Almost-unsupervised Speech Recognition with Close-to-zero Resource Based on Phonetic Structures Learned from Very Small Unpaired Speech and Text Data
Producing a large amount of annotated speech data for training ASR systems remains difficult for more than 95% of languages all over the world which are low-resourced. However, we note human babies start to learn the language by the sounds of a small…
Authors: Yi-Chen Chen, Chia-Hao Shen, Sung-Feng Huang
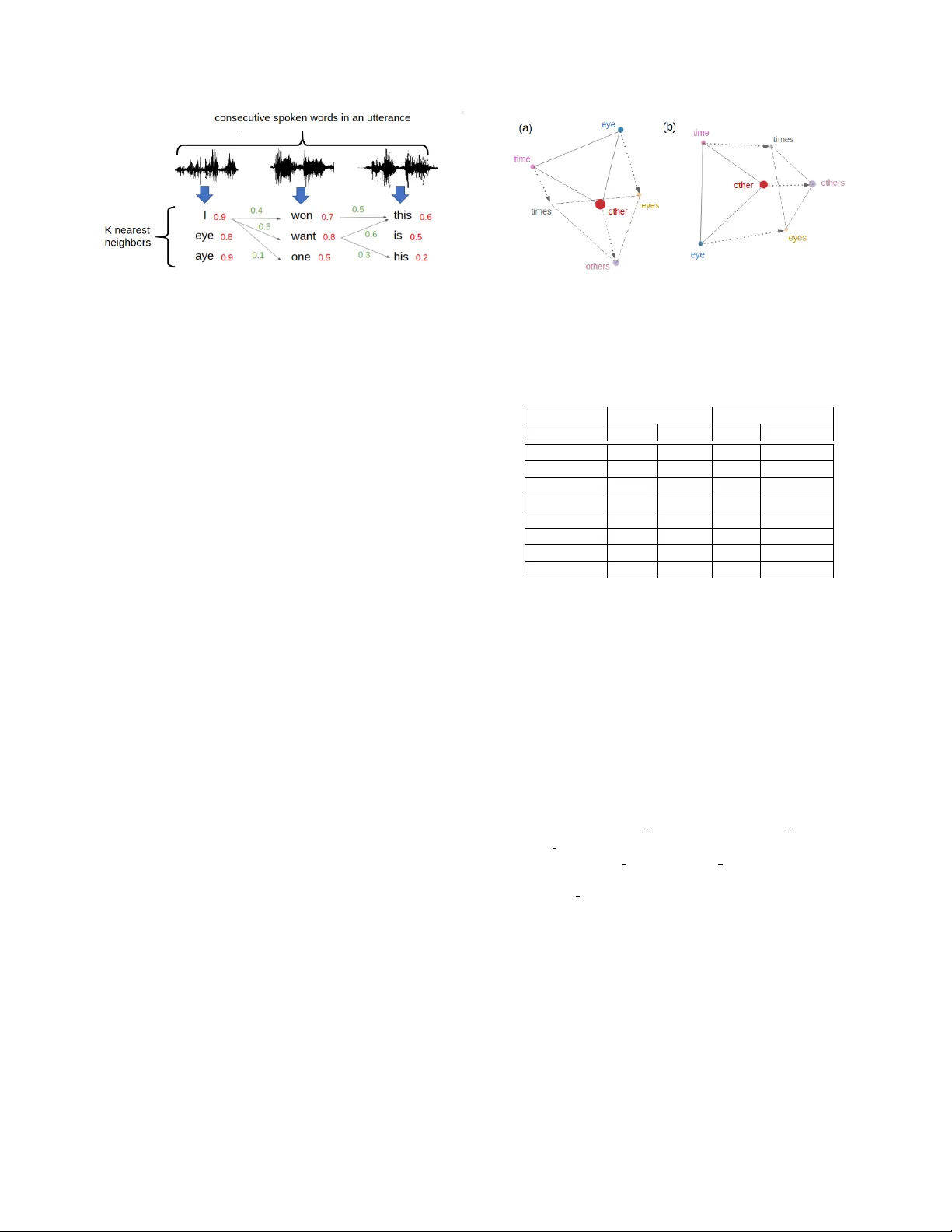
ALMOST -UNSUPER VISED SPEECH RECOGNITION WITH CLOSE-TO-ZER O RESOURCE B ASED ON PHONETIC STR UCTURES LEARNED FR OM VER Y SMALL UNP AIRED SPEECH AND TEXT D A T A Y i-Chen Chen, Chia-Hao Shen, Sung-F eng Huang, Hung-yi Lee , Lin-shan Lee National T aiwan Uni versity , T aiwan ABSTRA CT Producing a large amount of annotated speech data for training ASR systems remains difficult for more than 95% of languages all ov er the world which are lo w-resourced. Ho wev er , we note human babies start to learn the language by the sounds of a small number of e xem- plar words without hearing a large amount of data. W e initiate some preliminary work in this direction in this paper . Audio W ord2V ec is used to obtain embeddings of spoken words which carry phonetic information extracted from the signals. An autoencoder is used to generate embeddings of text words based on the articulatory features for the phoneme sequences. Both sets of embeddings for spoken and text words describe similar phonetic structures among words in their respectiv e latent spaces. A mapping relation from the audio embed- dings to text embeddings actually gives the word-level ASR. This can be learned by aligning a small number of spoken words and the corresponding text words in the embedding spaces. In the initial ex- periments only 200 annotated spoken words and one hour of speech data without annotation gave a word accuracy of 27.5%, which is low b ut a good starting point. Index T erms — automatic speech recognition, lo w resource, semi-supervised 1. INTR ODUCTION Huge success in automatic speech recognition (ASR) has been achiev ed and widely used in many daily applications. Howe ver , with the existing technologies, machines ha ve to learn from a large amount of annotated data to achieve acceptable accurac y , which makes the dev elopment of such technology for a new language with very low resource challenging. Collecting a large amount of speech data is expensi ve, not to mention having the data annotated. This remains true for at least 95% of languages all o ver the world. Al- though substantial efforts have been reported on semi-supervised ASR [1, 2, 3, 4, 5, 6], in most cases a large amount of speech data including a good portion annotated were still needed. So training ASR systems with very small data, most of which are not annotated, is an important but unsolv ed problem. On the other hand, we note human babies start to learn the lan- guage by the sounds of a small number of exemplar words without hearing a large amount of data. It is certainly highly desired if ma- chines can do that too. In this paper we initiate some preliminary work in this direction. Audio W ord2V ec has been proposed recently to transform spo- ken w ords (signal se gments for words without kno wing the underly- ing word it represents) to vectors of fixed dimensionality [7]. These vectors are shown to carry the information about the phonetic struc- tures of the spoken words. Segmental Audio W ord2V ec was further proposed to jointly segment an utterance into a sequence of spo- ken words and transform them into a sequence of vectors [8]. Un- supervised phoneme recognition was then achie ved to some extent by making the duration of spoken words shorter and mapping the clusters of vector representations to phonemes ev en without aligned audio and text [9]. T o further achieve word-based speech recognition in a very low resource setting, algorithms similar to the skip-gram model [10] were used to capture the contextual information in speech data and obtain a set of audio semantic embeddings [11, 12, 13]. A transformation matrix is then learned to align the audio semantic embeddings with the semantic embeddings learned from text, based on which speech recognition can be performed. In this way , two semantic embedding spaces are aligned, and speech recognition is performed. Howe ver , semantic information has to be learned from the context out of extremely large amount of data, such as hundreds of hours of speech data [11, 13], while rarely used words still have relatively poor embeddings for lack of contextual infor- mation. Achieving ASR through the semantic spaces of speech and text seems to be a too far route for the low-resource requirements considered here. In this work, we discover the phonetic structures among text words and spoken words in their respectiv e embedding spaces with only a small amount of text and speech data without annotation, and then align the text and speech embedding spaces using a very small number of annotated spoken words. The word accuracy achiev ed in the initial experiments with only 200 annotated spoken words and one hour of audio without annotation is 27.5%, which is still rela- tiv ely low b ut a good starting point. 2. PR OPOSED APPR O A CHES In Sections 2.1 and 2.2, phonetic embeddings of spoken and text words are respectiv ely learned from audio and text data with rela- tiv ely small size. The two embedding spaces are then aligned with a very small set of annotated spoken words in Section 2.3, so speech recognition can be achieved. In Section 2.4, a very weak language model is used to rescore the recognition results. 2.1. Phonetic Embedding of Spoken W ords W e denote the speech corpus as X = { x i } M i =1 , which consists of M spoken words, each represented as x i = ( x i 1 , x i 2 , ..., x i T ) , where x i t is the acoustic feature vector at time t and T is the length of the spoken word. In the initial work here we focus on the alignment of words in speech and text, so we assume all training spoken words hav e been properly segmented with good boundaries. There exist many approaches which can se gment utterances automatically [14, Fig. 1 . The whole architecture of the proposed approach. 15, 16, 17, 18, 19], including the Segmental Audio W ord2V ec [8] mentioned abov e. A text word corresponds to many different spoken words with varying acoustic factors such as speaker characteristics, micro- phone characteristics, background noise. W e jointly refer to them as speaker characteristics here for simplicity . W e perform phonetic embedding over the spoken words with speaker characteristics dis- entangled using the recently proposed approach [ 12] as shown in the left part of Fig. 1. A sequence of acoustic features x i = ( x i 1 , x i 2 , ..., x i T ) is en- tered to a phonetic encoder E nc p and a speaker encoder E nc s to obtain a phonetic vector v p and a speaker vector v s . Then the pho- netic and speaker vectors v p , v s are used by the decoder Dec ( p + s ) to reconstruct the acoustic features x 0 i . The two encoders E nc p , E nc s and the decoder D ec ( p + s ) are jointly learned to minimize the mean square error between x 0 i and x i . Besides, assuming that the spoken w ord x i is uttered by speaker s i . When the speaker information is not av ailable, we can simply assume that the spoken words in the same utterance are produced by the same speaker . If x i and x j are uttered by the same speaker ( s i = s j ), the speaker encoder E nc s should make their speaker vectors v s i and v s j as close as possible. But if s i 6 = s j , the distance between v s i and v s i should exceed a threshold λ . Finally , a speaker discriminator Dis s takes two phonetic vec- tors v p i and v p j as input and tries to tell if the two vectors come from the same speaker . An additional learning target of the pho- netic encoder E nc p is to ”fool” this speaker discriminator D is s , keeping it from discriminating the speaker identity correctly . In this way , only the phonetic information is learned in the phonetic vector v p , while only the speaker characteristics is encoded in the speaker vector v s . The phonetic vector v p will be used in the following alignment process in Section 2.3. 2.2. Phonetic Embedding of T ext W ords T o model the phonetic structures of text words, we represent each text word with a phoneme sequence, and each phoneme represented as a vector of articulatory features [20]. So the articulatory features of a text word is denoted as y i = ( y i 1 , y i 2 , ..., y i L ) , where y i l is the vector for the l th phoneme and L is the number of phonemes in the word. Then we feed y i into an autoencoder for text words ( E nc t and D ec t ) to obtain a text embedding v t , as in the right part of Fig. 1. The objecti ve of E nc t and Dec t is to reconstruct the original articulatory feature representation. More specifically , we use 15-dim SPE (The Sound Pattern of English [20]) articulatory features, respecti vely corresponding to the features sonorant, syllabic, consonantal, high, back, front, low , round, tense, anterior , coronal, voice, continuant, nasal, and strident. A value 1 is assigned to a dimension if a phoneme is positiv e for the corresponding feature, and a value -1 is assigned if negativ e. A value 0 is assigned if a phoneme does not hav e the corresponding feature. For example, a word “house” is represented with a phoneme sequence (HH, A W , S), and the phoneme “S” can be represented with (-1, -1, 1, -1, 0, 0, 0, 0, 0, 1, 1, -1, 1, -1, 1). 2.3. Alignment of Speech and T ext This approach was inspired from the Mini-Batch Cycle Iterativ e Closest Point (MBC-ICP) [21]. Since both E nc p and E nc t en- code the phonetic structures of the words in their respectiv e latent spaces for v p and v t , we may assume in these latent spaces the relativ e relationships among words should have similar structures (the phonetic structures). For example, the relationships among the words “other”, “bother” and “brother” should be very similar in the two spaces. Similarly for all other words. It is therefore possible to align the two spaces with a little annotation. All the vector representations v p and v t are denoted as V p = { v p i } M i =1 and V t = { v t i } M 0 i =1 respectiv ely , where M is the num- ber of spoken words in the speech corpus, and M 0 the number of distinct words in the text corpus. These vectors are first normal- ized to zero mean and unit variance in all dimensions, and then pro- jected onto their lower dimensional space by PCA. The projected vectors in the principal component spaces are respectiv ely denoted as A = { a i } M i =1 and B = { b i } M 0 i =1 . This is sho wn in the middle part of Fig. 1. Assuming the relati ve relationships among vectors re- main almost unchanged to a good extent after PCA, PCA makes the following alignment easier . T o align the latent spaces for speech and text, we need a small number of “seeds” or paired speech and text words, referred to as the training data here, is denoted as A 0 = { a n } N n =1 and B 0 = { b n } N n =1 , in which a n and b n correspond to the same word. N is a small number , N M . Then a pair of transformation matrices, T ab and T ba are learned, where T ab transforms a v ector a in A to the space of B , that is, ˜ b = T ab a , while T ba maps a v ector b in B to the space of A . T ab and T ba are initialized as identity ma- trices and then learned iteratively with gradient descent minimizing Fig. 2 . Language model rescoring with beam search for top 3 words ( K = 3 ). The numbers in red are cosine similarities for embeddings, while those in green are from the language model. the objectiv e function: L = N X n =1 k b n − T ab a n k 2 2 + N X n =1 k a n − T ba b n k 2 2 + λ 0 N X n =1 k a n − T ba T ab a n k 2 2 + λ 0 N X n =1 k b n − T ab T ba b n k 2 2 . (1) In the first two terms, we want the transformation of a n by T ab to be close to b n and vice versa. The last two terms are for c ycle consistency , i.e., after transforming a n to the space of B by T ab and then transforming back by T ba , it should end up with the original a n , and vice versa. λ 0 is a hyper-parameter . After we obtain the transformation matrix T ab , it can be di- rectly applied on all phonetic vectors v p . For each spoken word with phonetic vector v p i , we can get its PCA mapped vector a i and the transformed vector b i = T ab a i . Then we can find the nearest neighbor vector of b i among all vectors in B , whose corresponding text word is the result of alignment, or ASR result. 2.4. Rescoring with a Language Model W e can use a language model to perform rescoring as illustrated in Figure 2. During testing, for each spoken word a i , we obtain a vec- tor b i = T ab a i . W e find the K nearest neighbor vectors of b i , { b k } K k =1 , among the vectors in B . Each b k corresponds to a text word, with the cosine similarity between b i and b k (numbers in red in Figure 2) as the score. The language model scores are the num- bers in green. Any kind of language modeling can be used here, and the cosine similarities and language model scores are inte grated to find the best path in beam search. 3. EXPERIMENTS 3.1. Dataset LibriSpeech [22] for read speech in English deriv ed from audio- books were used here. It contains 1000 hours of speech uttered by 2484 speakers. W e used one-hour speech from the “clean-100” set as the training data for phonetic embedding of spoken words. This training set contains a total of 9022 spoken words for 1533 dis- tinct w ords. In the initial experiments here we used word boundaries from LibriSpeech, although joint learning of segmentation and spo- ken word embedding is achievable [8]. 39-dim MFCCs were taken Fig. 3 . 3-dim visualization for the first three principal component vectors of several words in the embedding spaces of (a) v p and (b) v t . T able 1 . T op-1 and top-10 accuracies with different N (numbers of paired words). N Paired acc. (%) Unpaired acc. (%) no. of pairs top-1 top-10 top-1 top-10 1533 (all) 71.3 95.2 15.5 34.7 1000 82.4 98.7 14.9 33.1 500 92.7 99.7 14.5 31.3 300 98.6 100.0 15.8 34.0 200 100.0 100.0 17.2 35.5 100 100.0 100.0 14.8 28.9 50 100.0 100.0 8.1 19.4 20 100.0 100.0 2.4 8.4 as the acoustic features. The “clean-100” set of 100 hours of speech includes 32219 distinct words. W e trained phonetic embedding of text words on all these 32219 words. For the “seeds” or paired data, we selected the N most frequent text words out of the 9022 in the one-hour training data, and randomly chose a corresponding spoken word from the one-hour set for each text word to form the paired training set, A 0 and B 0 . In this way , each word had at most one example in the paired data. The alignment or ASR results were e val- uated on the whole one-hour data set, b ut excluding those used in the paired data. 3.2. Model Implementation The phonetic encoder E nc p , speaker encoder E nc s and te xt en- coder E nc t were all single-layer Bi-GRUs with hidden layer size 256. The decoders D ec ( p + s ) and D ec t were double-layer GR Us with hidden layer size 512 and 256 respectiv ely . The speaker dis- criminator Dis s was a fully-connected feedforward network with 2 hidden layers of size 256. The v alue of threshold λ for the constraint of v s in Section 2.1 was set to 0.01. λ 0 in Equation (1) of Section 2.3 was set to 0.5. In all training processes, the initial learning rate was 0.0001 and the mini-batch size was 64. 3.3. V isualization of PCA V ectors W e visualized several typical examples of vectors v p and v t in the subspaces of the first three PCA components. For cleaner visual pre- sentation, we only sho w the a verages of the vectors corresponding to all spoken words for the same text word. In Fig. 3 (a) and (b) respec- tiv ely for v p and v t , we sho w the six vectors corresponding to the six words { time, eye, other , times, eyes, others } . W e see the trian- gle structures for the three words and the dif ference v ectors between T able 2 . The results of beam search with dif ferent beam widths. Beam width T op-1 acc. (%) no language model 17.2 1 21.5 3 24.9 10 26.4 50 27.5 T able 3 . Examples of beam search with beam width K=50. (1) before ... ned it feet mather flo wers out all ... after ... and if she gathered flowers out all ... reference ... and if she gathered flowers at all ... (2) before ... cur mother whiff shrill in zee her ... after ... her mother was three in the her ... reference ... her mother was three in teaching her ... (3) before ... key beganne to pearl her hair ... after ... she began to tell her head ... reference ... she began to curl her hair ... those for “word” and “word-s” are quite consistent in both spaces. Many similar examples can be found, including those for “verb” and “v erb-ing”, etc. These results illustrate the phonetic structures among spoken and text words offer a good knowledge source for ASR, and PCA provides v ery good initialization for such processes. 3.4. Results In the following tables, we use top-1 and top-10 accuracies as the ev aluation metrics for the alignment or word-lev el ASR. The columns under “Paired acc. ” are the accuracies for the training paired spoken and text words, and those under “Unpaired acc. ” are the achiev ed recognition accuracies of testing spoken words. 3.4.1. The Ef fect of N (Number of P air ed W or ds) W ithout Language Model The results for different numbers of paired words N without lan- guage model are listed in T able 1. W e see the paired accuracy was not 100% for N > 200. For example, it was 82.4% for N = 1000. This implies the linear mapping matrix T ab was not adequate for transforming 1000 pairs even if the transformation was already giv en. Better transformation is needed and currently under progress. This explained why training with N = 200 up to 1533 paired words didn’t offer higher unpaired accuracies. In other words, 200 paired words already provide all information the present framework of a linear transformation matrix T ab can learn. The highest top-1 un- paired accuracy of 17.2% for N = 200 seemed low since 200 / 1533 = 13.0% paired words were given. Note here each text word may correspond to many spoken words, but only one of them were giv en as the training pair . W e’ll also see the accuracy can be improved further with a language model. Also, when N ≤ 50, the accuracies drop dramatically ob viously because too fe w clues were av ailable in learning the mapping relations. All the following experiments were for N = 200. 3.4.2. Rescoring with a Language Model W e used the transcriptions of the “clean-100” set (excluding the one-hour data set) to train a very weak bi-gram language model. T able 4 . Ablation studies for disentanglement of speaker character- istics and SPE representation for text words. Disent. T ext Paired acc. Unpaired acc. top-1 top-10 top-1 top-10 yes SPE 100.0 100.0 17.2 35.5 no SPE 100.0 100.0 15.2 31.3 yes one-hot 100.0 100.0 17.0 35.5 no one-hot 100.0 100.0 15.0 32.1 The beam width for beam search ranged from 1 to 50. W e sim- ply summed the cosine similarities and the language model scores with weights 1 and 0.05 during the rescoring. The results are listed in T able 2. W e see the very weak language model of fered very good improv ements (27.5% vs 17.2% for K = 50), verifying the mapping from spok en to text words performed the word-le vel recognition to a certain extent. Some e xamples sho wing ho w the beam search helped (beam width K = 50) in T able 3. W e see the language model may correct some phonetically similar but semantically different words. It is believed with a stronger language model and a well-designed fusion approach, the accuracy can be further impro ved. 3.4.3. Ablation Studies Here we further v erify that the disentanglement of speaker character- istics for v p and the SPE-based representation used in text word em- bedding both improved the performance in T able 4 (N = 200 without language model). Removing the disentanglement and/or represent- ing the phonemes with one-hot vectors instead of SPE-based features led to some performance degradation. 4. CONCLUSION In this w ork, we let the machines learn the phonetic structures among spoken words and text words based on their embeddings, and learn the mapping from spoken words to text words based on the transfor- mation between the two phonetic structures using a small number of annotated words. Initial experiments with only one hour of speech data and 200 annotated spoken words gave an accuracy of 27.5%. There is still a long way to go, and a v ery wide space to be explored. 5. REFERENCES [1] Shigeki Karita, Shinji W atanabe, T omoharu Iwata, Atsunori Ogaw a, and Marc Delcroix, “Semi-supervised end-to-end speech recognition, ” Pr oc. Interspeec h 2018 , pp. 2–6, 2018. [2] Karel V esely , Mirko Hannemann, and Lukas Burget, “Semi- supervised training of deep neural networks, ” in Automatic Speech Recognition and Understanding (ASRU), 2013 IEEE W orkshop on . IEEE, 2013, pp. 267–272. [3] Erinc ¸ Dikici and Murat Sarac ¸ lar , “Semi-supervised and unsu- pervised discriminativ e language model training for automatic speech recognition, ” Speech Communication , vol. 83, pp. 54– 63, 2016. [4] Samuel Thomas, Michael L Seltzer, K enneth Church, and Hynek Hermansky , “Deep neural network features and semi- supervised training for low resource speech recognition, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), 2013 IEEE International Confer ence on . IEEE, 2013, pp. 6704– 6708. [5] Franti ˇ sek Gr ´ ezl and Martin Karafi ´ at, “Combination of multi- lingual and semi-supervised training for under-resourced lan- guages, ” in F ifteenth Annual Conference of the International Speech Communication Association , 2014. [6] Karel V esel ` y, Luk ´ as Bur get, and Jan Cernock ` y, “Semi- supervised dnn training with word selection for asr ., ” in IN- TERSPEECH , 2017, pp. 3687–3691. [7] Y u-An Chung, Chao-Chung W u, Chia-Hao Shen, Hung-Yi Lee, and Lin-Shan Lee, “ Audio word2v ec: Unsupervised learning of audio segment representations using sequence-to- sequence autoencoder, ” arXiv preprint , 2016. [8] Y u-Hsuan W ang, Hung-Y i Lee, and Lin-Shan Lee, “Segmental audio W ord2V ec: Representing utterances as sequences of v ec- tors with applications in spoken term detection, ” in ICASSP , 2017. [9] Da-Rong Liu, Kuan-Y u Chen, Hung-Y i Lee, and Lin-shan Lee, “Completely unsupervised phoneme recognition by adversari- ally learning mapping relationships from audio embeddings, ” arXiv pr eprint arXiv:1804.00316 , 2018. [10] T omas Mikolov , Ilya Sutskever , Kai Chen, Greg S Corrado, and Jeff Dean, “Distributed representations of words and phrases and their compositionality , ” in Advances in neural in- formation pr ocessing systems , 2013, pp. 3111–3119. [11] Y i-Chen Chen, Chia-Hao Shen, Sung-Feng Huang, and Hung- yi Lee, “T owards unsupervised automatic speech recognition trained by unaligned speech and text only , ” arXiv preprint arXiv:1803.10952 , 2018. [12] Y i-Chen Chen, Sung-Feng Huang, Chia-Hao Shen, Hung-yi Lee, and Lin-shan Lee, “Phonetic-and-semantic embedding of spoken words with applications in spoken content retrieval, ” arXiv pr eprint arXiv:1807.08089 , 2018. [13] Y u-An Chung, W ei-Hung W eng, Schrasing T ong, and James Glass, “Unsupervised cross-modal alignment of speech and text embedding spaces, ” arXiv preprint , 2018. [14] Keith Le vin, Aren Jansen, and Benjamin V an Durme, “Seg- mental acoustic indexing for zero resource keyword search, ” in ICASSP , 2015. [15] Samy Bengio and Georg Heigold, “W ord embeddings for speech recognition, ” in INTERSPEECH , 2014. [16] Guoguo Chen, Carolina Parada, and T ara N. Sainath, “Query- by-example keyw ord spotting using long short-term memory networks, ” in ICASSP , 2015. [17] Shane Settle, Keith Le vin, Herman Kamper, and Karen Liv escu, “Query-by-example search with discriminative neural acoustic word embeddings, ” INTERSPEECH , 2017. [18] Aren Jansen, Manoj Plakal, Ratheet Pandya, Dan Ellis, Shawn Hershey , Jiayang Liu, Channing Moore, and Rif A. Saurous, “T o wards learning semantic audio representations from unla- beled data, ” in NIPS W orkshop on Machine Learning for A udio Signal Pr ocessing (ML4Audio) , 2017. [19] Odette Scharenbor g, V incent W an, and Mirjam Ernestus, “Un- supervised speech segmentation: An analysis of the hypothe- sized phone boundaries, ” The Journal of the Acoustical Society of America , vol. 127, no. 2, pp. 1084–1095, 2010. [20] T om Brøndsted, “ A spe based distinctiv e feature composition of the cmu label set in the timit database, ” T echnical Report IR 98-1001, Center for P ersonK ommunikation, Institute of Elec- tr onic Systems, Aalborg University , 1998. [21] Y edid Hoshen and Lior W olf, “ An iterative closest point method for unsupervised word translation, ” arXiv preprint arXiv:1801.06126 , 2018. [22] V assil Panayoto v , Guoguo Chen, Daniel Pove y , and Sanjeev Khudanpur , “Librispeech: an asr corpus based on public do- main audio books, ” in Acoustics, Speech and Signal Process- ing (ICASSP), 2015 IEEE International Conference on . IEEE, 2015, pp. 5206–5210.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment