거의 무지도 음성 인식, 소량 데이터로 음소 구조 학습
본 논문은 1시간 분량의 비라벨 음성 및 200개의 라벨링된 단어만을 이용해, 음성 단어와 텍스트 단어의 음소 구조를 임베딩 공간에 학습하고, 두 공간을 선형 변환으로 정렬함으로써 단어 수준의 자동 음성 인식을 시도한다. 초기 실험에서 27.5%의 단어 정확도를 달성했으며, 언어 모델을 결합하면 성능이 크게 향상된다.
저자: Yi-Chen Chen, Chia-Hao Shen, Sung-Feng Huang
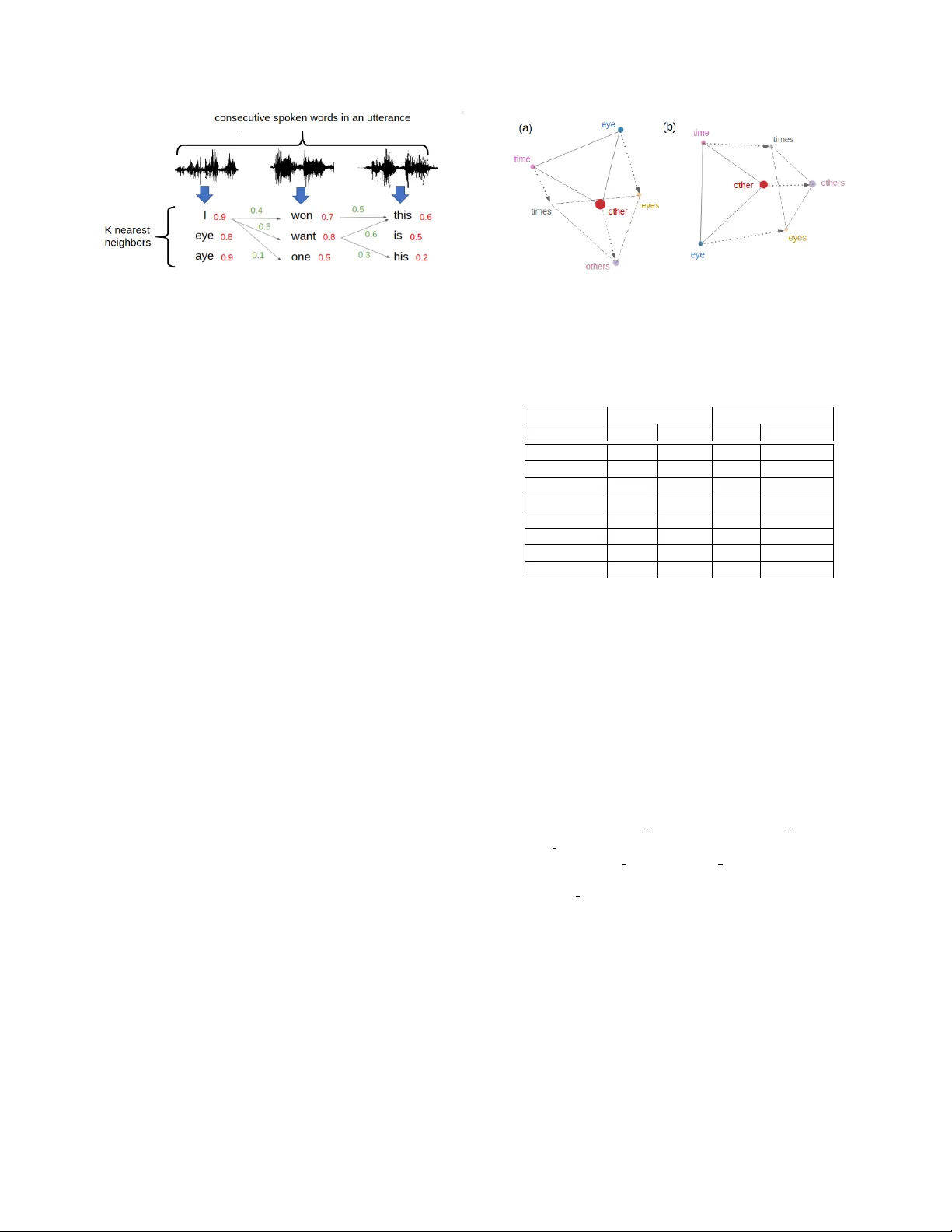
본 논문은 저자원이 극히 제한된 언어에 대해, 인간 영아가 소수의 예시 단어만으로 언어를 습득한다는 현상을 모방하고자 한다. 기존의 반지도 학습이나 대규모 비지도 학습은 수백 시간 이상의 음성 데이터와 풍부한 텍스트 코퍼스를 필요로 하지만, 이 연구는 1시간 분량의 비라벨 음성(총 9022개 단어)과 200개의 라벨링된 단어만으로 단어 수준의 자동 음성 인식(ASR)을 시도한다.
1. **음성 단어의 음소 임베딩**
- 음성 코퍼스를 x_i = (x_i1,…,x_iT) 형태의 MFCC 시퀀스로 표현하고, 이를 두 개의 인코더에 동시에 입력한다.
- 음성 인코더 Eₙcₚ는 음소 정보를, 화자 인코더 Eₙcₛ는 화자 특성을 각각 256차원 벡터(vₚ, vₛ)로 압축한다.
- 디코더 Dₑc(p+s)는 vₚ와 vₛ를 결합해 원본 MFCC를 재구성하도록 학습한다. 재구성 손실(MSE)과 화자 일관성 제약(같은 화자이면 vₛ 거리 최소, 다른 화자이면 거리 ≥ λ) 그리고 화자 디스크리미네이터 Dₛ를 이용한 적대 학습을 통해 vₚ는 순수 음소 정보만을 담게 된다.
2. **텍스트 단어의 음소 임베딩**
- 텍스트 단어를 국제 음성 기호(IPA) 기반의 음소 시퀀스로 변환하고, 각 음소를 15차원 SPE(음성학적 특징) 벡터로 표현한다.
- 이 시퀀스를 자동인코더(Eₙcₜ, Dₑcₜ)에 입력해 텍스트 임베딩 vₜ를 학습한다. 재구성 손실을 최소화함으로써 vₜ는 음소 구조를 보존한다.
3. **두 임베딩 공간 정렬**
- vₚ와 vₜ를 각각 평균 0, 분산 1로 정규화하고 PCA를 적용해 차원을 축소한다(주성분 A, B).
- N개의 “시드” 쌍(aₙ, bₙ) (음성‑텍스트 동일 단어) 을 이용해 선형 변환 행렬 T_ab와 T_ba를 학습한다. 손실 함수는 (i) 변환 후 거리 최소화, (ii) 사이클 일관성( T_ab → T_ba 순환) 보장을 포함한다.
- 학습이 끝난 후, 테스트 음성 단어의 a_i에 T_ab를 적용해 b_i를 얻고, B 집합에서 가장 코사인 유사도가 높은 b_j를 찾아 대응 텍스트 단어를 예측한다.
4. **언어 모델 기반 재점수화**
- 비라벨 “clean‑100” 데이터의 전사문을 이용해 매우 약한 바이그램 LM을 훈련한다.
- 각 테스트 음성에 대해 K개의 최근접 후보(b_k)를 추출하고, 코사인 유사도와 LM 점수를 가중합(1 : 0.05)해 빔 서치를 수행한다.
5. **실험**
- 데이터: LibriSpeech “clean‑100” 중 1시간(9022단어)만을 학습에 사용, 전체 32219개의 텍스트 단어에 대해 텍스트 임베딩을 학습.
- 모델: 모든 인코더/디코더는 Bi‑GRU(256) 혹은 2‑layer GRU(512/256) 구조, 학습률 1e‑4, 배치 64.
- 결과: N=200일 때, 라벨링된 쌍에 대한 정확도는 100%였으며, 비라벨 테스트에 대한 top‑1 정확도는 17.2% (K=1) → 27.5% (K=50, LM 적용)였다. N을 1000 이상으로 늘려도 선형 변환의 표현력 한계로 정확도가 크게 개선되지 않았다.
- Ablation: 화자 특성 분리를 제거하거나 텍스트 음소를 one‑hot으로 표현하면 top‑1 정확도가 각각 2~3%p 감소함을 확인했다.
6. **논의 및 한계**
- 선형 매핑은 제한된 시드(N≈200)에서는 충분히 작동하지만, 더 많은 쌍을 활용하려면 비선형 변환이 필요할 것으로 보인다.
- 현재는 단어 경계가 사전에 주어졌다고 가정했으며, 실제 무라벨 상황에서는 Segmental Audio Word2Vec와 같은 자동 분할 기법과 결합해야 한다.
- 언어 모델은 매우 약했음에도 불구하고 성능을 크게 끌어올렸으며, 더 강력한 LM(예: Transformer 기반)과 더 정교한 점수 결합 방식이 기대된다.
7. **결론**
- 소량의 라벨링된 단어와 비라벨 음성만으로도 음소 구조를 학습하고, 두 임베딩 공간을 정렬함으로써 단어 수준의 ASR을 구현할 수 있음을 입증하였다. 현재 정확도는 낮지만, 화자 특성 분리, SPE 기반 텍스트 임베딩, 언어 모델 결합 등 각 요소가 성능에 기여함을 실증하였다. 향후 비선형 매핑, 자동 단어 분할, 고성능 LM을 도입하면 저자원 언어에 대한 실용적인 음성 인식 시스템으로 발전할 가능성이 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기