다중스케일 CNN과 LSTM을 결합한 효율적 오디오 소스 분리 모델
본 논문은 기존의 다중스케일·다중밴드 DenseNet(MMDenseNet)에 장기 의존성을 포착할 수 있는 LSTM 모듈을 다중 스케일에 삽입한 MMDenseLSTM을 제안한다. LSTM을 저해상도 스케일에만 배치함으로써 파라미터 수와 연산량을 최소화하면서도 전역적인 시간‑주파수 구조를 효과적으로 학습한다. DSD100·MUSDB18 데이터셋에서 기존 MMDenseNet 및 BLSTM 대비 SDR 향상을 보였으며, 대규모 학습 시 이상적인 이진…
저자: Naoya Takahashi, Nabarun Goswami, Yuki Mitsufuji
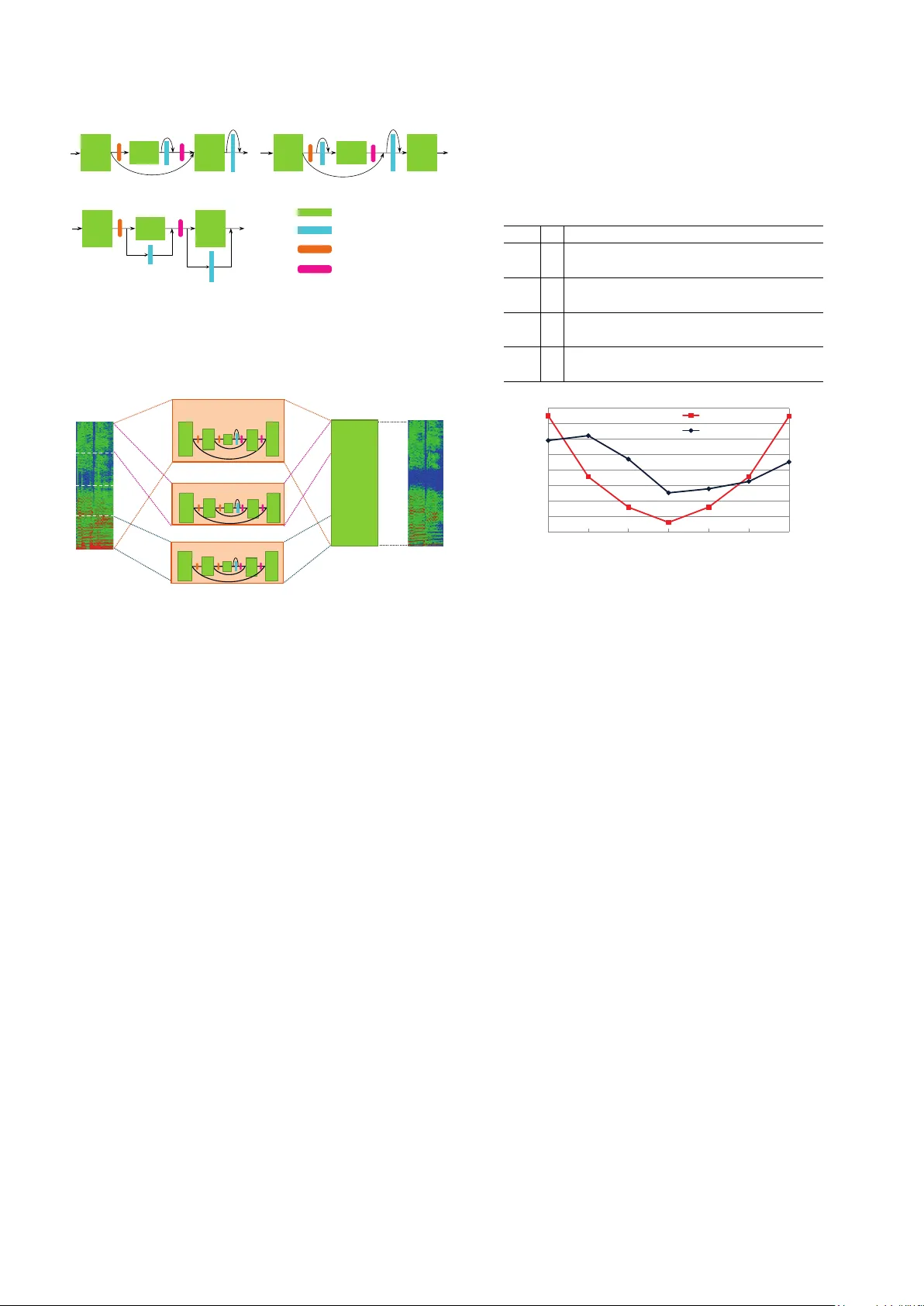
본 논문은 오디오 소스 분리(ASS) 분야에서 딥러닝 기반 모델의 성능을 한 단계 끌어올리기 위해, 기존의 다중스케일·다중밴드 DenseNet 구조(MMDenseNet)에 장기 의존성을 모델링할 수 있는 LSTM을 다중 스케일에 통합한 새로운 아키텍처 MMDenseLSTM을 제안한다.
1. **배경 및 동기**
- 전통적인 ASS 방법은 Gaussian 모델링, NMF, 커널 가법 모델 등이다. 최근에는 FNN, BLSTM, CNN 등 다양한 DNN이 도입돼 성능이 크게 향상되었다.
- CNN은 파라미터 공유와 지역 패턴 학습에 강점이 있지만, 긴 시간 컨텍스트를 포착하려면 깊은 네트워크가 필요해 학습이 어려워진다.
- LSTM은 시계열 데이터를 효과적으로 처리하지만, 전체 해상도에 적용하면 파라미터가 급증하고 학습이 느려진다.
2. **MMDenseNet 요약**
- DenseNet의 dense connectivity를 활용해 각 레이어가 이전 모든 레이어의 출력을 concat한다.
- 멀티스케일 구조: 다운샘플링을 통해 저해상도 특징을 추출하고, 업샘플링을 통해 원래 해상도로 복원한다. 스킵 연결을 통해 정보 흐름을 원활히 한다.
- 멀티밴드: 주파수 대역을 여러 밴드로 나누어 각각 전용 MDenseNet을 적용, 전역적인 밴드와 로컬 밴드의 특성을 동시에 학습한다.
3. **LSTM과의 결합 전략**
- LSTM 블록은 1×1 Conv → 양방향 LSTM → 선형 변환 순으로 구성된다.
- 세 가지 결합 방식: Sa(밀집 블록 뒤에 LSTM), Sb(밀집 블록 앞에 LSTM), P(병렬 결합). 실험 결과 Sa가 가장 높은 SDR을 기록했다.
- 파라미터 효율성을 위해 LSTM 블록은 저해상도 스케일(s > 1)에서만 삽입하고, 고해상도(s = 1)에서는 순수 DenseNet만 사용한다. 이렇게 하면 전역적인 시간 패턴을 LSTM이 담당하고, 세밀한 주파수‑시간 로컬 패턴은 DenseNet이 담당한다.
4. **구체적인 아키텍처**
- 입력 스펙트로그램을 0 ~ 4 kHz, 4 ~ 11 kHz, 11 ~ 22 kHz 세 밴드와 전체 밴드로 분할한다.
- 각 밴드마다 독립적인 MDenseLSTM을 구성하고, 최종 단계에서 모든 밴드의 출력을 concat한 뒤 마지막 Dense 블록을 통해 최종 마스크를 생성한다.
- 전체 모델 파라미터는 1.22 M이며, 효과적인 컨텍스트 크기는 356 프레임이다.
5. **실험 설정**
- 데이터셋: DSD100(Dev 50 곡, Test 50 곡) 및 MUSDB18(Dev 100 곡, Test 50 곡).
- 입력: 4096‑점 STFT magnitude, 75 % 오버랩, 데이터 증강 적용.
- 손실 함수: 평균 제곱 오차(MSE), 최적화: Adam.
- 평가: SDR(신호‑대‑잡음비) 평균값, BSSEval 및 museval 툴킷 사용.
6. **결과 및 분석**
- **구성 비교**: Sa(2.83 dB), Sb(2.31 dB), P(2.47 dB) – Sa가 가장 우수.
- **스케일별 LSTM 삽입 효과**: 저해상도 스케일에 LSTM을 삽입했을 때 파라미터 증가율이 10 % 이하이면서 MSE가 크게 감소, 고해상도에 삽입하면 파라미터가 급증하고 성능이 오히려 감소.
- **DSD100 결과**: MMDenseLSTM(베이스 3.73 dB, 드럼 5.46 dB, 기타 4.33 dB, 보컬 6.31 dB, 전체 12.73 dB) – 기존 MMDenseNet(12.10 dB)보다 평균 0.2 dB 향상.
- **MUSDB18 결과**: 파라미터 1.22 M, SDR(전체 16.40 dB)로 BLSTM(14.51 dB)·MMDenseNet(15.41 dB)·BLEND2(16.04 dB)를 모두 능가. IBM(10.83 dB)보다도 높은 성능을 보이며, 특히 반주(Acc.)에서 IBM을 초과.
- **대규모 학습**: 내부 800곡 데이터와 MUSDB18을 합친 900곡으로 학습했을 때, 평균 0.43 dB(베이스 제외) 향상.
7. **장점 및 한계**
- **장점**: 파라미터 효율성(전통적인 BLSTM·MMDenseNet 블렌드 대비 24배 적음), 연산 속도 향상, 멀티스케일 LSTM을 통한 전역‑로컬 특성 통합, 기존 최첨단 모델 대비 일관된 SDR 향상.
- **한계**: 베이스 영역에서 개선 폭이 작아 저주파 전용 모듈 필요, 위상 복원 및 멀티채널 상황에 대한 확장 필요, 현재는 마스크 기반 추정에 국한.
8. **결론**
MMDenseLSTM은 다중스케일·다중밴드 CNN과 LSTM을 효율적으로 결합함으로써, 파라미터 수와 연산량을 최소화하면서도 전역적인 시간‑주파수 구조를 효과적으로 학습한다. DSD100·MUSDB18에서의 실험 결과는 기존 최고 성능을 능가함을 보여주며, 특히 대규모 데이터 학습 시 이상적인 이진 마스크보다도 높은 성능을 달성한다. 향후 베이스 전용 처리와 멀티채널 확장 등을 통해 더욱 실용적인 시스템으로 발전시킬 여지가 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기