스택드 아워글래스 네트워크를 활용한 음악 소스 분리
본 논문은 이미지 기반 인간 자세 추정에 성공한 스택드 아워글래스 네트워크를 음악 스펙트로그램에 적용해, 단일 CNN으로 보컬·반주·드럼·베이스 등 여러 악기 소스를 동시에 분리하는 방법을 제안한다. 다중 스케일 특징을 학습하고, 각 아워글래스 모듈마다 마스크를 정제함으로써 MIR‑1K와 DSD100 데이터셋에서 기존 최첨단 모델과 경쟁 가능한 성능을 달성하였다.
저자: Sungheon Park, Taehoon Kim, Kyogu Lee
본 논문은 음악 신호의 소스 분리를 위해 최근 컴퓨터 비전 분야에서 성공을 거둔 스택드 아워글래스 네트워크를 도입한다. 기존 음악 소스 분리 연구는 주로 NMF, DNN, RNN, U‑Net 등 다양한 모델을 사용했지만, 대부분 파라미터가 많거나 여러 개의 네트워크를 별도로 학습해야 하는 한계가 있었다. 저자들은 이러한 문제를 해결하고자, 하나의 CNN으로 다중 소스를 동시에 분리할 수 있는 경량화된 구조를 설계하였다.
먼저, 입력으로는 8 kHz로 다운샘플링된 오디오의 magnitude 스펙트로그램을 사용한다. STFT 파라미터는 윈도우 1024, 홉 256이며, 512 × 64 크기의 2‑D 이미지 형태로 변환한다. 초기 레이어는 7 × 7 컨볼루션 하나와 3 × 3 컨볼루션 네 개(채널 64→128→128→128→256)로 구성되어, 풀링 없이 바로 아워글래스 모듈에 전달한다.
아워글래스 모듈은 4단계 다운샘플링/업샘플링을 거치며, 각 단계마다 3 × 3 컨볼루션을 적용한다. 다운샘플링에서는 2 × 2 맥스풀링으로 해상도를 절반으로 줄이고, 업샘플링에서는 최근접 보간 후 3 × 3 컨볼루션으로 복원한다. 이때 동일 해상도에서의 피처는 1 × 1 컨볼루션을 통해 연결돼, 저해상도에서 얻은 전역 정보와 고해상도에서의 세부 정보를 효과적으로 결합한다. 모듈 말미에는 3 × 3 컨볼루션과 1 × 1 컨볼루션 두 개가 이어져, 출력 채널 수를 소스 개수(C)와 동일하게 만든다.
스택드 구조는 이러한 아워글래스 모듈을 1, 2, 4번 순차적으로 쌓아 구현한다. 각 모듈의 출력 마스크는 입력 스펙트로그램과 원소별 곱해 추정 스펙트로그램을 만든 뒤, L1,1 손실(행렬 원소 절대값 합)로 학습한다. 손실은 모든 소스와 모든 모듈에 대해 합산되며, 이는 ‘intermediate supervision’이라 불리는 중간 감독 효과를 제공한다. 흥미롭게도, 마스크에 시그모이드 활성화를 적용하지 않고 직접 1 × 1 컨볼루션 출력값을 사용함으로써 학습 속도와 최종 성능이 향상되었다.
학습은 Adam 옵티마이저(초기 학습률 1e‑4, 80 % 학습 시 2e‑5로 감소)로 진행되며, MIR‑1K는 15 k 스텝, DSD100은 150 k 스텝을 수행한다. 배치 크기는 4이며, 데이터 증강은 적용하지 않았다. 훈련 시간은 MIR‑1K에서 약 3시간, DSD100에서 약 31시간(단일 GPU)이다.
실험에서는 두 가지 과제를 설정했다. 첫 번째는 보컬과 반주를 2‑source로 분리하는 MIR‑1K 실험이며, 두 번째는 드럼, 베이스, 보컬, 기타(기타) 등 4‑source로 분리하는 DSD100 실험이다. 평가 지표는 BSS‑Eval 기반 SDR, SIR, SAR와 보컬 분리에서는 NSDR, GNSDR 등을 사용했다.
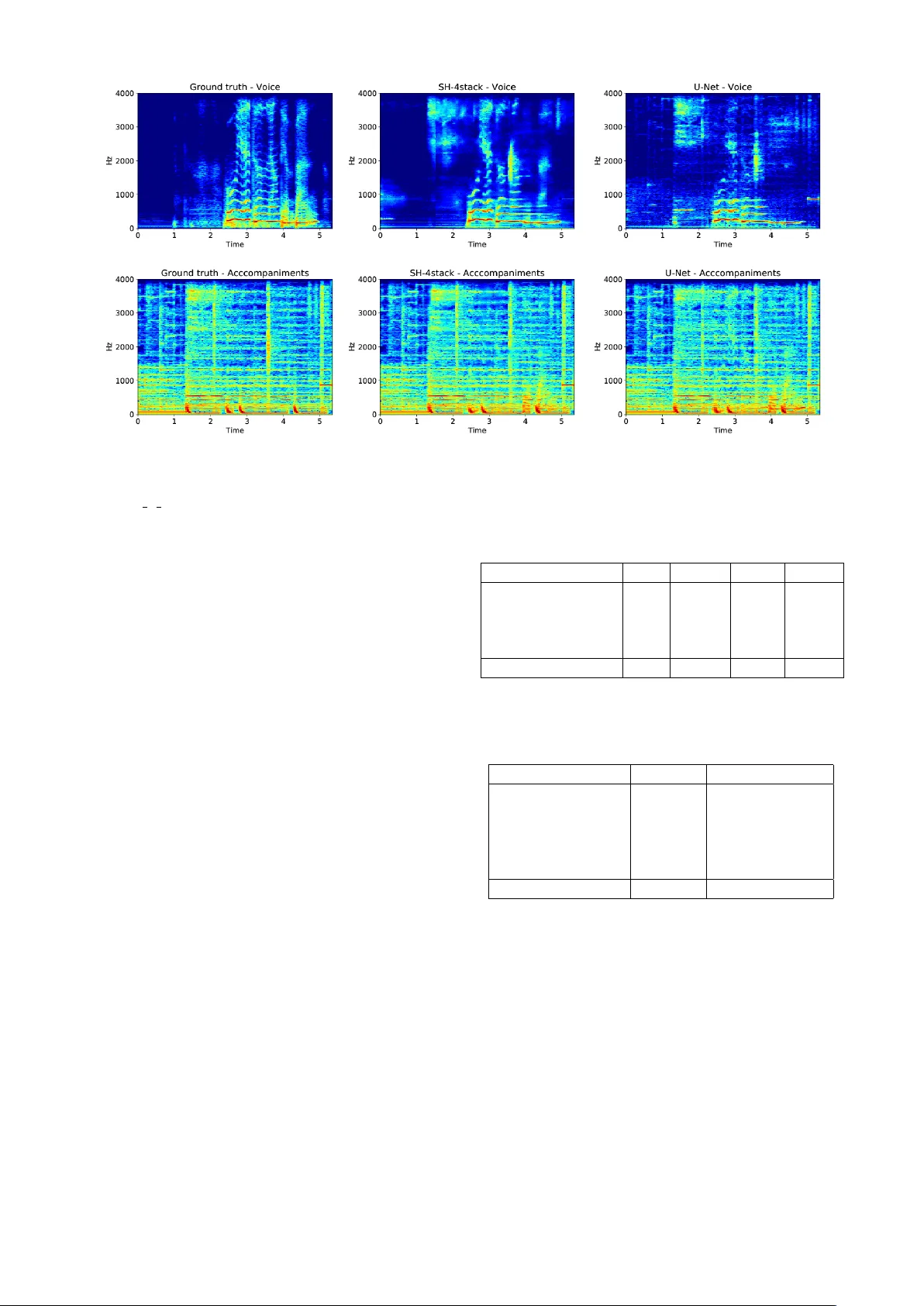
MIR‑1K 결과에서, 4‑스택 모델(SH‑4stack)은 GNSDR 10.51 dB, GSIR 16.01 dB, GSAR 12.53 dB를 기록했으며, 이는 기존 U‑Net(9.82 M 파라미터)보다 파라미터가 적은 8.99 M(컨볼루션만)임에도 불구하고 성능이 우수했다. 또한, 스택 수가 증가할수록 성능이 꾸준히 향상돼, 깊은 네트워크에도 과적합이 발생하지 않음을 확인했다. DSD100 실험에서도 4‑스택 모델이 최신 DenseNet‑ 기반 모델과 비슷하거나 약간 앞서는 결과를 보였다. 정성적 분석에서는 SH‑4stack이 보컬 스펙트로그램에서 미세한 하모닉과 시간적 디테일을 더 잘 복원하고, U‑Net 대비 잡음과 아티팩트가 현저히 적은 것을 확인했다.
결론적으로, 스택드 아워글래스 네트워크는 멀티스케일 피처 학습과 단계별 마스크 정제라는 두 가지 강점을 결합해, 단일 모델로 다중 소스를 효율적으로 분리한다. 파라미터 효율성, 학습 속도, 그리고 성능 면에서 기존 CNN 기반 방법들을 능가하며, 향후 더 많은 소스와 다양한 음악 장르에 대한 확장 가능성을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기