고차원 화성 언어 모델을 활용한 자동 코드 인식
프레임 단위가 아닌 코드 레벨에서 전이와 지속 시간을 명시적으로 모델링하고, N‑gram 화성 언어 모델과 신경망 기반 음향 모델을 결합한다. 소프트맥스 온도와 라벨 스무딩을 통해 신경망의 과신뢰 문제를 완화하고, 언어 모델이 인식 정확도를 약간 향상시키지만 그 효과는 제한적이다.
저자: Filip Korzeniowski, Gerhard Widmer
본 연구는 자동 코드 인식 시스템에서 음악적 화성 진행을 효과적으로 반영하기 위해 프레임‑단위가 아닌 코드‑레벨에서 전이와 지속 시간을 명시적으로 모델링하는 새로운 확률적 프레임워크를 제안한다. 기존 방법들은 P_T(전이 모델)로 마코프 혹은 RNN 기반의 프레임‑단위 전이만을 사용해, 자기‑전이가 지배적인 특성 때문에 실제 화성 규칙을 학습하기 어려웠다. 이를 극복하기 위해 저자들은 전이 모델을 두 부분, 즉 코드 언어 모델 P_L과 지속 시간 모델 P_D로 분리한다. P_L은 연속 중복을 제거한 압축 시퀀스 \(\bar y\)에 대해 N‑gram 확률을 적용하며, N은 2~4로 실험한다. N‑gram 확률은 최대우도 추정으로 구하고, 데이터 희소성을 완화하기 위해 Lidstone 스무딩(α) 을 사용한다. P_D는 부정 이항 분포를 기반으로 하여 ‘stay’와 ‘change’ 상태를 K개의 HMM 상태로 표현한다. K와 p는 학습 데이터에 대해 MLE로 추정한다.
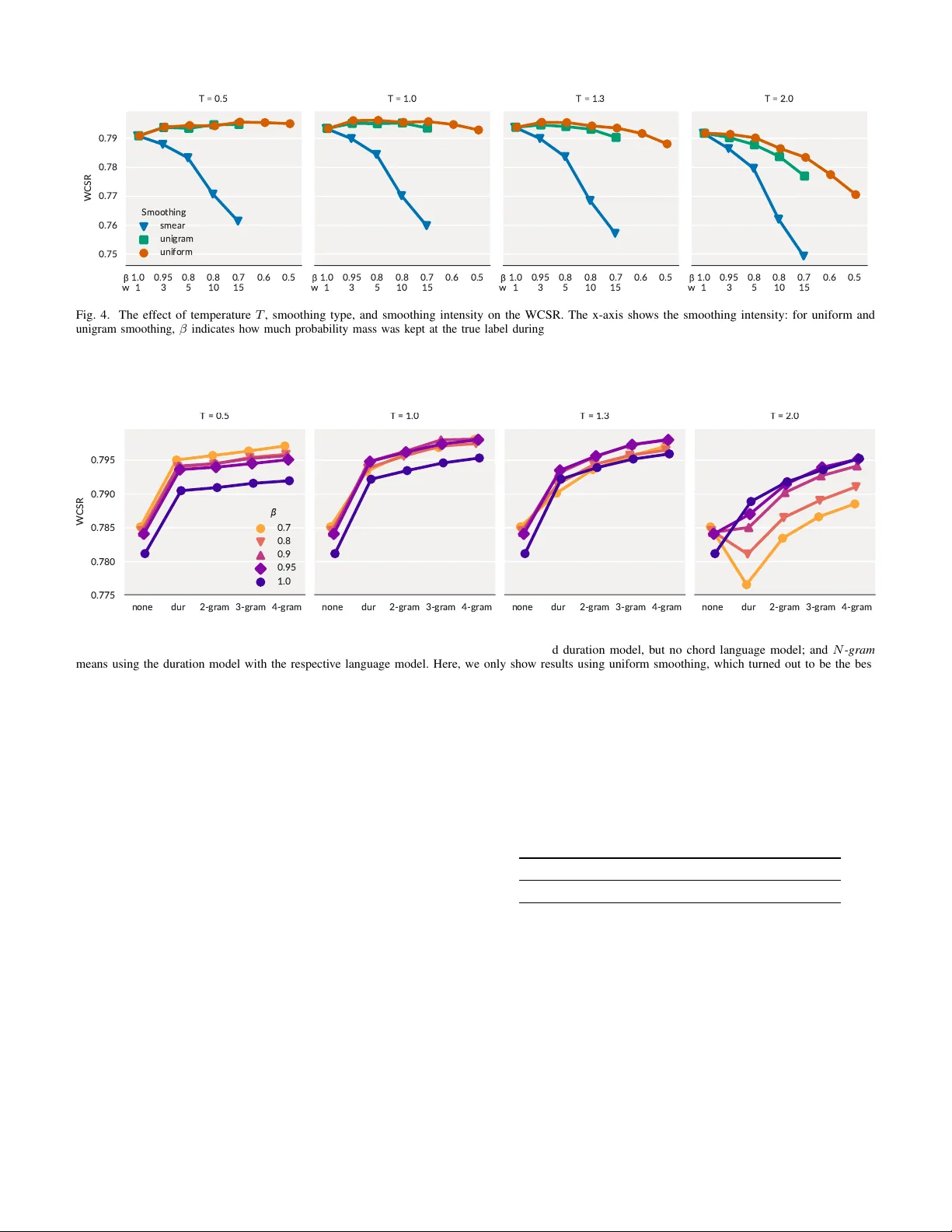
음향 모델 P_A는 VGG‑스타일 전역 컨볼루션 신경망으로, 1.5 초 길이의 로그‑멜 스펙트로그램을 입력받아 25개의 코드 클래스를 소프트맥스 확률로 출력한다. 신경망은 과신뢰(over‑confidence) 문제를 일으키기 쉬운데, 이를 완화하기 위해 두 가지 접근법을 시도한다. 첫째는 테스트 시에 소프트맥스 온도 T를 조절해 출력 분포를 부드럽게 하는 방법이며, 둘째는 학습 단계에서 라벨 스무딩을 적용하는 방법이다. 라벨 스무딩은 (a) 균일 스무딩, (b) 유니그램 스무딩, (c) 타깃 스미어링(시간적 평균) 세 가지 형태로 구현했으며, 스무딩 강도 β(또는 폭 w) 를 다양하게 조정했다.
전체 시스템은 P_A·P_L·P_D 를 결합한 계층적 HMM 형태가 되며, 이를 상태 평탄화 기법을 통해 1‑order HMM 으로 변환한다. 이렇게 하면 기존의 효율적인 Viterbi 디코딩을 그대로 사용할 수 있다. 실험은 비틀즈, 퀸, 로비 윌리엄스, 1958‑1991 빌보드 차트 등 다양한 장르와 시대의 1125곡(총 66 시간 이상)을 포함하는 복합 데이터셋을 4‑fold 교차 검증으로 수행했다. 평가 지표는 주요 25개 코드(메이저·마이너+무코드) 에 대한 Weighted Chord Symbol Recall(WCSR)이다.
주요 결과는 다음과 같다. (1) 온도 T=1 에서 라벨 스무딩 없이도 기본 성능이 높았으며, 온도를 낮추면(예: 0.5) 과신뢰가 심해져 스무딩이 필요했다. 반대로 온도를 높이면(예: 2.0) 스무딩이 과도하면 언어 모델이 과다하게 지배해 성능이 떨어졌다. (2) 균일 스무딩이 유니그램 스무딩보다 일관되게 좋은 결과를 보였으며, 타깃 스미어링은 언제나 성능을 저하시켰다. (3) 지속 시간 모델만 적용해도 WCSR가 약 1 %p 상승했으며, N‑gram 언어 모델을 추가하면 차수 N이 커질수록 추가 0.2~0.4 %p 정도의 미세한 향상이 있었다. 5‑gram까지 실험했을 때도 향상 폭은 여전히 작았다. (4) 전반적으로 언어 모델의 효과는 음성 인식 등 다른 분야에 비해 제한적이며, 이는 (a) 화성 진행 자체가 상대적으로 자유롭고, (b) 현재 사용된 N‑gram 모델이 충분히 복잡한 음악적 규칙을 포착하지 못하기 때문일 수 있다.
결론적으로, 코드‑레벨 전이와 지속 시간을 명시적으로 모델링하는 구조는 기존 프레임‑단위 접근법보다 더 나은 성능을 제공한다. 그러나 언어 모델의 추가 효과는 미미하며, 향후 연구에서는 더 풍부한 화성 규칙을 학습할 수 있는 심층 시퀀스 모델(예: 트랜스포머 기반)이나, 음악적 구조(키, 기능) 정보를 통합하는 방안을 모색해야 할 것이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기