The enhancement model arc hitectur e. The embedding subnetwork pr ocesses an envir onment recor ding thr ough a sequence of r esidual blocks to pr oduce a fixed length vector that is the noise embedding. In the main enhancement subnetwork, the noisy speech r ecording is pr ocessed thr ough another sequence of r esidual blocks, eac h conditioned on the noise embedding and additional positional embeddings, to emit one enhanced speech fr ame. from 921 speakers, where the validation and test sets contain 5.4 hours of speech and 40 speakers each. For the enhancement task training, validation and test sets, we mix clean utterances from the corresponding set in the Librispeech corpus. Clean speech utterances are mixed with the environment recordings using SNRs of 0, 5, 10, 15, 20 and 25 dB. For the training set, during training a random speech utterance is mix ed with a random noise recording with a random SNR, to obtain the largest ef fective training set size. For the v alidation and test sets, one environment noise recording and SNR are fix ed for ev ery utterance. 3. Enhancement model W e design a neural network enhancement model, that can be conditioned on environment noise samples and has a large ca- pacity that corresponds to the large training set. W e represent all audio se gments as their log magnitude spectrum, which is obtained by taking the log absolute value of the Short-T ime Fourier T ransform (STFT) over 25 ms frames shifted by 10 ms, where 10 − 7 is added before computing the log function to pre- vent the model from trying to fit unimportant differences in magnitude. All audio recordings we use have a sample rate of 16kHz, which results in 201 coefficients for each frame. Our enhancement model processes two inputs: n frames of noisy speec h se gment (speech mix ed with noise, as described in Section 2) and r frames that are the noise segment (in our ex- periments we found the best values are n = 200 and r = 35 ). It is important to note that in all cases the noise segment and the noise that w as mixed into the noisy speech segment are from the same recording, but from different parts of this recording. This better simulates a real-world situation, where an enhancement device may record the en vironment sound alone, just before recording the noisy speech. The network processes the two in- puts and then outputs the enhanced fr ame . The enhanced frame is the network approximation for the central frame of the clean speech recording (before mixing it with noise), which we refer to as the clean frame . A diagram of our enhancement model architecture is found in Figure 1. 3.1. Embedding subnetwork W e first process the noise segment through an embedding sub- network to create the noise embedding. The embedding subnet- work is comprised of a sequence of 4 residual blocks [7], each comprised of two 2D-conv olutional layers (we treat the time and frequency as spatial axes). The conv olutional layers of the first two residual blocks use a kernel size of 8 × 4 (time steps ov er frequency components) with a stride of 3 × 2 , where the con volutional layers of the last two residual blocks use a 4 × 4 kernel with a 1 × 1 and 1 × 2 stride respectiv ely . The num- ber of feature maps for the conv olutional layers in each of the four residual block are 64, 128, 256, 512 respectiv ely . Inside each residual block, batch normalisation [8] is applied on the output of the first con volutional layer , followed by a rectified linear acti vation function. Then, the second con volutional layer is applied and its output is added to the block’ s input. Batch normalisation is then applied again, followed by another recti- fied linear activ ation function to return the block’ s output. After applying the four residual blocks, we av erage each feature map across all locations, to obtain a single 512-dimensional vector that is the noise embedding. 3.2. Enhancement subnetwork The enhancement subnetwork then processes the noisy speech segment and the noise embedding, to output the enhanced frame. This subnetwork is comprised of a sequence of 8 resid- ual blocks, processing the noisy speech segment. In those resid- ual blocks, for each con volutional layer , the noise embedding is linearly projected to a dimension equal to the number of feature maps in this con volution layer . This projected noise embedding is then added to each location in the output map of the con volu- tion layer . By doing so, we inject the noise embedding along all parts of the deep network, allowing each part to emit different outputs based on the current en vironment noise that should be remov ed from the audio. Additionally , to allow the netw ork to process differently the different frequency components and time steps, we embed the time steps and frequency components (location embeddings) in- dices and add these embeddings to the appropriate locations in the output map of each con volutional layer . The location em- beddings are emitted using a small neural network. The input of this network is a single integer that represents the location in the appropriate axis (time / frequency), which is processed through two 50-dimensional fully-connected layers with recti- fied linear activ ation function and batch normalisation. Except the described above, the structure of each residual block in this subnetwork is identical to those in the embedding subnetwork. The con volutional layers in the first 4 residual blocks of the enhancement subnetwork use a 4 × 4 kernel, where a 3 × 3 kernel is used in the last 4 residual blocks. A 2 × 2 stride is applied in residual blocks number 3, 5 and 7. The first two residual blocks use 64 feature maps for each conv olutional layer , followed by 128, 256 and 512 feature maps for the next groups of 2 residual blocks. For the final part of the enhancement subnetwork, we flatten the output of the last residual block and feed it into a fully- connected layer with 201 output v alues. The output of this layer is treated as an enhancement mask , which is added to the central frame of the noisy speech segment to yield the enhanced frame. During training, network parameters are optimised to minimise the mean squared error between the enhanced frame and the clean frame. In our e xperiments we used Stochastic Gradient Descent (SGD), where 0 . 1 was found to be the best learning rate. 4. Experiments W e conduct a series of experiments to study the effect of noise embeddings and the number of different en vironment noises av ailable in training time on speech enhancement performance. In verse Short-Time Fourier Transform (ISTFT) was ap- plied to the enhanced magnitude spectrogram, together with the phase of the noisy speech, to reconstruct a wav eform from each enhanced log magnitude spectrum. T o measure the suc- cess of each of our speech enhancement models, we used the following ev aluation metrics. The first ev aluation metric is the WER obtained by feeding the enhanced audio to a pretrained ‘Deep Speech’ speech recognition system [9], where a model that was trained on the Librispeech dataset can be found in https://github.com/mozilla/DeepSpeech . In ad- dition, we computed three other well established metrics for the assessment of speech audio quality: the Perceptual Evaluation of Speech Quality (PESQ) [10], that is an industry standard for objecti ve voice quality testing, Segmental Signal-to-Noise Ratio (SegSNR) [11] and Log-Spectral Distortion (LSD) [12], T able 1: Comparison of test set evaluation metrics for all en- hancement models and the noisy speech. ‘No Emb x’ stands for the model with no noise embedding wher e x is the number of en vironment noises available at training time. Best r esults in bold. P erformance in all evaluation metrics impr oves with the incr ease in the number of training envir onments r ecordings, and using noise embedding further impr oves performance. Method WER PESQ SegSNR LSD Clean Speech 4.21 — — — Noisy Speech 34.04 2.59 7.02 0.94 Log-MMSE 35.38 2.66 7.12 0.91 Noise A ware 25.30 2.96 11.01 0.54 Ours - No Emb’ 200 21.51 3.12 10.03 0.53 Ours - No Emb’ 1000 20.54 3.13 10.00 0.52 Ours - No Emb’ All 16.78 3.25 11.71 0.48 Ours - W ith Emb’ 15.46 3.30 12.99 0.45 that ev aluate the clean speech features reconstruction in differ- ent manners. W e compared the enhancement performance of sev eral models. First, we e v aluated our hypothesis that speech en- hancement performance in unseen en vironments is closely re- lated to the number of dif ferent en vironment noises appearing during training time. T o this end, we compared three identical enhancement networks, trained with utterances that are mixed with 200, 1000, and our full training set of 16,784 environment noises respectively . These enhancement networks do not use the noise embedding, which is otherwise added to the output of the con volutional layers. Second, to study the effect of the noise embedding, we trained another identical enhancement network with the full training set of en vironment noises, that does use the noise embedding as described in Section 3. Finally , we compared our proposed netw ork with tw o other baselines, Log-MMSE and noise-a ware training. Log-MMSE [13] is a more traditional, non-neural network enhancement method, while in noise-aware training [2] an estimation of the noise is gi ven to a fully-connected enhancement network as ad- ditional features. In our case, we average frames of the noise segment along the time axis to create the noise estimation used in noise a ware training, in a manner inspired from [2]. W e optimise the number of layers (3-7), hidden units (500-2000) and regularisation (batch normalisation) in the fully-connected network used in noise-aware training. In all cases, model pa- rameters were chosen using the validation set, for each method separately . The training, validation and test sets all contain dif- ferent en vironment noises, to assess the model’ s performance in unseen en vironments. T est set results for all enhancement methods and the noisy speech can be found in T able 1, av eraged across all SNRs. Our test set contains noisy speech from noise en vironments, speak- ers and utterances that did not appear in training time. First, we observe that the pretrained speech recognition system obtained a 4.21% WER on the clean speech, while obtaining 34.04% on the noisy speech before applying any enhancement method. The Log-MMSE baseline did not manage to considerably im- prov e over the noisy speech, and for the WER ev aluation met- ric ev en caused a degradation in performance. The other base- T able 2: T est set word err or rates using the pretr ained speech reco gnition system, the differ ent enhancement methods and SNRs ranging fr om 0 to 25 dB. F or all SNRs, best performance is obtained using the larg est number of training set noises and noise embeddings. Method 0 dB 5 dB 10 dB 15 dB 20 dB 25 dB Noisy Speech 75.09 57.22 37.54 18.98 8.83 5.19 Log-MMSE 77.25 59.90 37.49 19.93 10.01 6.21 Noise A ware 61.41 40.15 24.84 12.38 6.72 4.93 Ours - No Embeddings 200 54.24 31.95 20.36 10.34 6.13 4.75 Ours - No Embeddings 1000 52.97 29.95 18.77 9.47 5.98 4.80 Ours - No Embeddings All 43.85 22.92 15.00 7.64 5.50 4.64 Ours - W ith Embeddings 41.76 21.34 12.35 6.88 5.18 4.05 line method, noise-aware training, did manage to considerably improv e all e v aluation metrics ov er the noisy speech, with a 25.30% WER. Further , we compared our proposed method to the baseline methods. Using our enhancement network with only 200 train- ing noise environments and no noise embedding managed to further reduce WER to 21.51%, and improv e all other evalu- ation metrics in a similar manner . This finding indicates that the structure of the enhancement network is important, and a deep, residual network is preferable o ver a fully-connected net- work. Ne xt, we observe that further increasing the number of training noise en vironments causes a substantial improvement in all evaluation metrics, with a WER of 16.78% when using all 16,784 training noise environments. Last, using the embedding subnetwork and feeding the noise embedding to the enhance- ment model as described in Section 3 reduces WER to 15.46% and improves all other ev aluation metrics as well. The 15.46% WER that is obtained by our best model corresponds to a rel- ativ e reduction of 54.58% in WER, compared to the original noisy speech. A decomposition of WERs for the dif ferent enhancement methods and SNRs can be found in T able 2. The results in the table sho w that the same conclusions we draw from T a- ble 1 also hold for each SNR independently . Specifically , we observe the adv antages of our methods that use a deep resid- ual network over the baseline methods, and the improv ement in WER due to a largest number of training noises and the usage of noise embeddings. Moreover , when using our best model to enhance noisy speech in the 25 dB condition, we surprisingly found that the WER obtained on the enhanced speech (4.05%) is better ev en compared to the WER obtained on the clean speech recordings (4.21%). This finding may indicate that the enhance- ment model captures the dynamics of speech up to a le vel of de- noising seemingly ne gligible background noises that exist in the clean recordings, and further enhances speech quality in those recordings. 5. Conclusions W e in vestigated speech enhancement in unseen en vironments using two main manipulations. First, we view speech enhance- ment in unseen en vironments as the problem of generalising to unseen points in the space of noise en vironments. Motiv ated by this, we scale the number of training noise environments to 16,784. Second, we supply the enhancement model with ad- ditional information about the environment, in the form of an additional recording from the noise en vironment. This addi- tional recording is processed to create a noise embedding vector that is fed as an additional input to different layers of the main enhancement subnetwork. In experiments, we observed that both of our manipulations managed to considerably improv e the quality of the speech enhancement model, as measured by a v a- riety of evaluation metrics. For example, our best model man- ages to reduce the WER of a pretrained speech recognition sys- tem from 34.04% on noisy speech to 15.46% on the enhanced speech. In future work we plan on further exploring the method of additional context embedding, e.g., embedding speaker record- ings for source separation and embedding noises for selectiv e denoising, as well as improving the current enhancement model using alternative training mechanisms [14, 15]. In addition, we plan on exploring the resulting embedding spaces for semantic and acoustic interpretations. 6. Acknowledgements This work w as supported by Huawei T echnologies Co. Ltd. and the European Union’ s Seventh Frame work Programme through the ERC Starting Grant No. 338164 (ERC StG iHEARu). 7. References [1] A. Kumar and D. A. F . Florencio, “Speech enhancement in multiple-noise conditions using deep neural networks, ” in Proc. of INTERSPEECH , 2016, pp. 3738–3742. [2] M. L. Seltzer , D. Y u, and Y . W ang, “ An in vestigation of deep neural networks for noise robust speech recognition, ” in Proc. of ICASSP , 2013, pp. 7398–7402. [3] F . W eninger , H. Erdogan, S. W atanabe, E. V incent, J. Le Roux, J. R. Hershey , and B. Schuller , “Speech Enhancement with LSTM Recurrent Neural Networks and its Application to Noise-Robust ASR, ” in Pr oceedings of the International Confer ence on La- tent V ariable Analysis and Signal Separation , vol. 9237, Liberec, Czech Republic, 2015, pp. 91–99. [4] G. Keren, M. Schmitt, T . Kehrenber g, and B. Schuller , “W eakly supervised one-shot detection with attention Siamese networks, ” arXiv pr eprint arXiv:1801.03329 , 2018. [5] V . Panayotov , G. Chen, D. Pove y , and S. Khudanpur, “Lib- rispeech: An ASR corpus based on public domain audio books, ” in Pr oc. of ICASSP , 2015, pp. 5206–5210. [6] J. F . Gemmek e, D. P . Ellis, D. Freedman, A. Jansen, W . Lawrence, R. C. Moore, M. Plakal, and M. Ritter , “ Audio Set: An ontology and human-labeled dataset for audio events, ” in Pr oc. of ICASSP , 2017, pp. 776–780. [7] K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition, ” in Pr oc. of CVPR , 2016, pp. 770–778. [8] S. Ioffe and C. Szegedy , “Batch normalization: Accelerating deep network training by reducing internal cov ariate shift, ” in Pr oceed- ings of ICML , Lille, France, 2015, pp. 448–456. [9] A. Hannun, C. Case, J. Casper , B. Catanzaro, G. Diamos, E. Elsen, R. Prenger , S. Satheesh, S. Sengupta, A. Coates et al. , “Deep speech: Scaling up end-to-end speech recognition, ” arXiv pr eprint arXiv:1412.5567 , 2014. [10] A. W . Rix, J. G. Beerends, M. P . Hollier, and A. P . Hekstra, “Perceptual ev aluation of speech quality PESQ-a new method for speech quality assessment of telephone networks and codecs, ” in Pr oc. of ICASSP , 2001, pp. 749–752. [11] J. H. L. Hansen and B. L. Pellom, “ An effecti ve quality ev aluation protocol for speech enhancement algorithms, ” in Proc. of ICSLP , 1998. [12] A. Gray and J. Markel, “Distance measures for speech process- ing, ” IEEE T rans. Acoustics, Speech, and Signal Pr ocessing , vol. 24, no. 5, pp. 380–391, 1976. [13] Y . Ephraim and D. Malah, “Speech enhancement using a mini- mum mean-square error log-spectral amplitude estimator, ” IEEE T rans. Acoustics, Speech, and Signal Pr ocessing , vol. 33, no. 2, pp. 443–445, 1985. [14] G. Keren, S. Sabato, and B. Schuller , “Fast single-class classi- fication and the principle of logit separation, ” in Pr oceedings of ICDM , Singapore, 2018, to appear . [15] G. Keren, S. Sabato, and B. Schuller , “T unable sensitivity to large errors in neural network training, ” in Proceedings of AAAI , San Francisco, CA, 2017, pp. 2087–2093.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment