Music Source Separation Using Stacked Hourglass Networks
In this paper, we propose a simple yet effective method for multiple music source separation using convolutional neural networks. Stacked hourglass network, which was originally designed for human pose estimation in natural images, is applied to a mu…
Authors: Sungheon Park, Taehoon Kim, Kyogu Lee
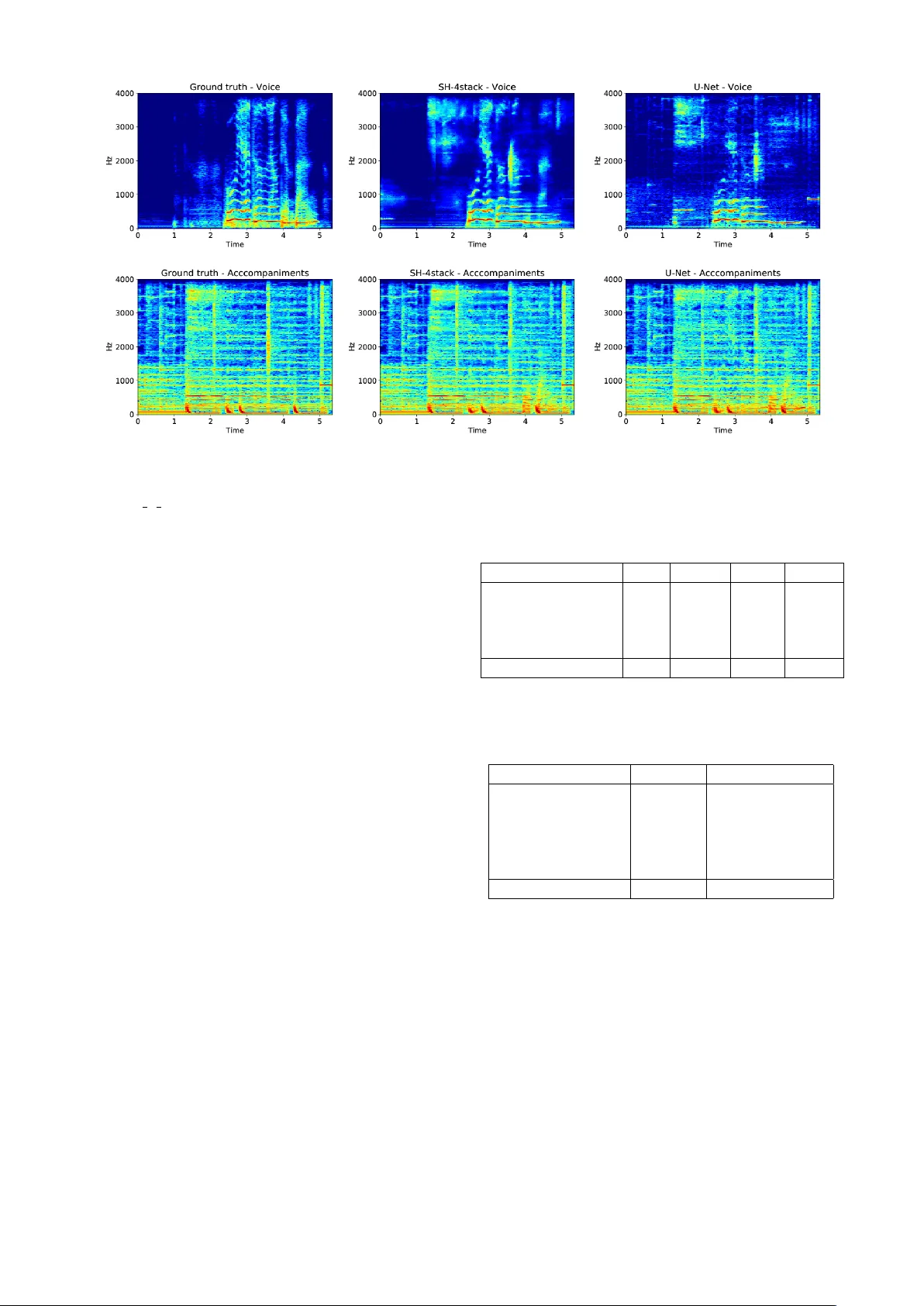
MUSIC SOURCE SEP ARA TION USING ST A CKED HOURGLASS NETWORKS Sungheon Park T aehoon Kim K y ogu Lee Nojun Kwak Graduate School of Con vergence Science and T echnology , Seoul National Uni versity , K orea { sungheonpark, kcjs55, kglee, nojunk } @snu.ac.kr ABSTRA CT In this paper , we propose a simple yet ef fective method for multiple music source separation using conv olutional neural networks. Stacked hourglass network, which was originally designed for human pose estimation in natural images, is applied to a music source separation task. The network learns features from a spectrogram image across multiple scales and generates masks for each music source. The estimated mask is refined as it passes ov er stacked hourglass modules. The proposed frame work is able to separate multiple music sources using a single network. Experimental results on MIR-1K and DSD100 datasets validate that the proposed method achiev es competiti ve re- sults comparable to the state-of-the-art methods in multi- ple music source separation and singing voice separation tasks. 1. INTR ODUCTION Music source separation is one of the fundamental research areas for music information retriev al. Separating singing voice or sounds of individual instruments from a mixture has grabbed a lot of attention in recent years. The separated sources can be further used for applications such as auto- matic music transcription, instrument identification, lyrics recognition, and so on. Recent impro vements on deep neural netw orks (DNNs) hav e been blurring the boundaries between many applica- tion domains, including computer vision and audio sig- nal processing. Due to its end-to-end learning character- istic, deep neural networks that are used in computer vi- sion research can be directly applied to audio signal pro- cessing area with minor modifications. Since the magni- tude spectrogram of an audio signal can be treated as a 2D single-channel image, con volutional neural networks (CNNs) ha ve been successfully used in various music applications, including the source separation task [1, 8]. While v ery deep CNNs are typically used in computer vi- sion literature with v ery lar ge datasets [4, 25], CNNs used c Sungheon Park, T aehoon Kim, K yogu Lee, Nojun Kwak. Licensed under a Creative Commons Attribution 4.0 Interna- tional License (CC BY 4.0). Attrib ution: Sungheon Park, T aehoon Kim, K yogu Lee, Nojun Kw ak. “Music Source Separation Using Stacked Hourglass Netw orks”, 19th International Society for Music Information Retriev al Conference, Paris, France, 2018. for audio source separation so far have relativ ely shallo w architectures. In this paper, we propose a novel music source separa- tion framew ork using CNNs. W e used stacked hourglass network [18] which was originally proposed to solve hu- man pose estimation in natural images. The CNNs take spectrogram images of a music signal as inputs, and gener- ate masks for each music source to separate. An hourglass module captures both holistic features from lo w resolution feature maps and fine details from high resolution feature maps. The module outputs 3D v olumetric data which has the same width and height as those of the input spectro- gram. The number of output channels equals the number of music sources to separate. The module is stacked for multiple times by taking the results of the previous mod- ule. As passing multiple modules, the results are refined and intermediate supervision helps faster learning in the initial state. W e used a single network to separate multiple music sources, which reduces both time and space com- plexity for training as well as testing. W e e valuated our frame work on a couple of source sep- aration tasks: 1) separating singing voice and accompa- niments, and 2) separating bass, drum, vocal, and other sounds from music. The results show that our method outperforms existing methods on MIR-1K dataset [5] and achiev es competitiv e results comparable to state-of-the-art methods on DSD100 dataset [30] despite its simplicity . The rest of the paper is organized as follows. In Sec- tion 2, we briefly revie w the literature of audio source sep- aration focusing on DNN based methods. The proposed source separation frame work and the architecture of the network are explained in Section 3. Experimental results are provided in Section 4, and the paper is concluded in Section 5. 2. RELA TED WORK Non-negati ve matrix factrization (NMF) [12] is one of the most widely-used algorithms for audio source separation. It has been successfully applied to monaural source sepa- rtion [32] and singing v oice separation [29, 38]. Howe ver , despite its generality and flexibility , NMF is inferior to re- cently proposed DNN-based methods in terms of perfor- mance and time complexity . Simple deep feed-forward networks consisting of multi- ple fully-connected layers sho wed reasonable performance for supervised audio source separation tasks [27]. W ang et Figure 1 . Structure of the hourglass module used in this paper . W e follow the structure proposed in [17] e xcept that the number of feature maps are set to 256 for all con volutional layers. al . [34] used DNNs to learn an ideal binary mask which boils the source separation problem down to a binary clas- sification problem. Simpson et al . [24] proposed a con- volutional DNN to predict a probabilistic binary mask for singing voice separation. Recently , a fully comple x-valued DNN [13] is proposed to integrate phase information into the magnitude spectrograms. Deep NMF [11] combined DNN and NMF by designing non-negati ve deep network and its back-propagation algorithm. Since an audio signal is time series data, it is natural to use a sequence model like recurrent neural networks (RNNs) for music source separation tasks to learn tempo- ral information. Huang et al . [6] proposed an RNN frame- work that jointly optimizes masks of foreground and back- ground sources, which showed promising results for var - ious source separation tasks. Other approaches include a recurrent encoder-decoder that exploits gated recurrent unit [15] or discriminativ e RNN [33]. CNNs are also an effecti ve tool for audio signal anal- ysis when the magnitude spectrogram is used as an input. Fully con volutional networks (FCNs) [14] are initially pro- posed for semantic segmentation in the computer vision area, which is also ef fective for solving human pose esti- mation [18, 35] or super -resolution [2]. FCNs usually con- tain downsampling and upsampling layers to learn mean- ingful features at multiple scales. Strided con volution or pooling is used for do wnsampling, while transposed con- volution or nearest neighbor interpolation is mainly used for upsampling. It is prov en that FCNs are also effecti ve in signal processing. Chandna et al . [1] proposed encoder- decoder style FCN for monoaural audio source separation. Recently , singing voice separation using an U-Net archi- tecture [8] showed impressi ve performance. U-Net [22] is a FCN which consists of a series of con volutional lay- ers and upsampling layers. There is a skip connection which connects the con volutional layers of the same res- olution. They trained vocal and accompaniment parts sep- arately on dif ferent networks. Miron et al . [16] proposed the method that separates multiple sources using a single CNN. They used score-filtered spectrograms as inputs and generated masks for each source via an encoder-decoder CNN. Multi-resolution FCN [3] was proposed for monau- ral audio source separation. Recently proposed CNN ar- chitecture [26] based on DenseNet [7] achiev ed state-of- the-art performance on DSD100 dataset. 3. METHOD 3.1 Network Architectur e The stacked hourglass network [18] was originally pro- posed to solve human pose estimation in RGB images. It is an FCN consisting of multiple hour glass modules. The hourglass module is similar to U-Net [22], of which feature maps at lower (coarse) resolution are obtained by repeat- edly applying conv olution and pooling operations. Then, the feature maps at the lowest resolution are upsampled via nearest neighbor interpolation with a preceding con- volutional layer . Feature maps at the same resolution in the do wnsampling and the upsampling steps are connected with an additional con volutional layer . The hourglass mod- ule captures features at different scales by repeating pool- ing and upsampling with con volutional layers at each reso- lution. In addition, multiple hourglass modules are stacked to make the network deeper . As more hourglass modules are stacked, the network learns more powerful and infor- mativ e features which refine the estimation results. Loss functions are applied at the end of each module. This in- termediate supervision improv es training speed and perfor- mance of the network. The structure of a single hourglass module used in this paper is illustrated in Fig 1. Considering the ef ficiency and the size of the network, we adopt the hourglass module used in [17] which is a smaller network than the origi- nally proposed one in [18]. A notable difference is that the residual blocks [4] used in [18] are replaced with a sin- gle con volutional layer . This light-weight structure showed competitiv e performance to the original netw ork in human pose estimation with much smaller number of parameters. In the module, there are four downsampling and upsam- pling steps. All conv olutional layers in downsampling and upsampling steps ha ve filter size of 3 × 3 . The 2 × 2 max pooling is used to halve the size of the feature maps, and the nearest neighbor interpolation is used to double the size of the feature maps in the upsampling steps. W e fixed the size of the maximum feature maps in con volutional layers to 256 which is dif ferent from [17]. After the last upsam- pling layer , a single 3 × 3 conv olution and two 1 × 1 con- volution is performed to generate network outputs. Then, an 1 × 1 con volution is applied to the outputs to match the number of channels to that of the input feature maps. An- other 1 × 1 conv olution is also applied to the feature maps Figure 2 . Overall music source separation framework proposed in this paper . Multiple hourglass modules are stack ed, and each module outputs masks for each music source. The masks are multiplied with the input spectrogram to generate pre- dicted spectrograms. Differences between the estimated spectrograms and the ground truth ones are used as loss functions of the network. which used for output generation. Finally , the tw o feature maps that passed the respecti ve 1 × 1 con volution and the input of the hourglass module is added together , and the re- sulting feature map is used as an input to the next hourglass module. In the network used in this paper, input image firstly passes through initial con volutional layers that consist of a 7 × 7 con volutional layer and four 3 × 3 con volutional lay- ers where the number of output feature maps for each layer is 64, 128, 128, 128, and 256 respectively . T o make the output mask and the input spectrogram have the same size, we did not use the pooling operations in the initial con vo- lutional layers before the hourglass module. The feature maps generated from the initial layers are fed to the first hourglass module. The proposed o verall music source sep- aration framew ork is depicted in Fig. 2. 3.2 Music Source Separation As shown in Fig. 2, to apply the stacked hourglass network to music source separation, we aim to train the network to output soft masks for each music source given the magni- tude spectrogram of the mixed source. Hence, the output dimension of the netw ork is H × W × C where H and W are the height and width of the input spectrogram respec- tiv ely , and C is the number of music sources to separate. The magnitude spectrogram of separated music source is obtained by multiplying the mask and the input spectro- gram. Our framework is scalable in that it requires almost no additional operation as the number of sources increases. The input for the network is the magnitude of spectro- gram obtained from Short-Time Fourier T ransform (STFT) with a window size of 1024 and a hop size of 256. The input source is downsampled to 8kHz to increase the du- ration of spectrograms in a batch and to speed up training. For each sample, magnitude spectrograms of mixed and separated sources are generated, which are divided by the maximum value of the mixed spectrogram for data normal- ization. The spectrograms have 512 frequency bins and the width of the spectrogram depends on the duration of the music sources. F or all the music sources, the width of the spectrogram is at least 64. Thus, we fix the size of an input spectrogram to 512 × 64 . Hence, the size of the feature maps at the lowest resolution is 32 × 4 . Starting time index is randomly chosen when the input batches are created. Follo wing [22], we designed the loss function as an L 1 , 1 norm of the difference between the ground truth spec- trogram and the estimated spectrogram. More concretely , giv en an input spectrogram X , i th ground truth music source Y i , and the generated mask for the i th source in the j th hourglass module ˆ M ij , the loss for the i th source is defined as J ( i, j ) = k Y i − X ˆ M ij k 1 , 1 , (1) where denotes element-wise multiplication of the ma- trix. L 1 , 1 norm is calculated as the sum of absolute values of matrix elements. The loss function of the network be- comes J = C X i =1 D X j =1 J ( i, j ) , (2) where D is the number of hourglass modules stacked in the network. W e directly used the output of the last 1 × 1 con- volutional layer as the mask, which is different from [22] where they used the sigmoid acti vation to generate masks. While it is natural to use the sigmoid function to restrict the v alue of the mask to [0,1], we empirically found that not applying the sigmoid function boosts the training speed and improv es the performance. Since sigmoid acti vations vanish the gradient of the inputs that hav e large absolute values, they may diminish the ef fect of intermediate super- vision. W e ha ve stacked hour glass modules up to four and pro- vide analysis of the effect of stacking multiple modules in Section 4. The network is trained using Adam opti- mizer [10] with a starting learning rate of 10 − 4 and a batch size of 4. W e trained the network for 15,000 and 150,000 iterations for MIR-1K dataset and DSD100 dataset respec- tiv ely , and the learning rate is decreased to 2 × 10 − 5 when 80% of the training is finished. No data augmentation is applied during training. The training took 3 hours for MIR- 1K dataset and 31 hours for DSD100 dataset using a single GPU when the biggest model is used. For the singing voice separation task, C is set to 2 which corresponds to vocal and accompaniments . For the music source separation task in DSD100 dataset, C = 4 is used where each output mask corresponds to drum , bass , vocal , and others . While it can be adv antageous in terms of performance to train a net- work for a single source individually , it is computationally expensi ve to train a deep CNN for each source. Therefore, we trained a single network for each task. In the test phase, the magnitude spectrogram of the in- put source is cropped to network input size and fed to the network sequentially . The output of the last hour glass module is used for testing. W e set the negati ve values of output masks to 0 in order to av oid negativ e magnitude values. The masks are multiplied by the normalized mag- nitude spectrogram of the test source and unnormalized to generate spectrograms of separated sources. W e did not change the phase spectrogram of the input source, and it is combined with the estimated magnitude spectrogram to retriev e signals for separated sources via in verse STFT . 4. EXPERIMENTS W e e valuated performance of the proposed method on MIR-1K and DSD100 datasets. For quantitative ev alua- tion, we measured signal-to-distortion ratio (SDR), source- to-interference ratio (SIR), and source-to-artifacts ratio (SAR) based on BSS-EV AL metrics [31]. Normalized SDR (NSDR) [20] is also measured for the singing voice separation task which measures improv ement between the mixture and the separated source. The values are obtained using mir -ev al toolbox [21]. Global NSDR (GNSDR), global SIR (GSIR), and global SAR (GSAR) are calcu- lated as a weighted mean of NSDR, SIR, and SAR respec- tiv ely whose weights are length of the source. The sepa- rated sources generated from the network are upsampled to the original sampling rate of the dataset and compared with ground truth sources for all experiments. 4.1 MIR-1K dataset MIR-1K dataset is designed for singing voice separation research. It contains a thousand song clips extracted from 110 Chinese karaoke songs at a sampling rate of 16kHz. Follo wing the previous works [6, 37], we used one male and one female ( abjones and amy ) as a training set which contains 175 clips in total. The remaining 825 clips are used for e valuation. For the baseline CNN, we trained the FCN that has U-Net [22]-like structure and ev aluated its Singing voice Method GNSDR GSIR GSAR MLRR [37] 3.85 5.63 10.70 DRNN [6] 7.45 13.08 9.68 ModGD [23] 7.50 13.73 9.45 U-Net [8] 7.43 11.79 10.42 SH-1stack 10.29 15.51 12.46 SH-2stack 10.45 15.89 12.49 SH-4stack 10.51 16.01 12.53 Accompaniments Method GNSDR GSIR GSAR MLRR [37] 4.19 7.80 8.22 U-Net [8] 7.45 11.43 10.41 SH-1stack 9.65 13.90 12.27 SH-2stack 9.64 13.69 12.39 SH-4stack 9.88 14.24 12.36 T able 1 . Quantitativ e ev aluation of singing voice separa- tion on MIR-1K dataset. performance. W e followed the structure of [8], in which singing voice and accompaniments are trained on differ - ent networks. For the stacked hourglass networks, both singing voice and accompaniments are obtained from a sin- gle network. The e valuation results on test sets are sho wn in T able 1. W e trained the networks with varying number of stacked hourglass modules 1, 2, and 4. It is proven that our stacked hourglass network (SH) significantly outperforms e xisting methods in all e valuation criteria. Our method gains 3.01 dB in GNSDR, 2.28 dB in GSIR, and 1.83 dB in GSAR compared to the best results of the existing methods. It is also prov en that the structure of the stacked hourglass module is more efficient and beneficial than U-Net [8] for music source separation. U-Net has 9.82 million parame- ters while single stack hour glass netw ork has 8.99 million parameters considering only con volutional layers. Even with the absence of batch normalization, smaller number of parameters, and multi-source separation in a single net- work, the stacked hourglass network showed superior per- formance to U-Net. While the network with a single hour- glass module sho ws outstanding source separation per- formance, even better results are provided when multiple hourglass modules are stacked. This indicates that SH net- work does not ov erfit e ven when the network gets deeper despite small amount of the training data. Our method pro- vides good performance on separating both singing voice and accompaniments with a single forward step. Qualitativ e results of our method and comparison with U-Net are sho wn in Fig. 3. The estimated log spectrograms of singing v oice and accompaniments from SH-4stack and U-Net and the ground truth log spectrograms are provided. It can be seen that our method captures fine details and harmonics compared to the U-Net. The voice spectrogram from U-Net has more artifacts in the time slot of 0 ∼ 1 and 4 ∼ 5 compared to the result of SH-4stack. On the other Figure 3 . Qualitati ve comparison of our method (SH-4stack) and U-Net for singing voice and accompaniments separation on annar 3 05 in MIR-1K dataset. Ground truth and estimated spectrograms are displayed in a log-scale. Our method is superior in capturing fine details compared to U-Net. hand, harmonics from v oice signals can be clearly seen in the spectrogram of SH-4stack. For accompaniments spec- trogram, it is observed that U-Net contains voice signals around the time slot of 3. 4.2 DSD100 dataset DSD100 dataset consists of 100 songs that are di vided into 50 training sets and 50 test sets. For each song, four dif fer- ent music sources, bass, drums, v ocals, and other as well as their mixtures are provided. The sources are stereophonic sound with a sampling rate of 44.1kHz. W e conv erted all sources to monophonic and performed single channel source separation using stacked hourglass networks. W e used a 4-stacked hourglass network (SH-4stack) for the ex- periments. The performance of music source separation using stacked hourglass network is provided in T able 2. W e mea- sured SDR of the separated sources for all test songs and report median values for comparison with existing meth- ods. The methods that use single channel inputs are com- pared to our method. While the stack ed hourglass netw ork giv es second-best performance following the state-of-the- art methods [26] for drums and vocals, it shows poor per- formance for separating bass and other . This is mainly due to the similarity between bass and guitar sound in other sources, which confuses the network especially when trained together in a single network. Since the losses for all sources are summed up with equal weights, the network tends to be trained to improv e the separation performance of vocal and drum, which is easier than separating bass and other sources. Next, we trained the stacked hourglass network for a Method Bass Drums Other V ocals dNMF [36] 0.91 1.87 2.43 2.56 DeepNMF [11] 1.88 2.11 2.64 2.75 BLEND [28] 2.76 3.93 3.37 5.13 MM-DenseNet [26] 3.91 5.37 3.81 6.00 SH-4stack 1.77 4.11 2.36 5.16 T able 2 . Median SDR values for music source separation on DSD100 dataset. Method V ocals Accompaniments DeepNMF [11] 2.75 8.90 wRPCA [9] 3.92 9.45 NUG [19] 4.55 10.29 BLEND [28] 5.23 11.70 MM-DenseNet [26] 6.00 12.10 SH-4stack 5.45 12.14 T able 3 . Median SDR values for singing voice separation on DSD100 dataset. singing voice separation task. The three sources e xcept v o- cals are mixed together to form accompaniments source. The median SDR values for each source are reported in T able 3. Our method achiev ed best result for accompa- niments separation and second-best for vocal separation. Separation performance of vocals is impro ved compared to the music source separation setting. It can be inferred that the stacked hourglass network provides better results as number of sources are smaller and the separating sources are more distinguishable from each other . Figure 4 . Examples sho wing the effecti veness of stacking multiple hourglass modules. Ground truth and estimated spec- trograms of the part of the song Schoolboy F ascination in DSD100 dataset are shown. SDR values of the source generated from the spectrograms obtained from first, second, fourth hourglass module are 10.90, 12.50, 13.30 respectively . Espe- cially , it is observed that the estimated spectrogram captures fine details of spectrogram at lo w frequency range ( 0 ∼ 500 Hz) as more hourglass modules are stack ed. Lastly , we inv estigate how the stacked hourglass net- work improv es the output masks as they pass through the hourglass modules within the network. The example illus- trated in Fig. 4 shows the estimated voice spectrogram of first, second, and fourth hour glass module with the ground truth spectrogram from one of the test sets of DSD 100 dataset. It is observed that the estimated spectrogram be- comes more similar to the ground truth as it is generated from a deeper side of the network. In the result of the fourth hourglass module, spectrograms at low frequency are clearly recovered compared to the result of the first hourglass module. The artifacts in the range of 2000 ∼ 3000 Hz are also remov ed. Although it is hard to recognize the difference in the spectrogram image, the difference of SDR between the source estimated from the first hourglass mod- ule and the last hourglass module is about 2.4dB which is a significant performance gain. 5. CONCLUSION In this paper, we proposed music source separation algo- rithm using stacked hour glass networks. The network suc- cessfully captures features at both coarse and fine resolu- tion, and it produces masks that are applied to the input spectrograms. Multiple hourglass modules refines the esti- mation results and outputs the better results. Experimental results has proven the ef fectiveness of the proposed frame- work for music source separation. W e implemented the framew ork in its simplest form, and there is a lot of room for performance improvements including data augmenta- tion, regularization of CNNs, and ensemble learning of multiple models. Designing a loss function that consid- ers correlation of dif ferent sources may further improves the performance. 6. A CKNO WLEDGEMENT This work was supported by Next-Generation Information Computing Development Program through the National Research Foundation of K orea (2017M3C4A7077582). 7. REFERENCES [1] Pritish Chandna, Marius Miron, Jordi Janer , and Emilia G ´ omez. Monoaural audio source separation using deep con volutional neural networks. In International Con- fer ence on Latent V ariable Analysis and Signal Sepa- ration , pages 258–266. Springer , 2017. [2] Chao Dong, Chen Change Loy , Kaiming He, and Xi- aoou T ang. Image super-resolution using deep conv o- lutional networks. IEEE tr ansactions on pattern anal- ysis and mac hine intelligence , 38(2):295–307, 2016. [3] Emad M Grais, Hagen Wierstorf, Dominic W ard, and Mark D Plumbley . Multi-resolution fully con volutional neural networks for monaural audio source separation. arXiv pr eprint arXiv:1710.11473 , 2017. [4] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In Pr oceedings of the IEEE confer ence on computer vi- sion and pattern r ecognition , pages 770–778, 2016. [5] C. L. Hsu and J. S. R. Jang. On the improvement of singing voice separation for monaural recordings using the mir -1k dataset. IEEE T ransactions on Au- dio, Speech, and Language Pr ocessing , 18(2):310– 319, Feb 2010. [6] Po-Sen Huang, Minje Kim, Mark Hasegaw a-Johnson, and Paris Smaragdis. Joint optimization of masks and deep recurrent neural networks for monaural source separation. IEEE/ACM T ransactions on A udio, Speec h, and Languag e Pr ocessing , 23(12):2136–2147, 2015. [7] Forrest Iandola, Matt Moske wicz, Serge y Karayev , Ross Girshick, Tre vor Darrell, and Kurt Keutzer . Densenet: Implementing efficient convnet descriptor pyramids. arXiv pr eprint arXiv:1404.1869 , 2014. [8] Andreas Jansson, Eric Humphre y , Nicola Montecchio, Rachel Bittner , Aparna Kumar , and T illman W eyde. Singing voice separation with deep u-net con volutional networks. 18th International Society for Music Infor- mation Retrieval Conferenceng, Suzhou, China , 2017. [9] Il-Y oung Jeong and K yogu Lee. Singing voice separa- tion using rpca with weighted l { 1 } -norm. In Inter- national Conference on Latent V ariable Analysis and Signal Separation , pages 553–562. Springer , 2017. [10] Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980 , 2014. [11] Jonathan Le Roux, John R Hershey , and Felix W eninger . Deep nmf for speech separation. In Acous- tics, Speech and Signal Pr ocessing (ICASSP), 2015 IEEE International Confer ence on , pages 66–70. IEEE, 2015. [12] Daniel D Lee and H Sebastian Seung. Algorithms for non-negati ve matrix factorization. In Advances in neu- ral information pr ocessing systems , pages 556–562, 2001. [13] Y uan-Shan Lee, Chien-Y ao W ang, Shu-Fan W ang, Jia- Ching W ang, and Chung-Hsien W u. Fully complex deep neural network for phase-incorporating monau- ral source separation. In Acoustics, Speech and Signal Pr ocessing (ICASSP), 2017 IEEE International Con- fer ence on , pages 281–285. IEEE, 2017. [14] Jonathan Long, Evan Shelhamer , and Tre vor Darrell. Fully con volutional networks for semantic segmenta- tion. In Pr oceedings of the IEEE confer ence on com- puter vision and pattern recognition , pages 3431– 3440, 2015. [15] Stylianos Ioannis Mimilakis, K onstantinos Drossos, T uomas V irtanen, and Gerald Schuller . A recurrent encoder-decoder approach with skip-filtering connec- tions for monaural singing voice separation. CoRR , abs/1709.00611, 2017. [16] Marius Miron, Jordi Janer , and Emilia G ´ omez. Monau- ral score-informed source separation for classical mu- sic using conv olutional neural networks. In 18th Inter- national Society for Music Information Retrie val Con- fer ence, Suzhou, China , 2017. [17] Alejandro Ne well, Zhiao Huang, and Jia Deng. Asso- ciativ e embedding: End-to-end learning for joint detec- tion and grouping. In Advances in Neural Information Pr ocessing Systems , pages 2274–2284, 2017. [18] Alejandro Newell, Kaiyu Y ang, and Jia Deng. Stacked hourglass networks for human pose estimation. In Eu- r opean Conference on Computer V ision , pages 483– 499. Springer , 2016. [19] Aditya Arie Nugraha, Antoine Liutkus, and Em- manuel V incent. Multichannel music separation with deep neural networks. In Signal Pr ocessing Confer ence (EUSIPCO), 2016 24th Eur opean , pages 1748–1752. IEEE, 2016. [20] Alex ey Ozerov , Pierrick Philippe, Frdric Bimbot, and Rmi Gribon val. Adaptation of bayesian models for single-channel source separation and its application to voice/music separation in popular songs. IEEE T rans- actions on Audio, Speech, and Language Pr ocessing , 15(5):1564–1578, 2007. [21] Colin Raffel, Brian McFee, Eric J Humphrey , Justin Salamon, Oriol Nieto, Da wen Liang, Daniel PW Ellis, and C Colin Raffel. mir ev al: A transparent implemen- tation of common mir metrics. In In Pr oceedings of the 15th International Society for Music Information Re- trieval Confer ence, ISMIR . Citeseer , 2014. [22] Olaf Ronneber ger , Philipp Fischer , and Thomas Brox. U-net: Con volutional networks for biomedical image segmentation. In International Conference on Medical image computing and computer-assisted intervention , pages 234–241. Springer , 2015. [23] Jilt Sebastian and Hema A Murthy . Group delay based music source separation using deep recurrent neural networks. In Signal Pr ocessing and Communications (SPCOM), 2016 International Conference on , pages 1– 5. IEEE, 2016. [24] Andre w JR Simpson, Gerard Roma, and Mark D Plumbley . Deep karaoke: Extracting vocals from mu- sical mixtures using a conv olutional deep neural net- work. In International Conference on Latent V ari- able Analysis and Signal Separation , pages 429–436. Springer , 2015. [25] Christian Szegedy , Serge y Ioffe, V incent V anhoucke, and Alexander A Alemi. Inception-v4, inception-resnet and the impact of residual connections on learning. In AAAI , volume 4, page 12, 2017. [26] Naoya T akahashi and Y uki Mitsufuji. Multi-scale multi-band densenets for audio source separation. In Applications of Signal Pr ocessing to Audio and Acous- tics (W ASP AA), 2017 IEEE W orkshop on , pages 21–25. IEEE, 2017. [27] Stefan Uhlich, Franck Giron, and Y uki Mitsufuji. Deep neural network based instrument extraction from music. In Acoustics, Speech and Signal Pr ocessing (ICASSP), 2015 IEEE International Confer ence on , pages 2135–2139. IEEE, 2015. [28] Stefan Uhlich, Marcello Porcu, Franck Giron, Michael Enenkl, Thomas K emp, Naoya T akahashi, and Y uki Mitsufuji. Improving music source separation based on deep neural networks through data augmentation and network blending. In Acoustics, Speech and Signal Pr ocessing (ICASSP), 2017 IEEE International Con- fer ence on , pages 261–265. IEEE, 2017. [29] Shankar V embu and Stephan Baumann. Separation of vocals from polyphonic audio recordings. In ISMIR , pages 337–344. Citeseer , 2005. [30] Emmanuel V incent, Shoko Araki, Fabian Theis, Guido Nolte, P au Bofill, Hiroshi Sawada, Alexey Oze- rov , V ikrham Gowreesunker , Dominik Lutter , and Ngoc QK Duong. The signal separation ev aluation campaign (2007–2010): Achiev ements and remain- ing challenges. Signal Pr ocessing , 92(8):1928–1936, 2012. [31] Emmanuel V incent, R ´ emi Gribon val, and C ´ edric F ´ evotte. Performance measurement in blind audio source separation. IEEE transactions on audio, speech, and language pr ocessing , 14(4):1462–1469, 2006. [32] T uomas V irtanen. Monaural sound source separation by nonnegati ve matrix f actorization with temporal con- tinuity and sparseness criteria. IEEE transactions on audio, speech, and language pr ocessing , 15(3):1066– 1074, 2007. [33] Guan-Xiang W ang, Chung-Chien Hsu, and Jen-Tzung Chien. Discriminativ e deep recurrent neural networks for monaural speech separation. In Acoustics, Speech and Signal Pr ocessing (ICASSP), 2016 IEEE Interna- tional Conference on , pages 2544–2548. IEEE, 2016. [34] Y uxuan W ang, Arun Narayanan, and DeLiang W ang. On training targets for supervised speech separation. IEEE/A CM T ransactions on Audio, Speech and Lan- guage Processing (TASLP) , 22(12):1849–1858, 2014. [35] Shih-En W ei, V arun Ramakrishna, T akeo Kanade, and Y aser Sheikh. Con volutional pose machines. In Pr o- ceedings of the IEEE Confer ence on Computer V ision and P attern Recognition , pages 4724–4732, 2016. [36] Felix W eninger , Jonathan Le Roux, John R Hershey , and Shinji W atanabe. Discriminativ e nmf and its appli- cation to single-channel source separation. In F ifteenth Annual Conference of the International Speech Com- munication Association , 2014. [37] Y i-Hsuan Y ang. Lo w-rank representation of both singing voice and music accompaniment via learned dictionaries. In ISMIR , pages 427–432, 2013. [38] Xiu Zhang, W ei Li, and Bilei Zhu. Latent time- frequency component analysis: A novel pitch-based approach for singing voice separation. In Acoustics, Speech and Signal Pr ocessing (ICASSP), 2015 IEEE International Conference on , pages 131–135. IEEE, 2015.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment