Spoken Pass-Phrase Verification in the i-vector Space
The task of spoken pass-phrase verification is to decide whether a test utterance contains the same phrase as given enrollment utterances. Beside other applications, pass-phrase verification can complement an independent speaker verification subsyste…
Authors: Hossein Zeinali, Lukas Burget, Hossein Sameti
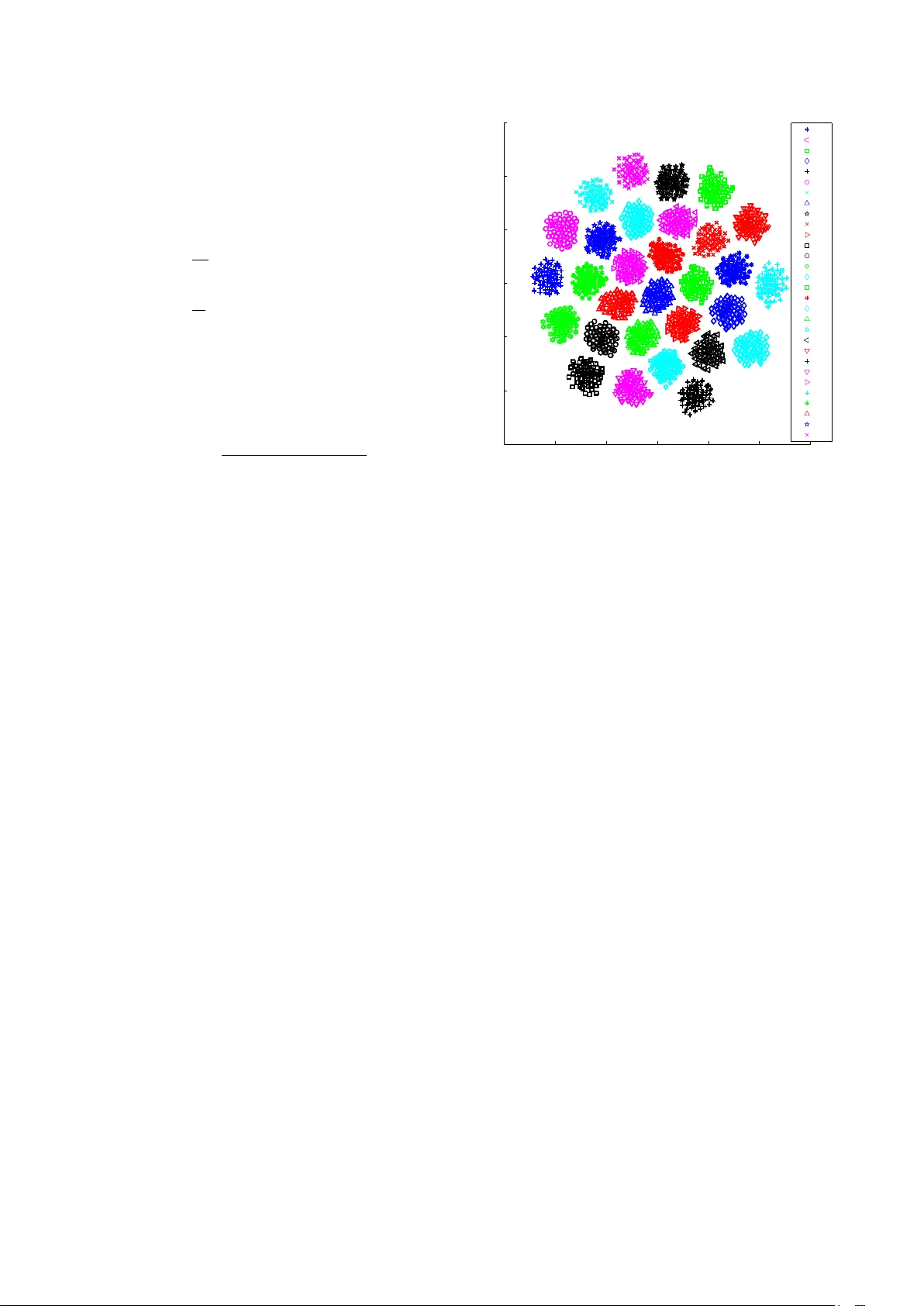
Spoken P ass-Phrase V erification in the i-vector Space Hossein Zeinali 1 , 2 , 3 , Luk ´ a ˇ s Bur g et 2 , Hossein Sameti 1 , J an “Honza” ˇ Cernock ´ y 2 1 Sharif Uni versity of T echnology , T ehran, Iran 2 Brno Uni versity of T echnology , Speech@FIT and IT4I Center of Excellence, Czech Republic 3 Sharif DeepMine Ltd., T ehran, Iran hsn.zeinali@gmail.com, burget@fit.vutbr.cz, sameti@sharif.edu, cernocky@fit.vutbr.cz Abstract The task of spoken pass-phrase verification is to decide whether a test utterance contains the same phrase as giv en enrollment utterances. Beside other applications, pass-phrase verification can complement an independent speak er v erification subsystem in text-dependent speaker v erification. It can also be used for liv eness detection by verifying that the user is able to correctly respond to a randomly prompted phrase. In this paper , we build on our previous work on i-vector based text-dependent speaker verification, where we have shown that i-vectors extracted using phrase specific Hidden Marko v Models (HMMs) or using Deep Neural Network (DNN) based bottle-neck (BN) features help to reject utterances with wrong pass-phrases. W e apply the same i-vector extraction techniques to the stand-alone task of speaker- independent spoken pass-phrase classification and verification. The experiments on RSR2015 and RedDots databases sho w that very simple scoring techniques (e.g. cosine distance scoring) applied to such i-vectors can pro vide results superior to those previously published on the same data. 1. Introduction Utterance V erification (UV) is the task of confirming the con- tent of a gi ven utterance and answering the question of whether the user uttered the prompted pass-phrase or not. In this pa- per , we focus on spoken pass-phrase verification, where one or more spoken examples are gi ven for the required pass-phrase. In other words, the task is to verify whether a test utterance (from, possibly , a pre viously unseen speaker) contains the same pass-phrase as a giv en enrollment utterance or a set of enroll- ment utterances. UV is a subtask of text-dependent Speaker V erification (SV), where the correctness of the uttered pass- phrase needs to be v erified together with the speaker identity . Here, the UV component helps to prev ent from replay attacks using a random utterance of the target speak er . A single model is often used in text-dependent SV to jointly address both UV and SV tasks. For example, in our pre vious work on i-vector based text-dependent SV [1, 2, 3], HMMs constructed specifically for each pass-phrase were used to ex- tract sufficient statistics in order to make the resulting i-vectors both speaker and phrase specific. Further text-dependent SV experiments hav e shown that it is enough to use the more con ventional Uni versal Background Model - Gaussian Mixture Model (UBM-GMM) if the i-vectors are extracted from BN features [4, 5]. The frame-by-frame BN features are obtained from a DNN, which is trained to extract phonetic information from the acoustic conte xt (300 ms) around the current frame. I-vectors extracted from such BN features contain lots of infor- mation about the phonetic content of the corresponding utter - ances and are very good for rejecting utterances with incorrect pass-phrases. Although a single model can be used to jointly address both UV and SV tasks, there is still good reason to hav e stand- alone (speaker-independent) system for utterance verification or classification. In text-dependent SV , for example, replay attacks with pre-recorded correct pass-phrases are very diffi- cult to reject. A possible way to tackle this problem is to use anti-spoofing techniques based on detecting typical distortions in recorded and replayed audio [6] or using audio fingerprint- ing [7] to detect a replay of an enrollment utterance. Ho wev er , these techniques are often not very reliable. An alternativ e is to use a liv eness detection using a separate UV subsystem as fol- lows: in one step, a standard te xt-dependent SV is used to verify the speaker , while in the second step the user is prompted some random phrase, which he needs to pronounce to prove his re- sponsiv eness. Speaker identity can be verified from this second phrase in more text independent f ashion. More importantly , the correctness of the phrase can be verified by the UV subsystem. The prompted random phrase can be in a textual form or can be represented by audio recording. The later case is of our main interest. Note that the UV techniques can be also applied to other problems than the text-dependent SV . An example can be re-scoring detections in keyw ord spotting or query-by-example system [8]. In this work, we experiment with the aforementioned i- vector based text-dependent SV techniques. Howe v er , we apply these techniques to the stand-alone task of (speaker - independent) spoken pass-phrase verification or classification. W e show that the i-vectors extracted in the described way con- tain predominantly information about the lexical content of the utterance and are therefore e xcellent representations for this task. W e also show that our solution based on the simple i- vector representation outperforms the previously proposed and often more computationally complex methods, which serve as our baseline [9]. 2. Baseline Utterance V erification Methods The effort on UV described in the literature is quite limited. In [9], four systems are described, which constitute a good ex- ample of the standard techniques for UV . W e use these systems and the corresponding results as our baseline. In some of our experiments with i-vector based UV , the same setup as in [9] is used to make the results directly comparable. Here, we provide the only brief description of these baseline systems. For more detailed description, we kindly refer the reader to [9]. The system denoted as UV1 uses Mel-Frequency Cep- stral Coefficients (MFCCs) with their first and second order deriv ati ves and a GMM-UBM with 512 Gaussian components trained on TIMIT data. The utterance models are adapted from the GMM-UBM using the standard relev ance maximum- a-posteriori (MAP) adaptation [10] and the log-likelihood ratio between the utterance and the UBM serves as the UV score. Note that this technique only models the distribution of acous- tic features in the training utterances, but does not try to model the temporal structure of the uttered phrases. The system denoted as UV2 uses 5-state HMM with the left-to-right topology to model the temporal structure of utter - ances. Each state is modeled using a GMM, which is MAP adapted in a similar manner and from the same GMM-UBM as in the case of the system UV1. V iterbi alignment of frames to HMM states is used to train phrase specific models on training utterances and to evaluate the log-likelihood ratio score for the test utterances. The UV3 system uses perhaps the most conv entional ap- proach to spoken utterance verification: dynamic time warping (DTW) [11] is used to frame-align utterances and to calculate the distances between the utterances. Euclidean distance be- tween MFCC feature vectors is used as the frame-to-frame dis- tortion. Note that the DTW based UV could be further improved by using more sophisticated frame-to-frame distortions [12] or by calibrating the resulting DTW scores to make them proper UV log-likelihood ratios [13]. These improvements are, ho w- ev er , not considered in this work. UV4 makes use of a DNN based automatic speech recog- nition (ASR) system trained on TIMIT data using Kaldi [14] toolkit. Each test utterance is forced-aligned to the known ref- erence transcript of a given pass-phrase and the acoustic score (pseudo log likelihood) for this alignment is used as the UV score. Note that this system performs UV using the pass-phrase giv en as text, unlike the other methods described in this paper , which rely on spoken pass-phrase. 3. i-vector Based Utterance V erification In this work, we use i-vectors as fixed length low-dimensional representations of speech utterances. First, i-vectors were pro- posed for the task of text-independent speaker recognition [15], but soon became popular for other tasks of utterance lev el clas- sification or verification such as language, gender , signature, age or emotion recognition [16, 17, 18, 19]. In the probabilis- tic model for i-vector extraction, a low-dimensional latent vari- able is used to representing utterance specific GMM. I-vector is the MAP point estimated of the latent variable adapting the corresponding GMM to a giv en speech utterance. For more de- tails on the i-vector model, we kindly refer the reader to other sources [15, 5]. Here, we only recall that the i-vector can be inferred from sufficient statistics, which are collected from the speech utterance. T o collect the suf ficient statistics, we need an alignment of speech frames to i-v ector model Gaussian compo- nents. This alignment is traditionally obtained using an under- lying UBM-GMM. 3.1. HMM based frame alignment methods In our pre vious works on te xt-dependent SV [1, 2] and also text- prompted SV [3], i-vectors were extracted using HMM based alignment. For this purpose, phoneme recognizer is first trained, where mono-phone 3-state HMMs are used with state distribu- tions modeled using GMMs. Giv en the kno wn transcriptions of enrollment and test utterances, the phrase specific HMMs are constructed from the mono-phone HMMs. The V iterbi algo- rithm is then used to obtain the alignment of the frames to the HMM states in order to collect the sufficient statistics. Note that, while there is a specific HMM built for each phrase, there is only one set of Gaussian components (Gaussians from all the HMM states of all phone models) corresponding to a sin- gle phrase-independent i-vector extraction model. The i-vector extractor is trained and used in the usual way , except that, it benefits from the better alignment of frames to Gaussian com- ponents as constrained by the HMM model. More details on this i-vector e xtraction method can be found in [1, 5]. For text-dependent SV , it was shown [1, 2] that this alignment extraction strategy produces more phrase specific i- vectors, which are especially effecti v e for rejecting utterance with wrong pass-phrases. For the same reason, this technique is also suitable for utterance verification task as demonstrated in our experiments. One the drawback of this approach is that we need to know the phrase specific phone sequence for construct- ing the corresponding HMM. 3.2. Bottleneck features MFCCs were conv entionally used as the speech features for i- vector extraction. More recently , howe v er , significant improve- ments were obtained for both text-dependent [4, 5] and text- independent [20, 21, 22] verification task from using BN fea- tures or concatenated MFCC+BN features. Note that BN fea- tures were pre viously successfully used also in other areas of speech processing [23, 24, 25]. BN features are frame-by-frame extracted using a bottle- neck DNN, which is typically trained for phone classification. Bottleneck DNN is a neural network with a specific topology , where one of the hidden layers has significantly lo wer dimen- sionality than the surrounding layers. A bottleneck feature vec- tor is generally understood as a by-product of forwarding a pri- mary input feature vector through the DNN, while reading the output of the bottleneck layer where the relev ant information is compressed into a low dimensional vector . In this work, we use more elaborate architecture for BN features called Stacked Bottleneck Features [26]. This architecture is based on a cas- cade of tw o such BN DNNs. The BN output of the first net- work is stacked in time, defining context-dependent input fea- tures for the second DNN. The input features to the first stage DNN are 36 log Mel-scale filter bank outputs augmented with 3 fundamental frequency features [26] and normalized using con versation-side based mean subtraction. The outputs from the BN layer of the second stage DNN are then taken as the final output features (i.e. the features to train the i-vector model on). W ith this architecture, each output feature vector is effecti vely extracted from at least 30 frames (300 ms) of the input features in the context around the current frame. Therefore, each BN feature vector contains important information about the pho- netic context around the current frame, which is further prop- agated to the i-v ector extracted from these features. This makes BN feature based i-vectors very phrase specific ev en when ex- tracted using the conv entional UBM-GMM model (i.e. there is no need for the HMM based alignment), which was previously demonstrated in text-dependent SV e xperiments [4, 5]. 3.3. Scoring methods In our experiments, we consider both the task of close-set pass- phrase classification and open-set pass-phrase verification. T o classify or compare i-vectors, we use only two very simple tech- niques, namely Linear Gaussian Classifier (LGC) and cosine similarity scoring. 3.3.1. Linear Gaussian Classifier (LGC) For each class (pass-phrase) i = 1 . . . K , LGC assumes Gaus- sian distribution of i-vectors N ( w | µ i , Σ ) . Each class is mod- eled by its o wn mean vector µ i . All the classes, howe ver , share the same average within-class covariance matrix Σ , which is typically estimated as µ i = 1 N i N i X n =1 w n i (1) Σ = 1 N K X i =1 N i X n =1 ( w n i − µ i )( w n i − µ i ) T , (2) where N i is the number of training samples (i-vectors) for phrase i and w n i is the n th training sample of phrase i . Once the model is trained on the training (or enrollment) utterances, ev aluation data can be classified by simply selecting the class with the highest posterior probability: P ( i | w ) = N ( w | µ i , Σ ) P ( i ) P K k =1 N ( w | µ k , Σ ) P ( k ) , (3) were we assume equal priors P ( i ) for all classes. T o be con- sistent with results from [9], we also report the performance in terms of Equal Error Rate (EER) for LGC, where the posterior probabilities serve as the verification score for the correspond- ing classes. In this case, ho wev er , we cannot talk about open-set verification as the score from the close-set of K phrases de- pends on each other through the normalization in the posterior probability calculation. 3.3.2. Cosine Similarity Scoring Cosine similarity scores are also used in our e xperiments to per- form classification and verification of i-vectors. In this case, the enrolled pass-phrase models are obtained as a simple average of training (or enrollment) i-vectors. Note that there is no need to estimate any cov ariance matrix for this scoring method, which makes it more robust for the cases where only few training ex- amples are a v ailable. T o perform classification of a test utter- ance, we can select the class with the highest cosine similarity score. For the detection task (i.e. to ev aluated EER), we simply use the cosine similarity score as the verification scores. Note that in this case, verification scores for individual pass-phrases are completely independent of each other and the obtained EER can be correctly interpreted as open-set pass-phrase v erification performance. Again, to be consistent with results from [9], we alterna- tiv ely normalize the cosine similarity scores using the so-called Max-Norm method. In this case, for each test utterance, the maximum of cosine scores over all other the K − 1 phrases is subtracted from the original cosine scores. The same normal- ization is also used for some of the results from [9], which are also presented for comparison in T able 2. Although the normal- ization (seemingly) improves the classification and verification results, we no more deal with the open-set verification problem just like in the case of LGC. 3.3.3. Motivation for simple classifiers W e hav e used t-SNE [27] to reduce 400-dimensional i-vectors extracted using UBM-GMM from MFCC+BN features into 2- dimensional space. The i-vectors were tak en from all male speakers from the RSR2015 test set. Figure 1 shows the plot of −150 −100 −50 0 50 100 150 −150 −100 −50 0 50 100 150 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 Figure 1: Male i-v ectors from the RSR2015 database reduced to 2-dimensional space using t-SNE. There are 30 well separated clusters corresponding to different phrases. the resulting vectors for 30 phrases of the RSR2015 database. Each point in the plot corresponds to one i-vector and is colored according to the phrase label. One can see that i-vectors from different phrases form nicely separated clusters in the t-SNE space. Moreover , all classes have roughly Gaussian distribu- tion with the same within-class co v ariance matrix. Although, in general, t-SNE provides nonlinear transformation of the origi- nal space, the nicely separated clusters and simple distributions make us believe that pass-phrase verification should be an easy task in this i-vector space and simple scoring technique should be sufficient. 4. Experimental setup W e report results on Part1 of the RSR2015 database [28] as well as Part1 of the RedDots database [29]. RSR2015 comprises recordings from 30 different phrases. The same phrases appear in three disjoint subsets of speakers bac kgr ound , de velopment and evaluation set . Each speakers repeats each phrase 9 times. The male utterances from the backgr ound set (50 speakers) are used for training the classifiers. The results are reported on male part of the evaluation set (57 speakers). The development set is not used in our experiments. Part1 of RedDots contains 49 male speakers, each pro- nouncing se veral times 10 common pass-phrases. For the re- sults reported in T able 2, the evaluation setup defined at UEF univ ersity was adopted to make our results directly comparable with those previously reported in [9]. In this setup, all utter- ances from 9 different speakers are used to train the 10 pass- phrase models (In total, 1485 utterances are used for training, roughly 148 utterances per pass-phrase) and 30 other speakers are selected for the e v aluation set. Note that 10 out of the 49 male speaker were not used at all in our experiments. For the results reported in T able 3 analyzing the performance for re- duced amount of training data, sev eral subsets of the 9 training speakers are used and e v aluation set remains unchanged. T able 1: Performance of the i-vector based methods on RSR2015 . Classification EER Error [%] [%] LGC 0.0 0.000 Cosine 0.0 0.007 Cosine Max-Norm 0.0 0.000 A UBM-GMM with 1024 components, alignment HMMs with 3 states and 8 components in each state and a 600- dimensional i-vector e xtractor are trained using LibriSpeech database [30] and the backgr ound set of RSR database. BN feature extractor was also trained on LibriSpeech [5]. In order to e valuate EERs, the verification scores for the individual pass-phrases are simply polled. W e understand that it is questionable to use such pooled EER in the case of close- set problem, where the verification scores are normalized using the scores from the competing hypothesis (i.e. our results with LGC and Cosine Max-Norm). Nev ertheless, we also include such results in order to allo w for comparison with the baselines from [9]. F or the RSR2015 database, each ev aluation utterance forms one target trial and 29 non-target trials corresponding to the remaining pass-phrases. Similarly , one target and 9 non- target trials are formed for each e v aluation utterance from Red- Dots. 5. Results 5.1. RSR2015 Results First, we report results on male utterances from RSR2015 e val- uation set . This is an e xample of a scenario where plenty of training examples are a vailable for each of 30 pass-phrases ( 50 × 9 = 450 training utterances per phrase). Further , we deal here with the ideal condition, where UBM and i-v ector e x- tractor are trained on training data of the same phrases. This leads to nearly faultless recognition performance for any of the scoring technique as presented in T able 1. In this case, we hav e chosen i-vectors extracted using UBM-GMM from MFCC+BN features, which was the configuration previously providing ex- cellent performance in text-dependent SV task [4, 5]. 5.2. RedDots Results T able 2 shows results for more challenging RedDots database. The phrase models are still trained on relativ ely many exam- ples. As mentioned in section 4 there are about 148 examples from 9 dif ferent speakers for each pass-phrase. But the data are recorded under more challenging conditions and the UBM and i-vector extractor are trained on data of mismatched phrases. Note also that, in the case of LGC, within-class cov ariance ma- trix (i.e. Eq. (2)) was estimated on RSR2015 on data of dif ferent phrases (i.e. in a phrase independent fashion). Only the class means were estimated on RedDots data. The first section of T able 2 shows results obtained with the baseline systems, which were described in Section 2. These results are borrowed from T able 5 of [9] and are directly com- parable with our result from the second section of T able 2. The results show that the proposed i-vectors (again UBM-GMM and BN features are used) easily outperform ev en the fusion of the previously published baseline methods from [9]. W e have man- T able 2: Comparison of the i-vector bases methods with the baseline methods from [9] on RedDots data. Method No-Norm Max-Norm Classification EER [%] EER [%] Error [%] UV1 9.31 2.08 – UV2 5.54 1.11 – UV3 24.81 7.80 – UV4 16.60 4.56 – Fused (UV1 . . . UV4) 6.13 1.43 – LGC 0.11 – 0.25 Cosine 0.61 0.10 0.25 T able 3: Comparison of features, alignment methods and dif- ferent amount of training examples on RedDots. Three training i-vectors are used per speaker . The results are EERs [%] Number of Speakers Method Feature / Align 1 2 3 5 9 MFCC / GMM 61.01 7.78 3.70 2.71 1.45 LGC MFCC / HMM 9.60 1.55 1.16 1.15 0.85 MFCC+BN / GMM 39.11 1.10 0.21 0.15 0.14 MFCC / GMM 24.54 16.7 12.9 10.1 7.17 Cosine MFCC / HMM 19.19 9.58 7.18 4.87 3.02 MFCC+BN / GMM 7.53 2.00 1.35 0.95 0.55 Cosine Max-Norm MFCC / GMM 15.51 8.18 5.67 3.62 2.01 MFCC / HMM 9.79 3.51 2.36 1.16 0.50 MFCC+BN / GMM 2.52 0.35 0.30 0.20 0.10 ually inspected the utterances where the i-vector based systems made an error , and we have observed that those were most sev erely corrupted utterances (i.e. mispronunciation, only si- lence, etc). Note also the very good performance of the Cosine similarity with no normalization, which is the result for the true open-set pass-phrase verification task. From the results in T able 2, we can see that both LGC and Cosine distance perform similarly . This is understandable real- izing the close relation between the two scoring methods: LGC with identity within-class cov ariance matrix applied to length normalized i-vectors 1 would produce class likelihood propor- tional to Cosine distance. In reality , the within-class cov ariance matrix will not be far from identity as the i-vector extractor is trained to produce standard normal distributed i-v ectors. More- ov er , the Max-Norm applied to Cosine distance scores can be seen as an approximation to the softmax normalization embed- ded in equation 3. 5.3. Featur es, Alignments and Amount of T raining Data T able 3 compares results obtained with the dif ferent proposed i-vector extraction variants: UBM-GMM vs. HMM alignment, MFCC vs. MFCC+BN features. F or LGC, within-class cov ari- ance matrix was again estimated on RSR20105 data. The results show the degradation of the performance with the decreasing 1 Howe ver , note that we do not apply the length normalization in the case of LGC scoring in our experiments. number of training examples (and training speakers). Here, we use only three training examples per speakers and the columns of the table correspond to the number of speakers considered for the training. With only MFCC features, HMM alignment per- forms better than UBM-GMM in almost all cases. This is due to the HMM ability to model the temporal structure of individual phrases, which has been previously sho wn to be very effecti ve for rejecting the wrong phrase trials [4, 1]. The best perfor- mance is achiev ed with MFCC+BN with UBM-GMM align- ment. In this case, the information about the temporal structure of phrases is encoded directly in the BN features, which are e x- tracted from a considerably large context windo w (i.e. more than 300 ms). This allo ws us to obtain the superior performance ev en with the simpler UBM-GMM alignment. Again, excellent results can be obtained with MFCC+BN features and the simple Cosine similarity scoring without an y normalization, considering that this corresponds to open-set verification task. In this case, acceptable performance is achiev ed just with 3 samples from 5 speakers (still outperform- ing all the baseline systems from T able 2), which might lead to very useful and practical applications. The simplicity of the i-vector based scoring methods and the relatively lo w number of parameters that need to be esti- mated on the training data of matching pass-phrases makes our approach suitable also for the cases with very limited amount of training examples. As can be seen from the results, acceptable performance can be obtained ev en with only 2 training speakers. In the case of only single enrollment speaker , the results for LGC based scoring seems to be quite unstable as compared to Cosine distance (e.g. note the surprisingly high 39.11% EER for MFCC+BN / GMM). Our further analysis revealed that this was due to the insufficient data used for the estimation of the LGC within-class cov ariance matrix. As mentioned above, the cov ariance matrix is pre-estimated on the RSR2015 data of mis- matched pass-phrases. Estimating the cov ariance matrix on more (still mismatched) data helped alleviated this problem. 6. Conclusions In this paper , we proposed simple but effecti ve i-vector based spoken pass-phrase verification methods and e valuated them on two standard databases: RSR2015 and RedDots. Experimen- tal results have shown the effecti veness of the methods, which achiev ed almost zero error rate on both databases and signifi- cantly outperformed previously published result. The main reason for the excellent performance of these methods is the suitability of i-vectors for utterance verification. I-vector extracted from short duration utterance contains pre- dominantly information about the phonetic content of the utter - ance. Therefore, such i-vectors naturally form phrase specific cluster in the i-vector space without any need for channel com- pensation and score normalization [1, 4], which are otherwise necessary for tasks like speaker v erification. The advantages of the proposed methods are simplicity , speed, very low ov erhead and excellent performance. Another interesting property is suitability of these methods for low re- source scenarios, which is allo wed by their good performance with little amount of training data. Although the proposed methods have achiev ed near zero error rate on both databases, we can hardly say that the pass- phrase verification is a solved problem. Much larger databases with plenty of phrases will be necessary to reliably ev aluate the verification methods and also to analyze the possible per- formance degradations due to the phrase similarity . This is an open topic for future works. 7. Acknowledgment The w ork was supported by Czech Ministry of Education, Y outh and Sports from Project No. CZ.02.2.69/0.0/0.0/16 027/0008371 and the National Pro- gramme of Sustainability (NPU II) project ”IT4Innov ations excellence in science - LQ1602” and also partially supported by Sharif DeepMine Ltd. company in Iran. 8. References [1] Hossein Zeinali, Hossein Sameti, and Lukas Burget, “HMM-based phrase-independent i-v ector extractor for text-dependent speaker verification, ” IEEE/A CM T r ans- actions on Audio, Speech, and Language Pr ocessing , vol. 25, no. 7, pp. 1421–1435, 2017. [2] Hossein Zeinali, Hossein Sameti, Lukas Burget, Jan Cer- nocky , Nooshin Maghsoodi, and P av el Matejka, “i- vector/HMM based text-dependent speaker verification system for RedDots challenge, ” in InterSpeech , 2016, pp. 440–444. [3] Hossein Zeinali, Elaheh Kalantari, Hossein Sameti, and Hossein Hadian, “T elephony text-prompted speaker ver- ification using i-vector representation, ” in Acoustics, Speech and Signal Processing (ICASSP), IEEE Interna- tional Confer ence on , 2015, pp. 4839–4843. [4] Hossein Zeinali, Lukas Burget, Hossein Sameti, Ondrej Glembek, and Oldrich Plchot, “Deep neural networks and hidden Markov models in i-vector-based text-dependent speaker verification, ” in Odysse y-The Speaker and Lan- guage Reco gnition W orkshop , 2016, pp. 24–30. [5] Hossein Zeinali, Hossein Sameti, Luk ´ a ˇ s Burget, and Jan ˇ Cernock ` y, “T ext-dependent speaker verification based on i-vectors, deep neural networks and hidden Markov mod- els, ” Computer Speech & Language , vol. 46, pp. 53–71, 2017. [6] T omi Kinnunen, Md Sahidullah, H ´ ector Delgado, Massi- miliano T odisco, Nicholas Evans, Junichi Y amagishi, and K ong Aik Lee, “The asvspoof 2017 challenge: Assessing the limits of replay spoofing attack detection, ” . [7] Zhizheng W u, Sheng Gao, Eng Siong Cling, and Haizhou Li, “ A study on replay attack and anti-spoofing for text- dependent speaker verification, ” in Asia-P acific Signal and Information Pr ocessing Association, 2014 Annual Summit and Confer ence (APSIP A) . IEEE, 2014, pp. 1–5. [8] Haisheng Dai, Xiaoyan Zhu, Y upin Luo, and Shiyuan Y ang, An Utterance V erification Algorithm in Ke ywor d Spotting System , pp. 555–561, Springer Berlin Heidel- berg, Berlin, Heidelber g, 2005. [9] T omi Kinnunen, Md Sahidullah, Ivan Kukanov , H ´ ector Delgado, Massimiliano T odisco, Achintya Kumar Sarkar, Nicolai Bæk Thomsen, V ille Hautam ¨ aki, Nicholas WD Evans, and Zheng-Hua T an, “Utterance verification for text-dependent speaker recognition: A comparati ve as- sessment using the reddots corpus, ” in InterSpeech , 2016, pp. 430–434. [10] Douglas A Reynolds, Thomas F Quatieri, and Robert B Dunn, “Speaker v erification using adapted Gaussian mix- ture models, ” Digital signal pr ocessing , vol. 10, no. 1, pp. 19–41, 2000. [11] Lawrence R Rabiner and Biing-Hwang Juang, Fundamen- tals of speech r eco gnition , PTR Prentice Hall, 1993. [12] Gilles Boulianne, “Language-independent voice passphrase verification, ” in Acoustics, Speech and Signal Processing (ICASSP), 2015 IEEE International Confer ence on . IEEE, 2015, pp. 4490–4494. [13] Qian Liu, Zhang-qin Huang, Y i-bin Hou, and Rui Chen, “Utterance v erification on DTW based speech recognition using likelihood, ” in Computer Application and System Modeling (ICCASM), 2010 International Conference on . IEEE, 2010, vol. 2, pp. V2–427. [14] Daniel Pov ey , Arnab Ghoshal, Gilles Boulianne, Luk ´ a ˇ s Burget, Ond ˇ rej Glembek, K. Nagendra Goel, Mirko Han- nemann, Petr Motl ´ ı ˇ cek, Y anmin Qian, Petr Schwarz, Jan Silovsk ´ y, Georg Stemmer, and Karel V esel ´ y, “The kaldi speech recognition toolkit, ” in Pr oceedings of ASR U 2011 . 2011, pp. 1–4, IEEE Signal Processing Society . [15] Najim Dehak, Patrick Kenn y , R ´ eda Dehak, Pierre Du- mouchel, and Pierre Ouellet, “Front-end factor analysis for speaker verification, ” IEEE T r ansactions on Audio, Speech, and Language Pr ocessing , vol. 19, no. 4, pp. 788– 798, 2011. [16] David Martınez, Oldrich Plchot, Luk ´ as Burget, Ondrej Glembek, and Pa vel Matejka, “Language recognition in iv ectors space, ” InterSpeech , pp. 861–864, 2011. [17] Hossein Zeinali and Bagher BabaAli, “On the usage of i-vector representation for online handwritten signa- ture verification, ” in Document Analysis and Recognition (ICD AR), 2017 14th IAPR International Confer ence on . IEEE, 2017, vol. 1, pp. 1243–1248. [18] Mohamad Hasan Bahari, ML McLaren, D A van Leeuwen, et al., “ Age estimation from telephone speech using i- vectors, ” 2012. [19] Rui Xia and Y ang Liu, “Using i-vector space model for emotion recognition, ” in InterSpeech , 2012. [20] Alicia Lozano-Diez, Anna Silnov a, Pa vel Matejka, On- drej Glembek, Oldrich Plchot, Jan Pe ˇ s ´ an, Luk ´ a ˇ s Burget, and Joaquin Gonzalez-Rodriguez, “ Analysis and opti- mization of bottleneck features for speaker recognition, ” in Odyssey-The Speaker and Langua ge Recognition W ork- shop , 2016, pp. 21–24. [21] Y ao Tian, Meng Cai, Liang He, and Jia Liu, “In vestiga- tion of bottleneck features and multilingual deep neural networks for speaker verification, ” in InterSpeech , 2015, pp. 1151–1155. [22] Pa vel Matejka, Ondrej Glembek, Ondrej Nov otny , Oldrich Plchot, Frantisek Grezl, Lukas Burget, and Jan Cernocky , “ Analysis of DNN approaches to speaker identification, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), IEEE International Confer ence on , 2016, pp. 5100–5104. [23] Frantisek Grezl, Martin Karafi ´ at, and Lukas Burget, “In- vestigation into bottle-neck features for meeting speech recognition, ” in InterSpeech , 2009, pp. 2947–2950. [24] Sibel Y aman, Jason Pelecanos, and Ruhi Sarikaya, “Bot- tleneck features for speaker recognition, ” in Odysse y- The Speaker and Language Recognition W orkshop , 2012, vol. 12, pp. 105–108. [25] Karel V esely , Martin Karafi ´ at, Frantisek Grezl, Mar- cel Janda, and Ekaterina Egorov a, “The language- independent bottleneck features, ” in IEEE Spoken Lan- guage T echnology W orkshop (SLT) , 2012, pp. 336–341. [26] Martin Karafi ´ at, Franti ˇ sek Gr ´ ezl, Karel V esel ´ y, Mirko Hannemann, Igor Sz ˝ oke, and Jan ˇ Cernock ´ y, “BUT 2014 Babel system: Analysis of adaptation in NN based sys- tems, ” in InterSpeech , 2014, pp. 3002–3006. [27] Laurens v an der Maaten and Geof frey Hinton, “V isual- izing data using t-SNE, ” Journal of Machine Learning Resear ch , v ol. 9, no. Nov , pp. 2579–2605, 2008. [28] Anthony Larcher, Kong Aik Lee, Bin Ma, and Haizhou Li, “T ext-dependent speaker verification: Classifiers, databases and RSR2015, ” Speech Communication , vol. 60, pp. 56–77, 2014. [29] K ong Aik Lee, Anthony Larcher, Guangsen W ang, Patrick Kenn y , Niko Br ¨ ummer , David van Leeuwen, Hagai Aronowitz, Marcel Kockmann, Carlos V aquero, Bin Ma, et al., “The RedDots data collection for speaker recogni- tion, ” in InterSpeech , 2015, pp. 2996–3000. [30] V assil Panayotov , Guoguo Chen, Daniel Pove y , and San- jeev Khudanpur, “Librispeech: an ASR corpus based on public domain audio books, ” in Acoustics, Speech and Signal Pr ocessing (ICASSP), IEEE International Confer- ence on , 2015, pp. 5206–5210.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment