Capsule Networks for Low Resource Spoken Language Understanding
Designing a spoken language understanding system for command-and-control applications can be challenging because of a wide variety of domains and users or because of a lack of training data. In this paper we discuss a system that learns from scratch …
Authors: Vincent Renkens, Hugo Van hamme
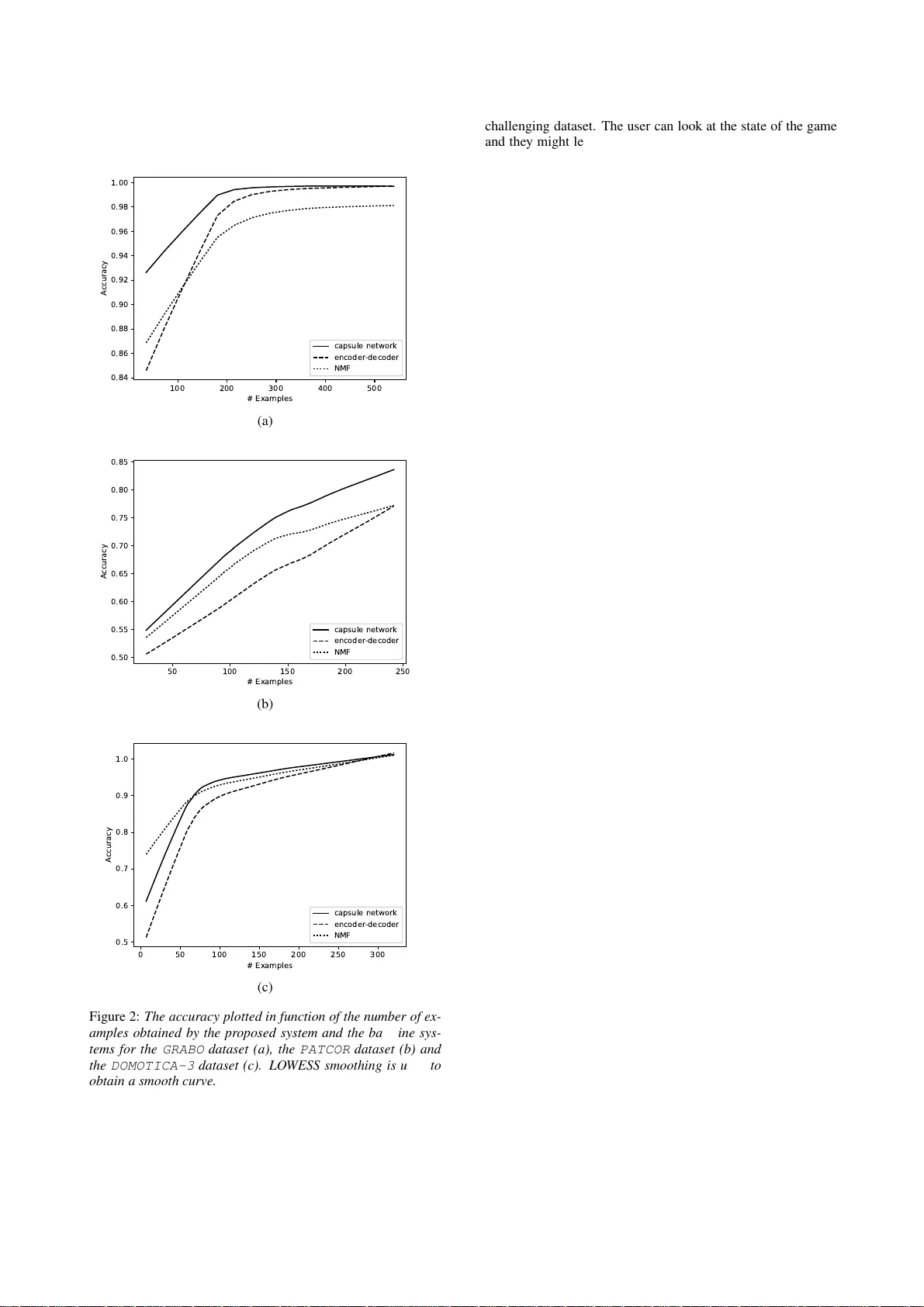
Capsule Networks f or Low Resour ce Spok en Language Understanding V incent Renkens, Hugo V an hamme Department Electrical Engineering-ESA T , KULeuven Kasteelpark Arenberg 10, Bus 2441, B-3001 Leuven B elgiu m vincent.renke ns@esat.kuleu ven.be, hugo.vanhamme @esat.kuleuve n.be Abstract Designing a spoken language understanding sys tem for command-an d-control applications can be challenging because of a wide v ariety of domains and users or because of a lack of training data. In t his paper we discuss a system that learns from scratch from user demonstrations. This method has the adv an- tage that the same system can be used for many domains and users without m odifications and that no training d ata is required prior to deploy ment. The user is required to train the system, so for a user friendly experience it is crucial to minimize the required amount of data. In this paper we inv estigate whether a capsule network can mak e efficient use of the limit ed amount of available training data. W e compare the prop osed model to an approach based on Non-negati ve Matrix Factorisation which is the state-of-the-art in this setting and another deep learning approach that w as rec ently introd uced for end-to-end spok en language understand ing. W e sho w that the proposed model out- performs the baseline models for three command-and-con trol applications: controlling a small robot, a vocally guided card game and a home automation task. Index T erms : Spoken Language Understanding, Capsu le Net- works, Deep L earning, Low Resource 1. Intr oduction In this paper we will discuss a spoken language understand- ing (SLU) system for command-and-control applications. The system can learn to map a spok en command to a task description. This description can then be giv en to some agent that can ex ecute the task. An example for a command in a home automation application would be “T urn on the light in the kitchen” . This could then be mapped to the task Switch(kitche n light, on) . The task is r epresented by the type of action, Swi tch in this example, and a collection of ar guments, kitchen light and on in this example. The SLU system learns to map the spok en command to a semantic representation, which is a collection of l abels, one for the action type and one for each of the ar guments. Many approaches t o this problem consist of an Auto- matic Speech Recognition (AS R) component that transforms the spoken command into a textual transcription and a Spoken Language Understanding (SL U) compon ent that maps the textual transcription to the semantic representation [1, 2]. Such a system mak es some assumptions abou t the user and how they are going to use the system. The ASR is typically trained for a single language, so it is assumed that the user will use this language. If the user has a pronou nced accent or if the user has a speech impairment the ASR will often introduce a lot of errors [3], which make s it difficult for the SLU componen t to correctly determine the task to be performed. This is especially difficu lt for speech impaired users whose speech impairment is cau sed by another cogniti ve or motor disability . Users with such a disability often hav e dif ficulties using device s, so speech has a lar ge potential to improve their way of li ving. Simple SLU componen ts, like one based on k ey phrases assume that the user i s going to use some predefined com- mands. From a design perspecti ve choosing these ke y phrases can be dif ficult to impossible for some applications. More adv anced methods based on Recurrent Neural Networks (RNN) [4] or Conditional Random Fi el ds [5] need lots of data to train, which may not be av ailable in the domain of the application. As an alternati ve we propose a system that learns to un- derstand spoken commands directly from the user through demonstrations. The user can train the system by giving a spoken command and subsequ ently demonstrating t he correspondin g task through an al t ernativ e interface to the agent. The command “T urn on the light in the kitchen” can be demonstrated by pressing t he bu tton to turn on the light. This demonstration can then be con verted to a semantic rep- resentation. The system directly maps speech to the semantic representation, without going through an intermediate textual representation. The system is trained using on ly the data from the user , which means that the assum ptions and restrictions mentioned above do not apply . The disadv antage of such a system is that the user needs to give some examples, which requires some effo rt on t heir part. In order to minimize this effo rt it is crucial that the required amou nt of training data is as small as possible. In the past we have proposed a metho d based on N on- Negati ve Matrix Facto risati on (NMF) for this task [6, 7]. NMF performs significantly better than other , more con ven- tional approaches like Hidden Mark ov Model (HMM) based approaches [8]. There are ho wev er limitations t o the NMF approach. For example, the NMF approach uses a bag-of-wo rds representation. It does not consider the order in which the words occur , which can be important to correctly interpret the command [9]. Deep learning based approache s ha ve shown great performance on many speech-related tasks [10, 11, 12]. These models are based on Deep Neural Networks or R NN s and requ ire a lot of data to tr ain, which is not av ailable in this setting. In this paper we propose to use a capsule network wi th a bidirectional RNN encoder . Capsule networks were proposed in [13] and it is suggested that they make more efficient use of the training data, making them better suited for this task. W e will discuss our prop osed model in section 2. In sec- tion 3 we will describe the performed experiments and we will e valuate the results in section 4 . Finally we will end with some conclusions in section 5. F Encoder H Attention Distributor · Squash Layer S Dynamic Routing O α δ Q Figure 1: A sch ematic of the prop osed model 2. Model Our proposed model is presented in figure 1. The inputs to the model are a sequence of filter bank features F . The inpu ts are first encoded into high lev el features H . For this work a multi-layered bidirectional GR U [14] is used for this purpose. The sequence is Sub-sampled with a stride of 2 between the layers of the encoder as proposed in [15]. The sequence of high lev el features i s therefore shorter than the sequence of input features. The sequence of high level features is con verted into capsules S using an attention mechanism [16] and a distributor . The concept of capsules was proposed in [13]. A capsule is represented by a vector . The direction of the vector r epresents the latent properties of the capsules. The norm of the vector lies between 0 and 1 and represents a probability that the capsule is present or not. The attention module is used to determine a weight rep- resenting the importance of each timestep. Not the entire sequence is important to determine the meaning of the utter- ance (e.g. words l ike “please”). The attention module gives the model the capability to filt er out the unimportant parts. The attention weights are determined using a sigmoid layer with a single output on the high le vel features: α t = sigmoid ( w a · h t + b a ) (1) α t is the attention weight for time t , w a and b a are the weights and bias of the si gmoid layer and h t contains the high lev el features for time t . The distribu tor is used to distri bute each timestep to the hidden capsules S . A distribution weight is determined from each timestep to each hidden capsu le. S imilar to the attention weights, the distribution weights are determined using a softmax layer on the high level features: δ t = softmax ( W d · h t + b d ) (2) δ t contains the distribution weights for timestep t , one for each hidden capsule. W d and b d are the weights and biase s of the softmax layer . Using the attention and distr ibution weights a contex t vector is created for each hidden capsu le i : q i = X t α t δ ti h t (3) Where q i is the contex t vector for capsule i . T he conte xt vectors are then con v erted to the capsule representation using a squash layer . T he squash layer is a linear transformation followed by a squashing function: s i = σ ( W s · q i ) (4) s i is the vector representation for capsule i , W s are the weights of the squashing layer . Notice that no bias is included in the linear t r ansformation to ensure that contex t v ectors with a small norm result in capsules with a small norm. σ ( · ) is the squashing function as defined in [13]: σ ( x ) = || x || 2 1 + || x || 2 x || x || (5) The squashing function ensures that the norm of the vector rep- resentations lies between 0 and 1. The output capsules O are computed using the iterative dynamic routing algorithm pro- posed in [13]. Ev ery hidden capsule will predict the output of e very outpu t capsule using a linear transformation: p ij = W p ij · s i (6) p ij is the predicted vector representation of output capsule j from hidd en capsule i and W p ij contains the weights for this prediction. The output capsules are computed using the coupling coef ficients C . The coupling coefficients represent ho w strongly linked the hidden capsules are to the output capsules. The coupling coef ficients are computed using a softmax function on the coupling logits B . The coupling logits are initialised wi t h learnable value s and then iterativ ely fine tuned with t he dynamic routing algorithm: Define v ariable B (1) ; fo r n = 1 : N d o For all hidden capsu les i : c i = softmax ( b ( n ) i ) ; For all output capsules j : o j = σ ( P i c ij p ij ) ; For all logits b ( n ) ij in B ( n ) : b ( n +1) ij = b ( n ) ij + p ij · o j ; end Algorithm 1: Dynamic routing algorithm At each iteration the output capsules are computed with the current connection logits. T he connection logits are updated based on the agreement between the output capsule and the prediction. The agreement is measured using the scalar product. If the agreement between a prediction from a hidden capsule with an output capsule is large t he connection logit will increase. The dynamic routing algorithm will look for groups of simil ar predictions for each output capsule. If there is a group of predictions that agree for a certain outp ut capsule the capsule will become activ e and its norm will be close to one. If there is no such group the capsule will be inacti ve and its norm close to zero. The probabilities of the output labels l are finally com- puted using t he norm of the output capsules: l j = || o j || (7) The network i s trained by minimizing the margin loss: L = X j t j max(0 , 0 . 9 − l j ) + (1 − t j ) max(0 , l j − 0 . 1) (8) where t j is the target for label j , which is either 0 or 1. 3. Experiments 3.1. Datasets The proposed model is tested and compared to the baselines for three datasets, in the do mains of robotics, a card game and home automation. The GRABO [17] dataset contains English and Dutch commands gi ven to a robot. The robot can mov e in its en vironment, pick up objects and use a laser pointer . T ypical commands gi ven to the robot are “ mo ve t o position x ” or “ gr ab object y ”. Output labels include positions i n the world, the actions the robot can take etc. There are a total of 30 output labels. Data was recorded f rom 11 speak ers issuing 36 diffe rent commands with 15 repetitions. The PATCOR dataset [18] contains Dutch utterances from a vocally guided card game called Patience. The players can mov e cards or get ne w cards from the deck. T ypical commands are “ Put car d x on card y ” or “ New car ds ”. T he outpu t labels are the v alue and suit of t he card being mo ved, the target position etc. T here are a total of 38 output labels. Data was recorded from 8 speak ers. The DOMOTI CA-3 dataset [7] is a follow up of the DOMOTICA-2 dataset [18] and contains utterances from Dutch dysarthric speak ers using voice commands in a home automation task. T ypical commands are “ open door x ” or “ turn on light y ”. The output labels include all the lights, doors and all the actions the system can take. There is a total of 25 output labels. Dat a was recorded from 17 speak ers with varying lev els of dysarthria. Because speaking costs more effort for some speak ers the amount of data per speak er v aries greatly . 3.2. Methodology W e use cross-validation to get reliable experimental result. First, we split the data in multiple blocks. The blocks are chosen such that they are maximally semantically similar . This is done by minimizing the Jensen-Shannon Div ergence between the blocks. W e then create the training set by taking the data from a random set of blocks and the rest of the data is put in the testing set. W e create learning curves by putting an increasing number of blocks in the training set. T o get more reliable results we do 5 experiments for each number of blocks in the training set, each time with a dif ferent set of random blocks. 40 Mel filter banks + energy including fi rst and second order deriv ativ es with a window size of 25 ms and a windo w step of 10 ms are used as input features. A v oice activity detector is used to remov e long silences from the commands. The encoder consists of 2 bi-directional GR U layers with 256 units. There are 32 hidden cap sules in S w i th 64 dimensions. There is one output capsule wit h a dimension of 8 for every output label. In t otal the network has around 2.2 million parameters. T he model is trained with batches of 16 utterances for 30 epochs. Adam [19] is used as the optimization method with a l earning rate of 0.001. 3.3. Baseline As a first baseline we use the method proposed in [6, 7]. This method is based on Non-ne gativ e Matrix Factorisation (NMF) that i s used to decompose the i nput utterance into recurring patterns, which can be thought of as words. These wo rds are linked to t he output labels and in such a way a dictionary of words corresponding to the labels is created . This method achie ves st at e-of-t he-art performance for t his task [8 ]. Alternativ ely we use a different deep l earning approac h proposed in [12] as a second baseline. This model was pro- posed in the context of end-to-en d NLU to predict domain and intent labels for spoken utterances. The model consists of the same encoder , with the same number of layers and units, used in the current paper and a decoder . The decoder aggregates the high l evel f eatures with max-pooling then applies a hidde n ReLU layer with 102 4 units followed by a sigmoid output layer to get the probabilities of the output labels. This network has aroun d 2.3 million parameters. Adding more layers to the encoder did not improve t he r esults. W e w i ll refer to this model as “encoder-deco der” in the results section. 4. Results In figure 2 the accuracy of the mode ls i s plotted as a function of the number of examples in the training set for all three data sets. In most cases the proposed model outperforms the baseline models. Only for the DOM OTICA-3 dataset, for a very small training set, t he NMF model outperfo rms the capsule network. This may be caused by the fact that D OMOTICA-3 contains dysarthric speech, which is less consistent in terms of timing and pronunciation. NMF does not suf fer a lot from this variability , but t he GR U encod er might hav e more trouble modelling it. Howe ver , with a little bit more data the capsule network catches up with NMF and performs slightly better . For the GRABO dataset all models achiev e a high accuracy , but the capsule network performs best. The encoder-decod er model does not perform well for small amounts of data, but catches up if more data is av ailable. For the PATCOR dataset the accuracy for all models is significantly lo wer . This is becau se PA TCOR is a more 1 0 0 2 0 0 3 0 0 4 0 0 5 0 0 # Ex a m p l e s 0 . 8 4 0 . 8 6 0 . 8 8 0 . 9 0 0 . 9 2 0 . 9 4 0 . 9 6 0 . 9 8 1 . 0 0 Ac c u r a c y c a p su l e n e tw o r k e n c o d e r- d e c o d e r NM F (a) 5 0 1 0 0 1 5 0 2 0 0 2 5 0 # Ex a m p l e s 0 . 5 0 0 . 5 5 0 . 6 0 0 . 6 5 0 . 7 0 0 . 7 5 0 . 8 0 0 . 8 5 Ac c u r a c y c a p su l e n e tw o r k e n c o d e r- d e c o d e r NM F (b) 0 5 0 1 0 0 1 5 0 2 0 0 2 5 0 3 0 0 # Ex a m p l e s 0 . 5 0 . 6 0 . 7 0 . 8 0 . 9 1 . 0 Ac c u r a c y c a p su l e n e tw o r k e n c o d e r- d e c o d e r NM F (c) Figure 2: The accuracy plotted in function of the number of ex- amples obta ined by the pr oposed system and the baseline sys- tems for the GRAB O dataset (a), the PATCOR dataset (b) and the DOMOTICA-3 dataset (c). LO WESS smoothing is used to obtain a smooth curve . challenging dataset. The user can look at the state of the game and they might leave out information in t he command because it i s obvio us from the state of the game. For exa mple if t here i s only on e 3 that can be mov ed they migh t not mention the suit of the card t o be mov ed. The st at e of the game is howe ver not av ailable to the NLU system in this setup, which introduces errors. In Dutch there are seve ral names for each card. Some users alt ernate between these names, which also makes i t more challenging for t he NLU. Even on this more challenging task the capsule network performs better than the NMF model, especially with more training data. The encoder-decode r seems to hav e trouble with this more challenging task, which supports the findings in [20] It is remarkable that the capsule network performs so well for only a couple dozen examples, which amounts to a few minutes of speech. These experiments seem to support the hypothesis that capsule networks make more efficient use of the tr ai ning data, especially when you compa re t he capsule network with the enco der-decoder for small amounts of data. 5. Conclusions In this pap er we proposed a capsule network for low resource spok en language understanding for command-and-control ap- plications. Only the data from the user is used to train the sys- tem, making it able to adapt to the domain of the application and the speaker without nee ding training data prior t o deploymen t. The proposed model has been sho wn to significantly outperform the pre vious state-of-the-art. Even for small amounts data, a f ew dozen utterances, the capsu le netw ork performs well. In future work we will look more closely at the reason why the capsule network works well, especially for so lit tle t r aining data. It might also be interesting to inv estigate using a distributer to- gether with an attention mechanism for attention based speech recognition. 6. Acknowledgements The Research in this work was funded by PhD grant 151014 of the Research Foundation F landers (FWO) 7. Refer ences [1] Y .-Y . W ang, L. Deng, and A. Acero, “Spoken language under - standing , ” IEEE Signal Pr ocessing Ma gazine , vol . 22, no. 5, pp. 16–31, 2005. [2] R. De Mori, F . Bechet, D. Hakkani-T ur , M. McT ear , G. Riccardi, and G. T ur , “Spoke n language understanding, ” IEEE Signal Pr o- cessing Maga zine , v ol. 25, no. 3, 2008. [3] H. Christensen, S. Cunn ingham, C. Fox, P . Green, and T . Hain, “ A comparat iv e study of adapti ve , automatic rec ognition of di s- ordered speech , ” in Thirteenth Annual Conferen ce of the Interna- tional Speec h Communication As sociati on , 2012. [4] M. Dinarelli and I. T elli er , “I mproving recurr ent neural networks for sequence labelli ng, ” arXiv pr eprint arXiv:1606.02555 , 2016. [5] C. Raymond and G. Riccardi , “Gene rati ve and discriminat ive al- gorithms for spoke n langua ge underst anding, ” in Eight h Annual Confer ence of the International Spee ch Communi cation Associa- tion , 2007. [6] J. Gemmeke, B. Ons, N. M. T essema, H. V an hamme, J. V an de Loo, G. De Pauw , W . Daelemans, J. Huyghe, J. Derboven, L . V ue- gen, B. V an Den Broeck et al. , “Sel f-taught assisti ve voca l inter- fac es: An ove rview of the ala din project , ” in Proc eedings Inte r- speec h 2013 . ISCA, 2013, pp. 2038–2043. [7] B. Ons, J. F . Gemmeke , and H. V an hamme, “The self-taught vo- cal interfa ce, ” EURA SIP J ournal on Audio, Speec h, and Music Pr ocessing , vol. 2014, no. 1, p. 43, 2014. [8] J. F . Gemmeke, S. Sehgal, S. Cunning ham, and H . V an hamme, “Dysarthri c vocal inte rfaces with minimal training data, ” in Spo- ken Langua ge T echnol ogy W orkshop (SLT), 2014 IEE E . IEEE, 2014, pp. 248–253. [9] V . Renke ns and H. V an hamme, “W eakly supervised learn- ing of hidden marko v models for spoken lang uage acquisition, ” IEEE/ACM T ransac tions on Audio, Speec h and Languag e Pro- cessing (T ASLP) , vol. 25, no. 2, pp. 285–295, 2017. [10] G. Hinton, L . Deng, D. Y u, G. E. Dahl, A.-r . Mohamed, N. Jaitly , A. Senior , V . V anhouck e, P . Nguyen , T . N. Sainat h et al. , “De ep neural netwo rks for acoustic m odeling in speech recognit ion: The shared vie ws of four research groups, ” IEE E Sign al Pr ocessing Magazi ne , vo l. 29, no. 6, pp. 82–97, 2012. [11] J. K. Chorowski, D. Bahdanau, D. Serdyuk, K. Cho, and Y . Ben - gio, “ Attenti on-based models for spe ech recogni tion, ” in Ad- vances in neural information proce ssing systems , 2015, pp. 577– 585. [12] D. Serdyuk, Y . W ang, C. Fue gen, A. Kumar , B. Liu, and Y . Ben- gio, “T oward s end -to-end spoken language understanding, ” arXiv pre print arXiv:1802.08395 , 2018. [13] S. Sabour , N. Frosst, and G. E . Hinton, “Dynamic routing between capsule s, ” in Advances in Neural Information Processin g Systems , 2017, pp. 3859–3869. [14] K. Cho, B. V an Merri ¨ enboer , C. Gulcehre, D. Bahda nau, F . Bougares, H. Schwenk, and Y . Bengio, “Learning phrase repre- sentati ons using rnn encoder -decoder for statistic al machine trans- latio n, ” arXiv pr eprint arXiv:1406.1078 , 2014. [15] D. Bahdanau, J. Choro wski, D. Serdyuk, P . Brakel, and Y . Ben- gio, “End-to-end attention -based large vocab ulary speech recog- nition, ” in A coustic s, Speec h and Signal Pr ocessing (ICASSP), 2016 IEEE International Confer ence on . IEEE, 2016, pp. 4945– 4949. [16] D. Bahdana u, K. Cho, and Y . Bengio, “Neural machine trans- latio n by jointl y learning to alig n and transl ate, ” arXiv preprint arXiv:1409.0473 , 2014. [17] V . Ren kens, S. J anssens, B. Ons, J. F . Gemmeke, and H. V an hamme, “ Acqui sition of ordinal words using weakly su- pervised nmf, ” in Spoke n Languag e T echno logy W orkshop (SLT), 2014 IEEE . IEEE, 2014, pp. 30–35. [18] N. M. T essema, B. Ons, J. va n de Loo, J. Gemmeke, G. De Pauw , W . Daeleman s, and H. V an hamme, “Metadata for corpora patco r and domotic a-2, ” 2013. [19] D. P . Kingma and J. Ba, “ Adam: A method for stochasti c opti- mizatio n, ” arXiv pr eprint arXiv:1412.6980 , 2014. [20] V . V uk otic, C. Raymond, and G. Grav ier , “Is it time to switch to word embed ding and recurre nt neural netw orks for spoke n lan- guage understanding? ” in InterSpeec h , 2015.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment