연결·자동차 에너지·배출 효율 평가를 위한 실거리 데이터 기반 프레임워크
** 본 논문은 자연주의 주행 데이터와 평가 대상 차량의 실시간 연료·배출 데이터를 결합해, 비지도 학습(HDP‑HSMM·K‑means)으로 도출한 ‘주행 프리미티브’를 기반으로 에너지 효율 및 배출량을 가중 평균하는 새로운 평가 방법을 제안한다. 전통적인 고정 주행 사이클을 대체할 수 있는 표준화된 오프‑사이클 평가 체계 구축에 기여한다. **
저자: Yan Chang, Weiqing Yang, Ding Zhao
**
본 논문은 연결·자동차(CAV)의 에너지 효율 및 배출량을 실거리 주행 데이터에 기반해 평가하는 새로운 방법론을 제시한다. 현재 연료 경제와 배출량을 측정하는 전통적인 고정 주행 사이클(예: EPA FTP, WLTP)은 CAV가 제공하는 에코‑드라이빙, 플래토닝, 교통 흐름 최적화 등 동적 특성을 반영하지 못한다. 따라서 정책 입안자와 규제 기관은 CAV 기술에 대한 공정한 오프‑사이클 크레딧을 부여하기 위한 표준화된 평가 체계가 필요하다.
### 1. 데이터와 전처리
연구에 사용된 대규모 자연주의 주행 데이터는 미시간 대학교가 제공한 Safety Pilot Model Deployment(SPMD) 데이터베이스에서 추출되었다. 3,000대 이상의 차량 중 경량 승용차 59대를 선택했으며, 각 차량은 10 Hz로 기록된 CAN 버스 신호(속도·가속도)를 포함한다. 데이터는 총 49,697 분(≈830 시간) 이상의 주행 시간을 제공한다. 전처리 단계에서 속도·가속도는 평균 0, 분산 1인 표준 정규분포로 정규화하였다.
### 2. 비지도 학습을 통한 주행 프리미티브 추출
#### 2.1 HDP‑HSMM 적용
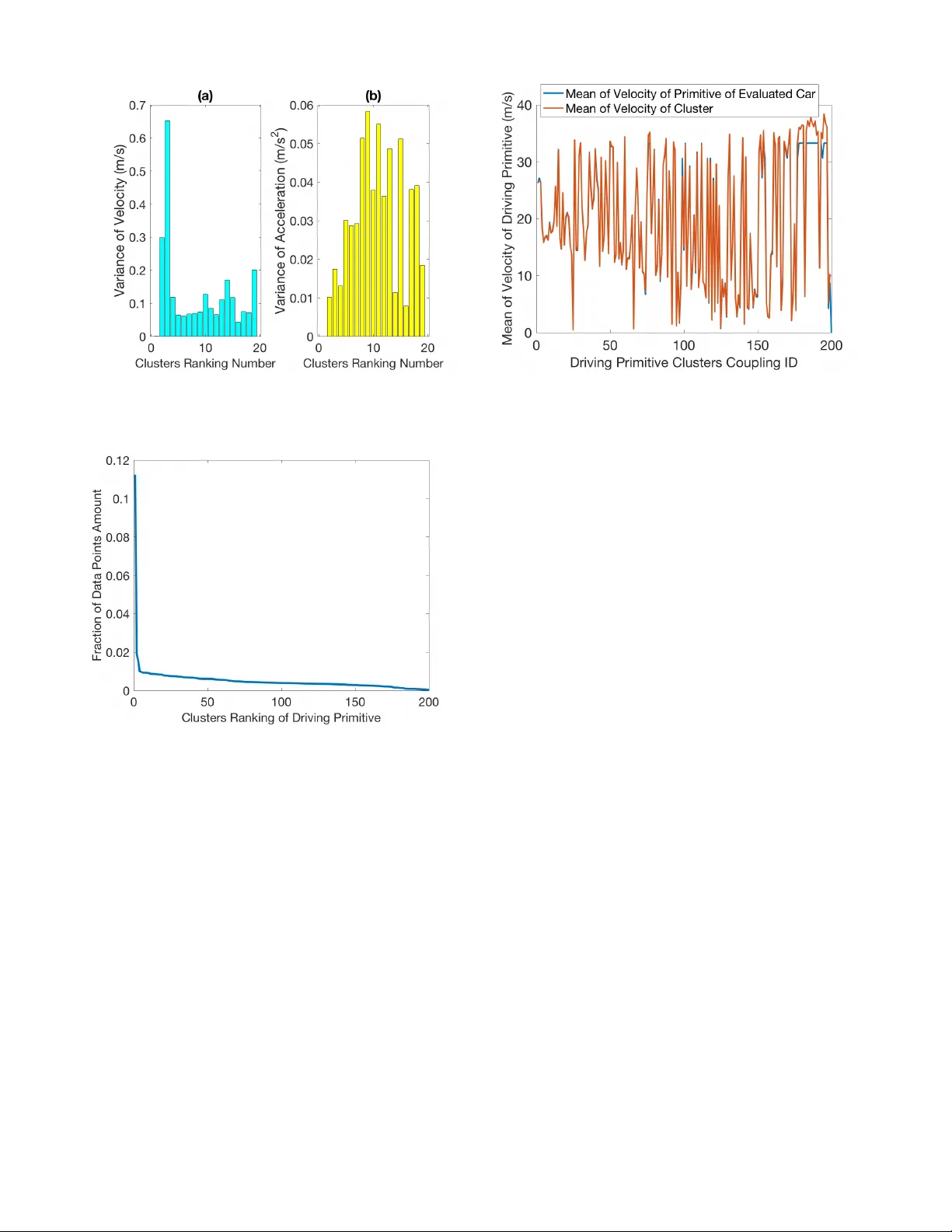
각 차량별 정규화된 시계열에 계층적 디리클레 프로세스 기반 은닉 반마코프 모델(HDP‑HSMM)을 적용했다. HDP‑HSMM은 사전 정의된 상태(프리미티브) 수를 필요로 하지 않으며, ‘sticky’ 파라미터를 통해 자기 전이 확률을 낮춰 실제 운전 상황에서 연속된 구간이 하나의 프리미티브에 머무르는 경향을 반영한다. 모델은 속도·가속도 평균, 공분산, 지속 시간(D) 등을 파라미터로 추정하고, 각 프리미티브는 가변 길이의 시간 구간으로 구분된다. 실험 결과, 차량당 평균 121개의 프리미티브가 도출되었으며, 최소 66개, 최대 155개의 프리미티브가 식별되었다.
#### 2.2 프리미티브 특성 요약
각 프리미티브에 대해 원본 물리량(속도·가속도)의 평균, 분산, 공분산을 계산하였다. 프리미티브의 데이터 포인트 비율을 기준으로 내림차순 정렬했으며, 상위 38% 프리미티브가 전체 데이터 포인트의 68%를 차지한다는 사실을 확인했다. 이는 대부분의 주행 상황이 소수의 프리미티브에 집중된다는 것을 의미한다.
### 3. 전역 클러스터링 – 전형적인 주행 프리미티브 정의
다양한 차량에서 추출된 프리미티브를 하나의 집합으로 모아 제약 K‑means(‘cannot‑link’ 제약) 알고리즘을 적용했다. 이 제약은 동일 차량의 프리미티브가 같은 클러스터에 배치되는 것을 방지해, 차량 간 공통된 운전 패턴을 강조한다. 결과적으로 20~30개의 전형적인 클러스터가 형성되었으며, 각 클러스터는 속도·가속도 평균값과 공분산 행렬로 대표된다. 클러스터별 데이터 포인트 비율(ω_i)은 전체 데이터에서 차지하는 비중을 나타내며, 이후 평가 단계에서 가중치로 활용된다.
### 4. 평가 대상 차량과 클러스터 매칭
평가하고자 하는 차량에 대해서도 동일한 HDP‑HSMM을 적용해 차량 고유의 프리미티브를 추출한다. 각 전형 클러스터와 평가 차량 프리미티브 사이의 유사도는 다변량 정규분포의 Kullback‑Leibler(KL) 발산을 이용해 측정한다. KL 발산이 최소인 프리미티브를 해당 클러스터와 ‘커플링’한다. 이 과정은 확률적 거리 기반 매칭이므로, 동일한 클러스터에 대해 여러 차량이 서로 다른 프리미티브와 매칭될 수 있다.
### 5. 에너지·배출 평가 계산
실험 차량에 연료 흐름 센서(또는 전기차의 전력 소비 센서)와 PEMS(Portable Emission Measurement System)를 장착해 실시간 연료 소비율(g/mi) 및 배출량(g/mi)을 측정한다. 각 매칭된 프리미티브 i에 대해 평균 연료·배출값(E_i)을 구하고, 클러스터 비율 ω_i와 곱해 가중합한다:
E = Σ_{i=1}^{n} ω_i·E_i
여기서 E는 전체 주행 구간에 대한 평균 연료 소비 또는 배출량을 의미한다. 연료 소비의 경우, 1/E를 통해 MPG(마일당 갤런)로 변환할 수 있다.
### 6. 결과 및 논의
- HDP‑HSMM을 이용한 프리미티브 추출은 차량별 데이터 양 차이에 강인하게 작동한다.
- 전형 클러스터는 전체 데이터의 대부분을 설명하며, 희귀 프리미티브(하위 5%)는 분석에서 제외해 잡음 감소 효과를 얻었다.
- KL 기반 매칭은 클러스터와 평가 차량 간의 통계적 차이를 정량화함으로써 재현 가능한 평가 절차를 제공한다.
- 제안된 가중 평균 방식은 기존 고정 사이클 대비 실제 교통 상황을 반영하므로, CAV의 에코‑드라이빙·플래토닝 효과를 정량화하는 데 유리하다.
### 7. 정책적·산업적 함의
본 프레임워크는 EPA의 오프‑사이클 크레딧 제도와 유사하게, CAV 및 신흥 친환경 기술에 대한 ‘공정한’ 크레딧을 부여할 수 있는 기반을 제공한다. 또한, 전통 내연기관 차량, 하이브리드, 전기차 모두 동일한 평가 절차에 적용 가능하므로, 국제적인 연비·배출 규제 표준을 통합하는 데 활용될 수 있다. 향후 연구에서는 도로 유형·날씨·교통량 등 외부 변수와 결합해 클러스터를 세분화하고, 실시간 클라우드 기반 평가 시스템을 구축하는 방향이 제시된다.
**
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기