MMDenseLSTM: An efficient combination of convolutional and recurrent neural networks for audio source separation
Deep neural networks have become an indispensable technique for audio source separation (ASS). It was recently reported that a variant of CNN architecture called MMDenseNet was successfully employed to solve the ASS problem of estimating source ampli…
Authors: Naoya Takahashi, Nabarun Goswami, Yuki Mitsufuji
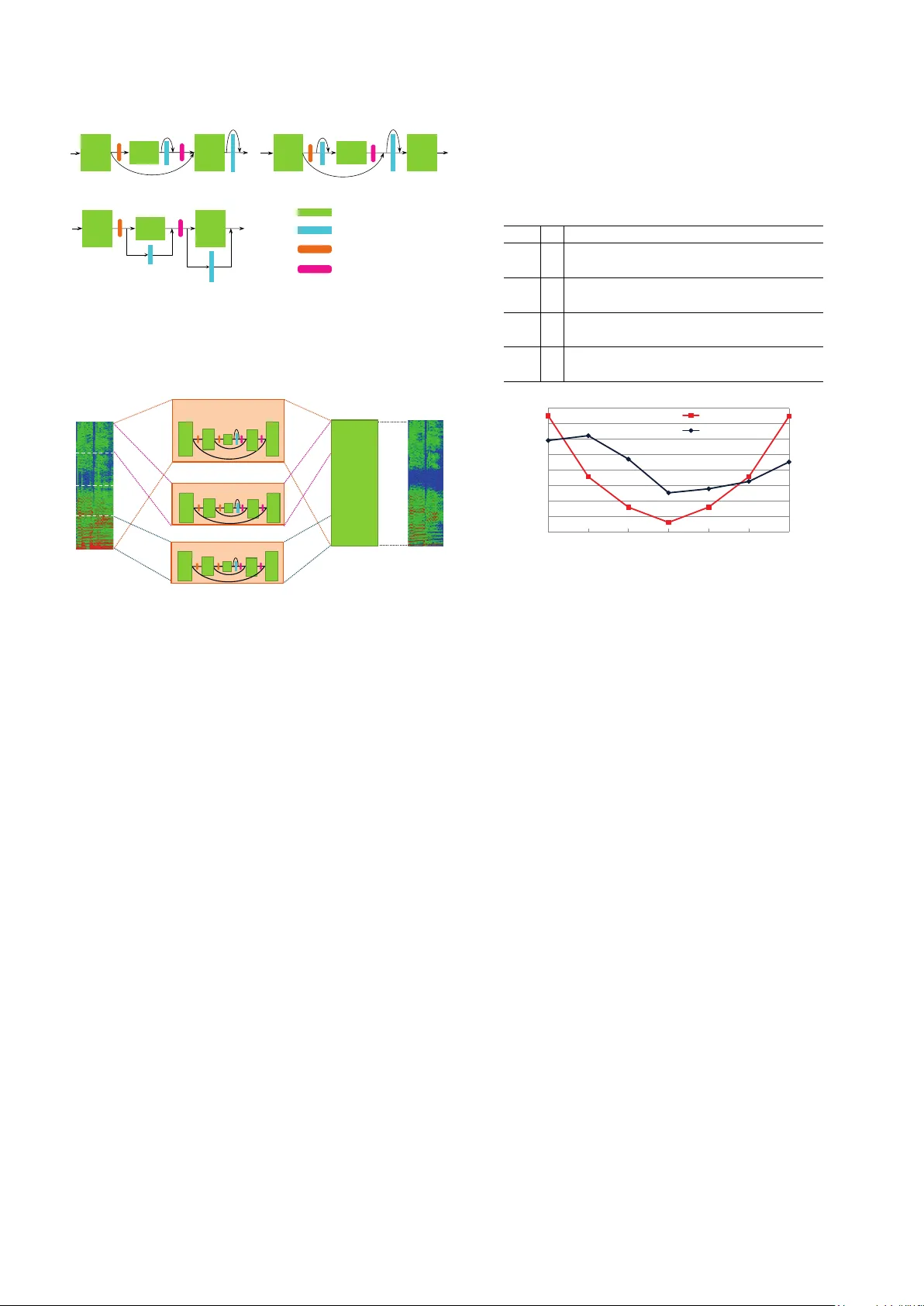
MMDENSELSTM: AN EFFICIENT COMBINA TION OF CONV OLUTIONAL AND RECURRENT NEURAL NETWORKS FOR A UDIO SOURCE SEP ARA TION Naoya T akahashi 1 , Nabarun Goswami 2 , Y uki Mitsufuji 1 1 Sony Corporation, Minato-ku, T okyo, Japan 2 Sony India Softw are Centre, Bangalore, India ABSTRA CT Deep neural networks ha ve become an indispensable tech- nique for audio source separation (ASS). It was recently reported that a variant of CNN architecture called MM- DenseNet was successfully employed to solve the ASS prob- lem of estimating source amplitudes, and state-of-the-art re- sults were obtained for DSD100 dataset. T o further enhance MMDenseNet, here we propose a novel architecture that in- tegrates long short-term memory (LSTM) in multiple scales with skip connections to ef ficiently model long-term struc- tures within an audio context. The e xperimental results sho w that the proposed method outperforms MMDenseNet, LSTM and a blend of the two networks. The number of parameters and processing time of the proposed model are significantly less than those for simple blending. Furthermore, the pro- posed method yields better results than those obtained using ideal binary masks for a singing voice separation task. Index T erms — con volution, recurrent, DenseNet, LSTM, audio source separation 1. INTR ODUCTION Audio source separation (ASS) has recently been intensiv ely studied. V arious approaches ha ve been introduced such as lo- cal Gaussian modeling [1, 2], non-negativ e factorization [3– 5], kernel additiv e modeling [6] and their combinations [7– 9]. Recently , deep neural network (DNN) based ASS meth- ods have sho wn a significant improv ement ov er con ventional methods. In [10, 11], a standard feedforw ard fully connected network (FNN) was used to estimate source spectra. A com- mon way to exploit temporal contexts is to concatenate mul- tiple frames as the input. Ho wever , the number of frames that can be used is limited in practice to av oid the explosion of the model size. In [12], long short-term memory (LSTM), a type of recurrent neural network (RNN), was used to model longer contexts. Howe ver , the model size tends to become excessi vely large and the training becomes slo w owing to the full connection between the layers and the gate mechanism in an LSTM cell. Recently , conv olutional neural networks (CNNs) have been successfully applied to audio modeling of spectrograms [13 – 16], although CNNs were originally intro- duced to address the transition-in v ariant property of images. A CNN significantly reduces the number of parameters and improv es generalization by sharing parameters to model lo- cal patterns in the input. Howe ver , a standard CNN requires considerable depth to cover long contexts, making training difficult. T o address this problem, a multi-scale structure was used to adapt a CNN to solve the ASS problem in [17, 18], where con volutional layers were applied on multiple scales obtained by do wnsampling feature maps, and low-resolution feature maps were progressiv ely upsampled to recover the original resolution. Another problem in applying a two di- mensional con volution to a spectrogram is the biased distri- bution of the local structure in the spectrogram. Unlike an image, a spectrogram has dif ferent local structures depending on the frequency bands. Complete sharing of con volutional kernels o ver the entire frequency range may reduce modeling flexibility . In [18], we proposed a multi-band structure where each band was linked to a single CNN dedicated to particu- lar frequency bands along with a full-band CNN. The novel CNN architecture called DenseNet w as extended to the multi- scale and multi-band structure called MMDenseNet, which outperformed an LSTM system and achieved a state-of-the- art performance for the DSD100 dataset [19]. Although it has been suggested that CNNs often work better than RNNs e ven for sequential data modeling [18, 20], RNNs can also benefit from multi-scale and multi-band modeling because they make it easier to capture long-term dependencies and can sa ve pa- rameters by omitting redundant connections between dif fer- ent bands. Moreov er, the blending of two systems improves the per- formance ev en when one system consistently performs better than the other [12]. Motiv ated by these observations, here we propose a novel network architecture called MMDenseL- STM. This combines LSTM and DenseNet in multiple scales and multiple bands, improving separation quality while re- taining a small model size. There ha ve been se veral attempts to combine CNN and RNN architectures. In [21, 22], conv olu- tional layers and LSTM layers were connected serially . Shi et al. proposed conv olutional LSTM for the spatio-temporal sequence modeling of rainfall prediction [23], where matrix multiplications in LSTM cells were replaced with con volu- tions. In contrast to these methods, in which con volution DS DS US US DS Down s ampling layer US Upsampling layer Output MDenseNet downsampli ng path upsampling path Input d1 s=2 s=3 s=1 s=2 s=1 dense block d2 d3 u2 u1 BN, ReLU , conv. Fig. 1 . MDenseNet architecture. Multi-scale dense blocks are connected though down- or upsampling layer or through block skip connections. The figure shows the case s = 3 . and LSTM operate at a single scale, we sho w that combin- ing them at multiple low scales increases the performance and ef ficiency . Moreov er, we systematically compare sev- eral architectures to search for the optimal strategy to combine DenseNet and LSTM. Experimental results show that the pro- posed method outperforms current state-of-the-art methods for the DSD100 and MUSDB18 datasets. Furthermore, MM- DenseLSTM even outperforms an ideal binary mask (IBM), which is usually considered as an upper baseline, when we train the networks with a lar ger dataset. 2. MUL TI-SCALE MUL TI-BAND DENSELSTM In this section, we first summarize multi-scale multi-band DenseNet (MMDenseNet) as our base network architecture. Then, we introduce strategies to combine dense block and LSTM at multiple scales and multiple bands. Finally , we discuss the architecture of MMDenseLSTM in detail. 2.1. MMDenseNet Among the various CNN architectures, DenseNet shows ex- cellent performance in image recognition tasks [24]. The ba- sic idea of DenseNet is to improve the information flow be- tween layers by concatenating all preceding layers as, x l = H l ([ x l − 1 , x l − 2 , . . . , x 0 ]) , where x l and [ . . . ] denote the out- put of the l th layer and the concatenation operation, respec- tiv ely . H l ( · ) is a nonlinear transformation consisting of batch normalization (BN) follo wed by ReLU and conv olution with k feature maps. Such dense connectivity enables all layers to receive the gradient directly and also reuse features com- puted in preceding layers. T o cover the long context required for ASS, multi-scale DenseNet (MDenseNet) applies a dense block at multiple scales by progressiv ely do wnsampling its output and then progressiv ely upsampling the output to re- cov er the original resolution, as shown in Fig.1. Here, s is the scale inde x, i.e., the feature maps at scale s are downsam- pled s − 1 times and ha ve 2 2( s − 1) times lo wer resolution than the original feature maps. T o allo w forward and backward signal flow without passing though lower -resolution blocks, an inter-block skip connection, which directly connects two dense blocks of the same scale, is also introduced. In contrast to an image, in an audio spectrogram, dif ferent patterns occur in different frequency bands, although a cer- tain amount of translation of patterns exists for a relativ ely small pitch shift. Therefore, limiting the band that shares the kernels is suitable for ef ficiently capturing local patterns. MMDenseNet addresses this problem by splitting the input into multiple bands and applying band-dedicated MDenseNet to each band. MMDenseNet has demonstrated state-of-the- art performance for the DSD100 dataset with about 16 times fewer parameters than the LSTM model, which obtained the best score in SiSEC 2016 [19]. 2.2. Combining LSTM with MMDenseNet Uhlich et al. hav e shown that blending two systems giv es better performance even when one system consistently out- performs the other [12]. The improv ement tends to be more significant when two very dif ferent architectures are blended such as a CNN and RNN, rather than the same architectures with different parameters. Ho wev er , the blending of archi- tectures increases the model size and computational cost in an additive manner , which is often undesirable when deploy- ing the systems. Therefore, we propose combining the dense block and LSTM block in a unified architecture. The LSTM block consists of a 1 × 1 conv olution that reduces the number of feature maps to 1 , followed by a bi-directional LSTM layer, which treats the feature map as sequential data along the time axis, and finally a feedforward linear layer that transforms back the input frequency dimension f s from the number of LSTM units m s . W e consider three configurations with dif- ferent combinations of the dense and LSTM blocks as shown in Fig. 2. The Sa and Sb configurations place the LSTM block after and before the dense block, respecti vely , while the dense block and LSTM block are placed in parallel and con- catenated in the P configuration. W e focus on the use of the Sa configuration since a CNN is effecti ve at modeling the lo- cal structure and the LSTM block benefits from local pattern modeling as it cov ers the entire frequency at once. This claim will be empirically validated in Sec. 3.2. Naiv ely inserting LSTM blocks at every scale greatly in- creases the model size. This is mostly due to the full connec- tion between the input and output units of the LSTM block in the scale s = 1 . T o address this problem, we propose the insertion of only a small number of LSTM blocks in the up- sampling path for low scales ( s > 1 ). This makes it easier for LSTM blocks to capture the global structure of the in- put with a much smaller number of parameters. On the other hand, a CNN is advantageous for modeling fine local struc- tures; thus placing only dense block at s = 1 is suitable. The multi-band structure is also beneficial for LSTM blocks since the compression from the input frequency dimension f s to m s LSTM units is relaxed or it even allows the dimension Sa: Sequential, LSTM after Dense Sb: Sequential, LSTM before Dense P: Parallel Down sample layer Up s ample layer LSTM block dense block Fig. 2 . Configurations with different combinations of dense and LSTM blocks. LSTM blocks are inserted at some of the scales input band N Full band output … R- MDenseNets band 1 d ense block Fig. 3 . MMDenseLSTM architecture. Outputs of MDenseL- STM dedicated to different frequency band including the full band are concatenated and the final dense block integrates fea- tures from these bands to create the final output. ( f s < m s ) to be increased while using fewer LSTM units, increasing the modeling capabilities as discussed in [25]. The entire proposed architecture is illustrated in Fig. 3. T o cap- ture the pattern that spans the bands, MDenseLSTM for the full band is also built in parallel along with the band dedi- cated MDenseLSTM. The outputs of the MDenseLSTMs are concatenated and integrated by the final dense block, as MM- DenseNet. 2.3. Architectural details Details of the proposed network architecture for ASS are de- scribed in T able 1. W e split the input into three bands at 4 . 1 kHz and 11 kHz. The LSTM blocks are only placed at bot- tleneck blocks and at some blocks at s = 2 in the upsampling path, which greatly reduces the model size. The final dense block has three layers with growth rate k = 12 . The effecti ve context size of the architecture is 356 frames. Note that MM- DenseLSTM can be applied to an input of arbitrary length since it consists of con volution and LSTM layers. T able 1 . The pr oposed ar chitectur e. All dense blocks ar e equipped with 3 × 3 kernels with gr owth rate k . l and m s de- note the number of layer and LSTM units of LSTM block, r e- spectively . ds denotes scale s in the downsampling path while us is that in the upsampling path. band k scale d1 d2 d3 d4 d5 u4 u3 u2 u1 1 14 l 5 5 5 5 - - 5 5 5 m s - - - 128 - - - 128 - 2 4 l 4 4 4 4 - - 4 4 4 m s - - - 32 - - - - - 3 2 l 1 1 - - - - - 1 1 m s - - 8 - - - - - - full 7 l 3 3 4 5 5 5 4 3 3 m s - - - 128 - - - 128 - 0.6 0.65 0.7 0.75 0.8 5 10 15 20 25 30 35 40 45 d1 d2 d3 bn u3 u2 u1 MSE increase in parameters[%] increase in p arameters MSE Fig. 4 . Effect of LSTM block at dif ferent scales. 3. EXPERIMENTS 3.1. Setup W e ev aluated the proposed method on the DSD100 and MUSDB18 datasets, prepared for SiSEC 2016 [19] and SiSEC 2018 [26], respectiv ely . MUSDB18 has 100 and 50 songs while DSD100 has 50 songs each in the Dev and T est sets. In both datasets, a mixture and its four sources, bass, drums, other and vocals , recorded in stereo format at 44.1kHz, are av ailable for each song. Short-time Fourier transform magnitude frames of the mixture, windowed at 4096 samples with 75% ov erlap, with data augmentation [12] were used as inputs. The networks were trained to estimate the source spectrogram by minimizing the mean square error with the Adam optimizer . For the ev aluation on MUSDB18, we used the museval package [26], while we used the BSSE- val v3 toolbox [27] for the ev aluation on DSD100 for a fair comparison with previously reported results. The SDR values are the median of the av erage SDR of each song. 3.2. Architectur e validation In this section we v alidate the proposed architecture for the singing voice separation task on MUSDB18. Combination structure The SDR values obtained by the Sa- , Sb- and P- type MMDenseLSTMs are tabulated in T able 2. These results validate our claim (Sec. 2.2) that the Sa T able 2 . Comparison of MMDenseLSTM configurations. type Sa Sb P SDR 2.83 2.31 2.47 T able 3 . Comparison of SDR on DSD100 dataset. SDR in dB Method Bass Drums Other V ocals Acco. DeepNMF [4] 1.88 2.11 2.64 2.75 8.90 NUG [10] 2.72 3.89 3.18 4.55 10.29 BLSTM [12] 2.89 4.00 3.24 4.86 11.26 BLEND [12] 2.98 4.13 3.52 5.23 11.70 MMDenseNet [18] 3.91 5.37 3.81 6.00 12.10 MMDenseLSTM 3.73 5.46 4.33 6.31 12.73 configuration performs the best because the LSTM layer can efficiently model the global modulations utilizing the local features extracted by the dense layers at this scale. Hence- forth, all experiments use the Sa configuration. LSTM insertion scale The efficiency of inserting the LSTM block at lower scales was validated by comparing sev en MMDenseLSTMs with a single 64 unit LSTM layer inserted at dif ferent scales in band 1 (all other LSTM layers in T able 1 are omitted). Figure 4 sho ws the percentage increase in the number of parameters compared with that of the base architecture and the mean square error (MSE) values for the sev en networks. It is evident that inserting LSTM layers at low scales in the up-scaling path gi ves the best performance. Contribution of dense and LSTM layers W e further compared the l 2 norms of the feature maps (Fig.5) in the LSTM block d 4 of band 1. It can be seen that the norm of the LSTM feature map is similar to the highest norm among the dense feature maps. Even though some dense feature maps hav e low norms, we confirmed that they tend to learn sparse local features. 3.3. Comparison with state-of-the-art methods W e next compared the proposed method with fi ve state-of- the-art methods, DeepNMF [4], NUG [10], BLSTM [12], F e atu r e M ap s 0 1 2 3 4 5 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 N orm LS T M De ns e Fig. 5 . A verage l 2 norm of feature maps. T able 4 . Comparison of SDR on MUSDB18 dataset. #params SDR in dB Method [ × 10 6 ] Bass Drums Other V ocals Acco. IBM - 5.30 6.87 6.42 7.50 10.83 BLSTM [12] 30.03 3.99 5.28 4.06 3.43 14.51 MMDenseNet [18] 0.33 5.19 6.27 4.64 3.87 15.41 BLEND2 30.36 4.72 6.25 4.75 4.33 16.04 MMDenseLSTM 1.22 5.19 6.62 4.93 4.94 16.40 BLEND [12] and MMDenseNet [18] on DSD100. The task was to separate the four sources and accompaniment, which is the residual of the vocal extraction, from the mixture. Here, the multichannel W iener filter was applied to MMDenseL- STM outputs as in [12, 18]. T able 3 shows that the proposed method improv es SDRs by an a verage of 0 . 2 dB compared with MMDenseNet, showing that the MMDenseLSTM archi- tecture further improv es the performance for most sources. T o further improve the capability of music source separa- tion and utilize the full modeling capability of MMDenseL- STM, we next trained models with the MUSDB dev set and an internal dataset comprising 800 songs resulting in a 14 times larger than the DSD100 dev set. The proposed method was compared with BLSTM [12], MMDenseNet [18] and a blend of these two systems (BLEND2) as in [12]. All baseline networks were trained with the same training set, namely 900 songs. For a fair comparison with MMDenseNet, we configured it with the same base architecture as in T able 1, with an extra layer in the dense blocks , corresponding to the LSTM block in our proposed method. W e also included the IBM as an upper baseline since it uses oracle separation. T able 4 shows the result of this experiment. W e obtained av erage improvements of 0.43dB over MMDenseNet and 0.41dB over BLEND2, achieving state-of-the-art results in SiSEC2018 [26]. The proposed method even outperformed the IBM for accompaniment . T able 4 also shows that MM- DenseLSTM can efficiently utilize the sequence modeling capability of LSTMs in conjunction with MMDenseNet, hav- ing 24 times fewer parameters than the nai ve combination of BLSTM and MMDenseNet. 4. CONCLUSION W e proposed an efficient way to combine DenseNet and LSTM to improv e ASS performance. The proposed MM- DenseLSTM achie ves state-of-the-art results on DSD100 and MUSDB18 datasets. MMDenseLSTM outperforms a naiv e combination of BSL TM and MMDenseNet despite having much fewer parameters, and ev en outperforms an IBM for a singing v oice separation task when the netw orks were trained with 900 songs. The improvement o ver MMDenseNet is less for bass , which will be further in vestigated in future. 5. REFERENCES [1] N. Q. K. Duong, E. V incent, and R. Gribon val, “Under- determined re verberant audio source separation using a full-rank spatial cov ariance model, ” IEEE T rans. Au- dio, Speech & Language Pr ocessing , vol. 18, no. 7, pp. 1830–1840, 2010. [2] D. Fitzgerald, A. Liutkus, and Roland Badeau, “PR O- JET - spatial audio separation using projections, ” in Pr oc. ICASSP , 2016, pp. 36–40. [3] A. Liutkus, D. Fitzgerald, and R. Badeau, “Cauchy non- negati ve matrix factorization, ” in Pr oc. W ASP AA , 2015, pp. 1–5. [4] J. LeRoux, J. R. Hershe y , and F . W eninger , “Deep NMF for speech separation, ” in Pr oc. ICASSP , 2015, p. 6670. [5] Y . Mitsufuji, S. Ko yama, and H. Saruwatari, “Multi- channel blind source separation based on non-negativ e tensor factorization in wav enumber domain, ” in Pr oc. ICASSP , 2016, pp. 56–60. [6] A. Liutkus, D. Fitzgerald, Z. Rafii, B. Pardo, and L. Daudet, “K ernel additiv e models for source sepa- ration, ” IEEE T rans. Signal Pr ocessing , vol. 62, no. 16, pp. 4298–4310, 2014. [7] A. Ozerov and C. F ´ evotte, “Multichannel nonnegati ve matrix factorization in conv olutive mixtures for audio source separation, ” IEEE T rans. Audio, Speech & Lan- guage Pr ocessing , vol. 18, no. 3, pp. 550–563, 2010. [8] A. Liutkus, D. Fitzgerald, and Z. Rafii, “Scalable au- dio separation with light kernel additive modelling, ” in Pr oc. ICASSP , 2015, pp. 76–80. [9] D. Fitzgerald, A. Liutkus, and R. Badeau, “Projection- based demixing of spatial audio, ” IEEE/ACM T rans. Au- dio, Speech & Language Pr ocessing , vol. 24, no. 9, pp. 1560–1572, 2016. [10] A. A. Nugraha, A. Liutkus, and E. V incent, “Multi- channel music separation with deep neural networks, ” in Pr oc. EUSIPCO , 2015. [11] S. Uhlich, F . Giron, and Y . Mitsufuji, “Deep neural net- work based instrument e xtraction from music, ” in Pr oc. ICASSP , 2015, pp. 2135–2139. [12] S. Uhlich, M. Porcu, F . Giron, M. Enenkl, T . Kemp, N. T akahashi, and Y . Mitsufuji, “Improving music source separation based on deep networks through data augmentation and network blending, ” in Pr oc. ICASSP , 2017, pp. 261–265. [13] T . Sercu, C. Puhrsch, B. Kingsb ury , and Y . LeCun, “V ery deep multilingual conv olutional neural networks for L VCSR, ” in Pr oc. ICASSP , 2016, pp. 4955–4959. [14] N. T akahashi, M. Gygli, B. Pfister , and L. V an Gool, “Deep Conv olutional Neural Networks and Data Aug- mentation for Acoustic Event Detection, ” in Pr oc. In- terspeech , 2016. [15] F . K orzeniowski and G. W idmer, “A fully con volutional deep auditory model for musical chord recognition, ” in Pr oc. MLSP , 2016. [16] N. T akahashi, M. Gygli, and L. V an Gool, “ Aenet: Learning deep audio features for video analysis, ” IEEE T rans. on Multimedia , vol. 20, pp. 513–524, 2017. [17] A. Jansson, E. Humphrey , N. Montecchio, R. Bittner , A. Kumar , and T . W eyde, “Singing voice separation with deep U-Net con volutional Networks, ” in Pr oc. IS- MIR , 2017. [18] N. T akahashi and Y . Mitsufuji, “Multi-scale multi-band DenseNets for audio source separation, ” in Pr oc. W AS- P AA , 2017, pp. 261–265. [19] A. Liutkus, F . St ¨ oter , Z. Rafii, D. Kitamura, B. Riv et, N. Ito, N. Ono, and J. F ontecave, “The 2016 Signal sep- aration ev aluation campaign, ” in Pr oc. L V A/ICA , 2017, pp. 66–70. [20] V . Koltun. S. Bai, Z. K olter, “Con volutional Sequence Modeling Revisited, ” in Pr oc. ICLR , 2018. [21] T . Sainath, O. V inyals, A. Senior , and H. Sak, “Con vo- lutional, long short-term memory , fully connected deep neural networks, ” in Pr oc. ICASSP , 2015. [22] Iv an T ashev Chin-Hui Lee Han Zhao, Shuayb Zarar , “Con volutional-recurrent neural networks for speech enhancement, ” in Pr oc. ICASSP , 2018, pp. 2401–2405. [23] X. Shi, Z. Chen, H. W ang, and D. Y eung, “Con volu- tional LSTM network: A machine learning approach for precipitation nowcasting, ” in Pr oc. NIPS , 2015. [24] H.Gao, L. Zhuang, and Q. W . Kilian, “Densely con- nected con volutional networks, ” in Pr oc. CVPR , 2017. [25] S. Zagoruyko and N. K omodakis, “W ide residual net- works, ” in Pr oc. BMVC , 2016. [26] A. Liutkus, F .-R. St ¨ oter , and N. Ito, “The 2018 sig- nal separation e v aluation campaign, ” in Pr oc L V A/ICA , 2018. [27] E. V incent, R. Gribon val, and C. F ´ evotte, “Performance measurement in blind audio source separation, ” IEEE T rans. on Audio, Speec h and Language Pr ocessing , vol. 14, pp. 1462–1469, 2006.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment