강화학습 기반 맞춤형 자동 플레이리스트 생성
본 논문은 음악 플레이리스트 생성을 언어 모델링 문제로 정의하고, 주의(attention) 기반 RNN 언어 모델을 사전 학습한 뒤 정책 그래디언트 강화학습으로 사용자 선호(다양성, 신선도, 최신성 등)에 맞게 보정한다. 실험 결과, 제안 방법이 기존 모델보다 낮은 퍼플렉시티와 높은 다양·신선도 지표를 달성함을 보인다.
저자: Shun-Yao Shih, Heng-Yu Chi
본 논문은 음악 스트리밍 서비스에서 요구되는 “자동·맞춤·유연”한 플레이리스트 생성 문제를 해결하기 위해, 딥러닝 기반 언어 모델과 강화학습을 결합한 새로운 프레임워크를 제안한다. 먼저, 기존 추천 시스템이 만든 사용자‑곡 이중 그래프에서 임베딩을 추출하고, 각 사용자의 시드 곡에 대해 k‑nearest neighbor 검색을 수행해 초기 베이스라인 플레이리스트를 만든다. 이 플레이리스트를 단어 시퀀스로 간주하고, 주의(attention)와 concatenation을 동시에 적용한 AC‑RNN‑LM을 사전 학습한다. 여기서 주의 메커니즘은 최근 C₍ws₎개의 히든 상태를 가중합해 컨텍스트 벡터를 만들고, 이를 원래 히든 상태와 결합해 강화된 히든 표현을 얻는다. 또한 전체 시퀀스 길이 T(=30)까지의 히든 상태를 하나의 긴 벡터 h₀에 연결(concatenation)함으로써, 각 타임스텝마다 독립적인 정보를 유지하면서도 전체 플레이리스트의 전역 정보를 반영한다. 실험 결과, AC‑RNN‑LM은 기존 RNN‑LM, 주의‑만 적용 모델, concatenation‑만 적용 모델보다 빠르게 수렴하고 최종 로그‑퍼플렉시티가 가장 낮아, 곡 시퀀스 예측 정확도가 우수함을 확인했다.
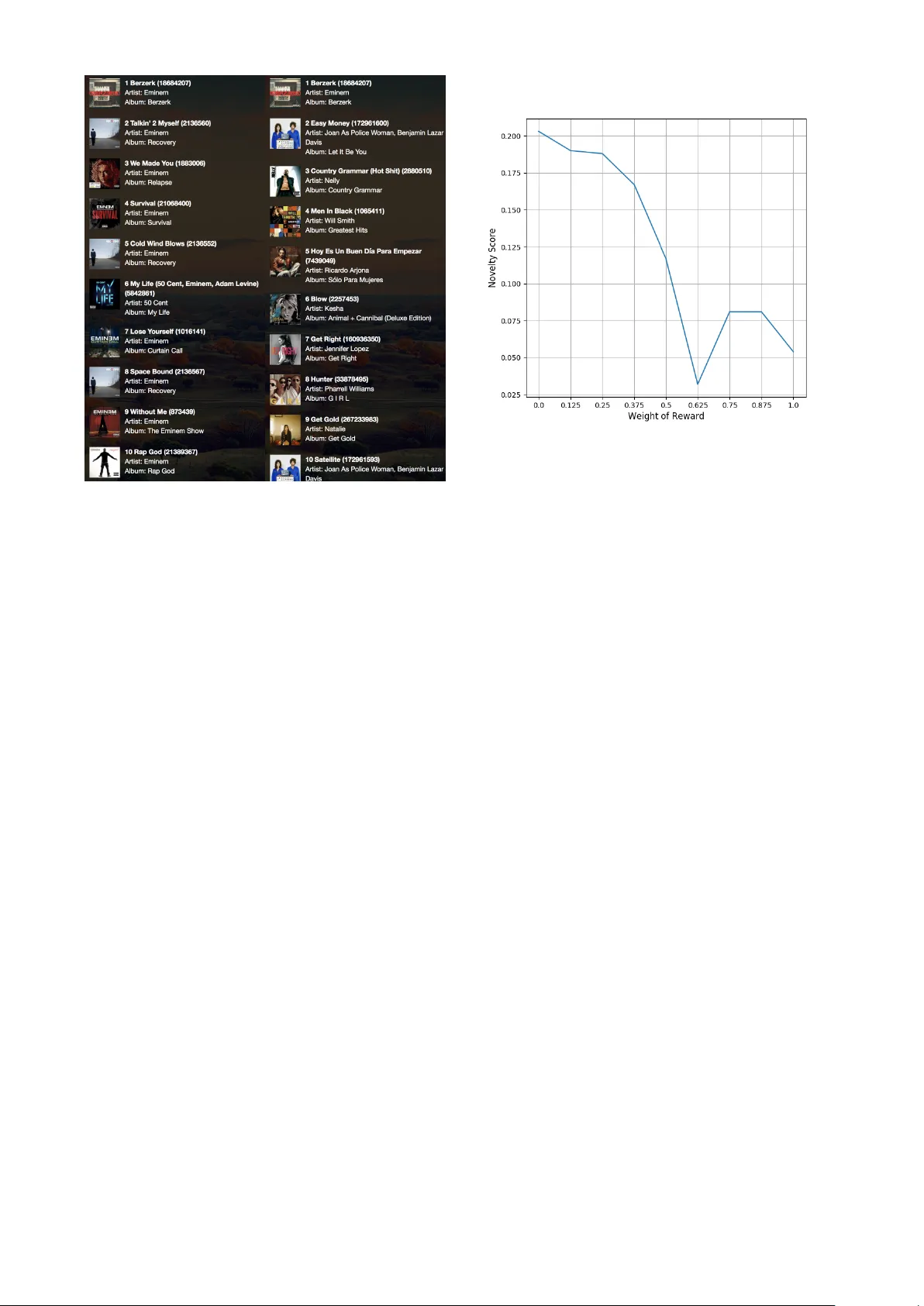
다음 단계에서는 정책 그래디언트 강화학습을 적용한다. 행동 a는 다음에 추천될 곡의 ID이며, 상태 s는 현재까지 선택된 곡들의 순서이다. 정책 πθ(s,a)는 사전 학습된 AC‑RNN‑LM 파라미터 θ에 의해 정의된다. 보상 함수는 네 가지 핵심 목표를 선형 결합한 형태로 설계되었다. 첫 번째 보상 R₁은 다양성을 촉진하기 위해 현재 마지막 곡과 후보 곡 임베딩 사이의 유클리드 거리를 목표 거리 C_distance와 비교해 로그‑스케일로 변환한다. 두 번째 보상 R₂는 신선도·신규성을 반영하는데, 시간 가중치 w(t)와 곡 재생 횟수 pₜ(a)를 이용해 재생 횟수가 적은 곡에 높은 보상을 부여한다. 세 번째 보상 R₃는 발매 연도를 이용해 최신곡(또는 구곡) 선호를 조정한다. 네 번째 보상 R₄는 사전 학습된 언어 모델이 제공하는 로그 확률을 그대로 보상에 포함시켜, 문맥적 일관성을 유지한다. 보상 가중치 γ₁~γ₄는 실험 설정에 따라 조정되며, 논문에서는 다양성 전용(RL‑DIST), 신선도 전용(RL‑NOVELTY), 연도 전용(RL‑YEAR), 그리고 복합 목표(RL‑COMBINE) 네 가지 시나리오를 제시한다. 강화학습 단계에서는 Adam 옵티마이저와 학습률 1e‑4를 사용해 정책 파라미터를 미세 조정한다.
실험은 KKBOX에서 제공한 10,000개의 30곡 플레이리스트(총 45,243곡) 데이터를 사용했다. 평가 지표는 (1) 퍼플렉시티(시퀀스 예측 정확도), (2) Distinct‑1 기반 다양성, (3) 로그‑스케일 신선도(재생 횟수 기반), (4) 평균 발매 연도(신선도)이다. 결과는 AC‑RNN‑LM이 사전 학습 단계에서 가장 낮은 퍼플렉시티를 기록했으며, 강화학습 후에는 설정된 γ에 따라 다양성·신선도·연도 지표가 목표대로 조정되는 것을 보여준다. 특히 복합 목표(RL‑COMBINE)에서는 모든 지표에서 균형 잡힌 성능을 달성해, 하나의 모델로 다중 비즈니스 목표를 동시에 만족시킬 수 있음을 입증한다.
논문의 주요 기여는 다음과 같다. 첫째, 플레이리스트를 언어 모델링 시퀀스로 변환해 딥러닝 기반 시퀀스 예측에 적용함으로써 기존 통계 기반 방법의 한계를 극복했다. 둘째, 주의와 concatenation을 결합한 AC‑RNN‑LM 구조가 기존 RNN‑LM보다 빠른 수렴과 낮은 퍼플렉시티를 달성함을 실험적으로 증명했다. 셋째, 정책 그래디언트를 이용해 사용자 정의 보상 함수를 손쉽게 삽입함으로써 실시간 맞춤형 플레이리스트를 생성할 수 있는 유연성을 제공했다. 넷째, 보상 함수가 모듈식으로 설계돼 새로운 비즈니스 목표(예: 분위기, 에너지 레벨 등)를 추가하기 용이하다는 실용적 장점을 강조한다.
이와 같이 본 연구는 딥러닝과 강화학습을 융합해 자동·맞춤·유연한 음악 플레이리스트 생성 시스템을 구현했으며, 실제 대규모 스트리밍 서비스에 적용 가능한 실증적 근거를 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기