i벡터 기반 음성 구문 검증
본 논문은 i‑vector를 활용해 화자와 무관하게 구문(패스프레이즈)의 일치 여부를 판별하는 방법을 제안한다. 구문별 HMM 정렬과 딥러닝 기반 bottleneck 특징을 이용해 추출한 i‑vector에 단순 코사인 유사도 혹은 Linear Gaussian Classifier(LGC)를 적용하면, 기존 복잡한 방법보다 낮은 EER을 달성한다. RSR2015와 RedDots 데이터베이스 실험 결과가 이를 입증한다.
저자: Hossein Zeinali, Lukas Burget, Hossein Sameti
본 논문은 “spoken pass‑phrase verification”(음성 구문 검증)이라는 과제를 i‑vector 프레임워크 내에서 해결하고자 한다. 구문 검증은 테스트 발화가 사전에 제공된 구문과 동일한지를 판단하는 작업으로, 텍스트‑종속 화자 인증 시스템에서 화자와 구문을 동시에 검증하거나, 랜덤 구문을 제시해 사용자의 실시간 반응(liveness)을 확인하는 용도로 활용될 수 있다. 기존 연구에서는 MFCC‑GMM 기반 로그우도비, HMM‑GMM 적응, DTW, 텍스트 기반 ASR 점수 등 네 가지 방법이 제시되었지만, 이들 모두 복잡한 모델링이나 텍스트 의존성, 혹은 제한된 구문 구분 성능이라는 한계를 가지고 있었다.
저자들은 이전에 텍스트‑종속 화자 인증에 i‑vector를 적용하면서 구문‑특화 HMM 정렬과 딥러닝 기반 bottleneck(BN) 특징이 구문 구분에 유리함을 확인했다. 이를 바탕으로, 현재 연구에서는 동일한 i‑vector 추출 기법을 화자‑독립 구문 검증에 그대로 적용한다. 구체적으로 두 가지 경로를 제시한다.
1. **HMM 기반 정렬**: 각 구문에 대해 3‑state monophone HMM을 구성하고, 각 상태를 GMM으로 모델링한다. 구문 텍스트가 알려진 경우, Viterbi 알고리즘을 통해 프레임을 HMM 상태에 정렬하고, 이 정렬 정보를 사용해 충분통계(sufficient statistics)를 수집한다. 이렇게 얻은 통계로부터 600‑차원 i‑vector를 추출한다. 이 과정에서 사용되는 GMM은 모든 HMM 상태를 통합한 하나의 대규모 가우시안 집합이며, HMM 정렬 덕분에 i‑vector가 구문 정보를 강하게 반영한다.
2. **Bottleneck 특징**: 두 단계의 stacked bottleneck DNN을 활용한다. 첫 번째 DNN은 36개의 로그 멜 필터뱅크와 3개의 기본 주파수(F0) 특징을 입력받아 30‑프레임(300 ms) 컨텍스트를 압축한 중간 BN 특징을 출력한다. 두 번째 DNN은 첫 번째 DNN의 BN 출력을 시간적으로 스택하고, 다시 압축된 BN 특징을 생성한다. 최종 BN 특징은 약 30 ms 프레임당 30‑프레임 컨텍스트 정보를 담고 있어, 음소 구분 능력이 뛰어나다. 이 BN 특징을 기존 UBM‑GMM(1024 가우시안)과 결합해 i‑vector를 추출한다. HMM 없이도 구문 구분 성능이 우수함을 실험적으로 확인한다.
점수 산출 단계에서는 복잡한 PLDA나 SVM 대신 두 가지 단순 기법을 사용한다.
- **Linear Gaussian Classifier (LGC)**: 각 구문을 평균 μ_i와 공통 공분산 Σ로 모델링한다. 사후 확률 P(i|w) = N(w|μ_i, Σ)·P(i) / Σ_k N(w|μ_k, Σ)·P(k) 로 계산하며, 동일 사전 확률을 가정한다. LGC는 클래스 간 공분산이 동일하고 평균만 차이가 날 때 최적이다.
- **Cosine Similarity**: 구문별 평균 i‑vector와 테스트 i‑vector 사이 코사인 유사도를 계산한다. Max‑Norm 정규화를 적용하면, 테스트 샘플이 가장 유사한 구문을 제외한 나머지와의 차이를 강조해 정확도가 상승한다.
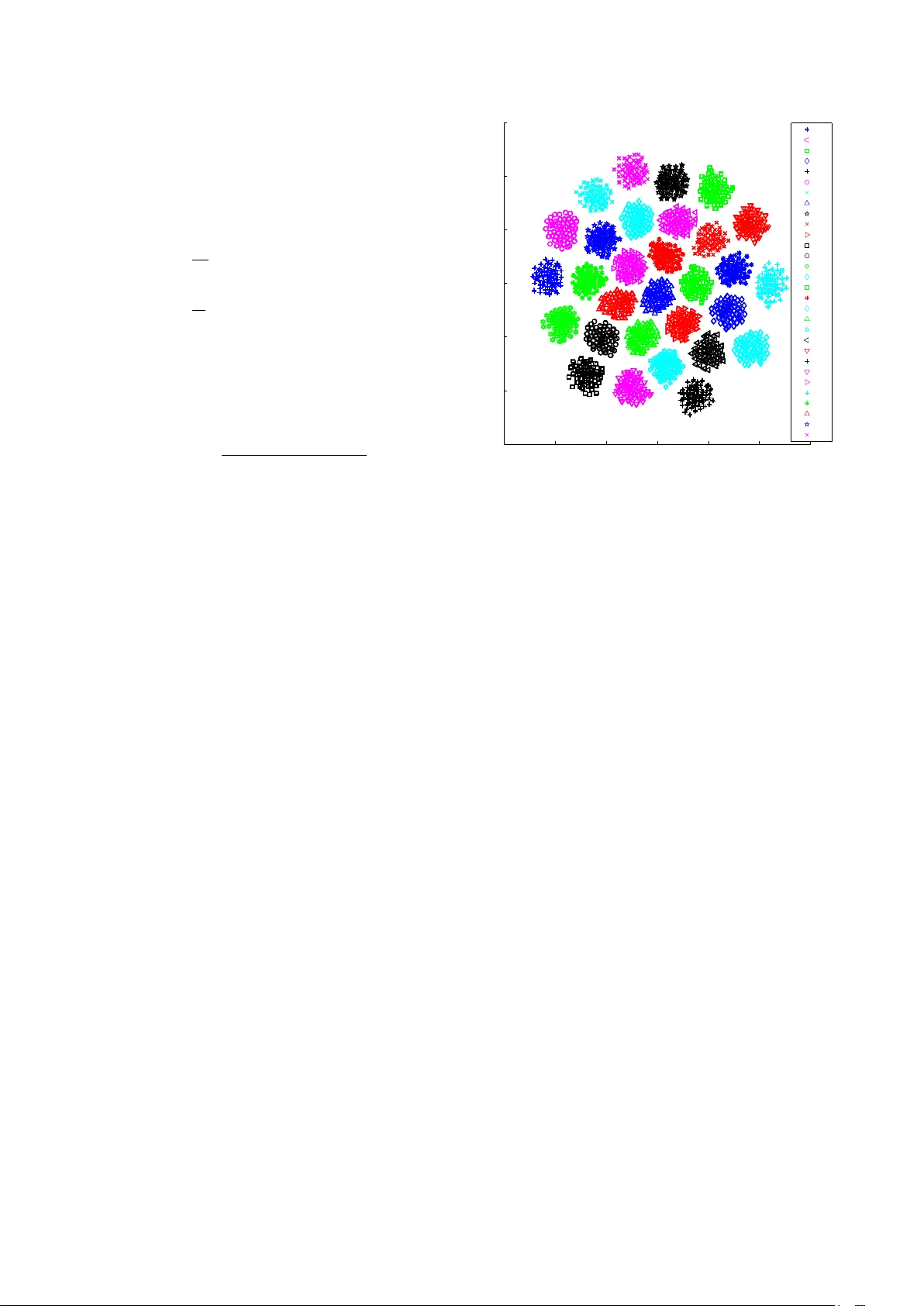
t‑SNE 시각화 결과는 30개의 구문이 서로 명확히 구분된 클러스터를 형성함을 보여준다. 이는 i‑vector 공간이 구문 정보를 고차원에서 저차원으로 보존하고 있음을 의미한다.
**실험 설정**: RSR2015 Part‑1(30 구문, 남성 화자 50명 훈련, 57명 평가)과 RedDots Part‑1(10 구문, 남성 화자 49명 중 9명 훈련, 30명 평가)을 사용했다. i‑vector 차원은 600, UBM은 1024 가우시안, HMM은 각 상태당 8개 가우시안으로 설정했으며, BN 모델은 LibriSpeech 기반으로 사전 학습했다.
**결과**: RSR2015에서 LGC와 코사인 모두 0 % EER을 기록했으며, 코사인 Max‑Norm 역시 0 %에 근접했다. RedDots에서도 코사인 기반이 0.5 % 이하의 EER을 달성, 기존 UV1‑UV4 대비 현저히 낮은 오류율을 보였다. 훈련 데이터 양을 감소시켜도 (구문당 10~30개 샘플) 성능 저하가 미미했다. 이는 i‑vector가 구문 정보를 강하게 내재하고 있음을 다시 한 번 입증한다.
**의의 및 활용**: 구문‑특화 HMM 정렬 혹은 BN 특징을 이용한 i‑vector는 구문 검증에 최적화된 저차원 표현을 제공한다. 단순 코사인 스코어링만으로도 높은 정확도를 얻을 수 있어, 실시간 서비스나 저전력 디바이스에 적용하기에 매우 적합하다. 또한, 화자‑독립성을 유지하면서도 텍스트‑종속 인증 시스템에 보조적인 liveness 검증 단계로 활용할 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기