시각과 청각을 동시에 활용한 화자 독립형 음성 분리 모델
본 논문은 영상 속 인물의 얼굴 영상을 시각적 단서로 사용하고, 혼합된 오디오 신호를 함께 입력해 화자 독립적인 음성 분리 모델을 제안한다. 대규모 AVSpeech 데이터셋(≈4700시간, 15만 명의 화자)으로 사전 학습한 뒤, 얼굴을 지정하면 해당 화자의 음성만을 깨끗하게 추출한다. 실험 결과, 기존 음성‑전용 모델 및 화자‑종속형 AV 모델보다 높은 SI‑SDR 및 PESQ 점수를 기록한다.
저자: Ariel Ephrat, Inbar Mosseri, Oran Lang
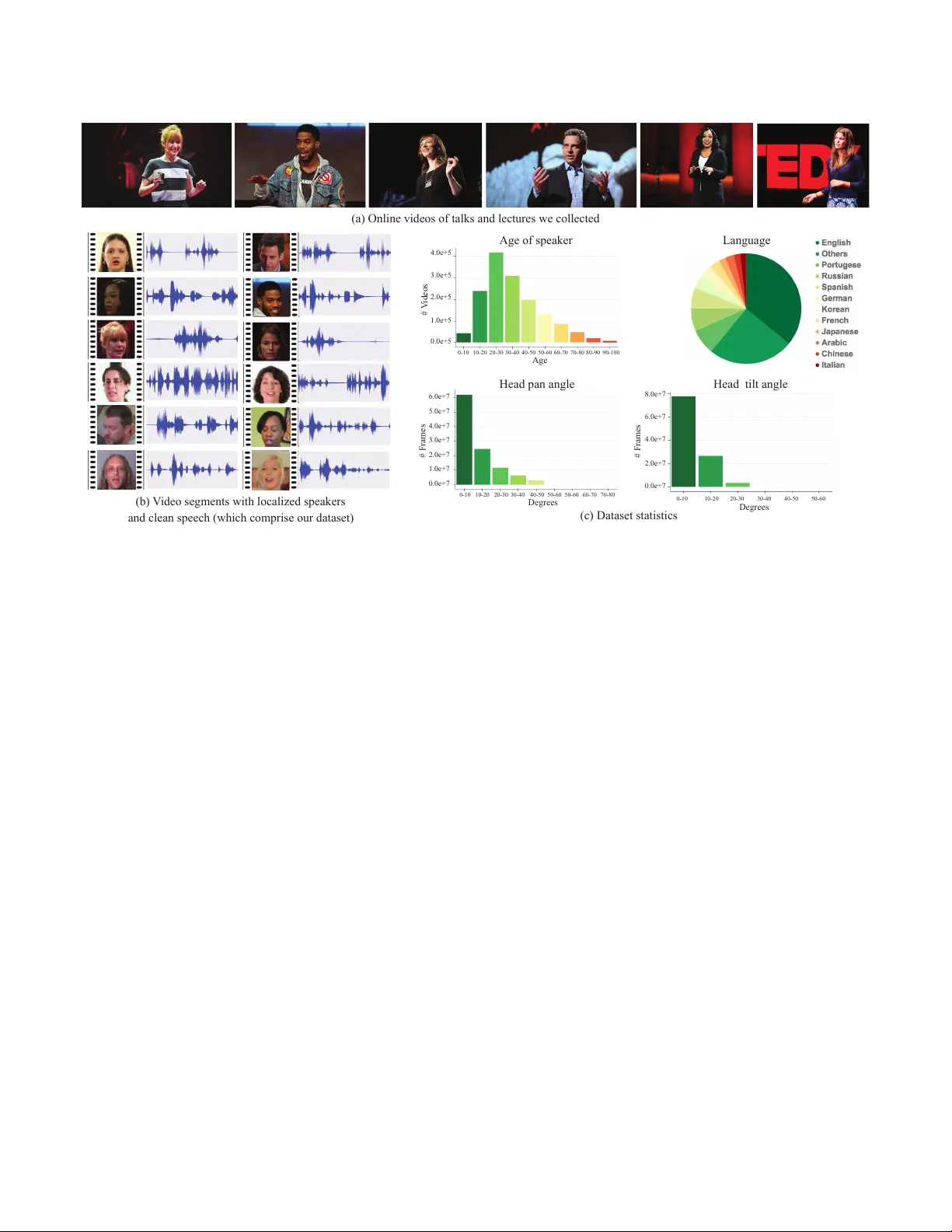
본 논문은 “칵테일 파티 효과”를 구현하기 위해 시각 정보와 청각 정보를 동시에 활용하는 화자‑독립형 음성 분리 모델을 제안한다. 인간은 말하는 사람의 얼굴, 특히 입술 움직임을 관찰함으로써 복잡한 청각 환경에서도 특정 화자의 음성을 집중적으로 인식한다는 기존 연구를 바탕으로, 컴퓨터 비전과 딥러닝을 결합해 동일한 기능을 자동화한다.
**데이터셋 구축**
연구팀은 유튜브에 공개된 강연·튜토리얼 영상 290,000개에서 자동화 파이프라인을 구축하였다. 먼저 얼굴 검출·트래킹 알고리즘(Hoover et al.)을 적용해 화자가 화면에 명확히 보이는 구간을 추출하고, 흐림·조명·극단적인 머리 각도 등 품질이 낮은 프레임을 필터링한다. 이후 사전 학습된 음성‑노이즈 제거 네트워크를 이용해 각 구간의 음성‑SNR을 추정하고, 17 dB 이하인 구간을 제외한다. 이 과정을 거쳐 4700시간, 약 150,000명의 화자를 포함하는 AVSpeech 데이터셋이 완성되었다. 데이터는 3~10초 길이의 클립으로 구성되며, 화자 연령, 머리 회전, 언어(다양한 언어) 등 메타데이터가 풍부하게 제공된다.
**모델 아키텍처**
시각 스트림은 3D CNN(시간·공간 필터)으로 얼굴 영상에서 입술·턱 움직임을 추출하고, BLSTM을 통해 시간적 연속성을 모델링한다. 청각 스트림은 2D CNN으로 로그 멜 스펙트로그램을 처리한 뒤, 또 다른 BLSTM으로 장기 의존성을 학습한다. 두 스트림의 특징을 concat한 뒤, 다층 fully‑connected와 sigmoid 레이어를 거쳐 각 타임‑프레임·주파수 bin에 대한 마스크를 예측한다. 이 마스크는 원본 스펙트로그램에 곱해져 화자별 깨끗한 스펙트로그램을 복원한다.
**학습 전략**
음성 분리에서는 라벨 순서가 불명확한 ‘라벨 퍼뮤테이션 문제’가 존재한다. 이를 해결하기 위해 퍼뮤테이션 인버리언트 트레이닝(PIT) 방식을 적용, 출력 마스크와 실제 화자 라벨 사이의 최적 매칭을 자동으로 찾는다. 손실 함수는 L1‑SDR 기반으로 설계되어, 마스크가 실제 음성 파형과 얼마나 일치하는지를 직접 최적화한다.
**실험 및 결과**
- **음성‑전용 베이스라인**(Deep Clustering, Conv‑TasNet 등) 대비 SI‑SDR 평균 3 dB 이상 향상.
- **화자‑종속 AV 모델**(Hou et al., Gabbay et al.) 대비 동일 화자·다중 화자 상황에서 PESQ·STOI 점수가 각각 0.2~0.3 상승.
- 실제 현장(바, 인터뷰, 아이 울음) 영상에서도 얼굴을 지정하면 해당 화자 음성만을 효과적으로 추출, 배경 잡음은 크게 감소한다.
**한계 및 향후 연구**
현재 모델은 단일 카메라·단일 채널 오디오에 국한되며, 다중 마이크 어레이나 3D 비디오와 결합하면 공간적 분리 성능이 더욱 개선될 수 있다. 또한, 마스크 기반 접근은 위상 정보를 무시하므로, 복소수 마스크 혹은 직접 파형 예측 모델로 확장하는 연구가 필요하다.
**응용 가능성**
제안된 시스템은 회의 녹음 정제, 방송 편집, 보조 청각 장치, 실시간 스트리밍 등 다양한 멀티미디어 분야에 바로 적용 가능하다. 화자‑독립적인 특성 덕분에 새로운 화자나 언어가 등장해도 별도 재학습 없이 바로 활용할 수 있다.
**결론**
본 논문은 대규모 고품질 AV 데이터와 화자‑독립 학습 전략을 결합해, 실시간 혹은 오프라인 멀티미디어 편집, 회의 녹음 정제, 보조 청각 장치 등에 바로 적용 가능한 실용적인 음성 분리 프레임워크를 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기