인식 기반 변분 오토인코더로 만든 생성적 음색 공간
본 논문은 인간의 음색 유사도 평가를 정규화 항으로 활용해 변분 오토인코더(VAE)의 잠재 공간을 음색 인지 구조와 일치시키는 방법을 제안한다. NSGT 기반 스펙트럼 입력을 사용해 고품질 오디오를 재구성하고, 정규화된 잠재 공간을 통해 새로운 악기의 음색을 분석·합성하며, 음향 기술자들을 위한 연속적인 음색 변형과 디스크립터 기반 제어까지 가능하게 한다.
저자: Philippe Esling, Axel Chemla--Romeu-Santos, Adrien Bitton
**1. 연구 배경 및 문제 정의**
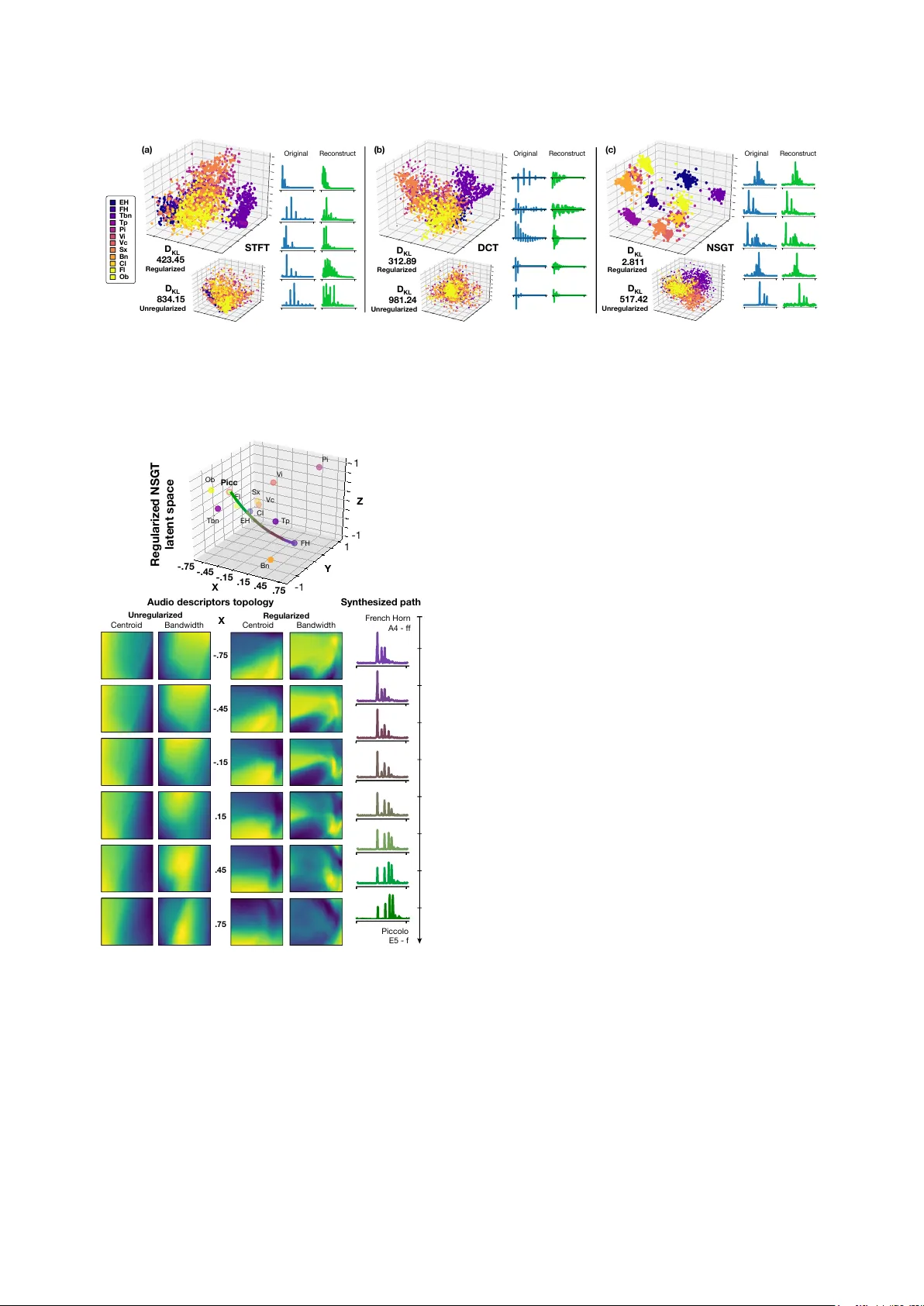
음색은 동일한 음높이와 강도에서 서로 다른 악기를 구별하게 하는 청각적 속성이다. 기존 연구에서는 청취자에게 악기 쌍의 유사도를 평가하게 하고, 이를 다차원 척도법(MDS)으로 시각화해 ‘음색 공간’을 만든다. 이러한 공간은 인간 인지 구조를 반영하지만, (i) 새로운 샘플이 추가될 때마다 전체 공간을 재계산해야 하고, (ii) 역변환이 불가능해 합성에 활용할 수 없으며, (iii) 차원 해석이 선형 상관관계에만 의존한다는 한계가 있다.
동시에, 딥러닝 기반 생성 모델, 특히 변분 오토인코더(VAE)는 데이터의 저차원 잠재 표현을 학습하고, 그 잠재 변수를 통해 새로운 샘플을 생성한다. VAE는 (a) 인코더 qφ(z|x)와 디코더 pθ(x|z)로 구성되며, ELBO 손실(재구성 손실 + KL 다이버전스)으로 최적화된다. 그러나 잠재 차원은 비지도 학습에 의해 형성돼 청각적 의미와 직접 연결되지 않는다.
**2. 제안 방법**
본 논문은 VAE의 손실에 **퍼셉추얼 정규화 항** R(z,T)를 추가한다. 여기서 T는 다섯 개 독립적인 음색 연구에서 얻은 MDS 기반 목표 공간이며, 각 악기 클래스 C_i에 대응한다. 정규화 항은 잠재 공간 내 거리 D_z(i,j)=‖z_i‑z_j‖와 목표 공간 거리 D_T(i,j)=‖T_i‑T_j‖ 사이의 차이를 최소화한다. 구체적으로 t‑SNE에서 영감을 받은 확률적 유사도 p_ij와 q_ij를 정의하고, KL 다이버전스로 두 분포를 맞춘다. 전체 손실은
L = E_q
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기