A Recurrent Convolutional Neural Network Approach for Sensorless Force Estimation in Robotic Surgery
Providing force feedback as relevant information in current Robot-Assisted Minimally Invasive Surgery systems constitutes a technological challenge due to the constraints imposed by the surgical environment. In this context, Sensorless Force Estimati…
Authors: Arturo Marban, Vignesh Srinivasan, Wojciech Samek
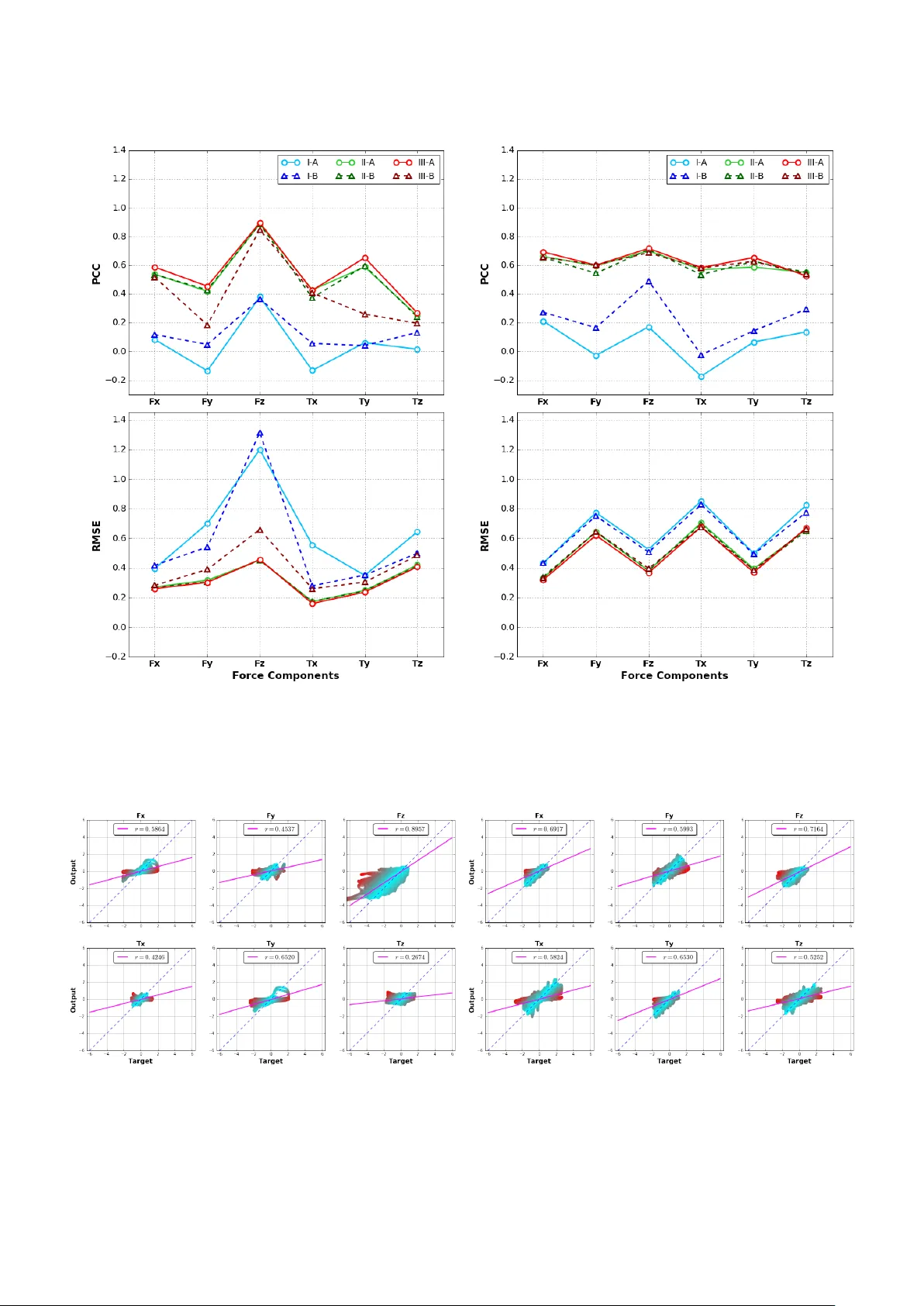
A Recurren t Con v olutional Neural Net w ork Approac h for Sensorless F orce Estimation in Rob otic Surgery Arturo Marban a,b, ∗ , Vignesh Sriniv asan b , W o jciech Samek b , Josep F ern´ andez a , Alicia Casals a a R ese ar ch Centr e for Biome dical Engine ering (CREB), Universitat Polit` ecnic a de Catalunya, 08034 Bar c elona, Spain b Machine L e arning Group, F r aunhofer Heinrich Hertz Institute, 10587 Berlin, Germany Abstract Pro viding force feedbac k as relev an t information in curren t Rob ot-Assisted Minimally In v asiv e Surgery systems consti- tutes a technological c hallenge due to the constrain ts imp osed b y the surgical en vironment. In this context, Sensorless F orce Estimation techniques represent a p oten tial solution, enabling to sense the interaction forces betw een the surgi- cal instrumen ts and soft-tissues. Sp ecifically , if visual feedbac k is av ailable for observing soft-tissues’ deformation, this feedbac k can be used to estimate the forces applied to these tissues. T o this end, a force estimation model, based on Con- v olutional Neural Netw orks and Long-Short T erm Memory net works, is proposed in this work. This mo del is designed to pro cess b oth, the spatiotemp oral information presen t in video sequences and the temp oral structure of to ol data (the surgical to ol-tip tra jectory and its grasping status). A s eries of analyses are carried out to reveal the adv an tages of the prop osal and the challenges that remain for real applications. This research work fo cuses on tw o surgical task scenarios, referred to as pushing and pulling tissue. F or these t w o scenarios, different input data modalities and their effect on the force estimation quality are in vestigated. These input data mo dalities are tool data, video sequences and a combination of b oth. The results suggest that the force estimation quality is b etter when both, the to ol data and video sequences, are pro cessed b y the neural netw ork mo del. Moreov er, this study reveals the need for a loss function, designed to promote the mo deling of smooth and sharp details found in force signals. Finally , the results show that the mo deling of forces due to pulling tasks is more c hallenging than for the simplest pushing actions. Keywor ds: Rob otic Surgery, Sensorless F orce Estimation, Conv olutional Neural Netw orks, LSTM Net w orks. 1. In tro duction T raditional op en surgery , characterized b y long inci- sions, has b een improv ed by minimally in v asiv e surgery , whic h uses long instrumen ts inserted in to the b o dy through small incisions. An endoscopic camera pro vides visual feedbac k of the target scenario, and tw o or more sur- gical instrumen ts allo w the surgeon to in teract with tissues and organs. Minimally inv asive surgery has b een extended and enhanced in capabilities by rob otic teleoperated sys- tems with a master-slav e configuration, resulting in a new pro cedure known as Rob otic Assisted Minimally In v asiv e Surgery (RAMIS) [1][2]. RAMIS pro vides surgeons with augmented capabilities, suc h as fine and dexterous mo v ements, prop er hand-ey e co- ordination, hand tremor suppression and high-quality vi- sualization of the surgical scenario [2]. Nonetheless, the in- tegration of force feedbac k as relev an t information in these ∗ Corresponding author Email addr esses: arturo.marban@upc.edu (Arturo Marban), vignesh.srinivasan@hhi.fraunhofer.de (Vignesh Sriniv asan), wojciech.samek@hhi.fraunhofer.de (W o jciech Samek), josep.fernandez@upc.edu (Josep F ern´ andez), alicia.casals@upc.edu (Alicia Casals) systems still remains an op en problem [3][4]. F orce feed- bac k has prov en to b e b eneficial in teleop erated surgery since it is associated with the control of interaction forces and thus, its use can result in less in traop erativ e tissue damage pro duced by the application of excessive forces. F orce feedback also helps to impro v e the proper execution of surgical tasks, suc h as grasping or suturing, in which the application of excessive or insufficien t forces can pro duce damage or malfunctions. F urthermore, force feedback can pro vide information of tissue stiffness and shap e. There- fore, it can help to detect abnormalities, such as tumors or calcified arteries [5]. The main difficult y in providing RAMIS systems with force feedback relies on measuring in teraction forces b e- t ween surgical instrumen ts and tissues. This problem can b e addressed by tw o approaches: direct force sensing and sensorless force estimation. In direct force sensing, the measuremen t of forces is carried out with a sensor located at, or close to, the p oin t of in teraction b et w een to ol and tissue. Although it represen ts the most intuitiv e solution, man y constraints, such as bio compatibilit y , sterilization, miniaturization, and cost [6], limit the design of such force sensors. The need of miniaturization has b een addressed in different works such as [7], where a laparoscopic instru- Pr eprint submitte d to Biome dic al Signal Pr o c essing and Contr ol May 23, 2018 men t with force sensing capability is describ ed. How ever, its clinical v alidation has not b een prov en yet, since it was only tested in an op en platform for surgical robotics re- searc h, called Ra ven-II [8]. In contrast, force estimation allo ws the remov al of any electronic device from the instru- men t in con tact with the patien t. Therefore, the in terac- tion forces hav e to b e estimated from the av ailable sources of information, which ma y result in inaccurate measures. Due to the aforesaid reasons, sensorless force estimation represen ts a p otential solution for the practical implemen- tation of force p erception systems in RAMIS. Sensorless force estimation can be implemented through con trol-based or vision-based approaches. In the con trol- based approach, interaction forces are estimated using ob- serv ers and models of the surgical tool, and by pro cessing a v ailable information from the motor units (i.e. angular p osition/v elo cit y , current consumption, and torque). In this regard, some relev an t w orks are fo cused on estimating the surgical instrumen t grasping force, as described in [9] and [10]. In contrast, the vision-based approach consists in estimating forces mainly from video sequences (mono c- ular or stereo), therefore, in this work it is referred to as Vision-Based F orce Sensing (VBFS). In VBFS, the uncer- tain ty of the force estimates is reduced by having access to surgical to ol data, such as to ol-tip tra jectory , its veloc- it y , and grasp er status. Although there are fewer works in the literature related to VBFS, if developed prop erly , it has p otential to restore force feedback in rob otic surgery . VBFS a voids the need for accurate mo deling of the surgi- cal instrument or sla ve-robot manipulator, as required b y most con trol-based approaches. In the next section, deep neural netw orks are introduced as effectiv e mo dels applied in the pro cessing of video se- quences (Section 1.1). Subsequently , the concept of VBFS is defined and different works rep orted in the literature are describ ed (Section 1.2). Finally , the prop osed approach for estimating forces in rob otic surgery is presented and the con tributions of this researc h work are listed (Section 1.3). 1.1. De ep Neur al Networks for Pr o c essing Vide o Se- quenc es Deep neural netw orks composed of Con volutional Neu- ral Netw orks (CNN) and Long-Short T erm Memory (LSTM) netw orks hav e b een inv estigated in different do- mains where the input data has a spatiotemp oral struc- ture, as in video sequences. The CNN addresses the pro- cessing of spatial information, while the LSTM net work the pro cessing of temp oral information. This neural net- w ork arc hitecture has b een applied in action recognition with visual attention [11], video activity recognition and image captioning [12], video conten t description [13], and learning ph ysical interaction through video prediction [14], among others. A particular domain of interest is related to the estimation of time-v arying signals from video se- quences in the con text of a regression framew ork. In this regard, [15] prop osed a tec hnique to estimate sound from silen t video sequences through a neural netw ork consisting of a CNN and LSTM net works. This neural netw ork w as trained using a video dataset, describing interactions of a woo den stick with different ob jects and materials with added audio recordings. In another application, [16] de- v elop ed a technique to estimate con tin uous pain intensit y from video sequences of facial expressions. This tec hnique is based on a CNN with added recurrent connections in its la yers. In the pro cessing of sequences of data with long-term temp oral dependencies, LSTM net works hav e excelled, pro viding state of the art results in applications such as language mo deling and translation, sp eec h synthesis, and analysis of audio and video data [17][18][19]. In particu- lar, the LSTM netw ork with coupled input-forget gates, suggested by [19] as a less computational exp ensive mo del than the v anilla LSTM netw ork, w as found suitable for the force estimation task, as discussed later in subsection 5.3. 1.2. Vision-Base d F or c e Sensing The Vision-Based F orce Sensing (VBFS) concept relies on a simple observ ation, that is, soft b o dies made of biolog- ical (i.e. tissue) or artificial (i.e. silicone) materials deform under an applied load. Therefore, if the deformation of soft b o dies (i.e. biological tissues) is a v ailable from visual feedbac k (i.e. video sequences), this feedbac k can be used to estimate the forces applied on these ob jects, [20][21]. VBFS metho ds are dev elop ed to estimate forces in 2D or 3D scenarios. In the first case, a force applied to a soft b ody results in a deformed contour, while in the second case, it pro duces a deformed surface. Notable works, such as [21] and [22], developed the con- cept of VBFS in 2D scenarios using neural netw orks. This approac h circum v ents the explicit modeling of complex mec hanical prop erties attributed to som e mate rials (i.e. bi- ological cells). In [21], VBFS is applied to estimate forces in ob jects that exhibit both linear (a microgripp er) and non-linear (a rubb er torus) mec hanical prop erties. This metho d relies on a deformable template matching algo- rithm to describ e the ob ject’s con tour deformation and a fully-connected neural netw ork that models the ob ject’s mec hanical prop erties. The micromanipulation of cells with a spherical shap e has b een addressed in [22]. In this w ork, a method is developed to estimate force during mi- croinjection of zebrafish embry os. This metho d relies on activ e con tours and conic fitting algorithms to model the cell’s contour deformation. Then, a fully-connected neural net work learns the non-linear relationship betw een defor- mation and force. The estimation of interaction forces b et ween to ols and tissues b ecomes more realistic when tissue deformation is pro cessed in 3D space, that is, by taking into account depth information. T o this end, a stereo vision system is used to recov er such information. Minimally in v asiv e surgical procedures are complex, how ev er, they can b e in- terpreted as the comp osition of different elemen tary sur- gical tasks [23]. One of suc h tasks, referred to as pushing tissue (pressing the end of the endoscopic tools against 2 soft-tissue), represen ts a common practice in minimally in v asiv e surgery [24]. This surgical task is studied in the con text of VBFS due to its simplicity . F orce estimation tec hniques that rely on a stereo vision system are reported in [24], [25], [26], [27] and [28]. In [24], the forces developed in a rubb er mem brane are studied. Its deformation w as reco vered by trac king no dal displace- men ts and a finite element metho d w as used to model the mec hanical relationship b etw een deformation and force. VBFS applied to neurosurgery was in vestigated in [25]. In this work, soft-tissue surface deformation is computed using a depth map extracted from stereo-endoscopic im- ages. Thereafter, this information is processed by a surface mesh (based on spring-damp er mo dels) to render force as output. Another approach in the con text of neurosurgery has b een in vestigated in [26]. The authors of this work de- v elop ed a metho d based on quasi-dense stereo correspon- dence to reco ver surface deformation from stereo video se- quences. Afterward, force is estimated from the surgical to ol displacement (which is extracted from the deforma- tion data), using a 2nd order polynomial model. In recen t y ears, models based on neural netw orks hav e b een inv esti- gated. In this regard, [27] prop osed a method consisting in a 3D lattice and a recurrent neural netw ork. The 3D lat- tice mo dels the complex deformation of soft-tissues. The recurren t neural netw ork was designed to estimate force b y pro cessing the information provided by this lattice in addition to the surgical to ol motion. A subsequen t notable w ork by the same author is presented in [28]. In this w ork, the recurrent neural net w ork describ ed in [27] is improv ed b y designing a model based on the LSTM netw ork arc hi- tecture [29], achieving high accuracy in the estimation of forces (in 3D space). Mono cular force estimation repre- sen ts a more challenging approach. In this regard, [30] dev elop ed a tec hnique to estimate forces from mono cu- lar video sequences using a real lamb liver as experimen- tal material. This metho d relies on a virtual template to mo del soft-tissue surf ace deformation, how ev er, it assumes that soft-tissue surface b eha ves as a smooth function with lo cal deformation. Then, a stress-strain bio-mechanical mo del defines the relationship b et ween force and penetra- tion depth caused b y the surgical to ol. F rom the literature review a series of conclusions are dra wn. First, most of the existing methods reco ver tissue deformation using a stereo vision system ([24]-[28]). They rely on a deformation mo del which is created based on 3D geometries such as a mesh or lattice (i.e. [25] and [28]), or stereo-corresp ondences (i.e. [26]). Second, the estimation of forces has b een studied only for pushing tasks. Other surgical tasks that result in complex in teractions, such as pulling or grasping tissue, hav e not b een addressed yet. Third, recurren t neural netw ork architectures hav e b een studied in [27] and [28], p erforming a mapping from soft- tissue deformation and to ol data to interaction force. F rom these tw o works, only [28] describes the use of a deep neu- ral netw ork, specifically a LSTM netw ork. F ourth, CNNs, whic h excel in tasks related to processing spatial informa- tion present in images or video sequences (e.g., [31, 11, 32]) ha ve not b een explored in the pro cessing of visual infor- mation av ailable from RAMIS systems. Fifth, monocular force estimation w as only addressed in [30]. Nonetheless, this metho d relies on feature detection and matching al- gorithms that are not robust to sp ecularities pro duced b y reflection of light on the tissue surface. Therefore, feature p oin ts had to b e detected and matched manually during the rep orted exp eriments. F urthermore, the force was es- timated only for the loading cycle (when the to ol is incre- men tally deforming the tissue, b efore reaching the p eak force), and for one comp onen t ( F z ). Finally , due to the complexit y of data acquisition (i.e. video sequences, to ol data and force sensing) in a real surgical scenario, most metho ds ([24]-[28]) are implemented and v alidated on ex- p erimen tal platforms using organs made of artificial tis- sues (i.e. silicone). Only [30] describ es exp erimen ts on a real lam b liver. The literature review shows that an approac h based on deep neural netw orks, specifically , CNN and LSTM net- w orks, has not b een inv estigated for VBFS in rob otic surgery . Its adv an tages and do wnsides will rev eal new re- searc h directions to design a b etter force estimation mo del that learns from data. In particular, transfer learning tech- niques (i.e. using a pre-trained CNN on the ImageNet dataset [33]) ha ve not been explored for VBFS in the con text of rob otic surgery . They can be useful to en- co de complex phenomena (i.e. to ol-tissue in teractions) in a lo w-dimensional feature vector represen tation learned from high-dimensional data, suc h as video sequences. This fea- ture v ector representati on is easier to mo del by an LSTM net work. 1.3. R e curr ent Convolutional Neur al Network Appr o ach In the present w ork, a Recurrent Con volutional Neu- ral Net work (R CNN) arc hitecture, based on CNN and LSTM netw orks, is proposed for VBFS in RAMIS. It esti- mates a 6-dimensional vector of forces and torques (in the 3D space) at ev ery time instan t, b y pro cessing monocular video sequences and to ol data. The focus of this research work is on the estimation of in teraction forces in tw o surgical tasks, pushing (pressing the to ol against a tissue) and pulling a tissue (which re- quires grasping). This surgical task decomposition was motiv ated by the discrete mo del presented in [23]. In that w ork, the complexity of minimally inv asive surgical pro ce- dures is modeled taking into account a set of fundamen tal tasks, among them, pushing and pulling a tissue. More- o ver, different input data modalities and their effect on the force estimation qualit y are in vestigated. These input data mo dalities are: (i) the to ol data represented b y the to ol-tip tra jectory (in 3D space) and its grasping status (op ened/closed), (ii) video sequences, and (iii) a com bina- tion of b oth. Finally , to facilitate the modeling of smo oth and sharp details found in the estimated force and torque signals, the RCNN is optimized with a loss function de- signed with the Ro ot Mean Squared Error (RMSE) and 3 Gradien t Different Loss (GDL), resp ectiv ely . The GDL has b een in v estigated in the prediction of future frames from video sequences as discussed in [34], enabling a DNN to render sharp images av oiding blurred pixels. Nonethe- less, this concept has neither b een extended nor studied for the prediction of time-v arying signals. Although mo dels based on CNN and LSTM net works ha ve b een inv estigated in different domains (as discussed in Section 1.1), their application to the force estimation task comes with its own c hallenges. Therefore, tw o important goals of this research work are: (i) to reveal the adv antages and downsides of a force estimation mo del based on deep neural netw orks, and (ii) define future research directions for its implemen tation on real scenarios. T o this end, the follo wing contributions are made: • A RCNN mo del is proposed for the estimation of in- teraction forces b et ween to ol and tissue relying on a single camera. This metho d has p otential applications in scenarios where a stereo vision system is unav ail- able, and consequen tly , depth information. • The effectiv eness of applying transfer learning tech- niques is inv estigated with the ob jective of finding a compact feature vector representation for ev ery video frame. F or this purp ose, the pre-trained V GG16 net- w ork [35] in the ImageNet dataset is used. This ap- proac h allows enco ding complex phenomena describ ed in video sequences, such as the deformation of tissues and sp ecular reflections, in a feature v ector represen- tation automatically learned from data. This repre- sen tation is easier to pro cess by a mo del that learns sequences of data, suc h as an LSTM netw ork. • A loss function designed with the RMSE and GDL is in vestigated to facilitate the mo deling of smo oth and sharp details found in force/torque signals. This loss function composition provides more accurate force es- timations than considering only RMSE during the R CNN optimization. • Video pre-pro cessing tec hniques, sp ecifically mean frame remo v al and space-time transformations, dis- cussed in [36] and [15] respectively , were studied to ease the learning pro cess of the RCNN. Mean frame remo v al w as found useful to discard those regions in video sequences whic h do not contribute to the learn- ing pro cess, suc h as the static background. The space- time transformation, allows emphasizing motion pro- duced by to ol-tissue interactions, in a new image rep- resen tation created from three consecutive frames. The next sections are organized as follows. Section 2 defines the problem statement. Section 3 describes the dataset acquisition using an exp erimental rob otic plat- form, and the pre-pro cessing op erations applied to this data. Section 4 details the prop osed RCNN arc hitecture for force estimation. Section 5 presents the exp erimen ts, pro viding details related to the tw o stage R CNN optimiza- tion, and describ es how the robustness of the RCNN mo del w as ev aluated. Section 6 discusses the results of the ex- p erimen ts and analyses the quality of the estimated force signals with differen t metrics. Finally , Section 7 presents the conclusions and future w ork. 2. Problem Statemen t Giv en sequences of video frames X v ideo t ∈ < h × w × c ( h , w and c stand for image height, width and n um b er of chan- nels, respectively) and to ol data X tool t ∈ < 8 , the ob jec- tiv e is to find a non-linear mo del F ( . ) with parameters W , that maps X v ideo t and X tool t to sequence of estimated forces b Y t ∈ < 6 at eac h time instant t , as expressed in Equation (1). The elemen ts of the input vector X tool t are shown in Equation (2), where P tool t = [ x t , y t , z t ] is a vector describing the tool-tip tra jectory in the 3D space, Λ tool t = [ u t , v t , w t ] is an unitary v ector that defines the to ol orientation in 3D space (coincident with the tool- axis direction), θ t is the angle of rotation around this axis, and s t is the to ol grasp er status, defined in Equa- tion (3). The to ol-tip tra jectory ( P tool t ) and its orienta- tion (defined by Λ tool t and θ t ) are illustrated in Fig. 1. The elements of the output vector b Y t (sho wn on the left of Equation (1)) are the estimated forces, ˆ F t = [ ˆ f x t , ˆ f y t , ˆ f z t ], and torques, ˆ T t = [ ˆ τ x t , ˆ τ y t , ˆ τ z t ], in the 3D space. Th us, b Y t = [ ˆ F t , ˆ T t ] 0 = [ ˆ f x t , ˆ f y t , ˆ f z t , ˆ τ x t , ˆ τ y t , ˆ τ z t ] 0 . In the present work, F ( . ) is learnt from data by using a deep neural net work. Therefore, given a rich dataset D consisting of video sequences X v ideo t , to ol data X tool t and ground-truth in teraction forces Y t , the goal is to find the parameters W that satisfy Equation (1) in the context of an optimization framew ork. A causal constrain t is en- forced, that is, a estimated force vector b Y t at the current time step, is computed b y pro cessing samples from X v ideo t and X tool t at the current and previous time steps (i.e. t , t − 1, t − 2, t − 3, ...). In the rep orted metho dology and ex- p erimen ts, the to ol orientation remained fixed, therefore, X tool t = [ P tool t , s t ] = [ x t , y t , z t , s t ] 0 ∈ < 4 . Nonetheless, in the general case, the full vector X tool t ∈ < 8 should b e con- sidered. b Y t = F ( X tool t , X video t ; W ) (1) X tool t = [ P tool t , Λ tool t , θ t , s t ] 0 (2) s t = ( 1 If the grasp er is open. 0 If the grasp er is closed. (3) 3. Dataset Acquisition & Pre-pro cessing Due to the lack of public datasets related to the appli- cation of VBFS in RAMIS, an experimental platform was designed to ev aluate the proposed approac h, as depicted in Fig. 1. This platform was used to record video sequences, to ol data, and ground-truth in teraction forces: • Video Sequences. A collection of 44 video se- quences, totaling 4.31 hours, w ere recorded using 4 4 Figure 1: Diagram of the exp erimental setup used to create the dataset. In the bottom, the three blocks relate devices/sensors to the recorded data (in vector form). The reference frame assigned to the robot is O o = { X o , Y o , Z o } , while the reference frame of the surgical tool-tip with resp ect to the robot is O o tool = { X o tool , Y o tool , Z o tool } . The origin of the reference frame O o tool , is located at the to ol-tip. Therefore, it describes the tool-tip tra jectory at each time instant t , P tool t = [ x t , y t , z t ]. The to ol orien tation, defined by the vector Λ tool t = [ u t , v t , w t ] and scalar θ t , was fixed during the exp erimen ts. The v ector Λ tool t is aligned with the Z o tool axis, which is colinear with the tool shaft. Figure 2: A sample of video frames recorded b y the four synchronized cameras. The tool is performing a pushing task o ver the artificial organs (digestiv e apparatus). digital cameras (DFK 72BUC02) with the ob jective to provide ric h visual information from differen t p er- sp ectiv es. The four cameras w ere synchronized and the video sequences w ere recorded with a resolution of 480 × 640 pixels at 50 frames p er second, in R GB color space. The target scenario consists in a motorized sur- gical instrument with grasping capability , moun ted on a slav e rob ot manipulator (St¨ aubli RX60B) that in- teracts with a digestiv e apparatus made of artificial tissue (Silicone-Smo oth On ECOFLEX 0030). A sam- ple of frames captured by the 4 cameras illustrates the Figure 3: Blo c k diagram of the pre-pro cessing steps applied to video frames. aforesaid scenario in Fig. 2. They sho w specularities and highlights rendered on the artificial tissue sur- face, a phenomenon that is presen t in real minimally in v asiv e surgery scenarios. • T o ol Dat a. The tool-tip tra jectory in the 3D space ( P tool t = [ x t , y t , z t ]) and the to ol grasping s tatus ( s t ) w ere pro vided, at eac h time instan t, b y the sla v e rob ot manipulator and the motorized surgical instrumen t, resp ectiv ely . • Ground-T ruth F orce. The in teraction forces and torques betw een the surgical instrument tip and arti- ficial tissue w ere acquired b y a 6D force/torque sensor (A TI Gamma SI-32-2.5) with its z axis aligned with the surgical instrument shaft. The measured forces lie in the range +2.5/-10 N and the torques in +/- 5 Nm, which are consistent with those v alues rep orted in a real scenario [37]. Thereafter, a series of pre-pro cessing op erations were applied to the tool data, ground-truth interaction force and video frames. The pre-pro cessing of the tool-tip tra- jectory P tool t = [ x t , y t , z t ], was carried out b y remo ving the mean and subsequently scaling its amplitude to the range +/- 1. The grasper status s t do es not need an y processing. The ground-truth in teraction forces Y t , were comp ensated with an offset and scaled to the range +/- 5. Additional pro cessing steps, such as time shifting and re-sampling, w ere applied to the aforesaid signals to sync hronize them with the video frames. Moreov er, filtering techniques w ere applied to remo ve noise. Video frames required more elab orated pre-pro cessing steps, which can b e summarized in the blo ck diagram sho wn in Fig. 3, where X v ideo t and U v ideo t represen t the ra w and pre-pro cessed video frames, resp ectively . Each op eration in the blo ck diagram was implemented using Op enCV [38] and is described as follows: 1. Mean F rame Remov al . A mean frame was com- puted for ev ery video sequence by av eraging all the ra w frames (with equal contribution). Subsequently , a subtraction operation w as performed o ver the RGB c hannels, b y removing the corresponding mean frame from all the ra w frames in the corresponding video sequence. During this pro cess, the pixel v alues w ere scaled prop erly , to conserve negativ e v alues. In [36], this method w as shown to reduce ov er-fitting of CNNs due to static bac kground present in video sequences. 2. T racking of Regions of Interest . T o provide meaningful visual information to the proposed net- w ork, a region of interest of dimensions 200 × 300 pix- 5 els, corresp onding to the area of in teraction betw een to ol and tissue, was track ed and extracted from every mean-normalized frame (480 × 640 pixels). This op er- ation w as carried out by processing mean-normalized and raw frames. The result is a mask of foreground pixels describing image regions where to ol-tip motion is present. F or this purp ose, standard computer vi- sion tec hniques were used, including image filtering (for image noise reduction), foreground extraction (to compute the mask of foreground pixels) and morpho- logical op erations (to refine the mask of foreground pixels). 3. Space-Time F rame T ransformation . This trans- formation, described in [15], is applied ov er the ex- tracted regions of in terest with the ob jectiv e to model to ol motion and tissue deformation. It represen ts an alternativ e method to the optical flo w, which is computationally more expensive. A space-time frame is defined b y the previous, current and next R GB frames, each one conv erted to grayscale. During the exp erimen ts, this op eration was carried out b y con- catenating these three frames only every 15 samples. This undersampling is due to the high frame rate of the cameras and the slo w motion of the surgical to ol. A comparison betw een regions of interest extracted from the ra w, mean-normalized and space-time frames is pre- sen ted in Fig. 4, for each surgical task. The last row of Fig. 4a and Fig. 4b shows that both, to ol motion and tis- sue deformation are emphasized in the space-time domain, and sp ecular reflections are partially suppressed. 4. F orce Estimation Mo del The pro cessing of video sequences requires taking into accoun t their spatial and temp oral information. In con- trast, for tool data only the temp oral information is rel- ev an t. T o deal with these tw o kinds of data, a Re- curren t Conv olutional Neural Net work (R CNN) architec- ture is prop osed to carry out the force estimation task. This R CNN consists of a Con volutional Neural Netw ork (CNN) serially connected with an Long-Short T erm Mem- ory (LSTM) net work. Each neural net work has a sp ecific ob jective and is optimized separately as described b elow: 1. CNN Optimization. The mo deling of the spatial comp onen t presen t in video sequences is carried out b y the CNN. This neural netw ork is optimized for a regression task on the dataset. The input and output data consist of space-time frames (in R GB color space with a resolution of 224 × 224 pixels) and interac- tion forces (6-dimensional force vectors), resp ectiv ely . Subsequen tly , the CNN is used as a feature extractor. Its ob jective is to find a compact feature v ector rep- resen tation (a 4096-dimensional vector) that enco des high-lev el abstractions of the input data (space-time frames). (a) Pushing T ask (b) Pulling T ask Figure 4: A sample of raw video frames after the mean frame has been remov ed and the space-time transformation has b een applied, for eac h surgical task. 2. LSTM Netw ork Optimization. The temp oral in- formation present in to ol data and feature v ectors computed b y the CNN is modeled by the LSTM net- w ork. This neural netw ork is optimized for a regres- sion task, b y taking the to ol data (4-dimensional vec- tors) and feature vectors (4096-dimensional v ectors) as input with the ob jective of estimating a tool-tissue in teraction force vector (a 6-dimensional v ector) at eac h time instant. The R CNN architecture is depicted in Fig. 5. This illus- tration sho ws the flo w of data from the input to the output in four stages. First, pre-pro cessing operations are applied to the raw video sequences X v ideo t ∈ < 200 × 300 × 3 and tool data X tool t ∈ < 4 , resulting in U v ideo t ∈ < 224 × 224 × 3 and φ tool t ∈ < 4 , resp ectiv ely . Second, the CNN extracts feature v ectors, φ v ideo t ∈ < 4096 , from the pre-pro cessed input video sequence, U v ideo t . Third, these feature v ectors ( φ v ideo t ) and the normalized to ol data ( φ tool t ) are concatenated, result- ing in a new feature v ector, Φ t ∈ < 4100 . Finally , these new feature vectors are fed in to the LSTM netw ork, which mo dels their temp oral structure to render the estimated force b Y t ∈ < 6 as output. F or the task of feature vector extraction from video se- quences, the pre-trained V GG16 netw ork model prop osed in [35], in the context of image classification, w as fine- tuned on the dataset. Specifically , in this pro cess, the V GG16 netw ork computes a force v ector as output con- 6 Figure 5: The R CNN arc hitecture consists in a CNN serially connected with an LSTM net w ork. First, pre-processing op erations are applied to the input data consisting of raw video sequences ( X video t ) and to ol data ( X tool t ). Therefore, a sequence of raw data ( X video t and X tool t ) of size M r is transformed into a new sequence of pre-pro cessed data ( U video t and φ tool t , resp ectively) of size M p , where M p < M r . The size difference of these t wo sequences results from the space-time transformation applied to raw video frames, whic h is computed by concatenating three consecutive (grayscale) frames spaced in time (in the exp eriments this spacing corresp ond to 15 frames). Subsequently , the CNN extracts feature vectors ( φ video t ) from the pre-processed input video sequence ( U video t ). Afterw ards, these feature v ectors ( φ video t ) and the normalized tool data ( φ tool t ) are concatenated, resulting in a new feature v ector (Φ t ). Finally , these new feature vectors (Φ t ) are fed into the LSTM netw ork, which models their temporal structure to render the estimated force as output ( b Y t ). Figure 6: VGG16 netw ork [35] used for fine-tuning and feature v ector extraction. It consists of 13 conv olutional (kernel size of 3 × 3) and 3 fully-connected lay ers. In this illustration, the conv olutional la yers are group ed in to CONV 1, ..., CONV 5. The fully connected lay ers are referred to as F C6, F C7, and FC8. The Rectifier Linear Unit (ReLU) is used as activ ation function in all lay ers except the output la yer, O9, which is densely connected with a linear activ ation. The n umber of output feature maps for each conv olutional lay er and the size of eac h fully connected lay er are indicated with the last num ber inside the corresp onding layer. At test time, the feature vectors φ video t ∈ < 4096 , are extracted from the lay er F C7 (shown in blue color). ditioned on an input video frame, while the netw ork’s parameters, in all lay ers, are adjusted in the con text of an optimization framework. During the fine-tuning pro- cess, generic features (i.e. computed in the first and sec- ond la yers) are less prone to c hange, while specific features (i.e. computed tow ards the last la yer) will b e adjusted ac- cording to the force estimation dataset. The VGG16 net- w ork, shown in Fig. 5 as the blo c k in blue color, is detailed 7 in Fig. 6. T o matc h the neural netw ork output size with that of the force vectors, the softmax lay er of dimension 1000 (found in the original V GG16 net w ork), was replaced b y a densely connected lay er of dimension 6 (with linear activ ation). The space-time frames ( U v ideo t ) were resized preserving their asp ect ratio (b y centered cropping and resampling op erations), from 200 × 300 to 224 × 224 pix- els (matc hing the netw ork’s input size). After the fine- tuning process is completed, the feature v ectors φ v ideo t , are extracted from the fully-connected lay er F C7 (shown in Fig. 6 in blue color). 4.1. L oss F unction Design The loss function has an important impact in the design of deep neural net works applied to regression tasks. This impact is also extended to the design of regression mo dels based on CNNs. F or instance, human p ose estimation was studied in [36] with a CNN optimized with the standard L 2 loss function (sensitive to outliers) to penalize the distance b et w een predicted and ground-truth upp er-b o dy joint p o- sitions. The same application was in v estigated in [39], by minimizing T ukey’s bi-w eight function to achiev e robust- ness against outliers. Recen tly , [34] prop osed a metho d for predicting future images from a video sequence by the minimization of a loss function that takes into accoun t the Gradient Different Loss (GDL). This method allo ws o vercoming the prediction of blurry images when only the mean squared error is considered in the loss function. In the presen t work, the GDL has been extended to the esti- mation of time-v arying force signals. Therefore, each net- w ork (CNN and LSTM), that defines the prop osed RCNN arc hitecture was optimized separately with a loss func- tion composed of the Ro ot Mean Squared Error (RMSE), and the GDL. The RMSE p enalizes the distance b etw een estimated and ground-truth 6D force vectors, while the GDL the distance b et ween their gradien ts. Intuitiv ely , the RMSE and GDL ease the mo deling of smooth and sharp details found in force/torque signals, resp ectiv ely . The loss function discussed ab o ve, denoted as L ∈ < , is mathematically expressed in Equation (4), where α ∈ [0 , 1] represen ts a trade-off betw een the RMSE ( L RM S E ∈ < ) and GDL ( L GDL ∈ < ). The RMSE e xpressed in Equa- tion (5) computes the distance betw een the ground-truth Y ( j ) i ∈ < and the estimated b Y ( j ) i ∈ < force comp onents, where i indexes the samples in the datase t D and j the N force comp onents. In this equation, ρ ( x i ) ∈ < is a func- tion applied to the scalar x i ∈ < , which is computed for the i -th sample in the dataset. The parameters describ ed for the RMSE are also found in the GDL expressed in Equation (6). As mentioned in the b eginning of this section, the RCNN optimization consists in tw o stages. In the first stage, the V GG16 netw ork (shown in Fig. 6) is fine-tuned with a loss function defined in Equations (4)-(6). This neural net w ork F 1 with parameters W 1 , is represented by Equation (7), where b Y i ∈ < N stands for the estimated force v ector, given as input the i -th space-time frame, U v ideo i . In the subse- quen t stage, the LSTM netw ork F 2 with parameters W 2 shared across T time steps, is trained using the same loss function. This neural netw ork is expressed in Equation (8). It outputs b Y i ∈ < N , that is, the estimated force vector at the time instan t i , giv en as input a sequence of T feature v ectors Φ d , at time steps d = i, i − 1 , i − 2 , ..., i − ( T − 1), (see the LSTM net work depicted in Fig. 5). The selection of ρ ( x i ) in Equation (5) and (6), was dif- feren t for each optimization step. Motiv ated by the work in [15], the VGG16 net work w as fine-tuned with the log- arithmic function stated in Equation (9), where the in- dex i is omitted for clarity in the notation, γ ∈ < is a parameter, and a small p ositiv e constant (which a v oids the ev aluation of the logarithmic function at zero). This function saturates large gradients pro duced by the error b et w een ground-truth and estimated data, adding robust- ness to the optimization. Equation (9) was applied to (5) using γ = 2 . 0, resulting in a function that op erates ov er the mean squared differences b et w een ground-truth and estimated data. In con trast, Equation (9) w as applied to (6) with γ = 1 . 0, resulting in a function that process the absolute difference of residuals. Another design c hoice for ρ ( x i ) consist of a linear function, shown in Equation (10) (where the index i is omitted), whic h pro vides b etter con- v ergence during the LSTM netw ork optimization. L = α L RM SE + (1 − α ) L GDL (4) L RM SE = |D| X i =1 ρ ( x i ) , x i = v u u t 1 N N X j =1 ( Y ( j ) i − b Y ( j ) i ) 2 (5) L GDL = |D| X i =1 ρ ( x i ) , x i = N X j =1 | Y ( j ) i − Y ( j ) i − 1 | − | b Y ( j ) i − b Y ( j ) i − 1 | (6) b Y i = F 1 ( U video i ; W 1 ) (7) b Y i = F 2 (Φ d ; W 2 ) (8) ρ ( x ) = ln ( x γ + ) (9) ρ ( x ) = x (10) 5. Exp eriments The prop osed RCNN architecture was implemen ted in Python using the T ensorflow [40] framework. The exp eri- men ts w ere carried out using multiple graphics pro cessing units, including the NVIDIA Titan X and T esla K80. The dataset samples were split into the training and test sets, as detailed in T able 1. 5.1. Exp eriments Design First, the V GG16 netw ork is fine-tuned with the ob- jectiv e to find a feature v ector representation φ v ideo t ∈ < 4096 , for every space-time frame U v ideo t ∈ < 224 × 224 × 3 (see Fig. 6). Subsequently , in the LSTM net w ork optimization, three t yp es of feature v ectors Φ t (pro cessed at ev ery time step t ), w ere ev aluated as input data: 8 T able 1: Dataset samples used in the exp eriments: (a) Complete dataset including b oth, pushing and pulling tasks, (b) dataset de- scribing only pushing and (c) pulling tasks. Dataset Video Sequences Samples (1) P ercentage Type # Files Duration (2) (a) Complete Dataset T raining 28 ∼ 3 h 19 min 597388 77 % T est 16 ∼ 1 h 179292 23 % T otal 44 ∼ 4 h 19 min 776680 100 % (b) Pushing T asks T raining 16 106.26 min 318776 41 % T est 12 46.48 min 139448 18 % T otal 28 152.74 min 458224 59 % (c) Pulling T asks T raining 12 92.87 min 278612 36 % T est 4 13.28 min 39844 5 % T otal 16 106.15 min 318456 41 % (1) Each sample consists of a video frame (224 × 224 × 3), a 4D tool data vector, and a 6D ground-truth force v ector. (2) Computed as T = N/F r , where T is the video duration, N the total num ber of frames, and F r is the frame rate (50 frames p er second). • Case I . Only to ol data as input: Φ t = φ tool t ∈ < 4 . • Case I I . Only feature v ectors extracted from video sequences as input: Φ t = φ v ideo t ∈ < 4096 . • Case I II . Both, to ol data and feature v ectors extracted from video sequences as input: Φ t = [ φ v ideo t , φ tool t ] 0 ∈ < 4100 . F or eac h aforesaid case, tw o loss functions were ev aluated to inv estigate the con tribution of the RMSE and GDL terms that app ear in Equation (4): • Loss A . Setting α = 0 . 75 results in the loss L = 0 . 75 L RM S E + 0 . 25 L GDL . Thus, more imp ortance is giv en to the RMSE than to the GDL, due to the faster con vergence of the former term compared to the lat- ter. • Loss B . Setting α = 1 . 0 results in the loss L = L RM S E . Therefore, only the RMSE is considered in the optimization. Therefore, a total of six cases, following the format c ase numb er-loss typ e , w ere analyzed during the LSTM net w ork optimization. These cases are referred to as I-A, I-B, I I- A, I I-B, II I-A, and I I I-B. The optimization of the V GG16 and LSTM netw orks is detailed in Sections 5.2 and 5.3, resp ectiv ely . In Section 5.4, additional experiments are describ ed, whose ob jectiv e is to ev aluate the robustness of the prop osed RCNN model. Finally , Section 5.5 explains an exp erimen t in which a time-series mo del is studied in the force estimation task. 5.2. VGG16 Network Fine-tuning The VGG16 model, with weigh ts pre-trained on the Im- ageNet dataset [33], w as fine-tuned ov er 100K iterations with the RMSProp optimizer [41]. Its accuracy w as calcu- lated based on the Mean Relative Error (MRE) p er batc h T able 2: Hyp erparameters used for the V GG16 mo del fine-tuning. Hyp erparameter V alue Learning Rate, λ 1 × 10 − 5 Batch Size, M 50 samples Dropout (F ully-Connected La yers) 50 % Parameter α in Equation (4) 0.8 Parameter in Equation (9) 1/100 Parameter δ in Equation (11) 1 × 10 − 3 Figure 7: Computed loss (in red) and accuracy (in blue), during the fine-tuning of the VGG16 netw ork. stated by Equation (11), where M stands for the num b er of samples in a batc h of data, N represents the n umber of force comp onen ts and δ is the tolerance error. Thus, the MRE w as computed for eac h batch defined in the dataset and av eraged o ver the total num ber of batches. The L 2- norm of the error p er force comp onen t k r j k 2 describ ed b y Equation (12), where j = 1 , ..., N , was also taken into accoun t. T able 2 summarizes the hyper-parameters used during the V GG16 netw ork fine-tuning, whic h were ad- justed exp erimen tally . In particular, α w as set to 0.8 due to the faster conv ergence of the RMSE compared to the GDL. Finally , was set to 1/100 for n umerical stability . T o monitor the evolution of the optimization, the loss func- tion defined in Equation (4) and the logarithm of the er- ror p er force component expressed b y Equation (12) were computed every 250 iterations on the training set. The accuracy was ev aluated on the training and test sets every 10K iterations. The plot of the loss and accuracy is shown in Fig. 7, while the error p er force comp onen t computed for data in the training set, is illustrated in Fig. 8. M RE = 1 M M X i =1 N X j =1 | Y ( j ) i − b Y ( j ) i | δ , M RE ∈ < (11) k r j k 2 = v u u t M X i =1 ( Y ( j ) i − b Y ( j ) i ) 2 , k r j k 2 ∈ < (12) After the V GG16 net w ork w as fine-tuned on the video dataset, visual features φ v ideo t w ere extracted from the fully connected lay er F C7 (see Fig.6), replacing the Rectifier Linear Unit (ReLU) b y the Hyp erb olic T angent (T anh) non-linearit y . By applying the T anh non-linearity , all v al- ues present in the feature vectors are squashed b et ween 9 Figure 8: Logarithm of the error p er force component computed (on data in the training set) during the fine-tuning pro cess. -/+1. This range of v alues is exp ected in the feature vec- tors to b e pro cessed by the LSTM netw ork (during b oth training and inference stages) since the blo ck-input of this net work has the T anh non-linearity as the activ ation func- tion. Each feature vector computed by the V GG16 net- w ork can b e interpreted as a learned representation in the low-dimensional space ( φ v ideo t ∈ < 4096 ) for each in- put video frame that lies in the high-dimensional space ( U v ideo t ∈ < 224 × 224 × 3 ). 5.3. LSTM Network Optimization Three mo dels w ere empirically ev aluated in the force es- timation task: (i) The v anilla LSTM net w ork (with added p eephole connections), (ii) the Coupled-Input F orget Gate (CIF G) v arian t of the LSTM netw ork (LSTM-CIF G) and (iii) the Gated Recurrent Unit (GRU). In terms of conv er- gence and qualit y of prediction, the LSTM-CIF G was su- p erior to the v anilla LSTM and GRU net w orks; the w orst results w ere obtained with the GR U model. Therefore, the LSTM-CIF G netw ork was selected to carry out the exp erimen ts and predict interaction forces betw een surgi- cal instrumen ts and tissues. The LSTM-CIFG net w ork was trained with the RM- SProp optimizer, using the h yp er-parameters listed in T a- ble 3. F or case I, this neural netw ork was designed with only 64 cell units p er la y er due to the lo w dimensionality of the input data ( φ tool t ∈ < 4 ), a voiding ov er-fitting in the training set. In con trast, the neural net w orks designed for cases I I and I I I required higher capacity (i.e. more param- eters) due to the complexity added by the feature v ectors ( φ v ideo t ∈ < 4096 ) in the input data. Therefore, these neural net works were designed with 256 cell units p er la yer. In all the six cases (I-A, ..., I I I-B), drop out w as applied at the output of each lay er as a metho d for regularization to pre- v ent o v er-fitting (a higher v alue was set for the case I). F or eac h case and loss function studied, the total num be r of iterations required to optimize the LSTM-CIFG net work is shown in the last row of T able 3. The optimization T able 3: Hyperparameters used for the LSTM net w ork optimization. Case I II I I I I II II I Loss F unction A (1) B (2) Number of La yers 2 Cells p er Lay er 64 256 256 64 256 256 Time Steps 64 Learning Rate, λ 0.0025 Batch Size, M 512 samples Dropout L1 (3) 75% 25% 25% 75% 25% 25% Dropout L2 (4) 75% 25% 25% 75% 25% 25% Parameter δ (5) 1 × 10 − 3 Iterations (6) 99.0 39.7 57.9 99.0 49.1 26.7 (1) Loss function A: L = 0 . 75 L RM S E + 0 . 25 L GDL . (2) Loss function B: L = L RM S E . (3) Dropout applied to la yer 1 (L1). (4) Dropout applied to la yer 2 (L2). (5) Equation (11) (6) T otal n umber of iterations ( × 1000). w as stopped after observing that the loss v alue reached a plateau, and there w as no visible improv emen t in test set accuracy . The qualit y of the predicted force signals with respect to the ground truth was assessed by considering tw o metrics, the Ro ot Mean Square Error (RMSE) and the Pearson Correlation Co efficien t (PCC). 5.4. R obustness of the R CNN Mo del Tw o exp erimen ts, describ ed b elow, were carried out to ev aluate the robustness of the R CNN mo del. In the first exp eriment, the robustness of the RCNN mo del against Gaussian noise added on tool data w as ev al- uated. As the noise intensit y was strengthened b y increas- ing the v ariance, the deterioration of the estimated force signal quality was measured with the PCC and RMSE met- rics. In the second exp erimen t, the RCNN mo del p erfor- mance was ev aluated by feeding this neural net work with input video sequences pre-pro cessed in offline and real- time mo des. In offline mode, the whole video sequence is a v ailable for computing and applying pre-pro cessing op- erations on raw frames, namely mean frame remov al and space-time transformation. In con trast, in the real-time mo de, only the past frames from video sequences can b e used to p erform such pre-processing op erations. In the con text of a real-time scenario, the computation of a mean frame follo wed by its subtraction from a sp ecific video se- quence represen ts a key pre-pro cessing operation that has an impact on the quality of the estimated force signals. Therefore, in the real-time mo de, the mean frame w as com- puted by av eraging only past frames in a video sequence. On the other hand, in the offline mo de, the mean frame was obtained by av eraging all the frames in a video sequence (in the exp erimen ts describ ed in Sections 5.2 and 5.3, it w as assumed that all video sequences were av ailable offline). Afterw ard, the qualit y of the force estimations that re- sulted from eac h pre-processing mo de w as compared. Tw o samples of video sequences (from the test set) w ere used in 10 this exp eriment, each one related to pushing and pulling tasks. This analysis reveals that the RCNN mo del is suit- able for the task of force estimation in real-time. How ever, there is a small degradation of the qualit y of the estimated force signals with resp ect to the offline mo de. These re- sults will b e discussed in the next section. 5.5. RCNN Mo del vs Time Series Mo del A simpler method (not based on neural netw orks) than the proposed R CNN w as in vestigated in the task of force estimation. F or this purp ose, an Auto-Regressive Moving Av erage Mo del with eXogenous Inputs (ARMAX), com- monly used in the con text of time series mo deling and system identification, w as selected to mo del the complex relationship b et ween the input to ol data and the output in teraction forces. This mo del was implemen ted in MA T- LAB, and its parameters w ere estimated using a com- bination of four line searc h algorithms, sp ecifically , sub- space Gauss-Newton, adaptiv e subspace Gauss-Newton, Lev enberg-Marquardt, and steep est descent. After a single optimization step, the algorithm that provides the lo west cost is selected to estimate the mo del parameters. 6. Results & Discussion The results and discussion of the exp eriments are pre- sen ted in four sections. First, Section 6.1 describ es the results of the LSTM-CIFG net work optimization (whic h outputs the estimated interaction force, b Y t , given as input the feature vectors, Φ t ) and discusses the six cases studied (I-A, ..., I II-B). Then, Section 6.2, rep orts the results from the exp eriments related to the robustness of the RCNN mo del in the conditions describ ed in Section 5.4. After- w ards, Section 6.3, contrasts the force estimation quality of the RCNN model against the ARMAX mo del. Finally , Section 6.4 discusses the key ideas to impro ve the RCNN mo del in the context of real applications. All the results sho wn in T ables 4, 6, and 7 and Figs. 9-12, were computed using the normalized signals provided by the RCNN, which are dimensionless and in the range +/-5. On the other hand, T able 5 shows the force estimation qualit y , mea- sured with the RMSE, in ph ysical units. 6.1. Estimate d F or c e Signals After the LSTM-CIF G net work optimization was com- pleted, the quality of the estimated force signals (in the test se t) was measured with the RMSE and PCC metrics. These metrics are shown in Fig. 9 for each surgical task (pushing and pulling), case (I, I I and I I I) and loss function (loss A and B). F rom this illustration, case I II-A stands out as the b est mo del (solid line in red color), since it has higher PCC v alues and low er RMSE v alues with re- sp ect to the other cases. On the other hand, the metrics for case I I I-B (dotted line in dark red color) fall b ehind those attributed to case I I I-A in a pushing task (left col- umn), while for pulling tasks (right column) they are close in proximit y . F or cases I I-A (solid line in green color) and I I-B (dotted line in dark green color), the PCC and RMSE v alues are sligh tly b ehind the accuracy rep orted for case II I-A. Therefore, the second b est mo del could b e ei- ther, case II-A or I I-B, since their v alues are very close to eac h other. Finally , cases I-A (solid line in blue color) and I-B (dotted line in dark blue color), represen t the worst mo dels. This conclusion is also justified in T able 4, where the maximum, minimum and mean v alues of the metrics displa yed in Fig. 9 are presented (the b est v alues are high- ligh ted in b old). The results presented in Fig. 9 and T able 4 suggest that the R CNN p erforms best when it is optimized with a loss function explicitly designed to mo del smo oth and sharp details found in time-v arying signals. In this work, the RMSE and GDL were used to promote suc h b ehavior, al- lo wing the mo deling of smo oth and sharp (i.e. signal p eaks) details attributed to force/torque signals. Nonetheless, other distance functions could p oten tially be applied for the same purp ose. Moreov er, these results show that it is imp ortan t to provide the RCNN with both video sequences and to ol data during the training and inference stages. The force estimation quality (from the test dataset) cor- resp onding to case II I-A (with the highest accuracy) is de- scrib ed in Fig. 10 and T able 5. The neural netw ork output vs target plot and the PCC are sho wn in Fig. 10, while the RMSE in force and torque units is rep orted in T able 5. In Figs. 9 and 10 is observ ed a high PCC v alue (0.8957) and low error present in the F z force comp onen t related to pushing tasks. Regarding pulling tasks, the estimated force F z has also higher PCC v alue (0.7164) with resp ect to the rest of force comp onen ts. How ev er, it falls below the PCC v alue rep orted for pushing tasks. These results suggest that in teraction forces pro duced b y pushing tasks (smo oth signals) are easier to mo del than those generated b y pulling tasks (irregular signals). A p ossible explanation of these results can b e deduced from the video frames com- puted in the space-time domain, depicted in Fig. 4. Th us, when dealing with pushing tasks, to ol-tissue interactions seem to b e regular and indep enden t of the organs’ geom- etry . F or instance, the p oint of interaction is defined b y a small contact area with an ov al shap e (Fig. 4a). In con- trast, those interactions resulting from pulling tasks are more irregular and highly dependent on the organs’ ge- ometry (Fig. 4b). The slightly imbalance in the dataset samples that represen t each surgical task, may be a small con tributing factor for this result (59% and 41% of the dataset samples corresp ond pushing and pulling tasks, re- sp ectiv ely , as sho wn in T able 1). The results of T able 5 sho w the p otential of the proposed R CNN architecture, up on which new mo dels can b e de- vised. F or real op erational purposes, the RMSE for forces is rep orted to fall below 0.1 N in b oth vision-based [28] and protot yp ed sensors [42]. A sample of estimated forces (from the test dataset) b et w een the surgical instrument and the tissue (normal- ized in the range +/-5), related to case I II-A is shown 11 in Fig. 11a and Fig. 11b for pushing and pulling tasks, resp ectiv ely . Fig. 11a shows that the amplitude of most in teraction forces (estimated for pushing tasks) are close to zero, with the exception of the F z force comp onent. The reason is that the forces are mainly applied along the surgi- cal instrumen t shaft which is aligned with the z axis of the force sensor. It is also observed that the estimated shap e of F z is fully retrieved, although its amplitude differs in some lo cations from the ground-truth signal. By con trast, in Fig. 11b the force and torque components (estimated for pulling tasks) are non-zero, because of the reaction forces applied to the surgical instrumen t when it is grasping a tis- sue. Nonetheless, these signals are more difficult to learn in b oth amplitude and shape. 6.2. R obustness of the R CNN Mo del The results of the robustness of the RCNN mo del against Gaussian noise added on to ol data are sho wn in Fig. 12. In this illustration, it can b e observed that the PCC and RMSE metrics are deteriorated by a small mar- gin as the noise intensit y is strengthened. Nonetheless, this effect is more noticeable in the metrics related to pushing tasks than those of pulling. These results suggest that the RCNN mo del is able to cop e with to ol data corrupted with (Gaussian) noise. F urthermore, they reveal that the estimation of interaction forces heavily relies on the input video sequences. The comparison of the RCNN p erformance by pre- pro cessing video sequences in offline and real-time mo des is summarized in T able 6. The metrics reported in this table corresp ond to a pair of video sequences in the test set. Each video sequence is related to pushing and pulling tasks. The relativ e error rep orted in this table (sho wn as a p ercen tage), rev eals that the p erformance of the RCNN mo del is slightly degraded. A p ositiv e relative error repre- sen ts a deterioration in the qualit y of the metrics in real- time mo de with resp ect to those in offline mo de. The rev erse effect, attributed to negative relative errors, is ob- serv ed in some force comp onen ts whose contribution is nonsignifican t for the task b eing performed (pushing or pulling). 6.3. RCNN Mo del vs ARMAX Mo del The ARMAX and RCNN mo dels are con trasted in T a- ble 7. This table shows the PCC computed from the es- timated force signals (data in the test set) b y the RCNN (case I I I-A) and the ARMAX mo dels, related to each sur- gical task (pushing and pulling). The PCC v alues pre- sen ted in this table reveal that the R CNN mo del is a b et- ter choice than the ARMAX mo del for the task of force estimation. 6.4. R e quir ements for R e al Applic ations F or practical applications, there are three key features of the RCNN mo del that should b e improv ed. First, the T able 4: Maximum, minimum, and mean v alues of the Pearson Cor- relation Coefficient (PCC) and Ro ot Mean Squared Error (RMSE) metrics (shown in Fig. 9) for all the cases studied (I-A, I-B, ..., I II-B). Case Pushing T ask Pulling T ask Max Min Mean Max Min Mean PCC (V alues closer to 1.0 are better) I-A 0.3800 -0.1351 0.0450 0.2110 -0.1732 0.0636 I-B 0.3655 0.0406 0.1263 0.4901 -0.0241 0.2232 II-A 0.8877 0.2474 0.5175 0.7002 0.5492 0.6100 II-B 0.8869 0.2405 0.5097 0.7086 0.5342 0.6024 II I-A 0.8957 0.2674 0.5466 0.7164 0.5252 0.6280 II I-B 0.8469 0.1841 0.4016 0.6860 0.5367 0.6141 RMSE (V alues closer to 0.0 are better) I-A 1.1997 0.3502 0.6407 0.8517 0.4329 0.6509 I-B 1.3149 0.2785 0.5672 0.8278 0.4349 0.6313 II-A 0.4531 0.1732 0.3137 0.7043 0.3321 0.5195 II-B 0.4531 0.1726 0.3098 0.6962 0.3419 0.5161 II I-A 0.4567 0.1598 0.3038 0.6778 0.3199 0.5041 II I-B 0.6592 0.2596 0.3967 0.6756 0.3320 0.5168 T able 5: Case I II-A: Ro ot Mean Squared Error (RMSE), where the force and torque units are expressed in Newtons (N) and Newtons per meter (Nm), respectively . T ask F x F y F z T x T y T z Pushing 0.1230 0.0892 1.1071 0.2810 0.3621 0.0232 Pulling 0.1511 0.1829 0.8894 1.1915 0.5660 0.0381 T able 6: Comparison of the p erformance of the R CNN mo del in offline (O) and real-time (R T) modes, using Pearson Correlation Co- efficient (PCC) and Ro ot Mean Squared Error (RMSE). Mo de F x F y F z T x T y T z Pushing T ask PCC O 0.5816 0.4869 0.9286 0.5860 0.8643 0.2432 R T 0.5873 0.4546 0.8794 0.5480 0.8205 0.2611 Error † -0.99 6.64 5.29 6.49 5.06 -7.34 RMSE O 0.1797 0.2182 0.4528 0.1103 0.1113 0.3874 R T 0.1817 0.2209 0.5918 0.1164 0.1260 0.3864 Error † 1.14 1.22 30.69 5.56 13.27 -0.26 Pulling T ask PCC O 0.7134 0.6635 0.7070 0.6700 0.7214 0.5935 R T 0.6838 0.6845 0.6547 0.6654 0.7238 0.5637 Error † 4.14 -3.16 7.40 0.69 -0.34 5.03 RMSE O 0.3079 0.5915 0.3737 0.6435 0.3423 0.6555 R T 0.3217 0.5814 0.4009 0.6431 0.3489 0.6691 Error † 4.48 -1.70 7.30 -0.07 1.92 2.07 O: Offline Mode R T: Real-Time Mo de † : Relative error in p ercen tage (%) computed by taking v alues in offline (O) mo de as a reference: Rel. E r ror = ( RT /O ) × 100 %. T able 7: Comparison of the Pearson Correlation Coefficient (PCC) computed from the estimated force by the RCNN (case I II-A) vs ARMAX models. Mo del F x F y F z T x T y T z Pushing T ask (PCC) RCNN 0.5864 0.4537 0.8957 0.4246 0.6520 0.2674 ARMAX 0.0949 0.0166 0.0925 0.0378 0.1331 0.1312 Pulling T ask (PCC) RCNN 0.6917 0.5993 0.7164 0.5824 0.6530 0.5252 ARMAX -0.0639 0.2872 0.0593 0.1567 0.0178 0.1709 12 (a) Pushing T asks (b) Pulling T asks Figure 9: F orce estimation quality measured with the Ro ot Mean Squared Error (RMSE) and Pearson Correlation Coefficient (PCC) for each surgical task, pushing (left column) and pulling (right column) tissue. The six cases studied (I-A, I-B, I I-A, II-B, I II-A, and I I I-B) are contrasted in these plots. F or the PCC, values closer to 1.0 are better, while for the RMSE v alues closer 0.0 are desirable. In this illustration, case II I-A (solid line in red color) stands out at the best mo del. (a) Pushing T ask (b) Pulling T ask Figure 10: Case I II-A: Neural net work output vs target plot (for all data in the test set) related to pushing (left column) and pulling tasks (right column). The P earson Correlation Coefficient (PCC) is shown for eac h force component as r . The best line that fits the data is sho wn in magenta color. A p erfect fitting to the data is represen ted by the dotted line in dark blue color. Data p oin ts with low and high error are plotted in blue and red colors, respectively . 13 (a) Pushing T ask (b) Pulling T ask Figure 11: Case I II-A: Sample of estimated interaction forces b et ween to ol and tissue (normalized in the range +/-5) for pushing (left column) and pulling tasks (right column). (a) Pushing T asks (b) Pulling T asks Figure 12: Case II I-A: Deterioration of the R CNN mo del as Gaussian noise is added to to ol data with increased strength (by v arying the standard deviation). The Pearson Correlation Coefficient (PCC) and Root Mean Squared Error (RMSE) metrics (p er force comp onent) related to pushing and pulling tasks are shown on the left and righ t columns, respectively . 14 error rep orted in T able 5, can be reduced (to meet the de- sign requirement of 0.1 N for forces) by taking in to account the pro cessing of depth information. This information can help to improv e the qualit y in the force estimates, sim- ilarly in that the addition of to ol data (i.e. the to ol-tip tra jectory and its grasping status) helped to render force estimates with b etter quality than pro cessing only video sequences. F or this purp ose, a monocular depth estima- tion technique, such as [43], can b e used. Second, tech- niques for pre-pro cessing of video sequences were explored as a first approach to highlight motion due to tool-tissue in teractions and ease the learning pro cess of the neural net work mo del. How ever, an attention mo del, suc h as the one described in [44], represen ts a suitable approac h to au- tomatically learn those image regions that are relev ant to the task of in terest (force estimation). Finally , the RCNN, consisting of the VGG16 netw ork connected in series with the LSTM-CIFG netw ork, results in a mo del with many parameters, which is slow during b oth training and infer- ence stages. F or real-time scenarios, a compact mo del is needed, capable of rendering force estimates without lo os- ing quality . T o this end, techniques for compressing and accelerating deep neural netw orks can be useful. F or in- stance, parameter pruning and sharing, lo w-rank factoriza- tion, transferred/compact conv olutional filters, and knowl- edge distillation [45]. 7. Conclusions & F uture W ork A Recurren t Conv olutional Neural Netw ork (R CNN) for Vision-Based F orce Sensing (VBFS) in rob otic surgery has b een developed. The prop osed neural netw ork was de- signed to estimate forces from mono cular video sequences, as opposed to the ma jority of rep orted works, whic h rely on stereo vision. F or this purp ose, a pre-trained CNN w as used to learn a compact feature v ector represen ta- tion for each frame in a video sequence ( φ v ideo t ), which enco des complex phenomena such as deformation of soft- tissues and sp ecular reflections. This representation to- gether with the to ol data ( φ tool t ), defined a new feature v ector space (i.e. b y concatenating φ v ideo t and φ tool t ), in- creasing the quality in the force estimates. T o enforce a temp oral constrain t, the feature vector space w as mo deled b y an LSTM netw ork. The prop osed RCNN mo del rep- resen ts an alternative to existing approaches and has the p oten tial to ac hieve b etter results in the future. F rom this research work, several exp erimen tal findings can b e highlighted. First, the force estimation task is ac hieved b etter when the CNN and LSTM netw orks are optimized with a loss function that tak es in to accoun t the Ro ot Mean Squared Error (RMSE) and Gradien t Dif- ference Loss (GDL). The intuition b ehind this loss func- tion design is that contin uous and time-v arying signals can b e in terpreted as comp osed of smo oth and sharp details. Therefore, the RMSE addresses the mo deling of smo oth information found in force/torque signals (i.e. sine wa v e- lik e signals), while the GDL promotes the modeling of sharp details attributed to these signals (i.e. signal peaks). Ho wev er, other alternatives to the GDL may result in b et- ter outcomes. F or instance, the adversarial loss, whic h is deriv ed from the Generative Adversarial Netw ork (GAN) framew ork [46], has pro v en useful in the mo deling of high- frequency components found in images. This type of loss can b e adapted to the modeling of sharp details found in force/torque signals. Second, b oth video sequences and to ol data, provide important cues for the estimation of forces than using either source of information alone. Third, this study shows that interaction forces resulting from pushing tasks (c haracterized b y smo oth signals) are eas- ier to mo del and estimate than those pro duced by pulling tasks (characterized b y irregular signals). F ourth, the ex- p erimen t related to the robustness of the RCNN against Gaussian noise added to the to ol data suggests that the R CNN mo del is able to cope with this p erturbation. F ur- thermore, this exp erimen t shows that the RCNN relies hea vily on video sequences to estimate in teraction forces. Fifth, regarding the pre-pro cessing of video sequences in real-time, this exp erimen t sho ws that the R CNN model p erformance is sligh tly degraded with resp ect to that rely- ing on video sequences pre-pro cessed offline. Finally , the ARMAX model is unable to model the complex relation- ship betw een tool data and in teraction forces. Therefore, the R CNN model represents a b etter c hoice in the task of force estimation. The RCNN mo del presen ted in this w ork addresses a sp ecial case of real surgical scenarios. The camera and organs are static while the surgical instrumen t is in mo- tion. The prop osed RCNN mo del has b een ev aluated only in static scenarios, using a dataset enriched with video sequences recorded from differen t viewp oin ts. This allows the neural net work to learn the relation b etw een to ol-tissue in teractions and force under a v ariet y of p ersp ectiv es. A real scenario is usually more dynamic, with the camera mo ving automatically or at surgeon’s will. Moreov er, the organs ma y b e affected b y physiological motion due to breathing and heart b eating cycles. As future work, fiv e researc h directions can b e explored. Some of them hav e already b een discussed in Section 6.4. First, for real op erational purp oses, the force estimation qualit y , sho wn in T able 5, could b e improv ed by tak- ing in to account depth information (i.e. using a tech- nique, suc h as [43]). Second, a mo del designed in a semi- sup ervised learning setting using an Auto-Enco der net- w ork and GANs, represents a potential approach to find a suitable feature v ector representation from video sequences when few data are a v ailable. Third, incorp orating an at- ten tion model [44], would allow automatically select those regions in video sequences that contribute to the learn- ing pro cess (i.e. where to ol-tissue in teractions are presen t), a voiding the need of applying pre-processing op erations (i.e. mean frame remov al and space-time transformation). Moreo ver, this attention mechanism would allo w the ex- tension of the neural netw ork mo del to the estimation of forces related to more complex surgical tasks than push- 15 ing and pulling (i.e. suturing or knot-t ying) and its ap- plication to dynamic scenarios (i.e. by pro cessing motion due to uniquely to ol-tissue in teractions, while suppressing the motion caused by the camera and organs). F ourth, tec hniques for compressing and accelerating deep neural net works should b e inv estigated. They will help in design- ing a compact neural netw ork mo del suitable for real-time scenarios. Finally , a b etter understanding of the RCNN mo del, e.g., by in terpretation of its predictions [47, 48], will certainly help in designing more efficient RCNN ar- c hitectures in the future. Ac kno wledgment The first author of this w ork ac kno wledges the Mexi- can National Council for Science and T echnology (CONA- CYT) and the Mexican Secretariat of Public Education (SEP) for their supp ort in do ctoral studies. The w ork is supp orted by the Ministerio de Econom ´ ıa y Competitivi- dad and the F ondo Europ eo de Desarrollo Regional, ref. DPI2015-70415-C2-1-R (MINECO/FEDER). References References [1] J. H. Palep, Rob otic assisted minimally inv asive surgery , Jour- nal of Minimal Access Surgery 5 (1) (2009) 1–7. [2] P . Gomes, Surgical rob otics: Reviewing the past, analysing the presen t, imagining the future, Robotics and Computer- Integrated Manufacturing 27 (2) (2011) 261–266. [3] A. Marb´ an, A. Casals, J. F ern´ andez, J. Amat, Haptic feed- back in surgical rob otics: Still a challenge, in: R OBOT2013: First Ib erian Robotics Conference: Adv ances in Rob otics, V ol. 1, Springer International Publishing, 2014, pp. 245–253. [4] B. Ba yle, M. Joini´ e-Maurin, L. Barb´ e, J. Gangloff, M. de Math- elin, Rob ot in teraction control in medicine and surgery: Origi- nal results and op en problems, in: Computational Surgery and Dual T raining: Computing, Rob otics and Imaging, Springer New Y ork, 2014, pp. 169–191. [5] A. M. Ok amura, L. N. V erner, T. Y amamoto, J. C. Gwilliam, P . G. Griffiths, F orce feedback and sensory substitution for robot-assisted surgery , in: Surgical Rob otics: Systems Appli- cations and Visions, Springer US, 2011, pp. 419–448. [6] A. M. Ok am ura, Haptic feedback in rob ot-assisted minimally inv asive surgery , Current Opinion in Urology 19 (1) (2009) 102– 107. [7] D. H. Lee, U. Kim, T. Gulrez, W. J. Y oon, B. Hannaford, H. R. Choi, A laparoscopic grasping tool with force sensing capabilit y , IEEE/ASME T ransactions on Mec hatronics 21 (1) (2016) 130– 141. [8] B. Hannaford, J. Rosen, D. W. F riedman, H. King, P . Roan, L. Cheng, D. Glozman, J. Ma, S. N. Kosari, L. White, Raven-ii: An op en platform for surgical rob otics research, IEEE T ransac- tions on Biomedical Engineering 60 (4) (2013) 954–959. [9] S. M. Y o on, M.-C. Lee, C. Y. Kim, Sliding p erturbation observer based reaction force estimation method in surgical robot instru- ment, in: Intelligen t Robotics and Applications: 6th In terna- tional Conference, ICIRA 2013, Pro ceedings, P art I, Springer Berlin Heidelberg, 2013, pp. 227–236. [10] Y. Li, M. Miyasak a, M. Haghighipanah, L. Cheng, B. Han- naford, Dynamic mo deling of cable driven elongated surgical instruments for sensorless grip force estimation, in: IEEE In- ternational Conference on Rob otics and Automation (ICRA), 2016, pp. 4128–4134. [11] S. Sharma, R. Kiros, R. Salakhutdino v, Action recognition using visual atten tion, CoRR abs/1511.04119. [12] J. Donahue, L. A. Hendricks, S. Guadarrama, M. Rohrbach, S. V en ugopalan, K. Saenko, T. Darrell, Long-term recurrent conv olutional net works for visual recognition and description, in: Proceedings of the IEEE Conference on Computer Vision and P attern Recognition (CVPR), 2015, pp. 2625–2634. [13] S. V enugopalan, M. Rohrbac h, J. Donahue, R. Mo oney , T. Dar- rell, K. Saenko, Sequence to sequence – video to text, in: Pro- ceedings of the IEEE International Conference on Computer Vision (ICCV), 2015, pp. 4534–4542. [14] C. Finn, I. J. Goo dfello w, S. Levine, Unsupervised learn- ing for physical interaction through video prediction, CoRR abs/1605.07157. [15] A. Owens, P . Isola, J. McDermott, A. T orralba, E. H. Adelson, W. T. F reeman, Visually indicated sounds, CoRR abs/1512.08512. [16] J. Zhou, X. Hong, F. Su, G. Zhao, Recurren t conv olutional neu- ral netw ork regression for con tinuous pain intensit y estimation in video, CoRR abs/1605.00894. [17] A. Grav es, N. Jaitly , T ow ards end-to-end sp eec h recognition with recurren t neural netw orks, in: Pro ceedings of the 31st In- ternational Conference on Machine Learning (ICML), 2014, pp. 1764–1772. [18] J. Chung, C. Gulcehre, K. Cho, Y. Bengio, Empirical ev aluation of gated recurren t neural netw orks on sequence modeling, in: NIPS 2014 W orkshop on Deep Learning, 2014, pp. 1–9. [19] K. Greff, R. K. Sriv asta v a, J. Koutnk, B. R. Steunebrink, J. Schmidhuber, Lstm: A search space o dyssey , IEEE T ransac- tions on Neural Net works and Learning Systems 28 (10) (2017) 2222–2232. [20] X. W ang, G. Ananthasuresh, J. P . Ostrowski, Vision-based sens- ing of forces in elastic ob jects, Sensors and Actuators A: Phys- ical 94 (3) (2001) 142–156. [21] M. A. Greminger, B. J. Nelson, Mo deling elastic ob jects with neural net works for vision-based force measurement, in: Pro- ceedings of the IEEE/RSJ International Conference on In telli- gent Rob ots and Systems (IROS), V ol. 2, 2003, pp. 1278–1283. [22] F. Karimirad, S. Chauhan, B. Shirinzadeh, Vision-based force measurement using neural netw orks for biological cell microin- jection, Journal of Biomechanics 47 (5) (2014) 1157–1163. [23] J. Rosen, J. D. Brown, L. Chang, M. N. Sinanan, B. Hannaford, Generalized approac h for modeling minimally in v asive surgery as a sto c hastic pro cess using a discrete marko v model, IEEE T ransactions on Biomedical Engineering 53 (3) (2006) 399–413. [24] C. W. Kennedy , J. P . Desai, A vision-based approac h for esti- mating contact forces: Applications to robot-assisted surgery , Applied Bionics and Biomechanics 2 (1) (2005) 53–60. [25] W. Kim, S. Seung, H. Choi, S. Park, S. Y. Ko, J. O. Park, Image-based force estimation of deformable tissue using depth map for single-p ort surgical rob ot, in: 12th In ternational Con- ference on Control, Automation and Systems (ICCAS), 2012, pp. 1716–1719. [26] S. Giannarou, M. Y e, G. Gras, K. Leibrandt, H. J. Mar- cus, G.-Z. Y ang, Vision-based deformation recov ery for intra- operative force estimation of to ol–tissue interaction for neuro- surgery , International Journal of Computer Assisted Radiology and Surgery 11 (6) (2016) 929–936. [27] A. I. Aviles, A. Marban, P . Sobrevilla, J. F ernandez, A. Casals, A recurrent neural netw ork approach for 3d vision-based force estimation, in: 4th In ternational Conference on Image Process- ing Theory , T o ols and Applications (IPT A), 2014, pp. 1–6. [28] A. I. A. Rivero, S. M. Alsaleh, J. K. Hahn, A. Casals, T o w ards retrieving force feedback in robotic-assisted surgery: A sup er- vised neuro-recurrent-vision approach, IEEE T ransactions on Haptics 10 (3) (2017) 431–443. [29] S. Hochreiter, J. Schmidh ub er, Long short-term memory , Neu- ral Computation 9 (8) (1997) 1735–1780. [30] E. Noohi, S. Parastegari, M. efran, Using mono cular images to estimate interaction forces during minimally inv asive surgery , in: IEEE/RSJ International Conference on Intelligen t Rob ots 16 and Systems, 2014, pp. 4297–4302. [31] A. Krizhevsky , I. Sutskev er, G. E. Hinton, Imagenet classifi- cation with deep conv olutional neural networks, in: Adv ances in Neural Information Processing Systems 25, 2012, pp. 1097– 1105. [32] S. Bosse, D. Maniry , K.-R. M ¨ uller, T. Wiegand, W. Samek, Deep neural netw orks for no-reference and full-reference im- age qualit y assessment, IEEE T ransactions on Image Processing 27 (1) (2018) 206–219. [33] O. Russako vsky , J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy , A. Khosla, M. Bernstein, A. C. Berg, L. F ei-F ei, ImageNet Large Scale Visual Recognition Challenge, International Journal of Computer Vision (IJCV) 115 (3) (2015) 211–252. [34] M. Mathieu, C. Couprie, Y. LeCun, Deep multi-scale video pre- diction beyond mean square error, CoRR abs/1511.05440. [35] K. Simony an, A. Zisserman, V ery deep conv olutional netw orks for large-scale image recognition, in: International Conference on Learning Representations, 2015, pp. 1–14. [36] T. Pfister, K. Simon yan, J. Charles, A. Zisserman, Deep conv o- lutional neural netw orks for efficient p ose estimation in gesture videos, in: Pro ceedings of the Asian Conference on Computer Vision (A CCV), 2014, pp. 538–552. [37] G. Pico d, A. C. Jambon, D. Vinatier, P . Dub ois, What can the operator actually feel when p erforming a laparoscop y?, Surgical Endoscopy And Other In terven tional T echniques 19 (1) (2005) 95–100. [38] Itseez, Op en Source Computer Vision Library (OpenCV), https://opencv.org/ (2018). [39] V. Belagiannis, C. Rupprech t, G. Carneiro, N. Nav ab, Robust optimization for deep regression, in: Pro ceedings of the IEEE International Conference on Computer Vision (ICCV), 2015, pp. 2830–2838. [40] M. Abadi, A. Agarw al, P . Barham, E. Brevdo, Z. Chen, C. Citro, G. S. Corrado, A. Davis, J. Dean, M. Devin, et al., T ensorflow: Large-scale machine learning on heterogeneous dis- tributed systems, arXiv preprint [41] T. Tieleman, G. Hinton, Lecture 6.5—RmsProp: Divide the gradient by a running av erage of its recen t magnitude, COURS- ERA: Neural Netw orks for Mac hine Learning (2012). [42] U. Kim, D.-H. Lee, W. J. Y oon, B. Hannaford, H. R. Choi, F orce sensor integrated surgical forceps for minimally inv asiv e robotic surgery , IEEE T ransactions on Rob otics 31 (5) (2015) 1214–1224. [43] C. Godard, O. Mac Aodha, G. J. Brostow, Unsup ervised monocular depth estimation with left-righ t consistency , in: Pro- ceedings of the IEEE Conference on Computer Vision and Pat- tern Recognition (CVPR), 2017, pp. 270–279. [44] K. Xu, J. Ba, R. Kiros, K. Cho, A. Courville, R. Salakhudi- nov, R. Zemel, Y. Bengio, Show, attend and tell: Neural image caption generation with visual attention, in: International Con- ference on Machine Learning, 2015, pp. 2048–2057. [45] Y. Cheng, D. W ang, P . Zhou, T. Zhang, Model compression and acceleration for deep neural netw orks: The principles, progress, and challenges, IEEE Signal Pro cessing Magazine 35 (1) (2018) 126–136. [46] I. Go o dfello w, J. Pouget-Abadie, M. Mirza, B. Xu, D. W arde- F arley , S. Ozair, A. Courville, Y. Bengio, Generativ e adv ersarial nets, in: Adv ances in neural information processing systems, 2014, pp. 2672–2680. [47] S. Bac h, A. Binder, G. Mon tav on, F. Klausc hen, K.-R. M ¨ uller, W. Samek, On pixel-wise explanations for non-linear classi- fier decisions by lay er-wise relev ance propagation, PLOS ONE 10 (7) (2015) e0130140. [48] G. Mon tav on, W. Samek, K.-R. M ¨ uller, Metho ds for in terpret- ing and understanding deep neural netw orks, Digital Signal Pro- cessing 73 (2018) 1–15. 17
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment