저자원 음성 언어 이해를 위한 캡슐 네트워크
본 논문은 사용자가 직접 시연을 통해 학습하는 명령‑제어 시스템에 캡슐 네트워크를 적용하여, 제한된 학습 데이터만으로도 높은 정확도를 달성한다는 것을 입증한다. 기존 NMF 기반 방법과 최신 인코더‑디코더 모델을 비교했을 때, 특히 소량 데이터 상황에서 우수한 성능을 보인다.
저자: Vincent Renkens, Hugo Van hamme
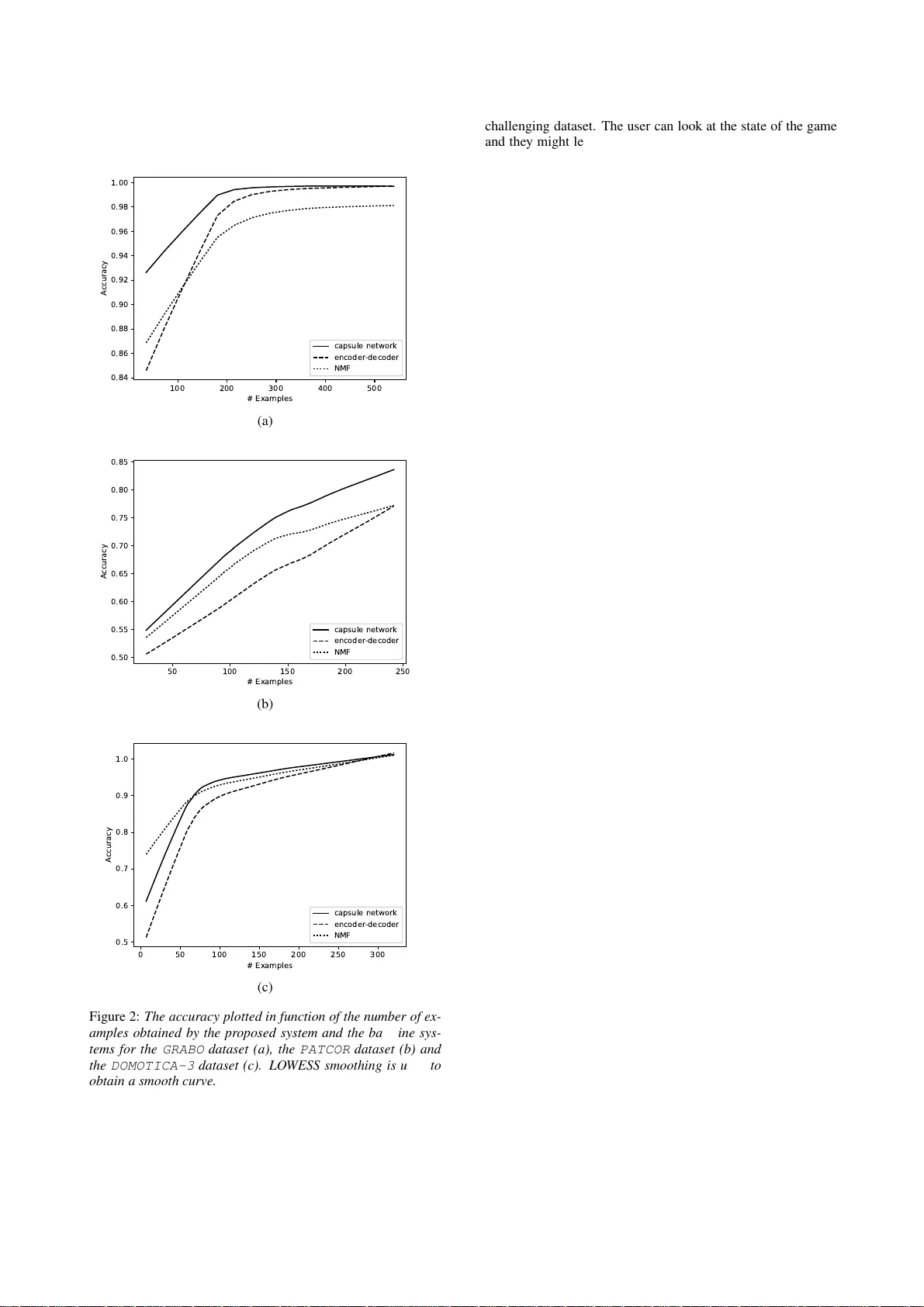
본 논문은 명령‑제어용 음성 언어 이해(SLU) 시스템을 설계하고, 특히 사전 학습 데이터가 전혀 없거나 매우 적은 상황에서도 사용자가 직접 시연을 통해 시스템을 학습시킬 수 있는 방법을 제안한다. 기존의 ASR‑SLU 파이프라인은 언어·발음·억양에 대한 사전 가정을 필요로 하며, 특히 발음 장애가 있는 사용자의 경우 오류가 급증한다. 이러한 한계를 극복하기 위해 저자들은 ‘사용자 시연 기반 학습’이라는 프레임워크를 채택했으며, 여기서 핵심은 음성 입력을 바로 의미 표현(액션 타입 + 인자)으로 매핑하는 것이다.
제안된 모델은 크게 세 부분으로 구성된다. 첫 번째는 2‑계층 양방향 GRU 인코더로, 40차원 멜 필터뱅크와 에너지, 1·2차 미분 특징을 입력받아 고수준 시퀀스 특징을 추출한다. 인코더는 각 계층 사이에 스트라이드 2를 적용해 시퀀스 길이를 절반으로 줄이며, 이는 연산 효율성을 높이고 캡슐 레이어에 전달되는 토큰 수를 감소시킨다. 두 번째는 어텐션‑디스트리뷰터 모듈이다. 어텐션은 시그모이드 함수를 통해 각 시간 단계의 중요도를 α_t 로 계산하고, 디스트리뷰터는 소프트맥스 함수를 이용해 각 시간 단계가 어느 숨겨진 캡슐에 기여할지를 δ_t 로 할당한다. 이 두 가중치를 곱해 각 캡슐 i에 대한 컨텍스트 벡터 q_i 를 얻는다.
세 번째는 캡슐 레이어와 동적 라우팅이다. 컨텍스트 벡터 q_i 는 선형 변환 후 스쿼시 함수 σ(·)를 통과해 캡슐 벡터 s_i 로 변환된다. 스쿼시 함수는 벡터의 노름을 0~1 사이로 압축해 ‘존재 확률’과 ‘특성 방향’을 동시에 표현한다. 이후 각 숨겨진 캡슐 s_i 는 출력 캡슐 O_j 로의 예측 벡터 p_ij = W_ij^p·s_i 를 만든다. 동적 라우팅 알고리즘은 초기 커플링 로짓 B 를 학습 가능한 값으로 두고, 각 라운드에서 소프트맥스된 커플링 계수 c_ij 로 가중합을 수행해 출력 캡슐 o_j 를 계산한다. 라우팅 과정에서 p_ij·o_j (내적) 값을 로짓에 더해 ‘합의’를 강화함으로써, 서로 유사한 예측을 하는 숨겨진 캡슐들이 같은 출력 캡슐에 집중하도록 만든다. 최종 라벨 확률 l_j 는 출력 캡슐 o_j 의 노름이며, 마진 손실 L = Σ_j
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기