음성 기반 감정 인식 앙상블 프레임워크
본 논문은 영화·TV 프로그램 클립에서 추출한 실제 환경 음성을 대상으로, 다중 과제 학습과 다양한 음향·언어 특징을 결합한 앙상블 시스템을 제안한다. IS10 전통 특징, iVector, MFCC 기반 가중 풀링 RNN, 그리고 ASR 기반 텍스트 SVM을 각각 독립 서브시스템으로 학습하고, 선형 가중 결합으로 최종 결정을 만든다. 멀티태스크 DNN에 화자·성별 보조 과제를 추가함으로써 감정 분류 성능을 29.5% 상대적으로 향상시켰다.
저자: Fei Tao, Gang Liu, Qingen Zhao
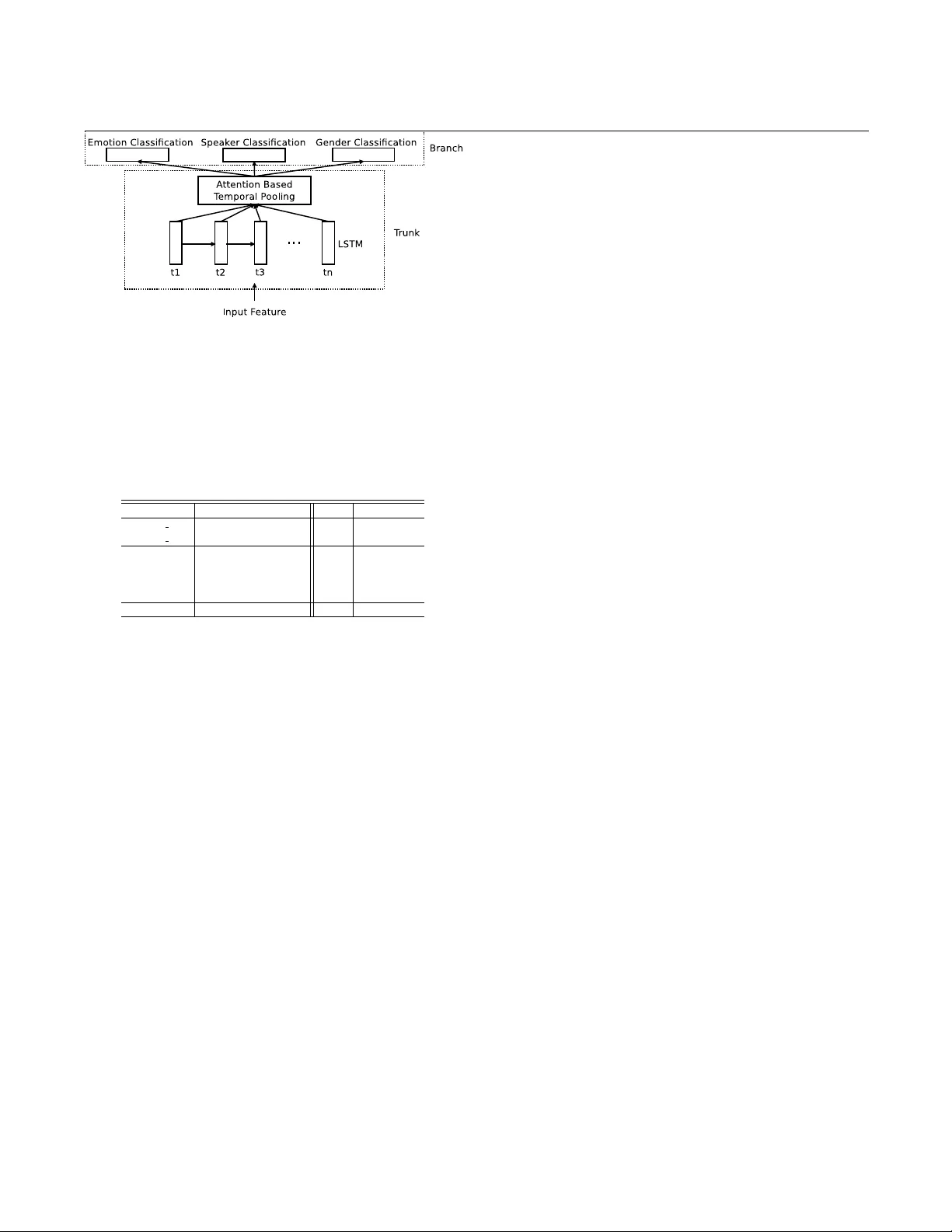
본 논문은 영화·TV 프로그램에서 추출한 실제 환경 음성 데이터를 대상으로, 감정 인식 시스템의 실용성을 높이기 위한 앙상블 프레임워크를 제안한다. 기존 연구들은 주로 스튜디오에서 녹음된 깨끗한 음성에 초점을 맞추어, 배경 잡음, 비음성 채우기(웃음, 한숨 등), 발화 길이 변동 등 실제 서비스 환경에서 발생할 수 있는 문제들을 충분히 다루지 못했다. 이를 보완하고자 저자들은 MEC 2017 코퍼스를 사용했으며, 이 코퍼스는 중국 영화·드라마·토크쇼에서 추출한 5.6시간 분량의 클립을 포함하고, 8가지 감정 라벨(angry, worried, anxious, neutral, disgust, surprise, sad, happy)과 2105명의 화자를 제공한다. 데이터는 SNR이 낮은 경우도 포함하고 있어 실환경의 복잡성을 잘 반영한다.
프레임워크는 네 개의 서브시스템으로 구성된다. 첫 번째는 IS10 전통 특징과 iVector를 각각 입력으로 하는 멀티태스크 DNN이다. 이 네트워크는 감정 분류를 메인 태스크로, 화자와 성별 분류를 보조 태스크로 설정하고, 공유된 트렁크 레이어(두 개의 4096/1024 뉴런)와 각 태스크별 브랜치 레이어(2048/1024 뉴런)로 구성된다. 멀티태스크 학습을 통해 감정과 화자·성별 간의 상관관계를 모델이 학습하도록 유도한다. 두 번째 서브시스템은 ASR 기반 텍스트 정보를 활용한다. 4000시간 데이터로 학습된 TDNN‑HMM ASR이 음성을 텍스트로 변환하고, 변환된 텍스트를 TF‑IDF 벡터화한 뒤 Crammer‑Singer 다중 클래스 SVM으로 감정을 예측한다. 세 번째는 36차원 시퀀스 음향 특징(MFCC, ZCR, 에너지 등)을 입력으로 하는 가중 풀링 RNN이다. 이 모델은 두 개의 트렁크 레이어(256‑ReLU, 128‑BiLSTM)와 attention‑like 가중치 행렬을 통해 중요한 프레임에 높은 가중치를 부여하고, 이후 브랜치 레이어에서 감정·화자·성별을 동시에 분류한다. 네 번째는 앞서 언급한 두 멀티태스크 DNN과 RNN을 포함한 전체 시스템을 선형 결합하는 앙상블 단계이다. 선형 가중치는 검증 셋에서 최소화된 로그우도비(C_llr)를 기준으로 Focal 툴킷을 사용해 최적화한다.
실험 설정은 훈련 4.4시간, 테스트 0.7시간으로 제한된 데이터 양에도 불구하고, 배치 크기 32, DNN은 SGD, RNN은 Adam 옵티마이저를 사용했으며, 멀티태스크 가중치는 감정 1.0, 화자 0.3, 성별 0.6으로 설정하였다. 평가 지표는 클래스 불균형을 고려한 Macro‑average F‑score(MAF)와 정확도이다. 결과는 다음과 같다. 베이스라인 랜덤 포레스트는 MAF 22.3%, 정확도 40.0%였으며, 단일 태스크 DNN은 MAF 26.4%, 정확도 40.2%를 기록했다. 멀티태스크 DNN(IS10)은 MAF 32.4%, 정확도 44.1%로 가장 큰 단일 서브시스템 성능을 보였고, iVector 기반 멀티태스크 DNN도 MAF 27.4%를 달성했다. 텍스트 SVM과 가중 풀링 RNN은 각각 MAF 17.7%와 23.2%로 베이스라인보다 낮았다. 그러나 네 개의 서브시스템을 선형 결합한 최종 앙상블은 MAF 34.2%, 정확도 41.0%를 달성, 베이스라인 DNN 대비 7.8% 절대, 약 29.5% 상대 향상을 기록했다.
논문의 주요 결론은 (1) 다양한 레벨의 음향 특징과 멀티태스크 학습을 결합하면 감정 인식 성능이 크게 개선된다, (2) 비음성 채우기와 같은 비정형 음성 이벤트도 attention 기반 RNN으로 효과적으로 처리할 수 있다, (3) 텍스트 정보는 ASR 품질에 따라 성능 변동이 크지만, 충분히 정확한 경우 보조 신호로 활용 가능하다, (4) 서브시스템 간의 상호 보완성을 활용한 앙상블이 단일 모델보다 우수한 결과를 만든다. 향후 연구에서는 더 큰 규모의 실시간 데이터와 고성능 ASR을 이용해 텍스트 서브시스템을 강화하고, 영상·텍스트·음성의 멀티모달 통합 모델을 개발함으로써 실제 서비스 환경에서의 적용 가능성을 높이는 방향을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기