Automatic, Personalized, and Flexible Playlist Generation using Reinforcement Learning
Songs can be well arranged by professional music curators to form a riveting playlist that creates engaging listening experiences. However, it is time-consuming for curators to timely rearrange these playlists for fitting trends in future. By exploit…
Authors: Shun-Yao Shih, Heng-Yu Chi
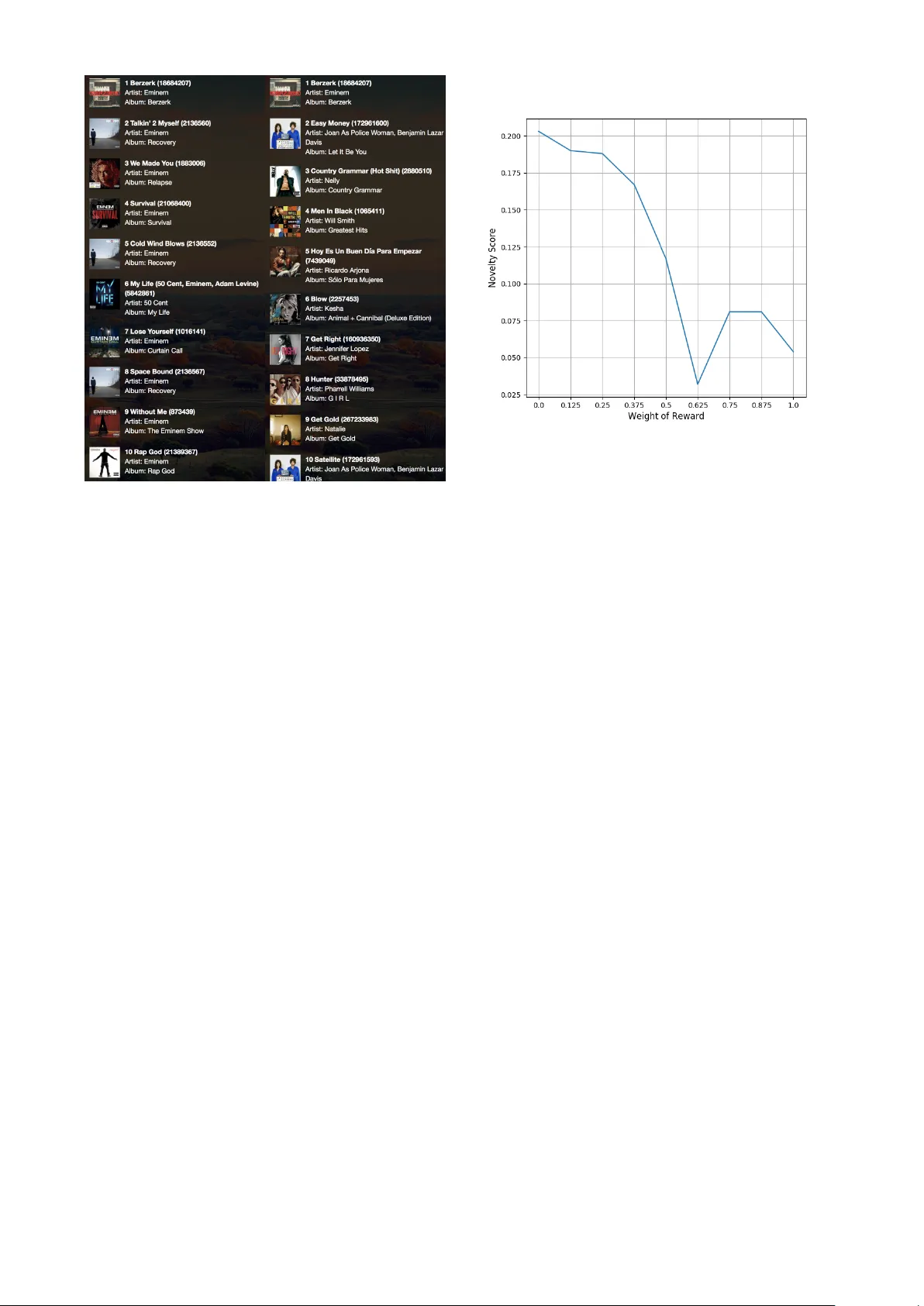
A UT OMA TIC, PERSON ALIZED, AND FLEXIBLE PLA YLIST GENERA TION USING REINFORCEMENT LEARNING Shun-Y ao Shih National T aiwan Uni v ersity shunyaoshih@gmail.com Heng-Y u Chi KKBO X Inc., T aipei, T aiwan henrychi@kkbox.com ABSTRA CT Songs can be well arranged by professional music curators to form a riv eting playlist that creates engaging listening experiences. Howe ver , it is time-consuming for curators to timely rearrange these playlists for fitting trends in fu- ture. By exploiting the techniques of deep learning and reinforcement learning, in this paper , we consider music playlist generation as a language modeling problem and solve it by the proposed attention language model with policy gradient. W e de velop a systematic and interactiv e approach so that the resulting playlists can be tuned flex- ibly according to user preferences. Considering a playlist as a sequence of words, we first train our attention RNN language model on baseline recommended playlists. By optimizing suitable imposed reward functions, the model is thus refined for corresponding preferences. The ex- perimental results demonstrate that our approach not only generates coherent playlists automatically but is also able to flexibly recommend personalized playlists for di versity , nov elty and freshness. 1. INTRODUCTION Professional music curators or DJs are usually able to care- fully select, order , and form a list of songs which can gi ve listeners brilliant listening experiences. For a music radio with a specific topic, they can collect songs related to the topic and sort in a smooth context. By considering pref- erences of users, curators can also find what they like and recommend them se veral lists of songs. Ho we ver , dif ferent people hav e different preferences tow ard div ersity , popu- larity , and etc. Therefore, it will be great if we can refine playlists based on dif ferent preferences of users on the fly . Besides, as online music streaming services grow , there are more and more demands for ef ficient and ef fecti v e mu- sic playlist recommendation. Automatic and personalized music playlist generation thus becomes a critical issue. Howe ver , it is unfeasible and expensi ve for editors to daily or hourly generate suitable playlists for all users based on their preferences about trends, novelty , diversity , c Shun-Y ao Shih, Heng-Y u Chi. Licensed under a Cre- ativ e Commons Attribution 4.0 International License (CC BY 4.0). At- tribution: Shun-Y ao Shih, Heng-Y u Chi. “automatic, personalized, and flexible playlist generation using reinforcement learning”, 19th Interna- tional Society for Music Information Retrie v al Conference, Paris, France, 2018. etc. Therefore, most of previous works try to deal with such problems by considering some particular assump- tions. McFee et al. [14] consider playlist generation as a language modeling problem and solv e it by adopting statis- tical techniques. Unfortunately , statistical method does not perform well on small datasets. Pampalk et al. [16] gen- erate playlists by exploiting explicit user behaviors such as skipping. Howe ver , for implicit user preferences on playlists, they do not provide a systematic way to handle it. As a result, for generating personalized playlists auto- matically and flexibly , we dev elop a novel and scalable music playlist generation system. The system consists of three main steps. First, we adopt Chen et al. ’ s work [4] to generate baseline playlists based on the preferences of users about songs. In details, given the relationship be- tween users and songs, we construct a corresponding bipar- tite graph at first. W ith the users and songs graph, we can calculate embedding features of songs and thus obtain the baseline playlist for each songs by finding their k-nearest neighbors. Second, by formulating baseline playlists as sequences of words, we can pretrain RNN language model (RNN-LM) to obtain better initial parameters for the fol- lowing optimization, using policy gradient reinforcement learning. W e adopt RNN-LM because not only RNN-LM has better ability of learning information progresses than traditional statistical methods in many generation tasks, but also neural networks can be combined with reinforce- ment learning to achieve better performances [10]. Finally , giv en preferences from user profiles and the pretrained pa- rameters, we can generate personalized playlists by ex- ploiting techniques of policy gradient reinforcement learn- ing with corresponding re ward functions. Combining these training steps, the experimental results show that we can generate personalized playlists to satisfy different prefer- ences of users with ease. Our contributions are summarized as follo ws: • W e design an automatic playlist generation frame- work, which is able to provide timely recommended playlists for online music streaming services. • W e remodel music playlist generation into a se- quence prediction problem using RNN-LM which is easily combined with policy gradient reinforcement learning method. • The proposed method can flexibly generate suitable personalized playlists according to user profiles us- ing corresponding optimization goals in policy gra- dient. The rest of this paper is organized as follo ws. In Sec- tion 2, we introduce sev eral related works about playlist generation and recommendation. In Section 3, we provide essential prior knowledge of our work related to policy gra- dient. In Section 4, we introduce the details of our pro- posed model, attention RNN-LM with concatenation (A C- RNN-LM). In Section 5, we show the effecti v eness of our method and conclude our work in Section 6. 2. RELA TED WORK Giv en a list of songs, previous works try to rearrange them for better song sequences [1, 3, 5, 12]. First, they construct a song graph by considering songs in playlist as vertices, and relev ance of audio features between songs as edges. Then they find a Hamiltonian path with some properties, such as smooth transitions of songs [3], to create new sequencing of songs. User feedback is also an important considera- tion when we want to generate playlists [6, 7, 13, 16]. By considering sev eral properties, such as tempo, loudness, topics, and artists, of users’ fa v orite played songs recently , authors of [6, 7] can thus provide personalized playlist for users based on favorite properties of users. Pampalk et al. [16] consider skip behaviors as negati v e signals and the proposed approach can automatically choose the next song according to audio features and avoid skipped songs at the same time. Maillet et al. [13] provides a more in- teractiv e way to users. Users can manipulate weights of tags to express high-level music characteristics and obtain corresponding playlists they want. T o better integrate user behavior into playlist generation, several works are pro- posed to combine playlist generation algorithms with the techniques of reinforcement learning [11, 19]. Xing et al. first introduce e xploration into traditional collaborativ e fil- tering to learn preferences of users. Liebman et al. take the formulation of Markov Decision Process into playlist generation framework to design algorithms that learn rep- resentations for preferences of users based on hand-crafted features. By using these representations, they can generate personalized playlist for users. Beyond playlist generation, there are se v eral works adopting the concept of playlist generation to facilitate recommendation systems. Giv en a set of songs, V argas et al. [18] propose sev eral scoring functions, such as di v er- sity and novelty , and retrieve the top-K songs with higher scores for each user as the resulting recommended list of songs. Chen et al. [4] propose a query-based music rec- ommendation system that allow users to select a preferred song as a seed song to obtain related songs as a recom- mended playlist. 3. POLICY GRADIENT REINFORCEMENT LEARNING Reinforcement learning has got a lot of attentions from public since Silv er et al. [17] proposed a general reinforce- ment learning algorithm that could make an agent achieve superhuman performance in many games. Besides, rein- forcement learning has been successfully applied to many other problems such as dialogue generation modeled as Markov Decision Process (MDP). A Markov Decision Process is usually denoted by a tu- ple ( S , A , P , R , γ ) , where • S is a set of states • A is a set of actions • P ( s, a, s 0 ) = Pr[ s 0 | s, a ] is the transition probability that action a in state s will lead to state s 0 • R ( s, a ) = E [ r | s, a ] is the expected rew ard that an agent will receiv e when the agent does action a in state s . • γ ∈ [0 , 1] is the discount factor representing the im- portance of future rew ards Policy gradient is a reinforcement learning algorithm to solve MDP problems. Modeling an agent with parameters θ , the goal of this algorithm is to find the best θ of a pol- icy π θ ( s, a ) = Pr[ a | s, θ ] measured by av erage rew ard per time-step J ( θ ) = X s ∈S d π θ ( s ) X a ∈A π θ ( s, a ) R ( s, a ) (1) where d π θ ( s ) is stationary distribution of Mark ov chain for π θ . Usually , we assume that π θ ( s, a ) is differentiable with respect to its parameters θ , i.e., ∂ π θ ( s,a ) ∂ θ exists, and solve this optimization problem Eqn (1) by gradient ascent. For - mally , given a small enough α , we up date its parameters θ by θ ← θ + α ∇ θ J ( θ ) (2) where ∇ θ J ( θ ) = X s ∈S d π θ ( s ) X a ∈A π θ ( s, a ) ∇ θ π θ ( s, a ) R ( s, a ) = E [ ∇ θ π θ ( s, a ) R ( s, a )] (3) 4. THE PROPOSED MODEL The proposed model consists of two main components. W e first introduce the structure of the proposed RNN-based model in Section 4.1. Then in Section 4.2, we formulate the problem as a Markov Decison Process and solve the formulated problem by policy gradient to generate refined playlists. 4.1 Attention RNN Language Model Giv en a sequence of tokens { w 1 , w 2 , . . . , w t } , an RNN- LM estimates the probability Pr[ w t | w 1: t − 1 ] with a recur- rent function h t = f ( h t − 1 , w t − 1 ) (4) and an output function, usually softmax, Pr[ w t = v i | w 1: t − 1 ] = exp( W > v i h t + b v i ) P k exp( W > v k h t + b v k ) (5) Figure 1 . The structure of our attention RNN language model with concatenation where the implementation of the function f depends on which kind of RNN cell we use, h t ∈ R D , W ∈ R D × V with the column vector W v i corresponding to a word v i , and b ∈ R V with the scalar b v i corresponding to a word v i ( D is the number of units in RNN, and V is the number of unique tokens in all sequences). W e then update the parameters of the RNN-LM by maximizing the log-likelihood on a set of sequences with size N , { s 1 , s 2 , . . . , s N } , and the corresponding tokens, { w s i 1 , w s i 2 , . . . , w s i | s i | } . L = 1 N N X n =1 | s n | X t =2 log Pr[ w s n t | w s n 1: t − 1 ] (6) 4.1.1 Attention in RNN-LM Attention mechanism in sequence-to-sequence model has been proven to be ef fectiv e in the fields of image caption generation, machine translation, dialogue generation, and etc. Sev eral previous works also indicate that attention is ev en more impressi v e on RNN-LM [15]. In attention RNN language model (A-RNN-LM), gi v en the hidden states from time t − C ws to t , denoted as h t − C ws : t , where C ws is the attention window size, we want to compute a context vector c t as a weighted sum of hid- den states h t − C ws : t − 1 and then encode the context vector c t into the original hidden state h t . β i = ν > tanh( W 1 h t + W 2 h t − C ws + i ) (7) α i = exp( β i ) P C ws − 1 k =0 exp( β k ) (8) c t = C ws − 1 X i =0 α i h t − C ws + i (9) h 0 t = W 3 h t c t (10) where β is Bahdanau’ s scoring style [2], W 1 , W 2 ∈ R D × D , and W 3 ∈ R D × 2 D . 4.1.2 Our Attention RNN-LM with concatenation In our work, { s 1 , s 2 , . . . , s N } and { w s i 1 , w s i 2 , . . . , w s i | s i | } are playlists and songs by adopting Chen et al. ’ s work [4]. More specifically , given a seed song w s i 1 for a playlist s i , we find top-k approximate nearest neighbors of w s i 1 to for - mulate a list of songs { w s i 1 , w s i 2 , . . . , w s i | s i | } . The proposed attention RNN-LM with concatenation (A C-RNN-LM) is shown in Figure 1. W e pad w 1: t − 1 to w 1: T and concatenate the corresponding h 0 1: T as the input of our RNN-LM’ s output function in Eqn (5), where T is the maximum number of songs we consider in one playlist. Therefore, our output function becomes Pr[ w t = v i | w 1: t − 1 ] = exp( W > v i h 0 + b v i ) P k exp( W > v k h 0 + b v k ) (11) where W ∈ R DT × V , b ∈ R V and h 0 = h 0 1 h 0 2 . . . h 0 T ∈ R DT × 1 (12) 4.2 Policy Gradient W e exploit policy gradient in order to optimize Eqn (1), which is formulated as follows. 4.2.1 Action An action a is a song id, which is a unique representation of each song, that the model is about to generate. The set of actions in our problem is finite since we would like to recommend limited range of songs. 4.2.2 State A state s is the songs we hav e already recommended in- cluding the seed song, { w s i 1 , w s i 2 , . . . , w s i t − 1 } . 4.2.3 P olicy A policy π θ ( s, a ) takes the form of our AC-RNN-LM and is defined by its parameters θ . 4.2.4 Rewar d Rew ard R ( s, a ) is a weighted sum of sev eral re ward func- tions, i.e., R i : s × a 7→ R . In the following introductions, we formulate 4 important metrics for playlists generation. The policy of our pretrained A C-RNN-LM is denoted as π θ RN N ( s, a ) with parameters θ RN N , and the policy of our A C-RNN-LM optimized by policy gradient is denoted as π θ RL ( s, a ) with parameters θ RL . Diversity represents the v ariety in a recommended list of songs. Several generated playlists in Chen et al. ’ s work [4] are composed of songs with the same artist or album. It is not regarded as a good playlist for recommendation system because of low div ersity . Therefore, we formulate the measurement of the di- versity by the euclidean distance between the em- beddings of the last song in the existing playlist, w s | s | , and the predicted song, a . R 1 ( s, a ) = − log ( | d ( w s | s | , a ) − C distance | ) (13) where d ( · ) is the euclidean distance between the em- beddings of w s | s | and a , and C distance is a parameter that represents the euclidean distance that we want the model to learn. Novelty is also important for a playlist generation sys- tem. W e would like to recommend something new to users instead of recommend something familiar . Unlike previous works, our model can easily gener- ate playlists with novelt y by applying a correspond- ing re ward function. As a result, we model rew ard of nov elty as a weighted sum of normalized playcounts in periods of time [20]. R 2 ( s, a ) = − log ( X t w ( t ) log( p t ( a )) log(max a 0 ∈ A p t ( a 0 )) ) (14) where w ( t ) is the weight of a time period, t , with a constraint P t w ( t ) = 1 , p t ( a ) is playcounts of the song a , and A is the set of actions. Note that songs with less playcounts hav e higher value of R 2 , and vice versa. Freshness is a subjective metric for personalized playlist generation. For example, latest songs is usually more interesting for young people, while older peo- ple would prefer old-school songs. Here, we arbi- trarily choose one direction for optimization to the agent π θ RL to show the feasibility of our approach. R 3 ( s, a ) = − log ( Y a − 1900 2017 − 1900 ) (15) where Y a is the release year of the song a . Coherence is the major feature we should consider to av oid situations that the generated playlists are highly rewarded but lack of cohesive listening ex- periences. W e therefore consider the policy of our pretrained language model, π θ RN N ( s, a ) , which is well-trained on coherent playlists, as a good enough generator of coherent playlists. R 4 ( s, a ) = log(Pr[ a | s, θ RN N ]) (16) Combining the abov e rew ard functions, our final re ward for the action a is R ( s, a ) = γ 1 R 1 ( s, a ) + γ 2 R 2 ( s, a )+ γ 3 R 3 ( s, a ) + γ 4 R 4 ( s, a ) (17) where the selection of γ 1 , γ 2 , γ 3 , and γ 4 depends on dif- ferent applications. Note that although we only list four reward functions here, the optimization goal R can be easily extended by a linear combination of more rew ard functions. 5. EXPERIMENTS AND ANAL YSIS In the follo wing e xperiments, we first introduce the details of dataset and ev aluation metrics in Section 5.1 and train- ing details in Section 5.2. In Section 5.3, we compare pre- trained RNN-LMs with different mechanism combination by perplexity to show our proposed AC-RNN-LM is more effecti vely and efficiently than others. In order to demon- strate the effecti veness of our proposed method, A C-RNN- LM combined with reinforcement learning, we adopt three standard metrics, di versity , nov elty , and freshness (cf. Sec- tion 5.1) to validate our models in Section 5.4. More- ov er , we demonstrate that it is effortless to flexibly ma- nipulate the properties of resulting generated playlists in Section 5.5. Finally , in Section 5.6, we discuss the details about the design of rew ard functions with giv en preferred properties. 5.1 Dataset and Evaluation Metrics The playlist dataset is provided by KKBOX Inc., which is a re gional leading music streaming compan y . It consists of 10 , 000 playlists, each of which is composed of 30 songs. There are 45 , 243 unique songs in total. For v alidate our proposed approach, we use the metrics as follows. Per plexity is calculated based on the song probability dis- tributions, which is sho wn as follo ws. per plexity = e 1 N P N n =1 P x − q ( x ) log p ( x ) where N is the number of training samples, x is a song in our song pool, p is the predicted song prob- ability distrib ution, and q is the song probability dis- tribution in ground truth. Diversity is computed as different unigrams of artists scaled by he total length of each playlist, which is measured by Distinct-1 [9] Figure 2 . Log-perplexity of different pretrained models on the dataset under different training steps Novelty is designed for recommending something new to users [20]. The more the novelty is, the lower the metric is. Freshness is directly measured by the average release year of songs in each playlist. 5.2 T raining Details In the pretraining and reinforcement learning stage, we use 4 layers and 64 units per layer in all RNN-LM with LSTM units, and we choose T = 30 for all RNN-LM with padding and concatenation. The optimizer we use is Adam [8]. The learning rates for pretraining stage and re- inforcement learning stage are empirically set as 0.001 and 0.0001, respectiv ely . 5.3 Pretrained Model Comparison In this section, we compare the training error of RNN-LM combining with dif ferent mechanisms. The RNN-LM with attention is denoted as A-RNN-LM, the RNN-LM with concatenation is denoted as C-RNN-LM, and the RNN- LM with attention and concatenation is denoted as A C- RNN-LM. Figure 2 reports the training error of different RNN-LMs as log-perplexity which is equal to negati v e log- likelihood under the training step from 1 to 500 , 000 . Here one training step means that we update our parameters by one batch. As shown in Figure 2, the training error of our proposed model, A C-RNN-LM, can not only decrease faster than the other models b ut also reach the lo west v alue at the end of training. Therefore, we adopt AC-RNN-LM as our pretrained model. W orth noting that the pretrained model is de veloped for two purposes. One is to provide a good basis for fur- ther optimization, and the other is to estimate transition T able 1 . W eights of reward functions for each model Model γ 1 γ 2 γ 3 γ 4 RL-DIST 0.5 0.0 0.0 0.5 RL-NO VEL TY 0.0 0.5 0.0 0.5 RL-YEAR 0.0 0.0 0.5 0.5 RL-COMBINE 0.2 0.2 0.2 0.4 T able 2 . Comparison on different metrics for playlist gen- eration system (The bold text represents the best, and the underline text represents the second) Model Div ersity No velty Freshness Embedding [4] 0.32 0.19 2007.97 A C-RNN-LM 0.39 0.20 2008.41 RL-DIST 0.44 0.20 2008.37 RL-NO VEL TY 0.42 0.05 2012.89 RL-YEAR 0.40 0.19 2006.23 RL-COMBINE 0.49 0.18 2007.64 probabilities of songs in the rew ard function. Therefore, we simply select the model with the lowest training er- ror to be optimized by policy gradient and an estimator of Pr[ a | s, θ RN N ] (cf. Eqn (16)). 5.4 Playlist Generation Results As shown in T able 2, to ev aluate our method, we compare 6 models on 3 important features, div ersity , novelty , and freshness (cf. Section 5.1), of playlist generation system. The details of models are described as follows. Embed- ding represents the model of Chen et al. ’ s work [4]. Chen et al. construct the song embedding by relationships be- tween user and song and then finds approximate k nearest neighbors for each song. RL-DIST , RL-NO VEL TY , RL- YEAR, and RL-COMBINE are models that are pretrained and optimized by the policy gradient method (cf. Eqn (17)) with different weights, respecti vely , as shown in T able 1. The experimental results show that for single objec- tiv e such as div ersity , our models can accurately gener- ate playlists with corresponding property . For example, RL-Y ear can generate a playlist which consists of songs with earliest release years than Embedding and AC-RNN- LM. Besides, ev en when we impose our model with mul- tiple re w ard functions, we can still obtain a better resulting playlist in comparison with Embedding and A C-RNN-LM. Sample result is shown in Figure 3. From T able 2, we demonstrate that by using appropriate rew ard functions, our approach can generate playlists to fit the corresponding needs easily . W e can systematically find more songs from dif ferent artists (RL-DIST), more songs heard by fewer people (RL-NO VEL TY), or more old songs for some particular groups of users (RL-YEAR). 5.5 Flexible Manipulating Playlist Properties After showing that our approach can easily fit sev eral needs, we further inv estigate the influence of γ to the re- Figure 3 . Sample playlists generated by our approach. The left one is generated by Embedding [4] and the right one is generated by RL-COMBINE. sulting playlists. In this section, se veral models are trained with the weight γ 2 from 0 . 0 to 1 . 0 to show the vari- ances in nov elty of the resulting playlists. Here we keep γ 2 + γ 4 = 1 . 0 and γ 1 = γ 3 = 0 and fix the training steps to 10 , 000 . As shown in Figure 4, novelty score generally decreases when γ 2 increases from 0 . 0 to 1 . 0 but it is also possible that the model may sometimes find the optimal policy ear - lier than expectation such as the one with γ 2 = 0 . 625 . Nev ertheless, in general, our approach can not only let the model generate more nov el songs b ut also make the e xtent of novelty be controllable. Besides automation, this kind of flexibility is also important in applications. T ake online music streaming service as an example, when the service provider wants to recommend playlists to a user who usually listens to non-mainstream but fa- miliar songs (i.e., novelty score is 0 . 4 ), it is more suitable to generate playlists which consists of songs with novelty scores equals to 0 . 4 instead of generating playlists which is composed of 60% songs with novelty scores equals to 0 . 0 and 40% songs with nov elty scores equals to 1 . 0 . Since users usually hav e dif ferent kinds of preferences on each property , to automatically generate playlists fitting needs of each user , such as novelty , becomes indispensable. The experimental results v erify that our proposed approach can satisfy the abov e application. 5.6 Limitation on Reward Function Design When we try to define a rew ard function R i for a prop- erty , we should carefully av oid the bias from the state s . In other words, rew ard functions should be specific to the corresponding feature we want. One common issue is that Figure 4 . Novelty score of playlists generated by dif ferent imposing weights the reward function may be influenced by the number of songs in state s . For example, in our experiments, we adopt Distinct-1 as the metric for diversity . Howe ver , we cannot also adopt Distinct-1 as our rew ard function directly be- cause it is scaled by the length of playlists which results in all actions from states with fewer songs will be bene- fited. Therefore, difference between cR 1 and Distinct-1 is the reason that RL-DIST does not achieve the best perfor- mance in Distinct-1 (cf. T able 1). In summary , we should be careful to design rew ard functions, and sometimes we may need to formulate another approximation objecti ve function to av oid biases. 6. CONCLUSIONS AND FUTURE WORK In this paper , we develop a playlist generation system which is able to generate personalized playlists automat- ically and flexibly . W e first formulate playlist generation as a language modeling problem. Then by exploiting the techniques of RNN-LM and reinforcement learning, the proposed approach can flexibly generate suitable playlists for different preferences of users. In our future work, we will further inv estigate the pos- sibility to automatically generate playlists by considering qualitativ e feedback. For online music streaming service providers, professional music curators will gi v e qualitati v e feedback on generated playlists so that research de velop- ers can improve the quality of playlist generation system. Qualitativ e feedback such as ‘songs from div erse artists but similar genres’ is easier to be quantitativ e. W e can de- sign suitable reward functions and generate corresponding playlists by our approach. Ho we v er , other feedback such as ‘falling in love playlist’ is more difficult to be quantita- tiv e. Therefore, we will further adopt audio features and explicit tags of songs in order to provide a better playlist generation system. 7. REFERENCES [1] Masoud Alghoniemy and Ahmed H. T ewfik. A net- work flow model for playlist generation. In Pr oceed- ings of International Conference on Multimedia and Expo , pages 329–332, 2001. [2] Dzmitry Bahdanau, K yunghyun Cho, and Y oshua Ben- gio. Neural machine translation by jointly learning to align and translate. In International Confer ence on Learning Repr esentations , 2015. [3] Rachel M. Bittner , Minwei Gu, Gandalf Hernandez, Eric J. Humphrey , Tristan Jehan, P . Hunter McCurry , and Nicola Montecchio. Automatic playlist sequenc- ing and transitions. In Pr oceedings of the 18th Inter- national Confer ence on Music Information Retrieval , pages 472–478, 2017. [4] Chih-Ming Chen, Ming-Feng Tsai, Y u-Ching Lin, and Y i-Hsuan Y ang. Query-based music recommendations via preference embedding. In Pr oceedings of the ACM Confer ence Series on Recommender Systems , pages 79–82, 2016. [5] Arthur Flexer , Dominik Schnitzer , Martin Gasser, and Gerhard W idmer . Playlist generation using start and end songs. In Pr oceedings of the 9th International Society for Music Information Retrieval Confer ence , pages 173–178, 2008. [6] Negar Hariri, Bamshad Mobasher, and Robin Burke. Context-a ware music recommendation based on latent- topic sequential patterns. In Pr oceedings of the Sixth A CM Confer ence on Recommender Systems , RecSys ’12, pages 131–138, Ne w Y ork, NY , USA, 2012. A CM. [7] Dietmar Jannach, Lukas Lerche, and Iman Kamehkhosh. Be yond ”hitting the hits”: Gener- ating coherent music playlist continuations with the right tracks. In Proceedings of the 9th A CM Confer- ence on Recommender Systems , RecSys ’15, pages 187–194, New Y ork, NY , USA, 2015. A CM. [8] Diederik P . Kingma and Jimmy Ba. Adam: A method for stochastic optimization. CoRR , abs/1412.6980, 2014. [9] Jiwei Li, Michel Galley , Chris Brockett, Jianfeng Gao, and Bill Dolan. A div ersity-promoting objec- tiv e function for neural conv ersation models. CoRR , abs/1510.03055, 2015. [10] Jiwei Li, Will Monroe, Alan Ritter, Michel Gal- ley , Jianfeng Gao, and Dan Jurafsky . Deep rein- forcement learning for dialogue generation. CoRR , abs/1606.01541, 2016. [11] Elad Liebman and Peter Stone. DJ-MC: A reinforcement-learning agent for music playlist recommendation. CoRR , abs/1401.1880, 2014. [12] Beth Logan. Content-based playlist generation: Ex- ploratory experiments. 2002. [13] Franc ¸ ois Maillet, Douglas Eck, Guillaume Desjardins, and Paul Lamere. Steerable playlist generation by learning song similarity from radio station playlists. In Pr oceedings of the 10th International Society for Mu- sic Information Retrieval Confer ence , 2009. [14] Brian McFee and Gert Lanckriet. The natural language of playlists. In Pr oceedings of the 12th International Society for Music Information Retrieval Confer ence , pages 537–542, 2011. [15] Hongyuan Mei, Mohit Bansal, and Matthe w R. W alter . Coherent dialogue with attention-based language mod- els. In The Thirty-F irst AAAI Conference on Artificial Intelligence , 2016. [16] Elias Pampalk, Tim Pohle, and Gerhard W idmer . Dy- namic playlist generation based on skipping behavior . In Pr oceedings of the 6th International Society for Mu- sic Information Retrieval Conference , pages 634–637, 2005. [17] David Silver , Thomas Hubert, Julian Schrittwieser , Ioannis Antonoglou, Matthew Lai, Arthur Guez, Marc Lanctot, Laurent Sifre, Dharshan Kumaran, Thore Graepel, T imothy Lillicrap, Karen Simonyan, and Demis Hassabis. Mastering chess and shogi by self- play with a general reinforcement learning algorithm. 2017. [18] Sa ´ ul V argas. New approaches to div ersity and novelty in recommender systems. In Pr oceedings of the F ourth BCS-IRSG Confer ence on Futur e Dir ections in Infor- mation Access , FDIA ’11, pages 8–13, Swindon, UK, 2011. BCS Learning & Dev elopment Ltd. [19] Zhe Xing, Xinxi W ang, , and Y e W ang. Enhancing col- laborativ e filtering music recommendation by balanc- ing exploration and e xploitation. In Pr oceedings of the 15th International Society for Music Information Re- trieval Confer ence , pages 445–450, 2014. [20] Y uan Cao Zhang, Diarmuid ´ O S ´ eaghdha, Daniele Quercia, and T amas Jambor . Auralist: Introducing serendipity into music recommendation. In Pr oceed- ings of the F ifth A CM International Conference on W eb Sear c h and Data Mining , WSDM ’12, pages 13–22, New Y ork, NY , USA, 2012. A CM.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment