Generative timbre spaces: regularizing variational auto-encoders with perceptual metrics
Timbre spaces have been used in music perception to study the perceptual relationships between instruments based on dissimilarity ratings. However, these spaces do not generalize to novel examples and do not provide an invertible mapping, preventing …
Authors: Philippe Esling, Axel Chemla--Romeu-Santos, Adrien Bitton
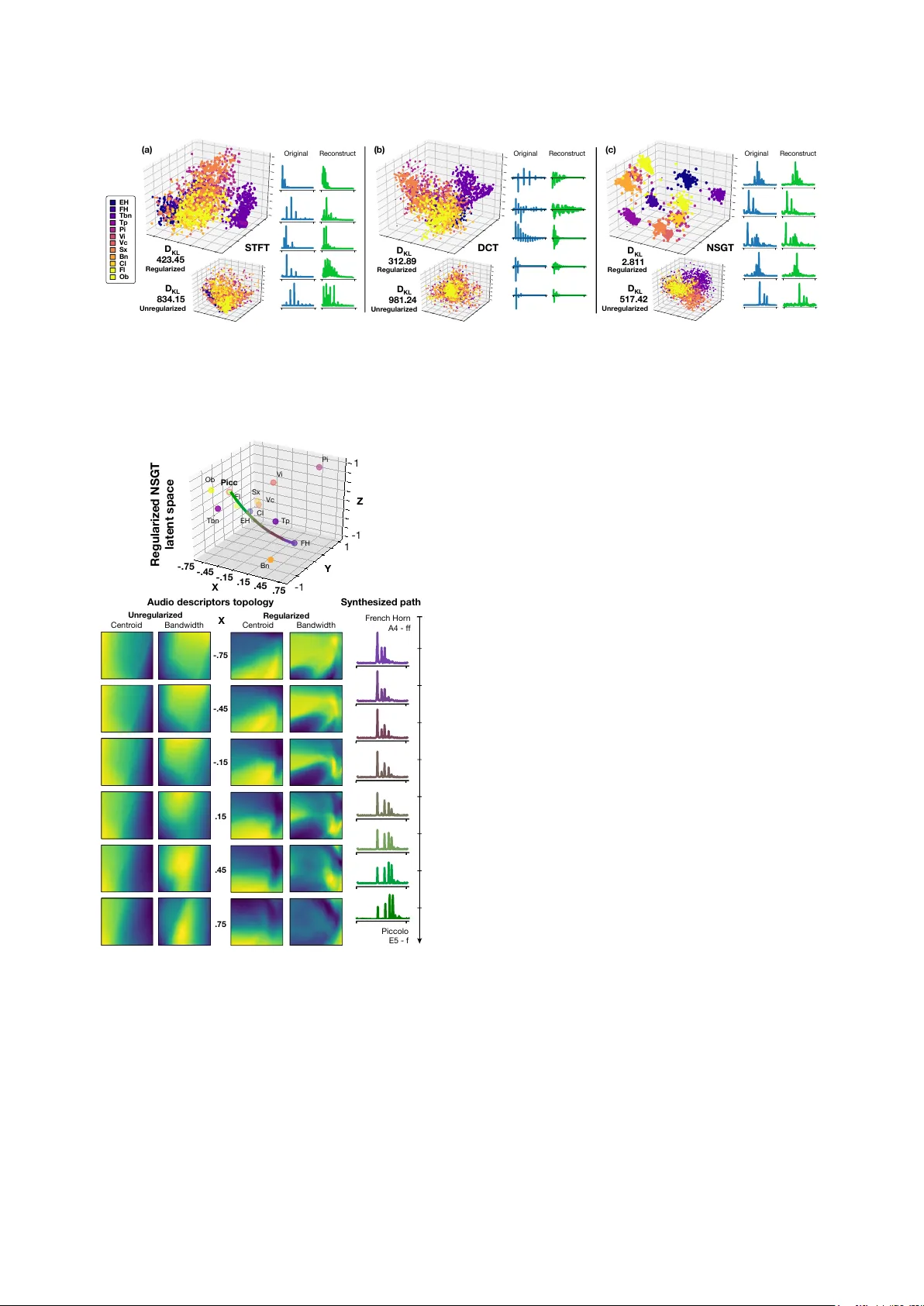
GENERA TIVE TIMBRE SP A CES: REGULARIZING V ARIA TIONAL A UTO-ENCODERS WITH PERCEPTU AL METRICS Philippe Esling 1 ∗ Axel Chemla–Romeu-Santos 2,1 , Adrien Bitton 1 1 IRCAM, UMR 9912 CNRS - Sorbonne Univ ersite, Paris, France 2 Laboratorio d’Informatica Musicale - Univ ersita degli Studi di Milano, Italy esling@ircam.fr ABSTRA CT T imbre spaces hav e been used in music perception to study the per- ceptual relationships between instruments based on dissimilarity ratings. Howe ver , these spaces do not generalize to novel exam- ples and do not provide an inv ertible mapping, prev enting audio synthesis. In parallel, generative models have aimed to provide methods for synthesizing novel timbres. Ho we ver , these systems do not provide an understanding of their inner workings and are usually not related to any perceptually rele vant information. Here, we sho w that V ariational Auto-Encoders (V AE) can alle viate all of these limitations by constructing generative timbre spaces . T o do so, we adapt V AEs to learn an audio latent space, while using perceptual ratings from timbre studies to regularize the organiza- tion of this space. The resulting space allows us to analyze nov el instruments, while being able to synthesize audio from any point of this space. W e introduce a specific regularization allowing to enforce an y giv en similarity distances onto these spaces. W e sho w that the resulting space provide almost similar distance relation- ships as timbre spaces. W e ev aluate several spectral transforms and show that the Non-Stationary Gabor Transform (NSGT) provides the highest correlation to timbre spaces and the best quality of syn- thesis. Furthermore, we show that these spaces can generalize to nov el instruments and can generate any path between instruments to understand their timbre relationships. As these spaces are con- tinuous, we study how audio descriptors behav e along the latent dimensions. W e show that e ven though descriptors have an ov erall non-linear topology , they follow a locally smooth ev olution. Based on this, we introduce a method for descriptor-based synthesis and show that we can control the descriptors of an instrument while keeping its timbre structure. 1. INTRODUCTION For the past decades, music perception research has tried to un- derstand the perception of instrumental timbre . Timbre is the set of properties that distinguishes two instruments that play the same note at the same intensity . T o do so, sev eral studies [1] collected human dissimilarity ratings between pairs of audio samples inside a set of instruments. These ratings are organized by applying Mul- tiDimensional Scaling (MDS), leading to timbr e spaces , which ex- hibit the perceptual similarities between different instruments. By analyzing the dimensions of resulting spaces, the studies tried to correlate audio descriptors to the perception of timbre [2]. Al- though these spaces provided interesting a venues of analysis, the y are inherently limited by the fact that ordination techniques (e.g. ∗ This work was supported by project MAKIMOno 17-CE38-0015-01 funded by the French ANR and Canadian NSERC (STPG 507004-17) and the A CTOR Partnership funded by the Canadian SSHRC (895-2018-1023). MDS) produce a fixed space, which has to be recomputed entirely for any new sample. Therefore, these spaces do not generalize to nov el examples and do not provide an in vertible mapping, preclud- ing audio synthesis to understand their perceptual topology . In parallel, recent developments in audio synthesis using gen- erative models has seen great improvements with the introduction of approaches such as the W aveNet [3] and SampleRNN [4] archi- tectures. These allow to generate novel high-quality audio match- ing the properties of the corpus they have been trained on. How- ev er , these models giv e little cue and control over the output or the features it results from. More recently , NSynth [5] has been pro- posed to synthesize audio by allowing to morph between specific instruments. Howe ver , these models still require very large num- ber of parameters, long training times and a large number of ex- amples. Amongst recent generative models, another key proposal is the V ariational Auto-Encoder ( V AE ) [6]. In these, a latent space is learned that allows both to encode data for analysis, but also to sample from it in order to generate novel content. V AEs address the limitations of control and analysis through this latent space, while remaining simple and fast to learn with a small set of ex- amples. Furthermore, V AEs seem able to disentangle underlying variation f actors by learning independent latent variables account- ing for distinct generative processes [7]. Howe ver , these latent dimensions are learned in an unsupervised way . Therefore, they are not related to perceptual properties, which might hamper their understandability or their use for audio analysis and synthesis. Here, we show that we can bridge timbre perception analy- sis and perceptually-relev ant audio synthesis by regularizing the learning of V AE latent spaces so that they match the perceptual dis- tances collected from timbre studies. Our overall approach is de- picted in Figure 1. First, we adapt the V AE to analyze musical au- dio content, by comparing the use of dif ferent spectral transforms as input to the learning. W e sho w that, amongst the Short-T erm Fourier Transform (STFT), Discrete Cosine Transform (DCT) and the Non-Stationary Gabor Transform (NSGT) [8], the NSGT pro- vides the best reconstruction abilities and regularization perfor- mances. By training this model on a small database of spectral frames, it already provides a generati ve model with an interesting latent space, able to synthesize novel instrumental timbres. Then, we introduce a regularization to the learning objective inspired by the t-Stochastic Neighbors Embedding (t-SNE) [9], aiming to en- force that the latent space exhibits the same distances between in- struments as those found in timbre studies. T o do so, we build a model of perceptual relationships by analyzing dissimilarity rat- ings from fiv e independent timbre studies [10, 11, 12, 13, 14]. W e sho w that perceptually-regularized latent spaces are simultane- ously coherent with perceptual ratings, while being able to synthe- size high-quality audio distrib utions. Hence, we driv e the learning of latent spaces to match the topology of giv en target spaces. 1 V AE Perceptual ratings x p ✓ ( x | z ) q ( z | x ) z µ ( x ) ⌃ ( x ) R , ✓ z , T MDS T Analysis Synthesis Perception Timbre spaces ˜ x ⇠ p ( x ) 5 5 2 6 6 2 5 8 4 4 6 2 7 7 1 5 3 2 6 6 2 5 3 1 Figure 1: ( Left ) V AEs can model a spectral frame x of an au- dio sample by learning an encoder q φ ( z | x ) which maps them to a Gaussian N ( µ ( x ) , σ ( x )) inside a latent space z . The de- coder p θ ( x | z ) samples from this Gaussian to generate a recon- struction ˜ x of the spectral frame. ( Right ) Perception studies use similarity ratings to construct timbr e spaces exhibiting perceptual distances between instruments. Here, we de velop a regularization R ( z , T ) enforcing that the variational model finds a topology of latent space z that matches the topology of the timbre space T . W e demonstrate that these spaces can be used for generating nov el audio content, by analyzing their reconstruction quality on a test dataset. Furthermore, we show that paths in the latent space (where each point corresponds to a single spectral frame) provide sound synthesis with continuous evolutions of timbre. W e also show that these spaces generalize to novel samples, by encoding a set of instruments that were not part of the training set. Therefore, the spaces could be used to predict the perceptual similarities of nov el instruments. Finally , we study how traditional audio descrip- tors are organized along the latent dimensions. W e sho w that e ven though descriptors behave in a non-linear way across space, they still follow a locally smooth ev olution. Based on this smoothness property , we introduce a method for descriptor-based path synthe- sis . W e show that we can modify an instrumental distribution so that it matches a giv en target ev olution of audio descriptors, while remaining perceptually smooth. The source code, audio examples and animations are av ailable on a supporting repository 1 . 2. ST A TE-OF-AR T 2.1. V ariational auto-encoders Generative models are a flourishing class of learning approaches, which aim to find the underlying probability distribution of the data p ( x ) [15]. Formally , based on a set of examples in a high- dimensional space x ∈ R d x , we assume that these follow an un- 1 https://github.com/acids- ircam/ variational- timbre known distribution p ( x ) . Furthermore, we consider a set of latent variables defined in a lower -dimensional space z ∈ R d z ( d z d x ). These latent variables help gov ern the generation of the data and enhance the expr essivity of the model. Thus, the complete model is defined by the joint probability distribution p ( x , z ) = p ( x | z ) p ( z ) . W e could find p ( x ) through its relation to the pos- terior distribution p ( z | x ) gi ven by Bayes’ theorem. Howe ver , for complex non-linear models (such as those that we will consider in this paper), this posterior can not be found in closed form. For decades, the dominant paradigm for approximating p ( x ) has been sampling methods [16]. Ho wev er , the quality of this ap- proximation depends on the number of sampling operations, which might be extremely large before we have an accurate estimate. Re- cently , variational inference (VI) [15] has been proposed to solve this problem through optimization rather than sampling. VI as- sumes that if the distribution is too complex to find, we could find a simpler approximate distribution that still models the data, while trying to minimize its difference to the real distribution. For - mally , VI specifies a family Q of approximate densities, where each member q ( z | x ) ∈ Q is a candidate approximation to the exact p ( z | x ) . Hence, the inference problem can be transformed into an optimization problem by minimizing the Kullback-Leibler (KL) div ergence between the approximation and original density q ∗ ( z | x ) = arg min q ( z | x ) ∈Q D K L q ( z | x ) k p ( z | x ) (1) The complexity of the family Q will both determine the quality of the approximation, but also the comple xity of this optimization. Hence, the major issue of VI is to choose Q to be flexible enough to closely approximate p ( z | x ) , while being simple enough to al- low efficient optimization. Now , if we expand the KL div ergence that we need to minimize and rely on Bayes’ rule to replace p ( z | x ) , we obtain the following e xpression D K L q ( z | x ) k p ( z | x ) = E q ( z ) log q ( z | x ) − log p ( x | z ) − log p ( z ) + log p ( x ) (2) Noting that the expectation is over q ( z | x ) and that p ( x ) does not depend on it, we can get this term out of the expectation and then observe that the remaining equation can be rewritten as another KL div ergence leading to log p ( x ) − D K L q ( z | x ) k p ( z | x ) = E z log p ( x | z ) − D K L q ( z | x ) k p ( z ) (3) This formulation describes the logarithm of the quantity that we want to maximize log p ( x ) minus the error we make by using an approximate q instead of p . Therefore, we can optimize this alter- nativ e objectiv e, called the evidence lower bound (ELBO) as log p ( x ) = D K L q ( z | x ) k p ( z | x ) + E LB O ( q ) . (4) and the KL is non-negativ e, so log p ( x ) ≥ E LB O ( q ) , ∀ q ( z ) . Now , to optimize this objective, we will rely on parametric dis- tributions q φ ( z | x ) and p θ ( x | z ) . Therefore, optimizing our gen- erativ e model will amount to optimize these parameters θ , φ L ( θ , φ ) = E q φ ( z ) log p θ ( x | z ) − D K L q φ ( z | x ) k p θ ( z ) (5) W e can see that this equation inv olves q φ ( z | x ) which encodes the data x into the latent representation z and a decoder p ( x | z ) , 2 which generates a data x giv en a latent configuration z . Hence, this whole structure defines the V ariational Auto-Encoder (V AE), which is depicted in Figure 1 (Left). The V AE objectiv e can be interpreted intuitively . The first term increases the likelihood of the data generated given a configu- ration of the latent, which amounts to minimize the r econstruction err or . The second term represents the error made by using a sim- pler distribution q φ ( z | x ) rather than the true distribution p θ ( z ) . Therefore, this r e gularizes the choice of approximation q so that L θ,φ = E q φ ( z ) log p θ ( x | z ) | {z } reconstruction − β · D K L q φ ( z | x ) k p θ ( z ) | {z } regularization (6) The first term can be optimized through a usual maximum likeli- hood estimation, while the second term requires that we define the prior p ( z ) . While the easiest choice is to choose p ( z ) ∼ N ( 0 , I ) , it also adds the benefit that this term has a simple closed solution for computing the optimization, as detailed in [6]. Here we intro- duced a weight β to the KL di vergence, which leads to the β -V AE formulation [7]. This has been shown to improve the capacity of the model to disentangle factors of variations in the data. How- ev er , it has later been sho wn that an appropriate w ay to handle this parameter was to perform warm-up [17], where the β parameter is linearly increased in the first epochs of training. Finally , we need to select a family of variational densities Q . One of the most widespread choice is the mean-field varia- tional family where latent v ariables are independent and are each parametrized by a distinct variational parameter q ( z ) = m Y j =1 q j ( z j ) (7) Therefore, each dimension of the latent space will be governed by an independent Gaussian distribution with its o wn mean and variance depending on the input data q j ( z j ) = N ( µ j ( x ) , Σ j ( x )) . V AEs are powerful representation learning frameworks, while remaining simple and fast to learn without requiring large sets of examples [17]. Their potential for audio applications have been only scarcely in vestigated yet and mostly in topics related to speech processing such as blind source separation [18] and speech trans- formation [19]. Howe ver , to the best of our knowledge, the use of V AE and their latent spaces to perform musical audio analysis and generation has yet to be in vestigated. 2.2. Timbre spaces and auditory perception For se veral decades, music perception research has tried to under- stand the mechanisms leading to the perception of timbr e . Se v- eral studies have shown that timbre could be partially described by computing various audio descriptors [13]. T o do so, most stud- ies relied on the concept of timbre spaces [2], a model that orga- nize audio samples based on perceptual dissimilarity ratings. In these studies, pairs of sounds are presented to subjects that are asked to rate their perceptual dissimilarities inside a given set of instruments. Then, these ratings are compiled into a set of dissim- ilarity matrices that are analyzed with Multi-Dimensional Scaling (MDS). The MDS algorithm provides a timbre space that exhibits the underlying perceptual distances between dif ferent instruments (Figure 1 (Right)). Here, we briefly detail corresponding studies and redirect interested readers to the full articles for more details. In his seminal paper, Grey [10] performed a study with 16 instru- mental sound samples. Each of the 22 subjects had to rate the dis- similarity between all pairs of sounds on a continuous scale from 0 (most similar) to 1 (most dissimilar). This lead to the first con- struction of a timbre space for instrumental sounds. They further exhibit that the dimensions explaining these dissimilarities could be correlated to the spectral centroid, spectral flux and attack cen- troid. Sev eral studies follo wed this research by using the same experimental paradigm. Krumhansl [11] used 21 instruments with 9 subjects on a discrete scale from 1 to 9, Iverson et al. [12] with 16 samples and 10 subjects on a continuous scale from 0 to 1, McAdams et al. [13] with 18 orchestral instruments and 24 sub- jects on a discrete scale from 1 to 16 and, finally , Lakatos [14] with 17 subjects on 22 harmonic and percussi ve samples on a con- tinuous scale from 0 to 1. Each of these studies shed light on different aspects of audio perception, depending on the aspect be- ing scrutinized and the interpretation of the space by the exper - imenters. Ho we ver , all studies hav e led to different spaces with different dimensions. The fact that dif ferent studies correlate to different audio descriptors prev ents a generalization of the acous- tic cues that might correspond to timbre dimensions. Furthermore, timbre spaces hav e been explored based on MDS to organize per- ceptual ratings and correlate spectral descriptors [13]. Therefore, these studies are inherently limited by the fact that • ordination techniques (such as MDS) produce fixed spaces that must be recomputed for any ne w data point • these spaces do not generalize nor synthesize audio between instruments as they do not pro vide an in vertible mapping • interpretation is bounded to the a posteriori linear correla- tion of audio descriptors to the dimensions rather than ana- lyzing the topology of the space itself As noted by McAdams et al. [1], critical problems in these approaches are the lack of an objectiv e distance model based on perception and general dimensions for the interpretation of tim- bral transformation and source identification. Here, we show that relying on V AE models to learn unsupervised spaces, while regu- larizing the topology of these spaces to fit giv en perceptual ratings can allow to alle viate all of these limitations. 3. REGULARIZING LA TENT SP A CE TOPOLOGY In this paper , we aim to construct a latent space that could both analyze and synthesize audio content, while providing the under- lying perceptual relationships between audio samples. T o do so, we show that we can influence the organization of the V AE latent space z so that it follows the topology of a giv en target space T . Here, we will rely on the MDS space constructed from perceptual ratings as a target space T . Howe ver , it should be noted that this idea can be applied to any gi ven target space that pro vides a set of distances between the elements used for learning the V AE space. T o further specify our problem, we consider a set of audio samples, where each x i can be encoded in the latent space as z i and hav e an equi valent in the target space T i . In order to relate the elements of the audio dataset to the perceptual space, we consider that each sample is labeled with its instrumental class C i , that has an equiv alent in the timbre space. Therefore, we will match the properties of the classes between the latent and tar get spaces (note that we could use element-wise properties for finer control). Here, we propose to regularize the learning by introducing the perceptual similarities through an additive term R ( z , T ) . This 3 penalty imposes that the properties of the latent space z are similar to that of the target space T . The optimization objective becomes E log p θ ( x | z ) − β D K L q φ ( z | x ) k p θ ( z ) + α R z , T (8) where α is an hyper-parameter that allows us to control the influ- ence of the regularization. Hence, amongst two otherwise equal solutions, the model is pushed to select the one that comply with the penalty . In our case, we want the distances between instru- ments to follow perceptual timbre distances. Therefore, we need to minimize the differences between the set of distances in the latent space D z i,j = D ( z i , z j ) and the distances in target space D T i,j = D ( T i , T j ) . Therefore, the regularization criterion will try to minimize the overall differences between these sets of distances. T o compute these sets, we take inspiration from the t-Stochastic Neighbor Embedding (t-SNE) algorithm [9]. Indeed, as their goal is to map the distances from one (high-dimensional) space into a target (low-dimensional) space, it is highly correlated to our task. Howe ver , we can not simply apply the t-SNE algorithm on the la- tent space as this would lead to a non-in vertible mapping. Instead, we aim to steer the learning in a similar way . Hence, we com- pute the relationships in the latent space z by using the conditional Gaussian density that i would choose j as its neighbor D z i,j = exp − k z i − z j k 2 / 2 σ 2 i P k 6 = i exp − k z i − z k k 2 / 2 σ 2 i (9) where σ i is the variance of the Gaussian centered on z i , defined as σ i = 1 / √ 2 . Then, to relate the points in the timbre space T , we use a Student-t distribution to define the distances in this space as D T i,j = 1 + kT i − T j k 2 − 1 P k 6 = l 1 + kT k − T l k 2 − 1 (10) Finally , we rely on the sum of KL diver gences between the two distributions of distances in dif ferent spaces to define our complete regularization criterion R z , T = X i D K L D z i k D T i = X i X j D z i,j log D z i,j D T i,j Hence, instead of applying a distance minimization a posteri- ori, we steer the learning to find a configuration of the latent space z that displays the same distance properties as the space T , while providing an in v ertible mapping. 4. EXPERIMENTS 4.1. Datasets T imbr e studies. W e rely on the perceptual ratings collected across fiv e independent timbre studies [10, 11, 12, 13, 14]. As discussed earlier , even though all studies follow the same experimental pro- tocol, there are some discrepancies in the choice of instruments, rating scales and sound stimuli. Ho wev er , here we aim to obtain a consistent set of properties to define a common timbre space. Therefore, we computed the maximal set of instruments for which we had ratings for all pairs. T o do so, we collated the list of instru- ments from all studies and counted their co-occurences, leading to a set of 12 instruments (Piano, Cello, V iolin, Flute, Clarinet, T rombone, French Horn, English Horn, Oboe, Saxophone, Trum- pet, T uba) with pairwise ratings. Then, we normalized the raw Pn Vi Vc Tbn Tp Sx Eh Fl Fh Cl Ob Bn Axis 1 Axis 2 Axis 3 E nglish H or n F r ench H or n T ro m b o n e T rum p et P ia n o Vi olin V iolin c ello S a x ophone B assoo n Cl arinet Ob oe Fl ute Figure 2: Multi-dimensional scaling (MDS) of the combined and normalized set of perceptual ratings from different studies. dissimilarity data (keeping all instruments of that study) so that it maps to a common scale from 0 to 1. Finally , we extracted the set of ratings that corresponds to our selected instruments. This leads to a total of 1217 subject ratings for all instruments, amounting to 11845 pairwise ratings. Based on this set of ratings, we com- pute an MDS space to ensure the consistency of our normalized perceptual space on the selected set. The results of this analysis are displayed in Figure 2. W e can see that even though the ratings come from dif ferent studies, the resulting space remains very co- herent, with the distances between instruments remaining coherent with the original perceptual studies. Audio datasets. In order to learn the distribution of instrumen- tal sounds directly from the audio signal, we rely on the Studio On Line (SOL) database [20]. W e selected 2,200 samples to repre- sent the 11 instruments for which we extracted perceptual ratings. W e normalized the range of notes used by taking the whole tes- situra and dynamics a vailable (to remove effects from the pitch and loudness). All recordings were resampled to 22050 Hz for the experiments. Then, as we intend to ev aluate the effect of different spectral distributions as input to our proposed model, we computed sev eral in vertible transforms for each audio sample. First, we com- pute the Short-T erm Fourier T ransform (STFT) with a Hamming window of 40ms and a hop size of 10ms. Then, we compute the Discrete Cosine T ransform (DCT) with the same set of parameters. Finally , we compute the Non-Stationary Gabor Transform (NSGT) [8] mapped either on a Constant-Q scale of 48 bins per octav e and a Mel scale or ERB scale of 400 bins, all from 30 to 11000 Hz. For all transforms, we only keep the magnitude of the distribution to train our models. W e perform a corpus-wide normalization to preserve the relati ve intensities of the samples (normalizing all dis- tributions by the maximal value found across samples). Then, we extract a single temporal frame from the sustained part of the rep- resentation (200 ms after the beginning of the sample) to represent a given audio sample. Finally , the dataset is randomly split across notes to obtain a training (90%) and test (10%) set. Audio reconstruction. T o perform audio synthesis, we con- sider paths inside the latent space, where each point corresponds to a single spectral frame. W e sample along a given path and con- catenate the spectral frames to obtain the magnitude distribution. Then, we apply the Griffin-Lim algorithm in order to recov er the phase distribution and synthesize the corresponding w aveform. 4 4.2. Models Here, we rely on a simple V AE architecture to show the ef ficiency of the proposed method. The encoder is defined as a 3-layer feed- forward neural network with Rectified Linear Units (ReLU) acti- vation functions and 2000 units per layer . The last layer maps to a giv en dimensionality d of the latent space. In our experiments, we analyzed the effect of relying on different latent spaces and em- pirically selected latent spaces with 64 dimensions. The decoder is defined in a symmetrical way , with the same architecture and units, mapping back to the dimensionality of the input transform. For learning the model, we use a v alue of β = 2 , which is linearly increased from 0 to its final value during the first 100 epochs (fol- lowing the warmup procedure [17]). In order to train the model, we rely on the AD AM [21] optimizer with an initial learning rate of 0.0001. In a first stage, we train the model without perceptual regularization ( α = 0 ) for a total of 5000 epochs. Then, we intro- duce the perceptual regularization ( α = 0 . 1 ) and train for another 1000 epochs. This allows the model to first focus on the quality of the reconstruction, and then to con ver ge to wards a solution with perceptual space properties. W e found in our experiments that this two-step procedure is critical to the success of the regularization. 5. RESUL TS 5.1. Latent spaces properties In order to visualize the 64d latent spaces, we apply a simple Prin- cipal Component Analysis (PCA) to obtain a 3d representation. Using a PCA ensures that the visualization is a linear transform of the original space. Therefore, this preserves the real distances inside the latent space. Furthermore, this will allow to recov er an exploitable representation when we will use this space to gener- ate novel audio content. The results of learning regularized latent spaces for different spectral transforms are displayed in Figure 3. As we can see, in V AEs without regularization (small space), the relationships between instruments do not match perceptual rat- ings. Furthermore, the variance of distributions sho w that the model rather tries to spread the information across the latent space to help the reconstruction. Howe ver , the NSGT provides a better unregu- larized space with dif ferent instrumental distributions already well separated. Now , if we compare to the regularized spaces, we can clearly see the effect of the criterion, which provides a larger sep- aration of distribution. This effect and final result is particularly striking for the NSGT (c), which provides the highest correlation to the distances in our combined timbre space (Figure 2). Inter- estingly , the instrumental distributions might be shuffled around space in order to comply with the reconstruction objectiv e. Ho w- ev er , the pairwise distances reflecting perceptual relations are well matched as indicated by the KL div ergence. By looking at the test set reconstructions, we can see that enforcing the perceptual topology on the latent spaces do not impact the quality of audio reconstruction for the NSGT , where the reconstruction provides an almost perfectly matching distribution. In the case of the STFT , we can see that the model is impacted by the regularization and mostly match the overall density of the distribution rather than its exact peak information. Finally , it seems that the DCT model di- ver ged in terms of reconstruction, being unable to reconstruct the distributions. Howev er , we can see that the KL fit to timbre dis- tances is better than the STFT , indicating an ov erfit of the learning tow ards the regularization criterion. This generativ e ev aluation is quantified and confirmed in the next section. Method log p ( x ) k x − ˜ x k 2 Unregularized (NSGT) PCA - 2.2570 AE -1.2008 1.6223 V AE -2.3443 0.1593 Regularized (V AE) STFT -1.9237 0.2412 DCT 4.3415 2.2629 NSGT -CQT -2.8723 0.1610 NSGT -MEL -2.9184 0.1602 NSGT -ERB -2.9212 0.1511 T able 1: Generativ e capabilities ev aluated by the log likelihood and mean quality of reconstructed representations on the test set. 5.2. Generative capabilities W e quantify the generativ e capabilities from the latent spaces by computing the log likelihood and mean difference between the original and reconstructed spectral representations on the test set. W e compare these results for dif ferent transforms and without reg- ularization, which are presented in T able 1. As we can see, the unregularized V AE trained on the NSGT distribution pro vides a very good reconstruction capacity , and still generalizes very well. This can be seen in its ability to gener- ate spectral distributions from the test set almost perfectly . Inter- estingly , regularizing the latent space does not seem to affect the quality of the reconstruction at all. It ev en seems that the gener- alization increases with the regularized latent space. This could howe ver be explained by the fact that the regularized models are trained for twice as much epochs based on our tw o-fold procedure. It clearly seems that NSGTs provide both better generalization and reconstruction abilities, while the DCT seems to provide only a diver gent model. This can be explained by the fact that NSGT frequency axis is organized on a logarithmic scale. Furthermore, their distribution are well spread across this axis, whereas STFT and DCT tends to ha ve most of their informati ve dimensions in the bottom half of the spectrum. Therefore, NSGTs provide a more informativ e input. Finally , there only seems to be a marginal dif- ference between the results of different NSGT scales. Ho wev er , for all remaining experiments, we select the NSGT -ERB as it is more coherent with our perceptual endeav or . Thanks to the decoder and its generative capabilities, we can now directly synthesize the audio corresponding to any point in- side the latent space, but also any paths between two gi ven in- struments. This allo ws us to turn our analytical spaces into audio synthesizers. Furthermore, as shown in Figure 5 (Bottom right), synthesizing audio along these spaces lead to smooth evolution of spectral distributions and perceptually continuous synthesis (as discussed extensiv ely in the next section). In order to perform sub- jectiv e evaluation of the audio reconstruction, generated samples from the latent space are av ailable on the supporting repository . 5.3. Generalizing perception, audio synthesis of timbre paths Giv en that the encoder of our latent space is trained directly on spectral distributions, it is able to analyze samples belonging to new instruments that were not part of the original perceptual stud- ies. Furthermore, as the learning is regularized by perceptual rat- ings, we could hope that the resulting position would predict the perceptual relationships of this new instrument to the existing in- 5 (a) (b) (c) D 423.45 EH FH Tbn Tp Pi Vi Vc Sx Bn Cl Fl Ob STFT DCT D 834.15 KL KL D 312.89 D 981.24 KL KL D 2.811 D 517.42 KL KL NSGT Original Reconstruct Original Reconstruct Original Reconstruct Unr egularized Regularized Unr egularized Regularized Unr egularized Regularized Figure 3: Comparing the regularized V AE latent spaces (large) for the STFT (a), DCT (b) and NSGT (CQT) (c) transforms. F or each transform, we plot the corresponding unregularized space (small) and their respective D K L div ergence to the timbre space distances. W e plot a set of V AE decoder reconstructions of instrumental spectral frame distrib utions from the test set directly from the regularized spaces Centr oid EH FH Tbn Tp Pi Vi Vc Sx Bn Cl Fl Ob Picc -.75 -.45 -1 1 -1 1 Regularized NSGT latent space Centr oid Bandwidth -.15 .15 .45 .75 Unr egularized Regularized -.75 -.45 -.15 .15 .45 .75 Fr ench Hor n A4 - f f Piccolo E5 - f Audio descriptors topology Synthesized path Bandwidth X Y Z X Figure 4: (T op) Projecting ne w instruments inside the regularized latent space allow to see their perceptual relations to others. (Bot- tom right) W e can generate any path between instruments in the space and synthesize the corresponding perceptually-smooth audio ev olution. (Bottom, left) W e define 6 equally-spaced projection planes across the x axis and sample points on a 50x50 grid. W e reconstruct their audio distribution to compute their spectral cen- tr oid and bandwidth . W e compare the resulting descriptor space topology for unregularized (left) and re gularized (right) spaces. struments. This could potentially feed further perceptual studies, to refine timbre understanding. T o e valuate this hypothesis, we e x- tracted a set of Piccolo audio samples to ev aluate their beha vior in latent space. W e perform the same processing as for the training dataset (Section 4.1) and encode these new samples in the latent space to study the out-of-domain generalization capabilities of our model. The results of this analysis are presented in Figure 5 (T op). Here, we can see that new samples (represented by their cen- troid for clarity) are encoded in a coherent position in the latent space, as they group with their families, ev en though they were nev er presented to the model during learning. Howev er, obtain- ing a definitive answer on the perceptual inference capabilities of these spaces would require a complete perception experiment, that we leave to future work. Now , as argued previously , one of the key property of the latent spaces is that they provide an inv ertible non-linear mapping. Therefore, we could thriv e on this property to truly understand what are the perceptual relations between in- struments based on the behavior of spectral distributions between the points in the timbre space. T o exhibit this capability , we en- code the position in the latent space of a Piccolo sample playing an E5-f. Then, based on the position of a F r ench Horn playing an A4-ff, we perform an interpolation between these latent points to obtain the path between these two instruments in latent space. W e then sample and decode the spectral distributions at 6 equally spaced positions along the path, which are displayed in Figure 5 (Right). As we can see, the resulting audio distributions demon- strate a smooth ev olution between timbral structures of both in- struments. Furthermore, the resulting interpolation is clearly more complex than a linear change between one structure to the other . Hence, this approach could be used to understand more deeply the timbre relationships between instruments. Also, this provides a model able to perform perceptually-relev ant synthesis of novel timbres, while sharing the properties of multiple instruments. 5.4. T opology of audio descriptors Here, we analyze the topology of signal descriptors across the la- tent space. As the space is continuous, we do so by sampling uniformly the PCA space and then using the decoder to gener- ate audio samples at a given point. Then, we compute the au- dio descriptors of this sample. In order to provide a visualiza- tion, we select 6 equally-distant planes across the x dimension, at {− . 75 , − . 45 , − . 15 , . 15 , . 45 , . 75 } , which define an uniform 50x50 6 grid between [ − 1 , 1] on other dimensions. W e compare the re- sults between unregularized or regularized NSGT latent spaces in Figure 5 (Bottom left) for the spectr al centr oid and spectral band- width . Animations of continuous traversals of the latent space are av ailable on the supporting repository . As we can see, the audio descriptors behav e following ov erall non-linear patterns for both unregularized and regularized latent spaces. Howe ver , they still exhibit locally smooth properties. This shows that our model is able to org anize audio variations. In the case of unregularized spaces, the organization of descriptors is spread out in a more e ven fashion. The addition of perceptual ratings to regularize the learn- ing seems to require that this space is or ganized with a more com- plex topology . This could be explained by the fact that, in the unregularized case, the V AE only needs to find a configuration of the distributions that maximizes their reconstruction. Oppositely , the regularization requires that instrumental distances follow the perceptual dissimilarity ratings, prompting the need for a more complex relationship between descriptors. This might underline the fact that linear correlations between MDS dimensions and au- dio descriptors is insuf ficient to truly understand the dimensions related to timbre perception. Howe ver , the audio descriptors topol- ogy overall still pro vide locally smooth ev olutions. Finally , a very interesting observation comes from the topology of the centroid. Indeed, all perceptual studies underline its correlation to timbre perception, which is partly confirmed by our model (by projecting on the y axis). This tends to confirm the perceptual relev ance of our regularized latent spaces. Howev er, this also shows that the relation between centroid and timbre might not be linear . 5.5. Descriptor-based synthesis As shown in the previous section, the audio descriptors are or- ganized in a smooth locally linear way across the space. Further- more, as discussed in Section 5.1, we ha ve seen that the instrumen- tal distributions are grouped across spaces depending on percep- tual relations. Based on these two findings, we hypothesize that we can find paths inside these spaces that modify a gi ven audio distri- bution to follow a target descriptor , while remaining perceptually smooth. Hence, we propose a simple method for perceptually- relev ant descriptor -based path synthesis presented in Algorithm 1. Based on the latent space z (with corresponding encoder q and decoder p ) and a giv en origin spectrum x 0 , the goal of this algo- rithm is to find the succession of spectral distributions that match a given target evolution t ∈ R N for a descriptor d . First, we find the position of the origin distribution in latent space z 0 and ev al- uate its descriptor value d 0 (lines 1-4). Then for each point i , we compute the descriptor values D i in the neighborhood of the cur- rent latent point (lines 6-10) by decoding their audio distrib utions. Note that the the neighborhood is defined as the set of close latent points, and its size directly defines the complexity of the optimiza- tion. Then, we select the neighboring latent point z i that provides the e volution of descriptor closest to the target e volution t [ i ] (lines 11-14). Finally , we obtain the spectral distribution S [ i ] by decod- ing the latent position z i . The results of applying this algorithm to a giv en instrumental distribution is presented in Figure 5. Here, we start from the NSGT distribution of a Clarinet-Bb playing a G#4 in fortissimo . W e apply our algorithm twice from the same origin point, either on a descending target shape for the spectral centroid (top), or an ascending log shape for the spec- tral bandwidth (bottom). In both cases, we plot the synthesized NSGT distributions at different points of the optimized path, and Algorithm 1: Descriptor-based path synthesis Data: space z , encoder q φ ( z | x ) , decoder p θ ( x | z ) Data: origin spectrum x 0 , target series t 1 ..N , descriptor d Result: spectral distrib . S ∈ R N × F 1 // Find origin position in latent space 2 z 0 = q φ ( x 0 ) 3 // Evaluate origin descriptor 4 d 0 = ev aluate ( x 0 , d ) 5 for i ∈ [1 , N ] do 6 // Latent 3-d neighborhood of current point 7 N i = neig hborhood ( z i − 1 ) 8 // Sample and ev aluate descriptors 9 X i = q φ ( N i ) 10 D i = ev aluate ( X i , d ) 11 // Compute difference to tar get 12 ∆ i = k ( D i − d i − 1 ) − ( t [ i ] − t [ i − 1]) k 2 13 // Find next latent point 14 z i = ar gmin (∆ i ) 15 // Decode distribution 16 S [ i ] = p θ ( z i ) 17 end the neighboring descriptor space. As we can see, the resulting de- scriptor ev olution closely match the input tar get in both cases. Fur- thermore, we can see by visual inspection of the spectrum ev olu- tion, that the corresponding distributions are indeed sharply mod- ified to match the desired descriptors. Interestingly , the optimiza- tion of different target shapes on different descriptors lead to widely different paths in the latent space. Howe ver , the ov erall timbre structure of the original instrument still seems to follow a smooth ev olution. Here, we note that the algorithm is quite rudimentary , and could benefit from more global neighborhood information, as witnessed from the slightly erratic local selection of latent points. 6. CONCLUSION Here, we hav e shown that regularizing V AEs with perceptual rat- ings provides timbre spaces that allow for high-le vel analysis and audio synthesis directly from these spaces. The organization of these perceptually-re gularized latent spaces pro ve the flexibility of these systems, and provides a latent space from which generation of novel audio content is straightforward. These spaces allow to extrapolate perceptual results on new sounds and instruments with- out the need to collect new measurements. Finally , by analyzing the behavior of audio descriptors across the latent space, we hav e shown that e ven though they follow a non-linear e volution, they still exhibit some locally smooth properties. Based on these, we introduced a method for descriptor-based path synthesis that allow to synthesize audio that match a target descriptor shape, while re- taining the timbre structure of instruments. Future work on these latent spaces would be to perform perceptual experiments to con- firm their perceptual topology . 7. REFERENCES [1] Stephen McAdams, Bruno L. Giordano, Patrick Susini, Ge- offro y Peeters, and V incent Rioux, “ A meta-analysis of 7 T ar get Centr oid Bandwidth Result T ar get Result Origin point Clarinet-Bb - G#4 f f Original NSGT Regularized latent space 0 1 .3 .8 0 1 .6 .9 Decoded NSGT Descriptor neighborhood Descriptor neighborhood Decoded NSGT Figure 5: Descriptor-based synthesis . Given an origin point in latent space (Clarinet-Bb G#4 ff), we apply our algorithm either on a descending target shape for the spectral centroid (top), or an ascending log shape for the spectral bandwidth (bottom). In both cases, we plot the decoded NSGT distributions and neighboring descriptor space information along the optimized path acoustic correlates of timbre dimensions, ” Journal of the Acoustical Society of America , vol. 120, no. 5, 2006. [2] John M Grey and John W Gordon, “Perceptual effects of spectral modifications on musical timbres, ” The J ournal of the Acoustical Society of America , vol. 63, no. 5, 1978. [3] Aaron V an Den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol V inyals, Alex Graves, Nal Kalchbren- ner , Andrew Senior , and K oray Kavukcuoglu, “W avenet: A generativ e model for raw audio, ” arXiv preprint arXiv:1609.03499 , 2016. [4] Soroush Mehri, Kundan Kumar , Ishaan Gulrajani, Rithesh Kumar , Shubham Jain, Jose Sotelo, Aaron Courville, and Y oshua Bengio, “Samplernn: An unconditional end-to-end neural audio generation model, ” ICLR Conference , 2017. [5] Jesse Engel, Cinjon Resnick, Adam Roberts, Sander Diele- man, Douglas Eck, Karen Simonyan, and Mohammad Norouzi, “Neural audio synthesis of musical notes with wa venet autoencoders, ” arXiv preprint:1704.01279 , 2017. [6] Diederik P Kingma and Max W elling, “ Auto-encoding vari- ational bayes, ” ICLR Conference , 2014. [7] Irina Higgins, Loic Matthey , Arka Pal, Christopher Burgess, Xavier Glorot, Matthew Botvinick, Shakir Mohamed, and Alexander Lerchner , “beta-v ae: Learning basic visual con- cepts with a constrained variational frame work, ” ICLR Con- fer ence , 2016. [8] Peter Balazs, Monika Dörfler , Florent Jaillet, Nicki Ho- lighaus, and G V elasco, “Theory , implementation and ap- plications of nonstationary gabor frames, ” J ournal of com- putational and applied mathematics , vol. 236, no. 6, 2011. [9] Laurens v an der Maaten and Geof frey Hinton, “V isualizing data using t-sne, ” Journal of machine learning resear ch , v ol. 9, no. Nov , pp. 2579–2605, 2008. [10] John M Grey , “Multidimensional perceptual scaling of mu- sical timbres, ” the J ournal of the Acoustical Society of Amer- ica , vol. 61, no. 5, pp. 1270–1277, 1977. [11] Carol L Krumhansl, “Why is musical timbre so hard to un- derstand, ” Structure and perception of electr oacoustic sound and music , vol. 9, pp. 43–53, 1989. [12] Paul Iverson and Carol L Krumhansl, “Isolating the dynamic attributes of musical timbrea, ” The Journal of the Acoustical Society of America , vol. 94, no. 5, pp. 2595–2603, 1993. [13] Stephen McAdams, Suzanne Winsber g, Sophie Donnadieu, Geert De Soete, and Jochen Krimphoff, “Perceptual scaling of synthesized musical timbres: Common dimensions, speci- ficities, and latent subject classes, ” Psychological r esear ch , vol. 58, no. 3, pp. 177–192, 1995. [14] Stephen Lakatos, “ A common perceptual space for harmonic and percussiv e timbres, ” P erception & psychophysics , vol. 62, no. 7, pp. 1426–1439, 2000. [15] Christopher M Bishop and T om M Mitchell, “Pattern recog- nition and machine learning, ” 2014. [16] Keith Hastings, “Monte carlo sampling methods using markov chains and their applications, ” Biometrika , vol. 57, no. 1, pp. 97–109, 1970. [17] Casper Kaae Sønderby , T apani Raiko, Lars Maaløe, Søren Kaae Sønderby , and Ole W inther , “How to train deep variational autoencoders and probabilistic ladder networks, ” arXiv pr eprint arXiv:1602.02282 , 2016. [18] Jen-Tzung Kuo and Kuan-T ing Chien, “V ariational recur- rent neural netw orks for speech separation, ” INTERSPEECH 2017 . [19] W ei-Ning Hsu, Y u Zhang, and James Glass, “Learning latent representations for speech generation and transformation, ” arXiv pr eprint arXiv:1704.04222 , 2017. [20] Guillaume Ballet, Riccardo Borghesi, Peter Hoffmann, and Fabien Levy , “Studio online 3.0: An internet "killer appli- cation" for remote access to ircam sounds and processing tools, ” Journee Informatique Musicale (JIM) , 1999. [21] Diederik P Kingma and Jimmy Ba, “ Adam: A method for stochastic optimization, ” arXiv preprint:1412.6980 , 2014. 8
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment