Energy Efficiency and Emission Testing for Connected and Automated Vehicles Using Real-World Driving Data
By using the onboard sensing and external connectivity technology, connected and automated vehicles (CAV) could lead to improved energy efficiency, better routing, and lower traffic congestion. With the rapid development of the technology and adaptat…
Authors: Yan Chang, Weiqing Yang, Ding Zhao
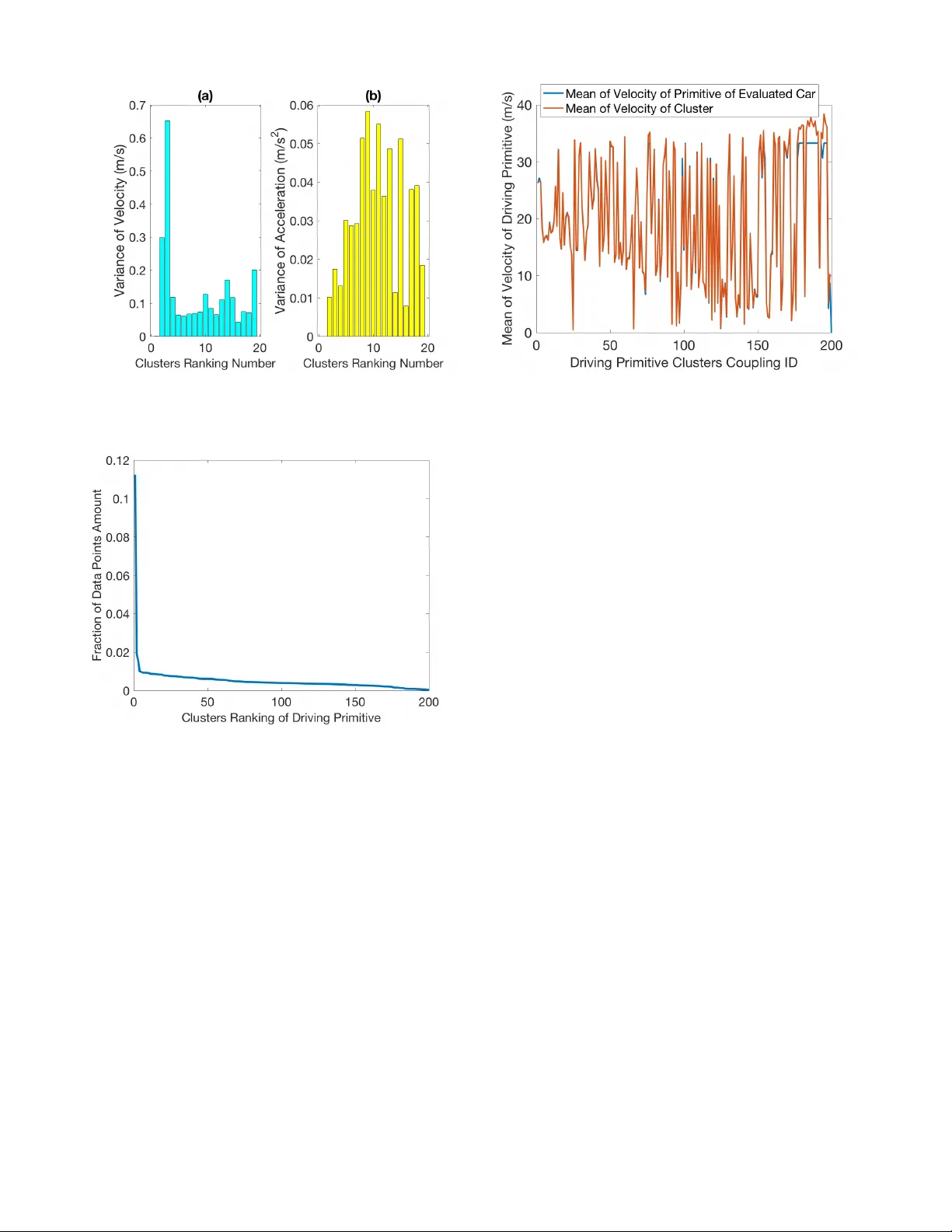
Energy Efficiency and Emission T esting for Connected and A utomated V ehicles Using Real-W orld Driving Data Y an Chang 1 , W eiqing Y ang 2 , Ding Zhao 3 Abstract — By using the onboard sensing and exter nal con- nectivity technology , connected and automated vehicles (CA V) could lead to improved energy efficiency , better routing, and lower traffic congestion. With the rapid development of the technology and adaptation of CA V , it is more critical to dev elop the universal evaluation method and the testing standard which could evaluate the impacts on energy consumption and en vironmental pollution of CA V fairly , especially under the various traffic conditions. In this paper , we proposed a new method and framework to ev aluate the energy efficiency and emission of the vehicle based on the unsupervised learning methods. Both the real-w orld driving data of the evaluated vehicle and the large naturalistic driving dataset are used to perform the driving primitive analysis and coupling. Then the linear weighted estimation method could be used to calculate the testing result of the evaluated vehicle. The results show that this method can successfully identify the typical driving primitives. The couples of the driving primitives from the evaluated vehicle and the typical driving primitives from the large real-world driving dataset coincide with each other very well. This new method could enhance the standard dev elopment of the energy efficiency and emission testing of CA V and other off-cycle credits. I . I N T RO D U C T I O N Connected and Automated V ehicle (CA V) technologies hav e been dev eloped significantly in recent years. CA V would change the mobility system and energy efficiency [1]. The mechanisms of the energy efficienc y and emission impacts of CA V could be eco-dri ving [2]–[4], platooning [5]– [7], congestion mitigation [8], [9], higher highway speeds [1], de-emphasized performance [10], [11], vehicle right siz- ing [12], improved crash avoidance [13], and trav el demand effects. Each eco-driving and platooning technology could offer substantial energy ef ficiency improvement in the range of 5% to 20% [1]. Howe ver , the standard to ev aluate the fuel economy and emission for CA V is not existing yet. The current fixed driv e cycle method is not suitable for the ev aluation of CA V . In order to fully release the benefits of the energy saving and emission reduction technologies and partial-automation technologies for CA V , policymakers need to consider to giv e the credits for fuel economy or Green House Gas (GHG) emission for the implementation of CA V technologies. How- ev er, the current Corporate A verage Fuel Economy (CAFE) 1 Y . Chang is with the Transportation Research Institute, University of Michigan, Ann Arbor , MI, 48109, USA. 2 W . Q. Y ang is with the Department of Mechanical Engineering, Uni- versity of Michigan, Ann Arbor , MI, 48109, USA. 3 D. Zhao is with the Department of Mechanical Engineering, Carnegie Mellon University , Pittsb urgh, P A, 15213, USA. ∗ Corresponding author . Email: yanchang@umich.edu (Y . Chang) /GHG test driving cycles [14] could not capture the benefits of CA V such as the scenarios when they interact with other vehicles and infrastructures. Fuel economy and emission testing normally uses a vehicle on a treadmill, while a trained driver or a robot follo ws a fixed dri ve cycle. The current standardized fuel economy testing system neglects differences in ho w individual vehicles dri ves on the road [15] so that some energy-sa ving automated and connected vehicle control algorithm could not be effecti vely reflected during the current dri ve cycle testing. The En vironmental Protection Agency (EP A) has used off-c ycle technology credits for CAFE standards to address similar issues of other emerg- ing technologies. Ho we ver , the e valuation process is not standardized and dif ferent technologies could not be tested equiv alently . In addition, the credits are only applicable to new and nonstandard technologies. Also, this only af fect the CAFE standard and it is not the fuel economy ratings which would inform the consumer or the emission le vel certification. [16] While Europe and China hav e the similar ev aluation method for fuel economy , commissions from these countries established the Real Driving Emissions (RDE) regulations and announced that the vehicle emission must be tested on the road in addition to the driv e c ycle testing and must be measured with a Portable Emission Measurement System (PEMS) [17]–[19]. Ho we ver , the reproducibility of these tests is very difficult to achieve because of the dynamic and en vironmental boundaries such as routes, ambient conditions, and the data analysis methods. The two main methods for data analysis that being tested and regulated are the Moving A veraging W indow (MA W) and Po wer Binning (PB). Ho we ver , MA W method sometimes normalized v alues which can influence the analysis and both MA W and PB lack of capability on analyzing the hybrid electric vehicles and electric vehicles [20]. In order to e v aluate the energy efficienc y and emission of new vehicle models with CA V features exhausti vely , new energy ef ficiency and emission testing method needs to be dev eloped. The research work related to fuel economy and emission testing standard for CA V is rare. Mersky [21] proposed a method to measure the fuel economy of the targeted vehicle by following a lead vehicle driving under EP A City and Highway fuel economy testing. This method could not include the information from the transportation system such as the other vehicles around the evaluated vehicle and the infrastructure. This paper proposes a method which targets on developing a statistical method of the energy efficiency and emission standard testing for CA V that can ev aluate the energy ef fi- ciency and emission of vehicles based on the database of naturalistic driving data instead of the driv e cycles. This method can e v aluate the CA V , the con ventional vehicles, and other of f-cycle credits ev aluation, which enhances the fair comparison of different types of vehicle technologies and models. Also, this e valuation method is flexible to be updated with the change of infrastructure, policy (speed limits), and dev elopment of the vehicle technologies. The idea of this method is as follows: 1. Use the data of naturalistic driving to get the typical driving primitiv es by using the unsupervised learning methods including Hierar- chical Dirichlet Process Hidden semi-Markov Model (HDP- HSMM) and K-means clustering. The driving primitiv e is defined as the combination of the speed and acceleration ov er a time interval. The durations of the driv e primitives usually vary . 2. Calculate the fraction of each cluster of the driving primitives and rank them. 3. Apply the HDP-HSMM method to the real dri ving data of the vehicle which is under ev aluation and get the driving primitiv es of the ev aluated vehicle. 4. Find the most matchable driving primiti ve of the e v aluated vehicle for each frequent dri ving primitive cluster and finish the coupling process. 5. Calculate the av erage value of the energy consumption and emission over the period of each dri ving primitiv e based on the real-time measurement of ener gy consumption and the emission of the ev aluated vehicle, and use these values and the corresponding fraction of the driving primitive clusters to get the energy efficienc y and emission ev aluation results. The major contributions of this paper are: • Propose a new method for the energy efficienc y and emission testing of CA V and the of f-cycle credit rating. • Propose a ne w method to se gment the dri ving conditions of velocity and acceleration of the real driving datasets effecti vely and efficiently . • Find out the frequent clusters of driving primitives and their fractions, which represent the typical dri ving conditions well. • Propose the effecti ve method for the coupling of the clusters of driving primiti ve based on large naturalis- tic driving datasets with the driving primitives of the ev aluated vehicle, which secures the repeatability and effecti veness of the ev aluation process. I I . M E T H O D O L O G Y A. Data Description For a relativ e long time, CA V and con ventional vehicles will coexist on the roads. When the penetration rate of CA V is lo w , CA V need to perform with the similar patterns as the con ventional vehicles driv e. In order to get the typical dri ving primitiv es which applies for both CA V and conv entional vehicles, the naturalistic driving data which records the drive behavior during ev ery day trips through unobtrusi ve data gathering equipment and without experimental control is used for this ev aluation method . Driving data used in this paper are from the Safety Pilot Model Deployment (SPMD) database. The SPMD was held T ABLE I: Ke y parameters of the de vices and trips from the queried dataset V ariable Name V alue V ehicle Amount 59 T otal T rip Amount 4577 Longest Trip Duration (min) 197.6 A verage of the Longest Trip Duration for Each V ehicle (min) 49.9 T otal Dri ving Time (min) 49697.3 Max of T otal Dri ving T ime for Each V ehicle (min) 2046.0 Min of T otal Dri ving T ime for Each V ehicle (min) 133.3 in Ann Arbor , Michigan, starting in August 2012. The deployment covered over 73 lane-miles and included ap- proximately 3,000 onboard vehicle equipped with vehicle-to- vehicle (V2V) communication devices and data acquisition system. The entities from this dataset include the basic safety messages (BSM) such as the v ehicles position, motion, safety information and the status of a vehicle’ s components. The data used in this paper is from the vehicle’ s Control Area Network (CAN) bus with recording frequency at 10 Hz. Currently ,two months of SPMD data (Oct. 2012 and April. 2013) are publicly av ailable for consumption and use via Department of T ransportation of ficial website [22]. W e are currently using this public sub-dataset of SPMD. The query standard of this dataset is as follows: • The vehicle is the light duty passenger car . (The data from the buses is eliminated) • The vehicle with a total driving duration from different trips larger than one hour . • The flag for valid CAN signal shows 1 (true). The key parameters of the devices and trips after the query are summarized in T able I. B. Analysis of the driving primitives of each vehicle The essential idea of the driv e cycle dev elopment from federal agencies is to have a standardized measurement stick for emissions and fuel economy which giv es a proxy for the typical driving and has the capability to compare across vehicles. The current dri ve cycle development is based on the frequency of bins of speed and acceleration with constant interval [23]. Ho wever , constant interv al might neglect important dri ving patterns inside the bins. In order to find the hidden patterns or grouping in driving data without restrictions, the unsupervised learning method is used in this paper to draw inferences of the typical dri ving primitiv es from datasets without labels of driving patterns. Unsuper- vised learning methods are widely used in transportation field. They hav e shown the great performance [24], [25]. Among the common cluster algorithms of the unsupervised learning, Hidden Markov models (HMM) can use observ ed data to recover the sequence of states, which would be suitable for the dri ving scenarios such as the speed change in the variable durations of driving primitives. HDP-HMM is a Bayesian nonparametric extension of the HMM for learning from sequential and time-series data [26]. HDP- HMMs strict Marko vian constraints are undesirable for our application. The weak limit sampling algorithm can be used Fig. 1: graphical model for the HDP-HSMM in which the number of nodes is random [27] for efficient posterior inference [27]. Here, we would like to identify the typical dri ving primitives of each vehicle without restriction of the duration of each primiti ve and amount of total primiti ves, so that HDP-HSMM with weak- limit sampler is used here. Figure 1 shows the graphical model for the HDP-HSMM in which the number of nodes is random. The HDP-HSMM ( γ , α, H , G ) can be described as follows [27]: β ∼ GE M ( γ ) (1a) π i iid ∼ D P ( α, β ) ( θ i , ω i ) iid ∼ H × G i = 1 , 2 , · · · , (1b) z s ∼ ¯ π z s − 1 , (1c) D s ∼ g ( ω z s ) , s = 1 , 2 , · · · , (1d) x t 1 s : t 2 s = z s (1e) y t 1 s : t 2 s iid ∼ f ( θ x t ) t 1 s = X ¯ s
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment