계층형 딥 컨볼루션 신경망으로 대규모 이미지 인식 성능 향상
** HD‑CNN은 이미지 분류를 두 단계(거친‑세밀)로 나누어, 쉬운 클래스는 거친 분류기만으로 처리하고, 혼동이 잦은 클래스는 전용 세밀 분류기로 추가 판단한다. 공통 레이어를 공유하고, 사전‑학습·전역‑미세조정을 결합한 손실함수와 조건부 실행·파라미터 압축 기법으로 메모리·시간 비용을 제한하면서 CIFAR‑100·ImageNet에서 기존 CNN 대비 Top‑1 오류를 각각 2.65 %, 3.1 %·1.1 % 낮추는 성과를 보였다. …
저자: Zhicheng Yan, Hao Zhang, Robinson Piramuthu
**
본 논문은 이미지 분류 작업에서 클래스 간 시각적 구분도가 크게 다르다는 점에 주목한다. 기존의 딥 컨볼루션 신경망(CNN)은 모든 클래스를 하나의 평면(N‑way) 구조로 학습시켜, 어려운 클래스 쌍을 구분하기 위한 전용 파라미터를 제공하지 못한다. 이를 해결하고자 저자들은 **Hierarchical Deep Convolutional Neural Network (HD‑CNN)** 라는 새로운 계층형 구조를 제안한다.
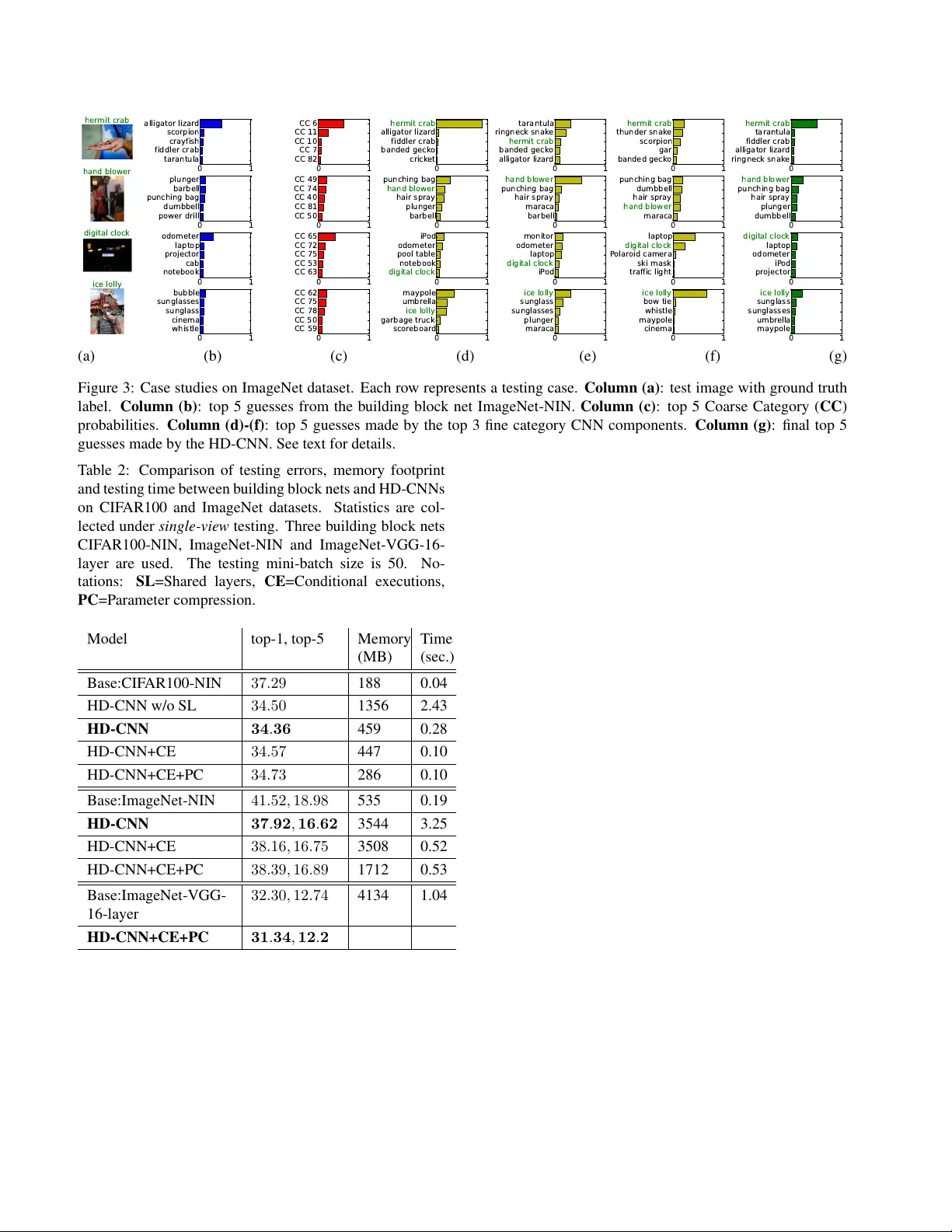
HD‑CNN은 크게 네 부분으로 구성된다. (1) **Shared Layers**: 이미지의 저수준 특징을 추출하는 앞부분 레이어는 모든 컴포넌트가 공유한다. (2) **Coarse Category Component (B)**: 전체 클래스를 K개의 거친 카테고리로 묶어, 이미지가 어느 거친 그룹에 속하는지를 예측한다. (3) **Fine Category Components (F₁…F_K)**: 각 거친 카테고리에 대응하는 세밀 분류기로, 해당 그룹 내에서 혼동이 잦은 세부 클래스를 구분한다. (4) **Probabilistic Averaging Layer**: Coarse 확률을 가중치로 사용해 여러 Fine Component의 출력을 평균해 최종 예측을 만든다.
계층 구조를 만들기 위한 **카테고리 계층 학습**은 다음과 같다. 전체 학습 데이터를 두 부분으로 나누어, 한 부분은 기본 CNN(빌딩 블록) 학습에 사용하고, 나머지는 검증 셋으로 활용한다. 검증 셋에 대해 기본 CNN을 실행해 혼동 행렬 F를 얻고, 이를 거리 행렬 D=1−F로 변환한다. 스펙트럼 클러스터링을 적용해 D를 K개의 클러스터로 나누어 거친 카테고리를 정의한다. 기본적인 경우는 각 Fine 클래스가 하나의 거친 카테고리에만 속하도록 하는 **Disjoint Coarse Categories**이다. 그러나 Coarse 분류기의 오류가 전체 성능에 크게 영향을 미칠 수 있기에, 저자들은 **Overlapping Coarse Categories**를 도입한다. 각 Fine 클래스 j가 거친 카테고리 k에 오분류될 확률 u_k(j)를 검증 셋에서 추정하고, 임계값 γ에 따라 다중 할당을 허용한다. 이렇게 하면 Coarse 예측이 잘못되더라도 다른 Fine Component가 해당 클래스를 잡아낼 가능성이 높아진다.
학습 과정은 **Component‑wise Pretraining**과 **Global Fine‑tuning** 두 단계로 나뉜다. 먼저 전체 데이터로 기본 CNN을 학습하고, 그 가중치를 Coarse Component와 각 Fine Component에 복사한다. Fine Component는 자신이 담당하는 거친 카테고리의 이미지만을 사용해 독립적으로 사전 학습한다(공통 레이어는 고정). 이후 전체 네트워크를 하나의 손실 함수로 미세조정한다. 손실은 (i) 다중 클래스 로지스틱 손실, (ii) **Coarse Category Consistency Term**(Coarse 예측 평균과 사전 정의된 목표 분포 t_k 사이의 L2 차이)으로 구성된다. λ=20의 정규화 상수를 사용해 두 항목을 균형 있게 학습한다.
실용성을 위해 **Conditional Execution**과 **Layer Parameter Compression**을 적용한다. 테스트 시 Coarse 확률 B_ik가 낮은 Fine Component는 실행을 건너뛰어 연산량을 크게 줄인다. 또한 Fine Component들의 뒤쪽 레이어는 동일한 구조를 공유하므로, SVD 기반 압축이나 가중치 공유 기법을 통해 파라미터 수를 감소시킨다. 이러한 설계 덕분에 파라미터와 메모리 사용량이 K에 대해 선형적으로 증가하더라도 실제 운영 환경에서 감당 가능한 수준으로 유지된다.
실험은 두 데이터셋에서 수행되었다. **CIFAR‑100**에서는 VGG‑16, ResNet‑110, Wide‑ResNet 등 다양한 빌딩 블록을 사용해 HD‑CNN을 구축했으며, 각각 기존 모델 대비 Top‑1 오류를 2.65 %, 3.1 %, 1.1 % 감소시켰다. **ImageNet (1,000 클래스)**에서는 ResNet‑152 기반 HD‑CNN이 기존 ResNet‑152 대비 Top‑1 오류를 1.1 % 낮추었다. 조건부 실행과 압축을 적용했음에도 불구하고 추론 시간은 약 1.5~2배 증가에 그쳤으며, 메모리 사용량도 크게 늘어나지 않았다.
결론적으로, HD‑CNN은 **“거친‑세밀” 두 단계 라우팅**을 통해 어려운 클래스 쌍에 전용 모델을 할당함으로써 정확도를 향상시키고, 공유 레이어와 압축 기법을 통해 실용적인 비용을 유지한다는 점에서 의미가 크다. 향후 연구는 (1) 더 정교한 자동 계층 생성 알고리즘, (2) 동적 라우팅을 통한 실시간 계층 선택, (3) 비전 외 분야(음성, 자연어)로의 확장 등을 제시한다.
**
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기