HD-CNN: Hierarchical Deep Convolutional Neural Network for Large Scale Visual Recognition
In image classification, visual separability between different object categories is highly uneven, and some categories are more difficult to distinguish than others. Such difficult categories demand more dedicated classifiers. However, existing deep …
Authors: Zhicheng Yan, Hao Zhang, Robinson Piramuthu
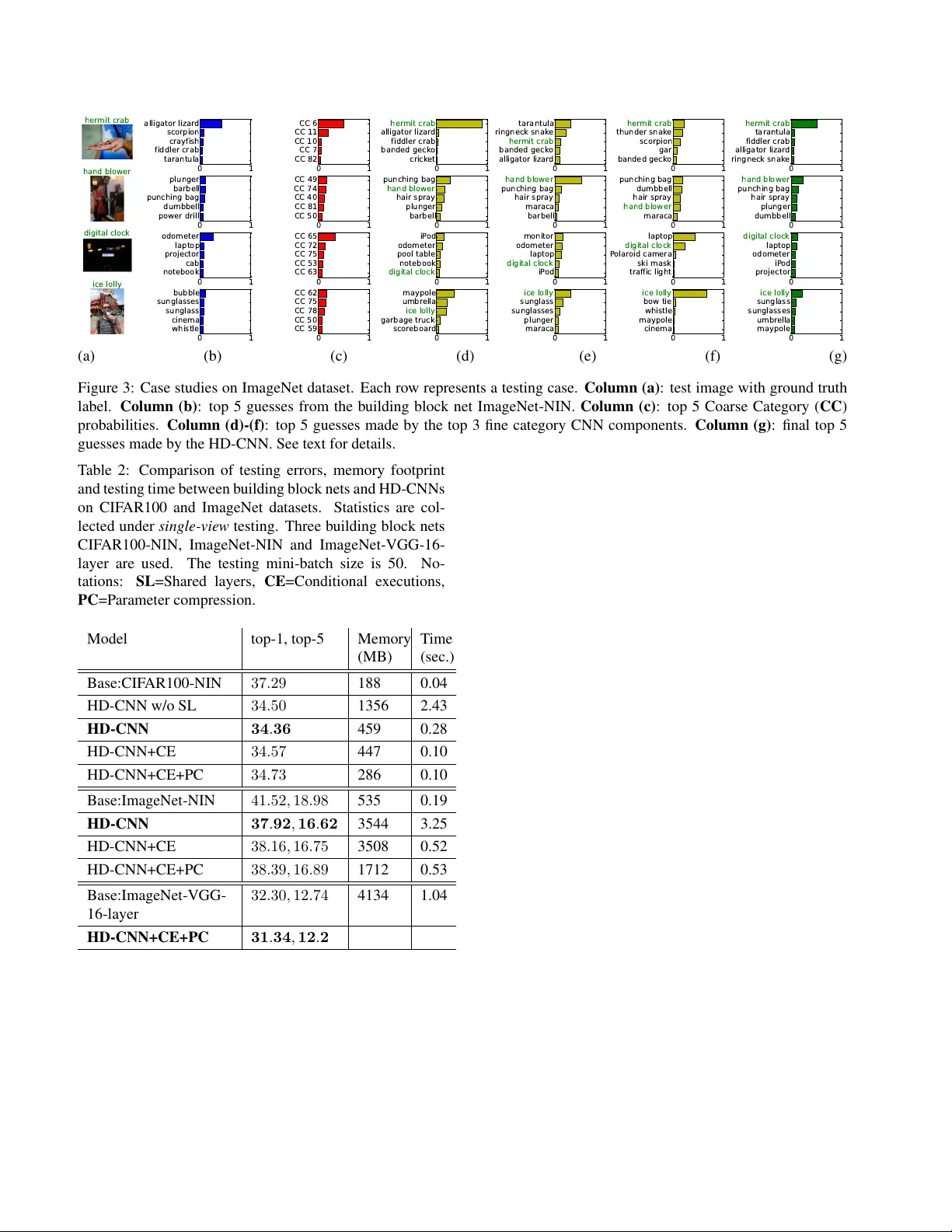
HD-CNN: Hierar chical Deep Con volutional Neural Netw ork f or Large Scale V isual Recognition Zhicheng Y an † , Hao Zhang ‡ , Robinson Piramuthu ∗ , V ignesh Jagadeesh ∗ , Dennis DeCoste ∗ , W ei Di ∗ , Y izhou Y u ? † Uni versity of Illinois at Urbana-Champaign, ‡ Carnegie Mellon Uni versity ∗ eBay Research Lab, ? The Uni versity of Hong K ong Abstract In image classification, visual separability between dif- fer ent object cate gories is highly uneven, and some cate- gories ar e more dif ficult to distinguish than others. Suc h dif- ficult cate gories demand mor e dedicated classifiers. How- ever , e xisting deep convolutional neural networks (CNN) ar e trained as flat N-way classifiers, and few efforts have been made to le vera ge the hierar chical structur e of cate- gories. In this paper , we intr oduce hierar chical deep CNNs (HD-CNNs) by embedding deep CNNs into a category hier- ar chy . An HD-CNN separates easy classes using a coarse cate gory classifier while distinguishing difficult classes us- ing fine category classifiers. During HD-CNN training, component-wise pretr aining is followed by global finetun- ing with a multinomial logistic loss r e gularized by a coarse cate gory consistency term. In addition, conditional execu- tions of fine category classifiers and layer parameter com- pr ession make HD-CNNs scalable for lar ge-scale visual r ecognition. W e achie ve state-of-the-art r esults on both CI- F AR100 and larg e-scale ImageNet 1000-class benchmark datasets. In our experiments, we b uild up thr ee dif fer ent HD-CNNs and the y lower the top-1 err or of the standard CNNs by 2 . 65% , 3 . 1% and 1 . 1% , r espectively . 1. Introduction Deep CNNs are well suited for lar ge-scale learning based visual recognition tasks because of its highly scalable train- ing algorithm, which only needs to cache a small chunk (mini-batch) of the potentially huge volume of training data during sequential scans (epochs). They have achiev ed in- creasingly better performance in recent years. As datasets become bigger and the number of object cat- egories becomes larger , one of the complications that come along is that visual separability between different object cat- egories is highly une ven. Some categories are much harder to distinguish than others. T ake the cate gories in CIF AR100 as an e xample. It is easy to tell an Apple from a Bus , but harder to tell an Apple from an Orange . In fact, both Ap- ples and Oranges belong to the same coarse category fruit and ve getables while Buses belong to another coarse cat- egory vehicles 1 , as defined within CIF AR100. Nonethe- less, most deep CNN models now adays are flat N-way clas- sifiers, which share a set of fully connected layers. This makes us wonder whether such a flat structure is adequate for distinguishing all the difficult categories. A very natu- ral and intuitiv e alternativ e or ganizes classifiers in a hier- archical manner according to the divide-and-conquer strat- egy . Although hierarchical classification has been prov en effecti ve for con ventional linear classifiers [38, 8, 37, 22], few attempts ha ve been made to exploit category hierarchies [3, 29] in deep CNN models. Since deep CNN models are large models themselves, organizing them hierarchically imposes the follo wing chal- lenges. First, instead of a handcrafted category hierarchy , how can we learn such a category hierarchy from the train- ing data itself so that cascaded inferences in a hierarchical classifier will not degrade the ov erall accuracy while ded- icated fine category classifiers exist for hard-to-distinguish categories? Second, a hierarchical CNN classifier consists of multiple CNN models at dif ferent le vels. How can we lev erage the commonalities among these models and effec- tiv ely train them all? Third, it would also be slo wer and more memory-consuming to run a hierarchical CNN clas- sifier on a novel testing image. Ho w can we alleviate such limitations? In this paper , we propose a generic and principled hierar- chical architecture, Hierar chical Deep Con volutional Neu- ral Network (HD-CNN), that decomposes an image classi- fication task into two steps. An HD-CNN first uses a coarse category CNN classifier to separate easy classes from one another . More challenging classes are routed do wnstream to fine category classifiers that focus on confusing classes. W e adopt a module design principle and every HD-CNN is built upon a b uilding block CNN. The b uilding block can be chosen to be any of the currently top ranked single CNNs. Thus HD-CNNs can always benefit from the progress of single CNN design. An HD-CNN follo ws the coarse-to-fine 4321 Root Coarse category 1: {white shark, numbfish , hammerhead, stingray, … } Coarse category 2: {toy terrier, greyhound, whippet, basenji, … } Coarse category K: {mink, cougar, bear, fox squirrel, otter, … } ." ." ." (a) Shared layers Fine component independent layers F 1 ." ." ." Coarse component independent layers B coarse prediction fine prediction 1 final prediction Image low-level features Probabilistic averaging layer Fine component independent layers F K fine prediction K (b) Figure 1: (a) A two-le vel cate gory hierarchy where the classes are taken from ImageNet 1000-class dataset. (b) Hierarchical Deep Con volutional Neural Network (HD-CNN) architecture. classification paradigm and probabilistically integrates pre- dictions from the fine category classifiers. Compared with the building block CNN, the corresponding HD-CNN can achiev e lower error at the cost of a manageable increase in memory footprint and classification time. In summary , this paper has the following contributions. First, we introduce a nov el hierarchical architecture, called HD-CNN, for image classification. Second, we develop a scheme for learning the two-lev el organization of coarse and fine categories, and demonstrate v arious components of an HD-CNN can be independently pretrained. The com- plete HD-CNN is further fine-tuned using a multinomial logistic loss regularized by a coarse category consistency term. Third, we make the HD-CNN scalable by compress- ing the layer parameters and conditionally e xecuting the fine category classifiers. W e have performed e valuations on the medium-scale CIF AR100 dataset and the lar ge-scale ImageNet 1000-class dataset, and our method has achie ved state-of-the-art performance on both of them. 2. Related W ork Our work is inspired by progresses in CNN design and efforts on integrating a category hierarchy with linear clas- sifiers. The main novelty of our method is a ne w scalable HD-CNN architecture that integrates a category hierarchy with deep CNNs. 2.1. Con volutional Neural Networks CNN-based models hold state-of-the-art performance in various computer vision tasks, including image classifca- tion [18], object detection [10, 13], and image parsing [7]. Recently , there has been considerable interest in enhanc- ing CNN components, including pooling layers [36], acti- vation units [11, 28], and nonlinear layers [21]. These en- hancements either improve CNN training [36], or expand the network learning capacity . This work boosts CNN per- formance from an orthogonal angle and does not redesign a specific part within any existing CNN model. Instead, we design a no vel generic hierarchical architecture that uses an existing CNN model as a building block. W e embed multi- ple building blocks into a lar ger hierarchical deep CNN. 2.2. Category Hierarch y for V isual Recognition In visual recognition, there is a vast literature exploiting category hierarchical structures [32]. For classification with a lar ge number of classes using linear classifiers, a common strategy is to build a hierarch y or taxonomy of classifiers so that the number of classifiers ev aluated giv en a testing im- age scales sub-linearly in the number of classes [2, 9]. The hierarchy can be either predefined[23, 33, 16] or learnt by top-down and bottom-up approaches [25, 12, 24, 20, 1, 6, 27]. In [5], the predefined category hierarchy of ImageNet dataset is utilized to achie ve the trade-of fs between classifi- cation accuracy and specificity . In [22], a hierarchical label tree is constructed to probabilistically combine predictions from leaf nodes. Such hierarchical classifier achiev es sig- nificant speedup at the cost of certain accuracy loss. One of the earliest attempts to introduce a category hi- erarchy in CNN-based methods is reported in [29] but their main goal is transferring knowledge between classes to im- prov e the results for classes with insuf ficient training e x- amples. In [3], various label relations are encoded in a hi- erarchy . Improved accuracy is achiev ed only when a sub- set of training images are relabeled with internal nodes in the hierarchical class tree. They are not able to improve the accuracy in the original setting where all training im- ages are labeled with leaf nodes. In [34], a hierarchy of CNNs is introduced b ut they experimented with only two coarse cate gories mainly due to scalability constraints. HD- CNN e xploits the cate gory hierarchy in a nov el way that we embed deep CNNs into the hierarchy in a scalable manner and achiev es superior classification results over the standard CNN. 3. Overview of HD-CNN 3.1. Notations The following notations are used belo w . A dataset con- sists of images { x i , y i } i . x i and y i denote the image data and label, respectiv ely . There are C fine categories of im- ages in the dataset { S f j } C j =1 . W e will learn a category hier- archy with K coarse categories { S c k } K k =1 . 4322 3.2. HD-CNN Architectur e HD-CNN is designed to mimic the structure of category hierarchy where fine categories are divided into coarse cat- egories as in Fig 1(a). It performs end-to-end classification as illustrated in Fig 1(b). It mainly comprises four parts, namely shared layers, a single coarse category component B , multiple fine category components { F k } K k =1 and a sin- gle probabilistic av eraging layer . On the left side of Fig 1 (b) are the shared layers. They receiv e raw image pixel as input and extract lo w-level features. The configuration of shared layers are set to be the same as the preceding layers in the building block net. On the top of Fig 1(b) are independent layers of coarse category component B which reuses the configuration of rear layers from the building block CNN and produces a fine prediction { B f ij } C j =1 for an image x i . T o produce a predic- tion { B ik } K k =1 ov er coarse categories, we append a fine-to- coarse aggregation layer which aggregates fine predictions into coarse ones when a mapping from fine categories to coarse ones P : [1 , C ] 7→ [1 , K ] is gi ven. The coarse cat- egory probabilities serve two purposes. First, they are used as weights for combining the predictions made by fine cat- egory components. Second, when thresholded, they enable conditional executions of fine category components whose corresponding coarse probabilities are sufficiently lar ge. In the bottom-right of Fig 1 (b) are independent layers of a set of fine category classifiers { F k } K k =1 , each of which makes fine category predictions. As each fine component only excels in classifying a small set of cate gories, the y pro- duce a fine prediction over a partial set of categories. The probabilities of other fine categories absent in the partial set are implicitly set to zero. The layer configurations are mostly copied from the building block CNN except that in the final classification layer the number of filters is set to be the size of partial set instead of the full categories. Both coarse category component and fine category com- ponents share common layers. The reason is three-fold. First, it is shown in [35] that preceding layers in deep networks response to class-agnostic low-le vel features such as corners and edges, while rear layers extract more class- specific features such as dog face and bird’ s legs. Since low-le vel features are useful for both coarse and fine classi- fication tasks, we allo w the preceding layers to be shared by both coarse and fine components. Second, it reduces both the total floating point operations and the memory footprint of network execution. Both are of practical significance to deploy HD-CNN in real applications. Last but not the least, it can decrease the number of HD-CNN parameters which is critical to the success of HD-CNN training. On the right side of Fig 1 (b) is the probabilistic av erag- ing layer which recei ves fine cate gory predictions as well as coarse category prediction and produces a weighted av erage as the final prediction. p ( x i ) = P K k =1 B ik p k ( x i ) P K k =1 B ik (1) where B ik is the probability of coarse cate gory k for the image x i predicted by the coarse cate gory component B . p k ( x i ) is the fine category prediction made by the fine cat- egory component F k . W e stress that both coarse and fine category components reuse the layer configurations from the building block CNN. This flexible modular design allo ws us to choose the best module CNN as the building block, depending on the task at hand. 4. Learning a Category Hierar chy Our goal of b uilding a category hierarchy is grouping confusing fine categories into the same coarse category for which a dedicated fine category classifier will be trained. W e employ a top-down approach to learn the hierarchy from the training data. W e randomly sample a held-out set of images with bal- anced class distribution from the training set. The rest of the training set is used to train a building block net. W e obtain a confusion matrix F by ev aluating the net on the held-out set. A distance matrix D is deriv ed as D = 1 − F and its diagonal entries are set to be zero. D is further trans- formed by D = 0 . 5 ∗ ( D + D T ) to be symmetric. The en- try D ij measures ho w easy it is to discriminate categories i and j . Spectral clustering is performed on D to cluster fine categories into K coarse cate gories. The result is a two- lev el category hierarchy representing a many-to-one map- ping P d : [1 , C ] 7→ [1 , K ] from fine to coarse categories. Here, the coarse categories are disjoint. Overlapping Coarse Categories With disjoint coarse cat- egories, the o verall classification depends heavily on the coarse category classifier . If an image is routed to an in- correct fine category classifier , then the mistake can not be corrected as the probability of ground truth label is implic- itly set to zero there. Removing the separability constraint between coarse categories can make the HD-CNN less de- pendent on the coarse category classifier . Therefore, we add more fine cate gories to the coarse cat- egories. For a certain fine classifier F k , we prefer to add those fine categories { j } that are likely to be misclassfied into the coarse category k . Therefore, we estimate the like- lihood u k ( j ) that an image in fine category j is misclassified into a coarse category k on the held-out set. u k ( j ) = 1 S f j X i ∈ S f j B d ik (2) B d ik is the coarse category probability which is obtained by aggregating fine category probabilities { B f ij } j according to 4323 the mapping P d : B d ik = P j | P d ( j )= k B f ij . W e threshold the likelihood u k ( j ) using a parametric variable u t = ( γ K ) − 1 and add to the partial set S c k all fine categories { j } such that u k ( j ) ≥ u t . Note that each branching component gives a full set prediction when u t = 0 and a disjoint set prediction when u t = 1 . 0 . W ith overlapping coarse categories, the cat- egory hierarchy mapping P d is extended to be a many-to- many mapping P o and the coarse category predictions are updated accordingly B o ik = P j | k ∈ P o ( j ) B ij . Note the sum of { B o ik } K k =1 exceeds 1 and hence we perform L 1 normal- ization. The use of overlapping coarse categories was also shown to be useful for hierarchical linear classifiers [24]. 5. HD-CNN T raining As we embed fine category components into HD-CNN, the number of parameters in rear layers gro ws linearly in the number of coarse categories. Given the same amount of training data, this increases the training complexity and the risk of over -fitting. On the other hand, the training im- ages within the stochastic gradient descent mini-batch are probabilistically routed to different fine category compo- nents. It requires larger mini-batch to ensure parameter gra- dients in the fine category components are estimated by a sufficiently large number of training samples. Large train- ing mini-batch both increases the training memory footprint and slo ws do wn the training process. Therefore, we decom- pose the HD-CNN training into multiple steps instead of training the complete HD-CNN from scratch as outlined in Algorithm 1. 5.1. Pretraining HD-CNN W e sequentially pretrain the coarse category component and fine category components. 5.1.1 Initializing the Coarse Category Component W e first pretrain a building block CNN F p using the training set. As both the preceding and rear layers in coarse cate gory component resemble the layers in the building block CNN, we copy the weights of F p into coarse category component for initialization purpose. 5.1.2 Pretraining the Rear Layers of Fine Category Components Fine category components { F k } k can be independently pretrained in parallel. Each F k should specialize in classi- fying fine categories within the coarse category S c k . There- fore, the pretraining of each F k only uses images { x i | i ∈ S c k } from the coarse category S c k . The shared preceding lay- ers are already initialized and kept fixed in this stage. For Algorithm 1 HD-CNN training algorithm 1: procedur e H D - C N N T R A I N I N G 2: Step 1: Pretrain HD-CNN 3: Step 1.1: Initialize coarse category component 4: Step 1.2: Pretrain fine category components 5: Step 2: Fine-tune the complete HD-CNN each F k , we initialize all the rear layers e xcept the last con- volutional layer by copying the learned parameters from the pretrained model F p . 5.2. Fine-tuning HD-CNN After both coarse category component and fine category components are properly pretrained, we fine-tune the com- plete HD-CNN. Once the category hierarchy as well as the associated mapping P o is learnt, each fine category compo- nent focuses on classifying a fix ed subset of fine categories. During fine-tuning, the semantics of coarse categories pre- dicted by the coarse category component should be kept consistent with those associated with fine category compo- nents. Thus we add a coarse cate gory consistency term to regularize the con ventional multinomial logistic loss. Coarse category consistency The learnt fine-to-coarse cat- egory mapping P : [1 , C ] 7→ [1 , K ] provides a way to spec- ify the target coarse category distribution { t k } . Specifically , t k is set to be the fraction of all the training images within the coarse category S c k under the assumption the distribution ov er coarse categories across the training dataset is close to that within a training mini-batch. t k = P j | k ∈ P ( j ) | S j | P K k 0 =1 P j | k 0 ∈ P ( j ) | S j | ∀ k ∈ [1 , K ] (3) The final loss function we use for fine-tuning the HD- CNN is shown belo w . E = − 1 n n X i =1 log ( p y i ) + λ 2 K X k =1 ( t k − 1 n n X i =1 B ik ) 2 (4) where n is the size of training mini-batch. λ is a re gulariza- tion constant and is set to λ = 20 . 6. HD-CNN T esting As we add fine category components into the HD-CNN, the number of parameters, memory footprint and execution time in rear layers, all scale linearly in the number of coarse categories. T o ensure HD-CNN is scalable for large-scale visual recognition, we de velop conditional execution and layer parameter compression techniques. Conditional Execution . At test time, for a giv en image, it is not necessary to e valuate all fine cate gory classifiers as most of them ha ve insignificant weights B ik as in Eqn 1. 4324 Their contrib utions to the final prediction are negligible. Conditional executions of the top weighted fine components can accelerate the HD-CNN classification. Therefore, we threshold B ik using a parametric variable B t = ( β K ) − 1 and reset B ik to zero when B ik < B t . Those fine category classifiers with B ik = 0 are not ev aluated. Parameter Compression . In HD-CNN, the number of pa- rameters in rear layers of fine category classifiers grows lin- early in the number of coarse categories. Thus we compress the layer parameters at test time to reduce memory foot- print. Specifically , we choose the Product Quantization ap- proach [14] to compress the parameter matrix W ∈ R m × n by first partitioning it horizontally into se gments of width s . W = [ W 1 , ..., W ( n/s ) ] . Then k -means clustering is used to cluster the ro ws in W i , ∀ i ∈ [1 , ( n/s )] . By only storing the nearest cluster indices in a 8-bit inte ger ma- trix I ∈ R m × ( n/s ) and cluster centers in a single-precision floating number matrix C ∈ R k × n , we can achiev e a com- pression factor (32 mn ) / (32 kn + 8 mn/s ) . The hyperpa- rameters for parameter compression are ( s, k ) . 7. Experiments 7.1. Overview W e ev aluate HD-CNN on the benchmark datasets CI- F AR100 [17] and ImageNet [4]. HD-CNN is implemented on the widely deployed Caffe [15] software. The network is trained by back propagation [18]. W e run all the testing experiments on a single NVIDIA T esla K40c card. 7.2. CIF AR100 Dataset The CIF AR100 dataset consists of 100 classes of natu- ral images. There are 50K training images and 10K testing images. W e follow [11] to preprocess the datasets (e.g. global contrast normalization and ZCA whitening). Ran- domly cropped and flipped image patches of size 26 × 26 are used for training. W e adopt a NIN network 1 with three stacked layers [21]. W e denote it as CIF AR100-NIN which will be the HD-CNN building block. Fine category com- ponents share preceding layers from con v1 to pool1 which accounts for 6% of the total parameters and 29% of the total floating point operations. The remaining layers are used as independent layers. For building the category hierarchy , we randomly choose 10K images from the training set as held-out set. Fine cat- egories within the same coarse categories are visually more similar . W e pretrain the rear layers of fine category compo- nents. The initial learning rate is 0 . 01 and it is decreased by a factor of 10 e very 6K iterations. Fine-tuning is performed for 20K iterations with large mini-batches of size 256. The 1 https://github.com/mavenlin/cuda- convnet/blob/ master/NIN/cifar- 100_def T able 1: 10-view testing errors on CIF AR100 dataset. No- tation CCC =coarse category consistenc y . Method Error Model av eraging ( 2 CIF AR100-NIN nets) 35 . 13 DSN [19] 34 . 68 CIF AR100-NIN-double 34 . 26 dasNet [30] 33 . 78 Base: CIF AR100-NIN 35 . 27 HD-CNN, no finetuning 33 . 33 HD-CNN, finetuning w/o CCC 33 . 21 HD-CNN, finetuning w/ CCC 32 . 62 initial learning rate is 0 . 001 and is reduced by a f actor of 10 once after 10K iterations. For ev aluation, we use 10-vie w testing [18]. W e ex- tract five 26 × 26 patches (the 4 corner patches and the center patch) as well as their horizontal reflections and av- erage their predictions. The CIF AR100-NIN net obtains 35 . 27% testing error . Our HD-CNN achie ves testing error of 32 . 62% which improves the building block net by 2 . 65% . Category hierarch y . During the construction of the cate- gory hierarchy , the number of coarse categories can be ad- justed by the clustering algorithm. W e can also make the coarse categories either disjoint or o verlapping by varying the hyperparameter γ . Thus we in vestigate their impacts on the classification error . W e experiment with 5, 9, 14 and 19 coarse categories and v ary the value of γ . The best results are obtained with 9 overlapping coarse categories and γ = 5 as shown in Fig 2 left. A histogram of fine category occur- rences in 9 o verlapping coarse categories is sho wn in Fig 2 right. The optimal v alue of coarse category number and hyperparameter γ are dataset dependent, mainly af fected by the inherent hierarchy within the categories. number of coarse categories 5 1 01 52 0 33 33.5 34 34.5 35 35.5 Disjoint coarse categories Overlapping coarse categories, γ = 5 Overlapping coarse categories, γ = 10 0 1 2 3 4 5 6 7 8 fine category occur r e nces 0 5 10 15 20 25 Figure 2: Left : HD-CNN 10-view testing error against the number of coarse categories on CIF AR100 dataset. Right : Histogram of fine category occurrences in 9 ov erlapping coarse categories. Shared layers . The use of shared layers makes both com- 4325 putational complexity and memory footprint of HD-CNN sublinear in the number of fine category classifiers when compared to the building block net. Our HD-CNN with 9 fine category classifiers based on CIF AR100-NIN con- sumes less than three times as much memory as the build- ing block net without parameter compression. W e also want to inv estigate the impact of the use of shared layers on the classification error , memory footprint and the net ex ecution time (T able 2). W e b uild another HD-CNN where coarse category component and all fine category components use independent preceding layers initialized from a pretrained building block net. Under the single-view testing where only a central cropping is used, we observe a minor error increase from 34 . 36% to 34 . 50% . But using shared layers dramatically reduces the memory footprint from 1356 MB to 459 MB and testing time from 2 . 43 seconds to 0 . 28 sec- onds. Conditional executions . By v arying the hyperparameter β , we can effecti vely affect the number of fine category com- ponents that will be ex ecuted. There is a trade-of f between ex ecution time and classification error . A larger value of β leads to higher accurac y at the cost of e xecuting more com- ponents for fine cate gorization. By enabling conditional ex- ecutions with hyperparameter β = 6 , we obtain a substan- tial 2 . 8 X speed up with merely a minor increase in error from 34 . 36% to 34 . 57% (T able 2). The testing time of HD-CNN is about 2 . 5 times as much as that of the building block net. Parameter compression . As fine category CNNs hav e in- dependent layers from con v2 to cccp6 , we compress them and reduce the memory footprint from 447 MB to 286 MB with a minor increase in error from 34 . 57% to 34 . 73% . Comparison with a strong baseline. As our HD-CNN memory footprint is about two times as much as the building block model (T able 2), it is necessary to compare a stronger baseline of similar comple xity with HD-CNN. W e adapt CIF AR100-NIN and double the number of filters in all con- volutional layers which accordingly increases the memory footprint by three times. W e denote it as CIF AR100-NIN- double and obtain error 34 . 26% which is 1 . 01% lower than that of the b uilding block net but is 1 . 64% higher than that of HD-CNN. Comparison with model averaging . HD-CNN is funda- mentally different from model av eraging [18]. In model av eraging, all models are capable of classifying the full set of the categories and each one is trained independently . The main sources of their prediction differences are differ - ent initializations. In HD-CNN, each fine category clas- sifier only excels at classifying a partial set of categories. T o compare HD-CNN with model averaging, we indepen- dently train two CIF AR100-NIN networks and take their av- eraged prediction as the final prediction. W e obtain an error of 35 . 13% , which is about 2 . 51% higher than that of HD- CNN (T able 1). Note that HD-CNN is orthogonal to the model av eraging and an ensemble of HD-CNN networks can further improv e the performance. Coarse category consistency . T o verify the effecti veness of coarse category consistenc y term in our loss function (4), we fine-tune a HD-CNN using the traditional multinomial logistic loss function. The testing error is 33 . 21% , which is 0 . 59% higher than that of a HD-CNN fine-tuned with coarse category consistenc y (T able 1). Comparison with state-of-the-art. Our HD-CNN im- prov es on the current two best methods [19] and [30] by 2 . 06% and 1 . 16% respectively and sets ne w state-of-the-art results on CIF AR100 (T able 1). 7.3. ImageNet 1000-class Dataset The ILSVRC-2012 ImageNet dataset consists of about 1 . 2 million training images, 50 , 000 validation images. T o demonstrate the generality of HD-CNN, we experiment with two dif ferent building block nets. In both cases, HD- CNNs achie ve significantly lower testing errors than the building block nets. 7.3.1 Network-In-Network Building Block Net W e choose a public 4-layer NIN net 2 as our first b uild- ing block as it has greatly reduced number of parameters compared to AlexNet [18] but similar error rates. It is de- noted as ImageNet-NIN. In HD-CNN, various components share preceding layers from conv1 to pool3 which account for 26% of the total parameters and 82% of the total floating point operations. W e follow the training and testing protocols as in [18]. Original images are resized to 256 × 256 . Randomly cropped and horizontally reflected 224 × 224 patches are used for training. At test time, the net makes a 10-view av- eraged prediction. W e train ImageNet-NIN for 45 epochs. The top-1 and top-5 errors are 39 . 76% and 17 . 71% . T o b uild the category hierarchy , we take 100K training images as the held-out set and find 89 overlapping coarse categories. Each fine category CNN is fine-tuned for 40K iterations while the initial learning rate 0 . 01 is decreased by a factor of 10 ev ery 15K iterations. Fine-tuning the complete HD-CNN is not performed as the required mini- batch size is significantly higher than that for the building block net. Nev ertheless, we still achie ve top-1 and top-5 er- rors of 36 . 66% and 15 . 80% and improv e the building block net by 3 . 1% and 1 . 91% , respectively (T able 3). The class- wise top-5 error impro vement over the building block net is shown in Fig 4 left. Case studies W e want to in vestigate how HD-CNN corrects the mistakes made by the building block net. In Fig 3, we 2 https://gist.github.com/mavenlin/ d802a5849de39225bcc6 4326 her m it crab 0 1 tarantula fiddler c rab crayfish scorpion alligator lizar d 0 1 CC 82 CC 7 CC 10 CC 11 CC 6 0 1 crick et banded g eck o fiddler c rab alligator lizar d her m it crab 0 1 alligator lizar d banded g eck o her m it crab ringneck snak e tarantula 0 1 banded g eck o gar scorpion thunder s nak e her m it crab 0 1 ringneck snak e alligator lizar d fiddler c rab tarantula her m it crab hand blower 0 1 power drill dumbbell punching bag barbell plunger 0 1 CC 50 CC 81 CC 40 CC 74 CC 49 0 1 barbell plunger hair spray hand blower punching bag 0 1 barbell maraca hair spray punching bag hand blower 0 1 maraca hand blower hair spray dumbbell punching bag 0 1 dumbbell plunger hair spray punching bag hand blower digital clock 0 1 notebook cab pr ojector laptop odometer 0 1 CC 63 CC 53 CC 75 CC 72 CC 65 0 1 digital clock notebook pool table odometer iP od 0 1 iP od digital clock laptop odometer monitor 0 1 traffic light ski m ask P olar oid camera digital clock laptop 0 1 pr ojector iP od odometer laptop digital clock ice lolly 0 1 whistle cinema sunglass sunglasses bubble 0 1 CC 59 CC 50 CC 78 CC 75 CC 62 0 1 scor eboar d garbage truck ice lolly umbr ella maypole 0 1 maraca plunger sunglasses sunglass ice lolly 0 1 cinema maypole whistle bow tie ice lolly 0 1 maypole umbr ella sunglasses sunglass ice lolly (a) (b) (c) (d) (e) (f) (g) Figure 3: Case studies on ImageNet dataset. Each row represents a testing case. Column (a) : test image with ground truth label. Column (b) : top 5 guesses from the building block net ImageNet-NIN. Column (c) : top 5 Coarse Category ( CC ) probabilities. Column (d)-(f) : top 5 guesses made by the top 3 fine category CNN components. Column (g) : final top 5 guesses made by the HD-CNN. See text for details. T able 2: Comparison of testing errors, memory footprint and testing time between building block nets and HD-CNNs on CIF AR100 and ImageNet datasets. Statistics are col- lected under single-view testing. Three building block nets CIF AR100-NIN, ImageNet-NIN and ImageNet-VGG-16- layer are used. The testing mini-batch size is 50. No- tations: SL =Shared layers, CE =Conditional executions, PC =Parameter compression. Model top-1, top-5 Memory (MB) T ime (sec.) Base:CIF AR100-NIN 37 . 29 188 0.04 HD-CNN w/o SL 34 . 50 1356 2.43 HD-CNN 34 . 36 459 0.28 HD-CNN+CE 34 . 57 447 0.10 HD-CNN+CE+PC 34 . 73 286 0.10 Base:ImageNet-NIN 41 . 52 , 18 . 98 535 0.19 HD-CNN 37 . 92 , 16 . 62 3544 3.25 HD-CNN+CE 38 . 16 , 16 . 75 3508 0.52 HD-CNN+CE+PC 38 . 39 , 16 . 89 1712 0.53 Base:ImageNet-VGG- 16-layer 32 . 30 , 12 . 74 4134 1.04 HD-CNN+CE+PC 31 . 34 , 12 . 26 6863 5.28 collect four testing cases. In the first case, the building block net fails to predict the label of the tin y hermit crab in the top 5 guesses. In HD-CNN, two coarse cate gories #6 and #11 receiv e most of the coarse probability mass. The fine cat- egory component #6 specializes in classifying crab breeds and strongly suggests the ground truth label. By combin- ing the predictions from the top fine category classifiers, the HD-CNN predicts hermit crab as the most probable label. In the second case, the ImageNet-NIN confuses the ground truth hand blower with other objects of close shapes and appearances, such as plunger and barbell . For HD-CNN, the coarse category component is also not confident about which coarse category the object belongs to and thus as- signs ev en probability mass to the top coarse categories. For the top 3 fine category classifiers, #74 strongly predicts ground truth label while the other two #49 and #40 rank the ground truth label at the 2nd and 4th place respectiv ely . Overall, the HD-CNN ranks the ground truth label at the 1st place. This demonstrates HD-CNN needs to rely on multi- ple fine category classifiers to make correct predictions for difficult cases. Overlapping coarse categories .T o in vestigate the impact of overlapping coarse categories on the classification, we train another HD-CNN with 89 fine category classifiers us- ing disjoint coarse categories. It achie ves top-1 and top-5 errors of 38 . 44% and 17 . 03% respectiv ely , which is higher than those of the HD-CNN using ov erlapping coarse cate- gory hierarchy by 1 . 78% and 1 . 23% (T able 3). Conditional executions . By v arying the hyperparameter β , we can control the number of fine category components that will be executed. There is a trade-off between ex ecu- tion time and classification error as sho wn in Fig 4 right. A larger v alue of β leads to lower error at the cost of more ex ecuted fine category components. By enabling condi- tional executions with hyperparameter β = 8 , we obtain a substantial 6 . 3 X speed up with merely a minor increase of single-view testing top-5 error from 16 . 62% to 16 . 75% (T able 2). With such speedup, the HD-CNN testing time is less than 3 times as much as that of the building block net. Parameter compr ession . W e compress independent layers con v4 and cccp7 as they account for 60% of the parame- 4327 T able 3: Comparisons of 10-view testing errors between ImageNet-NIN and HD-CNN. Notation CC =Coarse cate- gory . Method top-1, top-5 Base:ImageNet-NIN 39 . 76 , 17 . 71 Model av eraging ( 3 base nets) 38 . 54 , 17 . 11 HD-CNN, disjoint CC 38 . 44 , 17 . 03 HD-CNN 36 . 66 , 15 . 80 ters in ImageNet-NIN. Their parameter matrices are of size 1024 × 3456 and 1024 × 1024 and we use compression hyperparameters ( s, k ) = (3 , 128) and ( s, k ) = (2 , 256) . The compression factors are 4 . 8 and 2 . 7 . The compres- sion decreases the memory footprint from 3508 MB to 1712 MB and merely increases the top-5 error from 16 . 75% to 16 . 89% under single-view testing (T able 2). 0 200 400 600 800 1000 class −0.3 −0.2 −0.1 0.0 0.1 0.2 er r o r i mpr ovement log 2 β - 5 - 4 - 3 - 2 - 1 01234 Mean # of executed components 0 2 4 6 8 10 12 Top 5 error 0.15 0.155 0.16 0.165 0.17 0.175 0.18 Figure 4: Left : Class-wise HD-CNN top-5 error improve- ment over the building block net. Right : Mean number of ex ecuted fine category classifiers and top-5 error against hy- perparameter β on the ImageNet validation dataset. Comparison with model averaging . As the HD-CNN memory footprint is about three times as much as the build- ing block net, we independently train three ImageNet-NIN nets and average their predictions. W e obtain top-5 error 17 . 11% which is 0 . 6% lower than the building block but is 1 . 31% higher than that of HD-CNN (T able 3). 7.3.2 V GG-16-layer Building Block Net The second building block net we use is a 16-layer CNN from [26]. W e denote it as ImageNet-VGG-16-layer 3 . The layers from con v1 1 to pool4 are shared and they account for 5 . 6% of the total parameters and 90% of the total float- ing number operations. The remaining layers are used as independent layers in coarse and fine category classifiers. W e follo w the training and testing protocols as in [26]. F or training, we first sample a size S from the range [256 , 512] and resize the image so that the length of short edge is S . Then a randomly cropped and flipped patch of size 224 × 224 is used for training. For testing, dense e valuation is performed on three scales { 256 , 384 , 512 } and the aver - 3 https://github.com/BVLC/caffe/wiki/Model- Zoo aged prediction is used as the final prediction. Please refer to [26] for more training and testing details. On ImageNet validation set, ImageNet-VGG-16-layer achiev es top-1 and top-5 errors 24 . 79% and 7 . 50% respectiv ely . W e build a category hierarchy with 84 overlapping coarse categories. W e implement multi-GPU training on Caffe by exploiting data parallelism [26] and train the fine category classifiers on two NVIDIA T esla K40c cards. The initial learning rate is 0 . 001 and it is decreased by a fac- tor of 10 e very 4K iterations. HD-CNN fine-tuning is not performed. Due to large memory footprint of the building block net (T able 2), the HD-CNN with 84 fine category clas- sifiers cannot fit into the memory directly . Therefore, we compress the parameters in layers fc6 and fc7 as they ac- count for over 85% of the parameters. Parameter matrices in fc6 and fc7 are of size 4096 × 25088 and 4096 × 4096 . Their compression hyperparameters are ( s, k ) = (14 , 64) and ( s, k ) = (4 , 256) . The compression factors are 29 . 9 and 8 respectiv ely . The HD-CNN obtains top-1 and top-5 er - rors 23 . 69% and 6 . 76% on ImageNet v alidation set and im- prov es over ImageNet-VGG-16-layer by 1 . 1% and 0 . 74% respectiv ely . T able 4: Errors on ImageNet validation set. Method top-1, top-5 GoogLeNet,multi-crop [31] N/A, 7 . 9 VGG-19-layer , dense [26] 24 . 8 , 7 . 5 VGG-16-layer+V GG-19-layer ,dense 24 . 0 , 7 . 1 Base:ImageNet-VGG-16-layer ,dense 24 . 79 , 7 . 50 HD-CNN,dense 23 . 69 , 6 . 76 Comparison with state-of-the-art . Currently , the tw o best nets on ImageNet dataset are GoogLeNet [31] (T able 4) and VGG 19-layer network [26]. Using multi-scale multi- crop testing, a single GoogLeNet net achie ves top-5 error 7 . 9% . With multi-scale dense e valuation, a single VGG 19- layer net obtains top-1 and top-5 errors 24 . 8% and 7 . 5% and improv es top-5 error of GoogLeNet by 0 . 4% . Our HD- CNN decreases top-1 and top-5 errors of V GG 19-layer net by 1 . 11% and 0 . 74% respectively . Furthermore, HD-CNN slightly outperforms the results of a veraging the predictions from VGG-16-layer and V GG-19-layer nets. 8. Conclusions and Future W ork W e demonstrated that HD-CNN is a flexible deep CNN architecture to improve over e xisting deep CNN models. W e showed this empirically on both CIF AR-100 and Image- Net datasets using three dif ferent b uilding block nets. As part of future work, we plan to e xtend HD-CNN architec- tures to those with more than 2 hierarchical lev els and also verify our empirical results in a theoretical frame work. 4328 References [1] H. Bannour and C. Hudelot. Hierarchical image annota- tion using semantic hierarchies. In Pr oceedings of the 21st A CM International Conference on Information and Knowl- edge Manag ement , 2012. [2] S. Bengio, J. W eston, and D. Grangier . Label embedding trees for large multi-class tasks. In NIPS , 2010. [3] J. Deng, N. Ding, Y . Jia, A. Frome, K. Murphy , S. Bengio, Y . Li, H. Ne ven, and H. Adam. Large-scale object classifica- tion using label relation graphs. In ECCV . 2014. [4] J. Deng, W . Dong, R. Socher , L. Li, K. Li, and F . Li. Ima- genet: A large-scale hierarchical image database. In CVPR , 2009. [5] J. Deng, J. Krause, A. C. Berg, and L. Fei-Fei. Hedging your bets: Optimizing accuracy-specificity trade-offs in large scale visual recognition. In CVPR , 2012. [6] J. Deng, S. Satheesh, A. C. Berg, and F . Li. Fast and bal- anced: Efficient label tree learning for large scale object recognition. In Advances in Neural Information Pr ocessing Systems , 2011. [7] C. Farabet, C. Couprie, L. Najman, and Y . LeCun. Learning hierarchical features for scene labeling. IEEE T ransactions on P attern Analysis and Machine Intelligence , 2013. [8] R. Fergus, H. Bernal, Y . W eiss, and A. T orralba. Semantic label sharing for learning with many categories. In ECCV . 2010. [9] T . Gao and D. K oller . Discriminati ve learning of relax ed hierarchy for large-scale visual recognition. In ICCV , 2011. [10] R. Girshick, J. Donahue, T . Darrell, and J. Malik. Rich fea- ture hierarchies for accurate object detection and semantic segmentation. In CVPR , 2014. [11] I. Goodfello w , D. W arde-Farley , M. Mirza, A. Courville, and Y . Bengio. Maxout networks. In ICML , 2013. [12] G. Griffin and P . Perona. Learning and using taxonomies for fast visual categorization. In CVPR , 2008. [13] K. He, X. Zhang, S. Ren, and J. Sun. Spatial pyramid pooling in deep con volutional networks for visual recognition. In ECCV . 2014. [14] H. Jegou, M. Douze, and C. Schmid. Product quantization for nearest neighbor search. IEEE T ransactions on P attern Analysis and Machine Intelligence , 2011. [15] Y . Jia. Caf fe: An open source conv olutional architecture for fast feature embedding, 2013. [16] Y . Jia, J. T . Abbott, J. Austerweil, T . Griffiths, and T . Dar- rell. V isual concept learning: Combining machine vision and bayesian generalization on concept hierarchies. In NIPS , 2013. [17] A. Krizhevsky and G. Hinton. Learning multiple layers of features from tiny images. Computer Science Department, University of T or onto, T ech. Rep , 2009. [18] A. Krizhe vsky , I. Sutske ver , and G. Hinton. Imagenet clas- sification with deep conv olutional neural networks. In NIPS , 2012. [19] C.-Y . Lee, S. Xie, P . Gallagher , Z. Zhang, and Z. T u. Deeply- supervised nets. arXiv pr eprint arXiv:1409.5185 , 2014. [20] L.-J. Li, C. W ang, Y . Lim, D. M. Blei, and L. Fei-Fei. Build- ing and using a semanti visual image hierarchy . In CVPR , 2010. [21] M. Lin, Q. Chen, and S. Y an. Network in network. CoRR , 2013. [22] B. Liu, F . Sadeghi, M. T appen, O. Shamir , and C. Liu. Prob- abilistic label trees for ef ficient large scale image classifica- tion. In CVPR , 2013. [23] M. Marszalek and C. Schmid. Semantic hierarchies for vi- sual object recognition. In CVPR , 2007. [24] M. Marszałek and C. Schmid. Constructing category hierar - chies for visual recognition. In ECCV . 2008. [25] R. Salakhutdinov , A. T orralba, and J. T enenbaum. Learning to share visual appearance for multiclass object detection. In CVPR , 2011. [26] K. Simonyan and A. Zisserman. V ery deep conv olu- tional networks for large-scale image recognition. CoRR , abs/1409.1556, 2014. [27] J. Sivic, B. C. Russell, A. Zisserman, W . T . Freeman, and A. A. Efros. Unsupervised discovery of visual object class hierarchies. In CVPR , 2008. [28] J. T . Springenberg and M. Riedmiller . Improving deep neu- ral networks with probabilistic maxout units. arXiv pr eprint arXiv:1312.6116 , 2013. [29] N. Sriv astav a and R. Salakhutdinov . Discriminativ e transfer learning with tree-based priors. In NIPS , 2013. [30] M. F . Stollenga, J. Masci, F . Gomez, and J. Schmidhuber . Deep networks with internal selective attention through feed- back connections. In NIPS , 2014. [31] C. Szegedy , W . Liu, Y . Jia, P . Sermanet, S. Reed, D. Anguelov , D. Erhan, V . V anhoucke, and A. Rabi- novich. Going deeper with con volutions. arXiv preprint arXiv:1409.4842 , 2014. [32] A.-M. T ousch, S. Herbin, and J.-Y . Audibert. Semantic hier- archies for image annotation: A surve y . P attern Recognition , 2012. [33] N. V erma, D. Mahajan, S. Sellamanickam, and V . Nair . Learning hierarchical similarity metrics. In CVPR , 2012. [34] T . Xiao, J. Zhang, K. Y ang, Y . Peng, and Z. Zhang. Error- driv en incremental learning in deep con volutional neural net- work for large-scale image classification. In Pr oceedings of the A CM International Confer ence on Multimedia , 2014. [35] M. Zeiler and R. Fergus. V isualizing and understanding con- volutional netw orks. In ECCV . 2014. [36] M. D. Zeiler and R. Fergus. Stochastic pooling for regu- larization of deep conv olutional neural networks. In ICLR , 2013. [37] B. Zhao, F . Li, and E. P . Xing. Large-scale category structure aware image cate gorization. In NIPS , 2011. [38] A. Zweig and D. W einshall. Exploiting object hierarchy: Combining models from different category lev els. In ICCV , 2007. 4329
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment