Automatic Chord Recognition with Higher-Order Harmonic Language Modelling
Common temporal models for automatic chord recognition model chord changes on a frame-wise basis. Due to this fact, they are unable to capture musical knowledge about chord progressions. In this paper, we propose a temporal model that enables explici…
Authors: Filip Korzeniowski, Gerhard Widmer
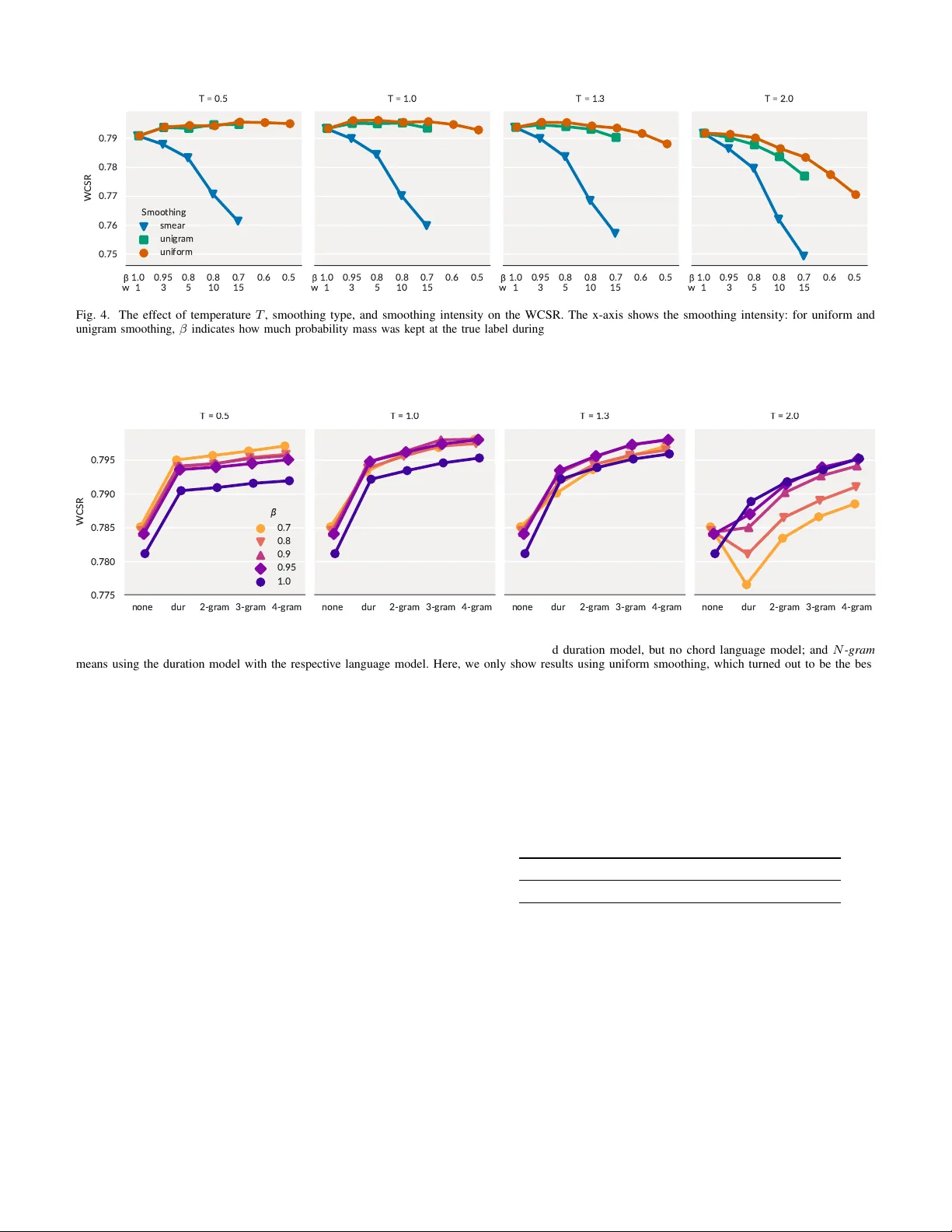
First published in the Proceedings of the 26th European Signal Processing Conference (EUSIPCO-2018) in 2018, published by EURASIP . Automatic Chord Recognition with Higher -Order Harmonic Language Modelling Filip K orzeniowski and Gerhard W idmer Institute of Computational Perception, Johannes Kepler Uni versity , Linz, Austria Email: filip.korzenio wski@jku.at Abstract —Common temporal models f or automatic chord recognition model chord changes on a frame-wise basis. Due to this fact, they are unable to captur e musical knowledge about chord progr essions. In this paper , we propose a temporal model that enables explicit modelling of chord changes and durations. W e then apply N -gram models and a neural-network- based acoustic model within this framework, and ev aluate the effect of model ov erconfidence. Our results show that model over confidence plays only a minor r ole (but target smoothing still impro ves the acoustic model), and that stronger chord language models do impr ove recognition results, howev er their effects are small compared to other domains. Index T erms —Chord Recognition, Language Modelling, N- Grams, Neural Networks Research on automatic chord recognition has recently focused on improving frame-wise predictions of acoustic models [1]–[3]. This trend roots in the fact that existing temporal models just smooth the predictions of an acoustic model, and do not incorporate musical knowledge [4]. As we argue in [5], the reason is that such temporal models are usually applied on the audio-frame lev el, where ev en non-Markovian models fail to capture musical properties. W e know the importance of language models in domains such as speech recognition, where hierarchical grammar , pronunciation and context models reduce word error rates by a large margin. Howe ver , the degree to which higher-order language models improv e chord recognition results yet remains unexplored. In this paper , we want to shed light on this question. Moti vated by the preliminary results from [5], we sho w how to integrate chord-lev el harmonic language models into a chord recognition system, and ev aluate its properties. Our contributions in this paper are as follows. W e present a probabilistic model that allo ws for combining an acoustic model with explicit modelling of chord transitions and chord durations. This allows us to deploy language models on the chor d level , not the frame le vel. W ithin this framework, we then apply N -gram chord language models on top of an neural network based acoustic model. Finally , we ev aluate to which degree this combination suffers from acoustic model over -confidence, a typical problem with neural acoustic models [6]. This work is supported by the European Research Council (ERC) under the EU’ s Horizon 2020 Framew ork Programme (ERC Grant Agreement number 670035, project “Con Espressione”). I . P RO B L E M D E FI N I T I O N Chord recognition is a sequence labelling problem similar to speech recognition. In contrast to the latter , we are also interested in the start and end points of the segments. Formally , assume x 1: T 1 is a time-frequency representation of the input signal; the goal is then to find y 1: T , where y t ∈ Y is a chord symbol from a chord vocabulary Y , such that y t is the correct harmonic interpretation of the audio content represented by x t . Formulated probabilistically , we want to infer ˆ y 1: T = argmax y 1: T P ( y 1: T | x 1: T ) . (1) Assuming a generati ve structure where y 1: T is a left-to-right process, and each x t only depends on y t , P ( y 1: T | x 1: T ) ∝ Y t 1 P ( y t ) P A ( y t | x t ) P T ( y t | y 1: t − 1 ) , where the 1 / P ( y t ) is a label prior that we assume uniform for simplicity [7], P A ( y t | x t ) is the acoustic model , and P T ( y t | y 1: t − 1 ) the temporal model . Common choices for P T (e.g. Markov processes or recurrent neural networks) are unable to model the underlying musical language of harmony meaningfully . As shown in [5], this is because modelling the symbolic chord sequence on a frame- wise basis is dominated by self-transitions. This prev ents the models from learning higher-le vel knowledge about chord changes. T o av oid this, we disentangle P T into a chord language model P L , and a chord duration model P D . The chord language model is defined as P L ( ¯ y i | ¯ y 1: i − 1 ) , where ¯ y 1: i = C ( y 1: t ) , and C ( · ) is a sequence compression map- ping that removes all consecutiv e duplicates of a symbol (e.g. C (( a, a, b, b, a )) = ( a, b, a ) ). P L thus only considers chord changes . The duration model is defined as P D ( s t | y 1: t − 1 ) , where s t ∈ { s , c } indicates whether the chord changes (c) or stays the same (s) at time t . P D thus only considers chord durations . The temporal model is then formulated as: P T ( y t | y 1: t − 1 ) = (2) ( P L ( ¯ y i | ¯ y 1: i − 1 ) P D ( c | y 1: t − 1 ) if y t 6 = y t − 1 P D ( s | y 1: t − 1 ) else . T o fully specify the system, we need to define the acoustic model P A , the language model P L , and the duration model P D . 1 W e use the notation v i : j to indicate ( v i , v i +1 , . . . , v j ) . 1 I I . M O D E L S A. Acoustic Model The acoustic model used in this paper is a minor variation of the one introduced in [8]. It is a VGG-style [9] fully con volutional neural network with 3 conv olutional blocks: the first consists of 4 layers of 32 3 × 3 filters, followed by 2 × 1 max-pooling in frequency; the second comprises 2 layers of 64 such filters followed by the same pooling scheme; the third is a single layer of 128 12 × 9 filters. Each of the blocks is followed by feature-map-wise dropout with probability 0.2, and each layer is follo wed by batch normalisation [10] and an exponential linear acti vation function [11]. Finally , a linear con volution with 25 1 × 1 filters follo wed by global average pooling and a softmax produces the chord class probabilities P A ( y k | x k ) . The input to the network is a log-magnitude log-frequency spectrogram patch of 1.5 seconds. See [8] for a detailed description of the input processing and training schemes. Neural networks tend to produce overconfident predictions, which leads to probability distributions with high peaks. This causes a weaker training signal because the loss function saturates, and makes the acoustic model dominate the language model at test time [6]. Here, we in vestigate two approaches to mitigate these effects: using a temperature softmax in the classification layer of the network, and training using smoothed labels. The temperature softmax replaces the regular softmax activ ation function at test time with σ ( z ) j = e z j / T P K k =1 e z k / T , where z is a real vector . High values for T make the resulting distribution smoother . With T = 1 , the function corresponds to the standard softmax. The advantage of this method is that the network does not need to be retrained. T arget smoothing, on the other hand, trains the network with with a smoothed version of the target labels. In this paper , we explore three ways of smoothing: uniform smoothing , where a proportion of 1 − β of the correct probability is assigned uniformly to the other classes; unigram smoothing , where the smoothed probability is assigned according to the class distribution in the training set [12]; and tar get smearing , where the target is smeared in time using a running mean filter . The latter is inspired by a similar approach in [13] to counteract inaccurate segment boundary annotations. B. Language Model W e designed the temporal model in Eq. 2 in a way that enables chord changes to be modelled explicitly via P L ( ¯ y k | C ( ¯ y 1: k − 1 )) . This formulation allows to use all past chords to predict the next. While this is a powerful and general notion, it prohibits efficient e xact decoding of the sequence. W e would hav e to rely on approximate methods to find ˆ y 1: T (Eq. 1). Ho wever , we can restrict the number of past chords the language model can consider , and use higher-order Markov models for 1 2 3 p 1 − p p 1 − p p 1 − p Fig. 1. Markov chain modelling the duration of a chord segment ( K = 3 ). The probability of staying in one of the states follows a ne gative binomial distribution. Fig. 2. Histogram of chord durations with two configurations of the negativ e binomial distribution. The log-probability is computed on a validation fold. exact decoding. T o achie ve that, we use N -grams for language modelling in this work. N -gram language models are Markovian probabilistic mod- els that assume only a fixed-length history (of length N − 1 ) to be rele vant for predicting the next symbol. This fixed-length history allo ws the probabilities to be stored in a table, with its entries computed using maximum-likelihood estimation (MLE)—i.e., by counting occurrences in the training set. W ith larger N , the sparsity of the probability table increases exponentially , because we only hav e a finite number of N - grams in our training set. W e tackle this problem using Lidstone smoothing, and add a pseudo-count α to each possible N -gram. W e determine the best value for α for each model using the validation set. C. Duration Model The focus of this paper is on ho w to meaningfully incorporate chord language models beyond simple first-order transitions. W e thus use only a simple duration model based on the negati ve binomial distribution, with the probability mass function P ( k ) = k + K − 1 K − 1 p K (1 − p ) k , where K is the number of failures, p the failure probability , and k the number of successes giv en K failures. For our purposes, k + K is the length of a chord in audio frames. The main advantage of this choice is that a negati ve binomial distribution is easily represented using only fe w states in a HMM (see Fig. 1), while still reasonably modelling the length of chord segments (see Fig. 2). For simplicity , we use the same duration model for all chords. The parameters ( K , the number of states used for modelling the duration, and p , the probability of moving to the next state) are estimated using MLE. D. Model Integr ation If we combine an N -gram language model with a negati ve binomial duration model, the temporal model P T becomes a Hierarchical Hidden Markov Model [14] with a higher-order Marko v model on the top level (the language model) and a first- order HMM at the second lev el (see Fig. 3a). W e can translate the hierarchical HMM into a first-order HMM; this will allow us to use many existing and optimised HMM implementations. T o this end, we first transform the higher-order HMM on the top lev el into a first-order one as shown e.g. in [15]: we factor the dependencies beyond first-order into the HMM state, considering that self-transitions are impossible as Y N = { ( y 1 , . . . , y N ) : y i ∈ Y , y i 6 = y i +1 } , where N is the order of the N -gram model. Semantically , ( y 1 , . . . , y N ) represents chord y 1 , ha ving seen y 2 , . . . , y N in the immediate past. This increases the number of states from |Y | to |Y | · ( |Y | − 1) N − 1 . W e then flatten out the hierarchical HMM by combining the state spaces of both lev els as Y N × [1 ..K ] , and connecting all incoming transitions of a chord state to the corresponding first duration state, and all outgoing transitions from the last duration state (where the outgoing probabilities are multiplied by p ). Formally , Y ( K ) N = { ( y , k ) : y ∈ Y N , k ∈ [1 ..K ] } , with the transition probabilities defined as P (( y , k ) | ( y , k )) = 1 − p, P (( y , k + 1) | ( y , k )) = p, P (( y , 1) | ( y 0 , K )) = P L ( y 1 | y 2: N ) · p, where y 2: N = y 0 1: N − 1 . All other transitions have zero prob- ability . Fig. 3b shows the HMM from Fig. 3a after the transformation. The resulting model is similar to a higher-order duration- explicit HMM (DHMM). The main difference is that we use a compact duration model that can assign duration probabilities using few states, while standard DHMMs do not scale well if longer durations need to be modelled (their computation increases by a factor of D 2 / 2 , where D is the longest duration to be modelled [17]). For example, [16] uses first-order DHMMs to decode beat-synchronised chord sequences, with D = 20 . In our case, we would need a much higher D , since our model operates on the frame lev el, which would result in a prohibitively large state space. In comparison, our duration models use only K = 2 (as determined by MLE) states to model the duration, which significantly reduces the computational burden. I I I . E X P E R I M E N T S Our experiments aim at uncovering (i) if acoustic model ov erconfidence is a problem in this scenario, (ii) whether smoothing techniques can mitigate it, and (iii) whether and to which degree chord language modelling improves chord C 2 1 e p 1 − p p 1 − p 1 . 0 A 2 1 e p 1 − p p 1 − p 1 . 0 . . . . . . . . . P ( A | C ) P ( G | C ) P ( F | C ) . . . . . . . . . P ( E | A ) P ( D | A ) (a) First-Order Hierarchical HMM. (C, 1) (C, 2) (A, 1) (A, 2) p 1 − p P ( A | C ) · p 1 − p p 1 − p 1 − p . . . . . . . . . P ( G | C ) · p P ( F | C ) · p . . . . . . . . . P ( D | A ) · p P ( E | A ) · p (b) Flattened version of the First-Order Hierarchical HMM. Fig. 3. Exemplary Hierarchical HMM and its flattened version. W e left out incoming and outgoing transitions of the chord states for clarity (except C → A and the ones indicated in gray). The model uses 2 states for duration modelling, with “e” referring to the final state on the duration level (see [14] for details). Although we depict a first-order language model here, the same transformation works for higher-order models. recognition results. T o this end, we in vestigated the ef fect of var - ious parameters: softmax temperature T ∈ { 0 . 5 , 1 . 0 , 1 . 3 , 2 . 0 } , smoothing type (uniform, unigram, and smear), smoothing intensity β ∈ { 0 . 5 , 0 . 6 , 0 . 7 , 0 . 8 , 0 . 9 , 0 . 95 } and smearing width w ∈ { 3 , 5 , 10 , 15 } , and the language model order N ∈ { 2 , 3 , 4 } . The experiments were carried out using 4-fold cross- validation on a compound dataset consisting of the following sub-sets: Isophonics 2 : 180 songs by the Beatles, 19 songs by Queen, and 18 songs by Zweieck, 10:21 hours of audio; R WC Popular [18]: 100 songs in the style of American and Japanese pop music, 6:46 hours of audio; Robbie Williams [19]: 65 songs by Robbie W illiams, 4:30 of audio; and McGill Bill- board [20]: 742 songs sampled from the American billboard charts between 1958 and 1991, 44:42 hours of audio. The compound dataset thus comprises 1125 unique songs, and a total of 66:21 hours of audio. W e focus on the major/minor chord vocabulary (i.e. major and minor chords for each of the 12 semitones, plus a “no- chord” class, totalling 25 classes). The ev aluation measure we are interested in is thus the weighted chord symbol recall of major and minor chords, WCSR = t c / t a , where t c is the total time the our system recognises the correct chord, and t a is the total duration of annotations of the chord types of interest. 2 http://isophonics.net/datasets Fig. 4. The effect of temperature T , smoothing type, and smoothing intensity on the WCSR. The x-axis shows the smoothing intensity: for uniform and unigram smoothing, β indicates how much probability mass was kept at the true label during training; for target smearing, w is the width of the running mean filter used for smearing the targets in time. For these results, a 2-gram language model was used, but the outcomes are similar for other language models. The key observations are the following: (i) target smearing is always detrimental; (ii) uniform smoothing works slightly better than unigram smoothing (in other domains, authors report the contrary [6]); and (iii) smoothing improves the results, howe ver , excessiv e smoothing is harmful in combination with higher softmax temperatures (a relation we explore in greater detail in Fig. 5). Fig. 5. Interaction of temperature T , smoothing intensity β and language model with respect to the WCSR. W e show four language model configurations: none means using the predictions of the acoustic model directly; dur means using the chord duration model, but no chord language model; and N -gram means using the duration model with the respective language model. Here, we only show results using uniform smoothing, which turned out to be the best smoothing technique we examined in this paper (see Fig. 4). W e observe the following: (i) Even simple duration modelling accounts for the majority of the improvement (in accordance with [16]). (ii) Chord language models further impro ve the results—the stronger the language model, the bigger the improvement. (iii) T emperature and smoothing interact: at T = 1 , the amount of smoothing plays only a minor role; if we lower T (and thus make the predictions more confident), we need stronger smoothing to compensate for that; if we increase both T and the smoothing intensity , the predictions of the acoustic model are over -ruled by the language model, which shows to be detrimental. (iv) Smoothing has an additional effect during the training of the acoustic model that cannot be achiev ed using post-hoc changes in softmax temperature. Unsmoothed models never achieve the best result, regardless of T . A. Results and Discussion W e analyse the interactions between temperature, smoothing, and language modelling in Fig. 4 and Fig. 5. Uniform smooth- ing seems to perform best, while increasing the temperature in the softmax is unnecessary if smoothing is used. On the other hand, target smearing performs poorly; it is thus not a proper way to cope with uncertainty in the annotated chord boundaries. The results indicate that in our scenario, acoustic model ov erconfidence is not a major issue. The reason might be that the temporal model we use in this work allows for exact decoding. If we were forced to perform approximate inference (e.g. by using a RNN-based language model), this ov erconfidence could cut off promising paths early . T ar get smoothing still exhibits a positiv e effect during the training of the acoustic model, and can be used to fine-balance the interaction between acoustic and temporal models. T ABLE I W C SR F O R T H E C O MP O U N D DAT A S ET . F O R T H ES E R E S U L T S , W E U S E A S O FT M A X T E MP E R A T U R E O F T = 1 . 0 A N D U N I FO R M S M O OT H IN G W I TH β = 0 . 9 . None Dur . 2-gram 3-gram 4-gram 5-gram 78.51 79.33 79.59 79.69 79.81 79.88 Further , we see consistent improv ement the stronger the language model is (i.e., the higher N is). Although we were not able to ev aluate models beyond N = 4 for all configurations, we ran a 5-gram model on the best configuration for N = 4 . The results are shown in T able I. Although consistent, the improv ement is marginal compared to the effect language models show in other domains such as speech recognition. There are two possible interpretations of this result: (i) ev en if modelled explicitly , chord language models contribute little to the final results, and the most important part is indeed modelling the chord duration; and (ii) the language models used in this paper are simply not good enough to make a major difference. While the true reason yet remains unclear , the structure of the temporal model we propose enables us to research both possibilities in future work, because it makes their contributions explicit. Finally , our results confirm the importance of duration modelling [16]. Although the duration model we use here is simplistic, it improves results considerably . Howe ver , in further informal experiments, we found that it underestimates the probability of long chord segments, which impairs results. This indicates that there is still potential for improvement in this part of our model. I V . C O N C L U S I O N W e proposed a probabilistic structure for the temporal model of chord recognition systems. This structure disentangles a chord language model from a chord duration model. W e then applied N -gram chord language models within this structure and ev aluated various properties of the system. The key outcomes are that (i) acoustic model overconfidence plays only a minor role (but target smoothing still improves the acoustic model), (ii) chord duration modelling (or, sequence smoothing) improv es results considerably , which confirms prior studies [4], [16], and (iii) while employing N -gram models also improv es the results, their effect is marginal compared to other domains such as speech recognition. Why is this the case? Static N -gram models might only capture global statistics of chord progressions, and these could be too general to guide and correct predictions of the acoustic model. More powerful models may be required. As shown in [21], RNN-based chord language models are able to adapt to the currently processed song, and thus might be more suited for the task at hand. The proposed probabilistic structure thus opens v arious possibilities for future work. W e could explore better language models, e.g. by using more sophisticated smoothing techniques, RNN-based models, or probabilistic models that take into account the key of a song (the probability of chord transitions v aries depending on the key). More intelligent duration models could take into account the tempo and harmonic rhythm of a song (the rhythm in which chords change). Using the model presented in this paper , we could then link the improvements of each individual model to improv ements in the final chord recognition score. R E F E R E N C E S [1] F . Korzenio wski and G. Widmer , “Feature Learning for Chord Recog- nition: The Deep Chroma Extractor, ” in 17th International Society for Music Information Retrieval Conference (ISMIR) , New Y ork, USA, Aug. 2016. [2] B. McFee and J. P . Bello, “Structured T raining for Lar ge-V ocabulary Chord Recognition, ” in 18th International Society for Music Information Retrieval Conference (ISMIR) , Suzhou, China, Oct. 2017. [3] E. J. Humphrey , T . Cho, and J. P . Bello, “Learning a Robust T onnetz- Space Transform for Automatic Chord Recognition, ” in 2012 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing (ICASSP) , Kyoto, Japan, 2012. [4] T . Cho and J. P . Bello, “On the Relative Importance of Individual Components of Chord Recognition Systems, ” IEEE/ACM Tr ansactions on Audio, Speech, and Language Processing , vol. 22, no. 2, pp. 477–492, Feb . 2014. [5] F . K orzeniowski and G. W idmer , “On the Futility of Learning Complex Frame-Lev el Language Models for Chord Recognition, ” in Proceedings of the AES International Conference on Semantic Audio , Erlangen, Germany , Jun. 2017. [6] J. Chorowski and N. Jaitly , “T ow ards better decoding and language model integration in sequence to sequence models, ” , Dec. 2016. [7] S. Renals, N. Mor gan, H. Bourlard, M. Cohen, and H. Franco, “Con- nectionist Probability Estimators in HMM Speech Recognition, ” IEEE T ransactions on Speech and Audio Pr ocessing , vol. 2, no. 1, pp. 161–174, Jan. 1994. [8] F . Korzenio wski and G. Widmer , “ A Fully Conv olutional Deep Auditory Model for Musical Chord Recognition, ” in 26th IEEE International W orkshop on Machine Learning for Signal Processing (MLSP) , Salerno, Italy , Sep. 2016. [9] K. Simonyan and A. Zisserman, “V ery Deep Convolutional Networks for Large-Scale Image Recognition, ” , Sep. 2014. [10] S. Ioffe and C. Szegedy , “Batch Normalization: Accelerating Deep Net- work T raining by Reducing Internal Covariate Shift, ” , Mar . 2015. [11] D.-A. Clevert, T . Unterthiner, and S. Hochreiter, “Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs), ” in International Confer ence on Learning Repr esentations (ICLR), arXiv:1511.07289 , San Juan, Puerto Rico, Feb . 2016. [12] C. Szegedy , V . V anhoucke, S. Ioffe, J. Shlens, and Z. W ojna, “Rethinking the Inception Architecture for Computer V ision, ” , Dec. 2015. [13] K. Ullrich, J. Schl ¨ uter , and T . Grill, “Boundary Detection in Music Structure Analysis Using Convolutional Neural Networks, ” in 15th International Society for Music Information Retrieval Confer ence (ISMIR) , T aipei, T aiwan, Oct. 2014. [14] S. Fine, Y . Singer, and N. Tishby , “The Hierarchical Hidden Markov Model: Analysis and Applications, ” Machine Learning , vol. 32, no. 1, pp. 41–62, Jul. 1998. [15] U. Hadar and H. Messer , “High-order Hidden Markov Models - Estimation and Implementation, ” in 2009 IEEE/SP 15th W orkshop on Statistical Signal Pr ocessing , Aug. 2009, pp. 249–252. [16] R. Chen, W . Shen, A. Sriniv asamurthy , and P . Chordia, “Chord Recognition Using Duration-Explicit Hidden Markov Models, ” in 13th International Society for Music Information Retrieval Confer ence (ISMIR) , Porto, Portugal, Oct. 2012. [17] L. R. Rabiner, “ A T utorial on Hidden Markov Models and Selected Applications in Speech Recognition, ” Pr oceedings of the IEEE , vol. 77, no. 2, pp. 257–286, 1989. [18] M. Goto, H. Hashiguchi, T . Nishimura, and R. Oka, “R WC Music Database: Popular , Classical and Jazz Music Databases. ” in 3rd Interna- tional Conference on Music Information Retrieval (ISMIR) , Paris, France, 2002. [19] B. Di Giorgi, M. Zanoni, A. Sarti, and S. Tubaro, “ Automatic chord recog- nition based on the probabilistic modeling of diatonic modal harmony , ” in Pr oceedings of the 8th International W orkshop on Multidimensional Systems , Erlangen, Germany , Sep. 2013. [20] J. A. Burgoyne, J. Wild, and I. Fujinaga, “ An Expert Ground T ruth Set for Audio Chord Recognition and Music Analysis. ” in 12th International Society for Music Information Retrieval Confer ence (ISMIR) , Miami, USA, Oct. 2011. [21] F . Korzenio wski, D. R. W . Sears, and G. Widmer , “ A Large-Scale Study of Language Models for Chord Prediction, ” in 2018 IEEE International Confer ence on Acoustics, Speech and Signal Processing (ICASSP) , Calgary , Canada, Apr. 2018.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment