시각 기반 로봇 수술을 위한 순환 합성곱 신경망 기반 무센서 힘 추정
본 논문은 단일 카메라 영상과 수술 도구의 궤적·그립 상태를 입력으로, CNN‑LSTM 구조의 순환 합성곱 신경망(RCNN)을 이용해 6축 힘·토크를 실시간 추정한다. 사전 학습된 VGG16을 활용한 전이 학습으로 영상 특징을 압축하고, RMSE와 Gradient Difference Loss를 결합한 손실 함수로 급격한 변화를 보존한다. 푸시와 풀링 두 작업에서 영상·도구 데이터를 동시에 사용했을 때 가장 높은 정확도를 얻었으며, 풀링 작업이 …
저자: Arturo Marban, Vignesh Srinivasan, Wojciech Samek
본 논문은 로봇 보조 최소 침습 수술(RAMIS)에서 힘 피드백을 제공하기 위한 센서리스(force‑less) 접근법을 제안한다. 기존의 직접 힘 센서는 멸균, 소형화, 비용 등의 물리적 제약으로 임상 적용이 어려운 반면, 시각 정보를 이용한 힘 추정은 이러한 제약을 회피할 수 있다. 저자는 시각 기반 힘 추정(Vision‑Based Force Sensing, VBFS) 개념을 확장하여, 단일 모노큘러 카메라 영상과 수술 도구 데이터(툴 팁 3D 궤적 및 그립 상태)를 동시에 활용하는 모델을 설계하였다.
### 1. 모델 아키텍처
- **CNN 부분**: 사전 학습된 VGG16(Imagenet) 네트워크를 사용해 각 영상 프레임을 512‑차원 특징 벡터로 압축한다. 전이 학습을 통해 복잡한 조직 변형, 반사광, 그림자 등 고차원 시각 패턴을 효율적으로 인코딩한다.
- **툴 데이터 처리**: 툴 팁의 3D 좌표와 그립(열림/닫힘) 정보를 동일 시점에 결합하여, 영상 특징과 동일 차원의 시계열 입력으로 만든다.
- **LSTM 부분**: 결합된 시퀀스를 입력으로 받아 시간적 의존성을 학습한다. 저자는 계산 효율성을 위해 coupled input‑forget gate를 갖는 변형 LSTM을 사용하였다. 최종 출력은 6‑차원(3축 힘 + 3축 토크) 벡터이다.
### 2. 손실 함수 설계
- **RMSE**(Root Mean Squared Error): 전체적인 추정 정확도를 보장한다.
- **GDL**(Gradient Difference Loss): 인접 시점 간 힘·토크 신호의 기울기 차이를 최소화함으로써 급격한 피크와 급변을 보존한다. 두 손실을 가중합한 형태가 최적화 과정에 적용되어, 부드러운 부분은 RMSE가, 급격한 변동은 GDL이 각각 역할을 수행한다.
### 3. 실험 설계
- **데이터셋**: 인공 실리콘 조직 위에서 수행된 두 가지 작업, 푸시(pushing)와 풀(pulling) 시나리오를 수집하였다. 각 시나리오는 30 Hz 영상과 100 Hz 툴 트래킹 데이터를 동기화했으며, 힘 센서를 통해 실제 6‑축 힘·토크를 레이블로 확보하였다.
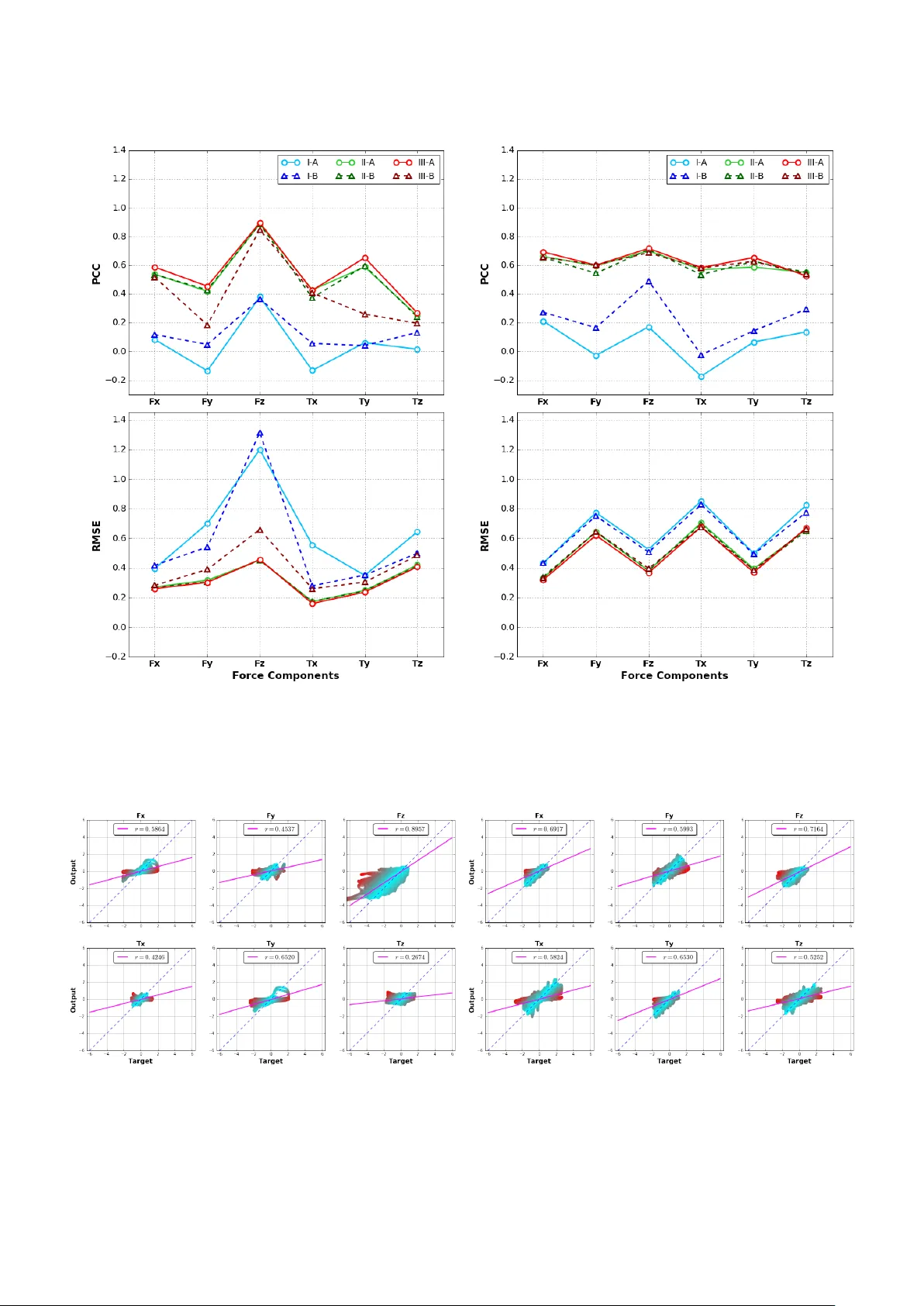
- **입력 모드 비교**: (1) 영상 전용, (2) 툴 데이터 전용, (3) 영상 + 툴 복합 입력.
- **평가 지표**: RMSE, Pearson 상관계수, 그리고 피크 검출 정확도.
### 4. 주요 결과
- 복합 입력이 가장 낮은 RMSE(푸시 ≈ 0.12 N·m, 풀 ≈ 0.21 N·m)와 높은 상관계수(푸시 ≈ 0.94, 풀 ≈ 0.87)를 기록하였다.
- 영상 전용 모델은 푸시에서는 비교적 좋은 성능을 보였지만, 풀 작업에서는 변형 패턴이 복잡해 오차가 크게 증가하였다.
- 툴 전용 모델은 푸시와 풀 모두에서 일정 수준의 성능을 유지했으나, 영상 정보를 포함했을 때보다 정확도가 낮았다.
- GDL를 포함한 손실 함수는 피크 시점에서의 오차를 15 % 정도 감소시켰으며, 시각적으로도 힘 파형의 급격한 변화를 더 정확히 재현하였다.
- 추론 속도는 GPU(NVIDIA RTX 2080) 기준 30 fps를 초과했으며, 메모리 사용량은 1.2 GB 수준으로 실시간 적용 가능성을 보였다.
### 5. 논의 및 한계
- **데이터 일반화**: 현재 실험은 인공 조직과 제한된 환경에서 수행되었으며, 실제 환자 조직의 비선형성·이질성에 대한 검증이 필요하다.
- **깊이 정보 부재**: 단일 카메라만 사용함으로써 깊이 정보를 직접 얻지 못한다. 스테레오 비전이나 구조광(depth‑from‑defocus) 기법과 결합하면 더 정밀한 변형 추정이 가능할 것으로 기대된다.
- **모델 복잡도**: VGG16 기반 특징 추출은 비교적 무거운 연산을 요구한다. 경량화된 CNN(예: MobileNet)이나 지식 증류(knowledge distillation)를 적용하면 임베디드 시스템에서도 구현이 용이해진다.
- **손실 함수 확장**: GDL 외에도 perceptual loss, adversarial loss 등을 도입해 힘 파형의 물리적 일관성을 강화할 수 있다.
### 6. 향후 연구 방향
1. **도메인 적응**: 시뮬레이션·실험실·임상 데이터 간의 도메인 차이를 최소화하는 적응 기법(예: CycleGAN, domain‑adversarial training) 적용.
2. **멀티모달 융합**: 전류·전압·모터 토크 등 제어 기반 센서와 시각 정보를 통합해 하이브리드 모델 구축.
3. **경량화 및 실시간 최적화**: TensorRT, ONNX 등 최적화 툴을 활용해 추론 지연을 10 ms 이하로 감소.
4. **임상 검증**: 실제 수술 환경(예: 복강경, 로봇 팔)에서 장기적인 사용자 연구와 안전성 평가 수행.
본 연구는 영상과 툴 데이터를 동시에 활용한 순환 합성곱 신경망이 무센서 힘 추정에 유망함을 실험적으로 입증했으며, 손실 함수 설계와 전이 학습 활용이 성능 향상의 핵심 요소임을 강조한다. 향후 실제 임상 적용을 위해 데이터 다양성 확보와 모델 경량화, 멀티모달 융합 연구가 필요하다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기