우세 집합을 이용한 화자 클러스터링
본 논문은 화자 클러스터링에 그래프 기반 군집화 기법인 우세 집합(Dominant Sets)을 적용한다. TIMIT 데이터셋 전체와 부분집합에 대해 두 종류의 딥러닝 기반 음성 임베딩(CNN‑T, CNN‑V)을 사용해 특징을 추출하고, 코사인 거리와 로컬 스케일링으로 유사도 행렬을 만든 뒤 우세 집합을 반복적으로 추출한다. 클러스터 라벨링은 최대 참여도 방식과 헝가리안 매칭을 비교한다. 실험 결과, 기존 계층적 군집, K‑means, 스펙트럴 …
저자: Feliks Hibraj, Sebastiano Vascon, Thilo Stadelmann
본 논문은 화자 클러스터링(Speaker Clustering, SC) 문제를 해결하기 위해 그래프 기반 군집화 기법인 우세 집합(Dominant Sets, DS)을 도입한다. SC는 발화문 집합에서 화자를 식별하고 그룹화하는 완전 비지도 학습 과제로, 화자 수와 각 화자에 속한 발화문 수가 사전에 알려지지 않는다. 기존 연구에서는 MFCC와 GMM, i‑vector 등 전통적인 특징과 K‑means, 계층적 클러스터링, 스펙트럴 클러스터링 등을 사용했지만, 클러스터 수를 미리 지정해야 하거나 노이즈에 취약한 한계가 있었다.
본 연구는 두 단계로 구성된 파이프라인을 제안한다. 첫 번째 단계는 음성 발화문을 특징 벡터로 변환하는 과정이며, 두 가지 딥러닝 기반 임베딩을 사용한다. 첫 번째는 TIMIT 데이터에 대해 직접 학습된 CNN‑T 모델로, 스펙트로그램을 입력받아 1000 차원의 벡터를 출력한다. 두 번째는 VoxCeleb 데이터로 사전 학습된 VGG‑Vox 모델(CNN‑V)에서 FC7 레이어를 추출해 1024 차원의 벡터를 얻는다. 두 모델 모두 스펙트로그램 입력을 사용하지만, CNN‑T는 도메인 특화 학습으로 TIMIT 전체에 대해 높은 구분력을 보이고, CNN‑V는 도메인 일반화 능력으로 다양한 화자에 대해 강인한 성능을 제공한다.
두 번째 단계에서는 추출된 특징을 기반으로 완전 연결 무방향 그래프 G=(V,E,w)를 구성한다. 노드 V는 발화문을, 가중치 w는 코사인 거리 기반 유사도 ω(f_i,f_j)=exp(−d(f_i,f_j)/σ)로 정의한다. 여기서 σ는 로컬 스케일링 파라미터로, 각 노드 i의 7‑최근접 이웃 평균 거리로 계산한다. 이렇게 만든 유사도 행렬 A는 복제자 역학(Replicator Dynamics) 방정식 x_i(t+1)=x_i(t)(A x(t))_i/(x(t)^T A x(t))에 의해 반복 업데이트된다. 수렴 시 x는 특성 벡터이며, x_i>θ·max(x)인 노드 집합을 하나의 우세 집합으로 추출한다. 추출된 우세 집합은 그래프에서 제거하고, 남은 노드에 대해 동일 과정을 반복하는 피어링‑오프 전략을 사용한다. 이 과정은 클러스터 내부의 응집도를 최적화하고, 노이즈에 해당하는 희소 노드들을 자연스럽게 배제한다는 장점을 가진다.
클러스터 라벨링 단계에서는 두 가지 방법을 시험한다. ‘Max’ 방식은 각 우세 집합 내에서 특성 벡터 x의 최대값을 가진 샘플의 실제 화자 라벨을 클러스터 라벨로 채택한다. ‘Hungarian’ 방식은 비용 행렬을 구성해 Munkres(헝가리안) 알고리즘으로 최적 매칭을 수행한다. 후자는 라벨 충돌을 최소화해 전체 오류율을 낮추는 데 유리하다.
실험은 TIMIT 데이터셋의 두 변형, TIMIT Small(40 화자)과 TIMIT Full(630 화자)를 사용한다. 비교 대상으로는 기존 연구에서 사용된 계층적 클러스터링(HC), K‑means(KM), 스펙트럴 클러스터링(SP) 외에도 Affinity Propagation(AP)과 HDBSCAN을 포함한다. 각 방법에 대해 클러스터 수 k를 실제 화자 수, DS가 추정한 수, Eigengap heuristic 등으로 설정해 공정한 비교를 수행했다. 평가 지표는 Misclassification Rate(MR), Adjusted Rand Index(ARI), Average Cluster Purity(ACP)이며, 각각 라벨 정확도와 군집 품질을 측정한다.
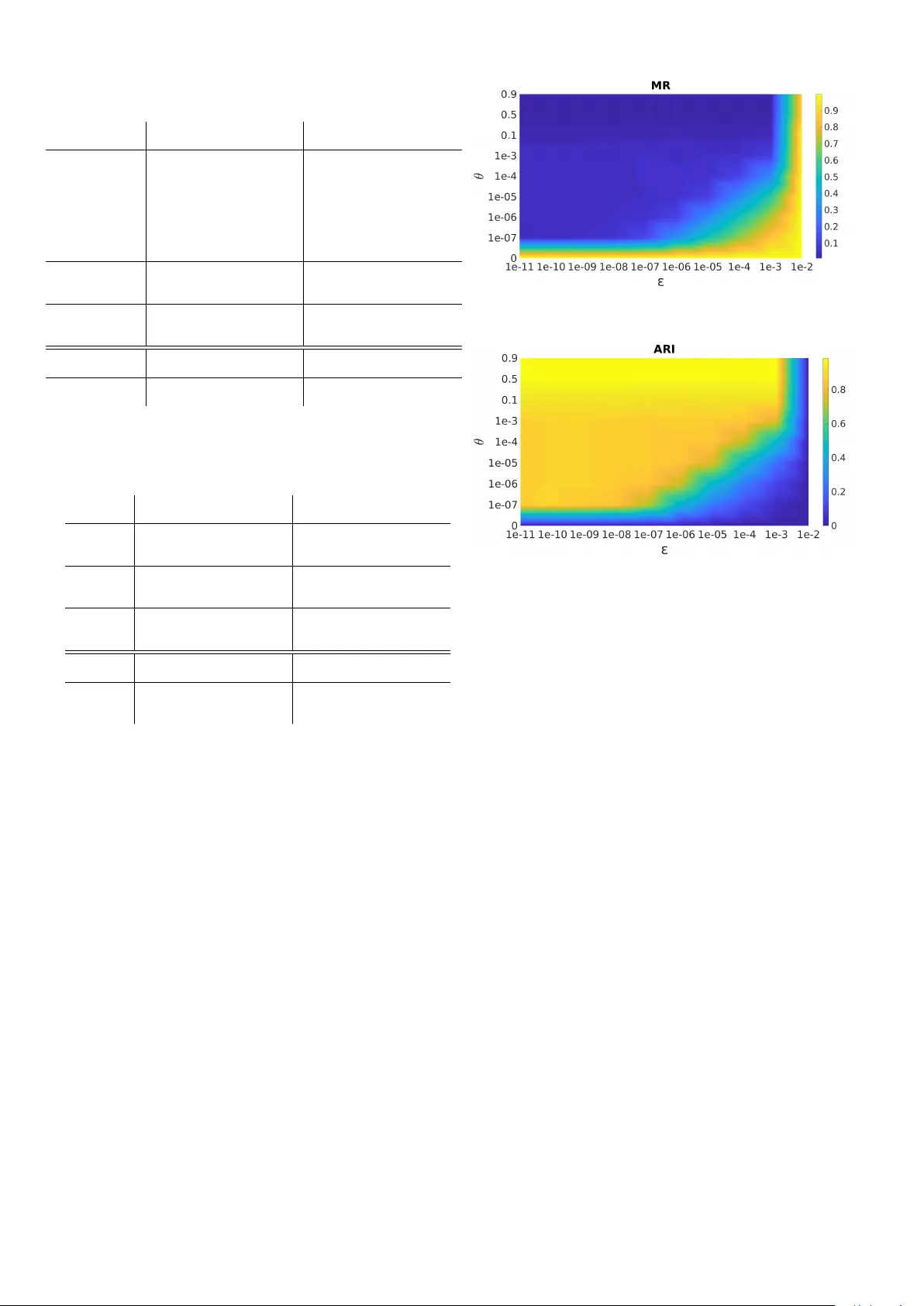
결과는 DS 기반 SCDS가 모든 지표에서 가장 우수함을 보여준다. 특히 TIMIT Full에서 CNN‑T 특징을 사용할 경우 MR이 0.2% 수준으로 거의 완벽에 가까우며, ARI와 ACP도 0.99 이상을 기록한다. CNN‑V 특징을 사용해도 비슷한 수준의 성능을 유지해, 사전 학습된 일반화 모델만으로도 높은 정확도를 달성할 수 있음을 입증한다. 또한 DS는 클러스터 수를 자동 추정하면서도 다른 방법보다 일관된 군집 구조를 제공한다는 점에서 실용성이 강조된다. 파라미터 θ와 ε에 대한 민감도 분석에서도 성능 변동이 미미함을 확인해, 방법의 안정성을 뒷받침한다.
본 연구의 주요 기여는 다음과 같다. 첫째, 우세 집합을 화자 클러스터링에 최초 적용해 기존 방법을 능가하는 성능을 달성하였다. 둘째, 전체 TIMIT 데이터셋을 사용한 최초 벤치마크를 제공해 향후 연구의 기준점을 마련하였다. 셋째, VGG‑Vox 기반 일반화 특징이 화자 구분에 충분히 효과적임을 증명하였다. 향후 연구에서는 노이즈가 포함된 실시간 회의 녹음이나 다중 채널 데이터에 대한 확장, 그리고 DS와 딥러닝 기반 임베딩을 공동 최적화하는 통합 프레임워크 개발이 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기