An Ensemble Framework of Voice-Based Emotion Recognition System for Films and TV Programs
Employing voice-based emotion recognition function in artificial intelligence (AI) product will improve the user experience. Most of researches that have been done only focus on the speech collected under controlled conditions. The scenarios evaluate…
Authors: Fei Tao, Gang Liu, Qingen Zhao
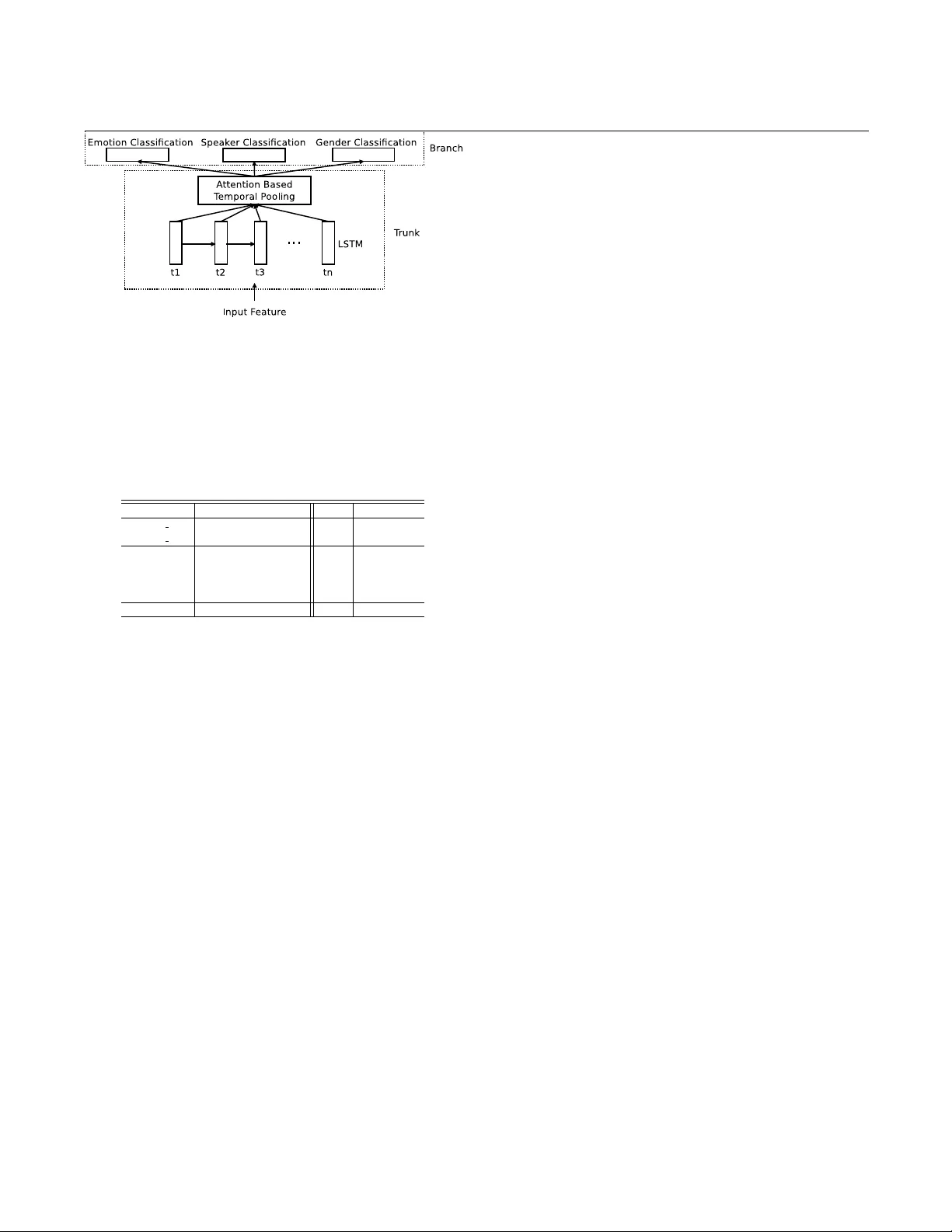
Accepted by 2018 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing AN ENSEMBLE FRAMEWORK OF V OICE-B ASED EMO TION RECOGNITION SYSTEM FOR FILMS AND TV PR OGRAMS F ei T ao 1 ∗ , Gang Liu 2 , Qingen Zhao 2 1. Multimodal Signal Processing (MSP) Lab, The Uni versity of T exas at Dallas, Richardson TX 2. Institute of Data Science and T echnology (iDST)-Speech, Alibaba Group (U.S.) Inc. fxt120230@utdallas.edu,g.liu@alibaba-inc.com,qingen.zqe@alibaba-inc.com ABSTRA CT Employing voice-based emotion recognition function in arti- ficial intelligence (AI) product will improve the user experi- ence. Most of researches that have been done only focus on the speech collected under controlled conditions. The scenar - ios ev aluated in these research were well controlled. The con- ventional approach may f ail when background noise or non- speech filler exist. In this paper , we propose an ensemble framew ork combining sev eral aspects of features from au- dio. The framework incorporates gender and speaker infor- mation relying on multi-task learning. Therefore it is able to dig and capture emotional information as much as pos- sible. This framew ork is ev aluated on multimodal emotion challenge (MEC) 2017 corpus which is close to real world. The proposed frame work outperformed the best baseline sys- tem by 29.5% (relativ e improv ement). Index T erms — multi-task learning, attention model, en- semble framew ork, deep learning, emotion recognition 1. INTRODUCTION Humans are emotional creatures. People desire reaction from others according to their emotion [1]. Artificial intelligence (AI) system will be more like human beings when it is able to do such reaction. This capability relies on recognizing emo- tion. Emotion recognition is therefore very important in AI product, since it will make human-computer interface (HCI) more friendly and improv e the user experience. Emotion recognition system based on audio (which can also be seen as voice-based) has very low requirement for hardware, e ven though multimodal speech processing can im- prov e speech related system performance [2, 3]. Therefore the audio based emotion recognition system is easier to be employed on AI product [1, 4] than other means. Howe ver , current voice-based AI products, such as Siri, Google voice search and Cortona, lack of emotion recognition capability , which make people feel them as “machine”. This sho ws the importance of exploring on the emotion recognition system. Researches hav e done in this area for decades [1, 5, 6, 7]. So f ar , most of the work has been done on the data collected in the studio environment. The data collection was well con- trolled, therefore the data is clean and well segmented. Be- ∗ This work was done during the author’s summer internship at Alibaba Group (U.S.) Inc. sides, most of the voice-based emotion recognition research hav e been done tar geting on speech. In real application, there are sev eral problems that may make current de veloped emo- tion recognition system failed. First, the non-speech voice fillers, such as laugh, whimper , cry , sigh, sob and etc., has no lexicon information but contains emotion information. Some- times people only perform non-speech v oice filler to e xpress their emotion. Second, the v oice segment length may v ary in a large range. Con ventional feature extraction may fail under this condition. Third, some people can control their intonation and only use the le xical information to e xpress their emotion. Acoustic feature will not work in this case. T o address these problems, we propose an ensemble framew ork that combines different aspects of features from audio to develop an emotion recognition system applicable in real w orld. The framework is ev aluated on the multimodal emotion challeng e (MEC) 2017 corpus. In this study , we focus on categorical emotion recognition, which is the task defined in MEC 2017. The corpus was collected by capturing clips from films and TV programs. These clips may con- tain background noise and only have non-speech voice filler , which is very close to real world scenarios. The rest parts of the paper are org anized as following: Section 2 re views related work about emotion recognition and previous work on audio-based approach; Section 3 describes the MEC 2017 corpus; Section 4 shows our proposed approach including the sub-system and the ensemble frame work; Section 5 sho ws the experiments results and discuss about results analysis; Section 6 concludes our work and discusses the future work. 2. RELA TED WORK V oice-based emotion recognition has been done for decades. [5] extracted prosodic features from speech and applied ma- jority voting of subspace specialists. It was a pilot study exploring static classifier and features for speech-based emo- tion recognition. [6] built phoneme-based dependent hidden Markov model (HMM) classifier for emotion recognition. This work indicated the speech contents w as related to emo- tion. Both of [6, 4] showed the adv antage of HMM ov er static model. [8] discussed the feature set for emotion recognition task. The feature sets proposed by these works showed reli- able performance. [9] also used le xical information besides acoustic and sho wed it was helpful for acoustic e vent identi- Accepted by 2018 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing fication. Ho wev er , most of the work only focused on speech part rather than non-speech voice fillers. Deep learning techniques were emerging as new classifier in speech related machine learning area[10]. The deep learn- ing techniques, such as deep neural network (DNN), con vo- lutional neural network (CNN) and recurr ent neural network (RNN) is able to model the feature in a high dimensional manifold space. DNN as static classifier and RNN as dy- namic classifier sho wed their advantage in emotion recogni- tion task compared with con ventional approaches [11]. Espe- cially , [11] used attention based weighted pooling to extract acoustic representation. It sho wed adv antage ov er the con- ventional hand crafted features. Multi-task learning recently raised as a technique helping train better model for main task [12, 13]. Ho we ver these w ork used v alence and arousal as auxiliary tasks which may be difficult to get. In this study , we use deep learning techniques with multi- task learning to build better classifier for cate gorical emotion recognition. The work includes the follo wing novelties. 1. W e combine different features including classical hand-craft feature and high level representation learned from deep learn- ing techniques. The framew ork considered both speech and non-speech audio. 2. multi-task learning techniques were ap- plied to DNN and weighted pooling RNN with the auxiliary tasks of speaker and gender classification, whose labels can be easily acquired. 3. Lexical information from speech was also incorporated into the system. 4. the framew ork was tar- geting at the corpus which is close to real world scenarios. 3. CORPUS DESCRIPTION This study uses the MEC 2017 corpus [14]. The corpus in- cludes the clips from Chinese films, TV plays and talk sho ws. The clip has both of audio and video. The video is under resolution of 1028 × 680 with 24 frames per second (FPS). The audio is under 44.1 kHz sample rate with mono chan- nel. In this study , we do wnsample the audios to 16 kHz. The total duration is 5.6 hours. Each clip has one label among eight classes, angry , worried, anxious, neutral, disgust, sur- prise, sad and happy . The duration of the clips vary from 0.24 secs to 46.71 secs. The av erage duration is around 4.1 secs. There are 2105 speakers in this corpus. The gender is almost balanced. The male to female ratio is 0.46 to 0.54. The signal-to-noise ratio (SNR) distribution is sho wn in Figure 1. The clips is not captured in the controlled studio environment, so there might be background noise in the clips (sev eral clips hav e lower than 10 db SNR). Since this is a challenge task, the training and testing set has been determined. The statistics for each cate gory is listed in the T able 1. It can be seen that the data is imbalance but the distribution in training and testing sets are v ery similar . 4. PROPOSED APPRO A CH W e propose 4 sub-systems in this ensemble frame work. The decisions are fused with linear combination. W e use the open source toolkit Focal [15] to fuse the decisions from the 4 sub- systems. It determines the linear combination weight by min- Fig. 1 . The SNR distribution of MEC 2017 corpus. The y- axis is the proportion. The x-axis is the SNR value (dB). T able 1 . The distribution of MEC 2017 corpus on train set. Category Training T esting Count Proportion Count Proportion Angry 884 0.180 128 0.181 W orried 567 0.115 81 0.115 Anxious 457 0.093 66 0.093 Neutral 1400 0.285 200 0.283 Disgust 144 0.029 21 0.030 Surprise 175 0.036 25 0.035 Sad 462 0.094 67 0.095 Happy 828 0.168 119 0.168 T otal 4917 1.000 707 1.000 imizing cost of the log-likelihood ratio ( C llr ). The framework diagram is shown in Figure 2 4.1. Multi-task DNN W e built multi-task DNN with the main task of emotion clas- sification and the auxiliary tasks of speaker and gender clas- sification. The system diagram is shown in Figure 3. The assumption that emotion is related to speaker and gender in- spires us to incorporate speaker and gender information into the classifier . The feature set pro vided in Interspeech 2010 paralinguis- tic challenge (we name it as “IS10” feature set) [8] has been used and proved to work well in emotion recognition and speaker ID tasks. Therefore, we select this as one feature set to multi-task DNN. W e use openSMILE [16] to extract the IS10 feature set. iV ector [17] has been proved to work well in speaker ID task. It was also used in emotion classification Fig. 2 . The proposed framework diagram. It has 4 sub- systems. The final decision is made by linearly combining sub-systems’ decisions. Accepted by 2018 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing Fig. 3 . The multi-task DNN. The trunk part has the layers that are shared by all the tasks. On top of the trunk part, there is branch part for tasks. The main task is emotion classification. The auxiliary tasks are speaker and gender classifications. [18]. Compared with IS10 feature set, it is a high lev el fea- ture, which contains speaker and channel information. It is also selected as input feature to another multi-task DNN. An iV ector e xtractor is trained based on 2000 hours of cellphone data [19]. For each utterance, a 200-dimension iV ector is ex- tracted. iV ector has a disadvantage that it may not be reliable with short utterance, while IS10 is not affected by utterance duration. W e e xpect the iV ector and IS10 feature set can com- plement each other . In this study , we define the architectures of the multi-task DNNs according to the inputs, since they hav e dif ferent di- mension number . For the IS10 input, the multi-task DNN has two hidden layers in the trunk part with 4096 neurons in each layer . In the branch part, there are one hidden layer for each task with 2048 neurons. On top of that, there is a softmax layer for task classification. For the iV ector input, the archi- tecture is same. But in the trunk part the neuron number is 1024 per layer and in the branch part the neuron number is 1024 per layer . All the neuron type is r ectified linear unit (RELU). The dropout rate is 0.5. 4.2. Lexical Support V ector Machine W e also built a sub-system which is a support vector ma- chine (SVM) based on lexical information. An automatic speech reco gnition (ASR) system trained with 4000 hours data was used to recognize the speech contents. The ASR is a HMM framew ork with time-delay DNN (TDNN) acous- tic model [20]. After recognizing text, LibShortT ext toolkit is adopted for text based emotion classification [21] with the feature of term frequency in verse document frequency (TF- IDF). The classification is based on support vector classifica- tion by Crammer and Singer . 4.3. Attention Based W eighted Pooling RNN There are utterances in the corpus only containing non-speech voice filler such as laugher , whimper , sob and etc. In addi- tional, the utterance may contain long silence or pause. Us - ing IS10 feature set may not accurately represent acoustic characteristics. In this study , we build a sub-system which is a RNN with attention based weighted pooling to address these issues. RNN was used to model acoustic e vent [22, 23], which can be voice filler . Attention based weighted pooling has been pro ved to w ork better than basic statistics, lik e av er- aging, summation and so on, because it is able to capture the informativ e section rather than silence or pause part [11]. The system diagram is shown in Figure 4. The input feature is a 36D sequential acoustic feature. The acoustic feature includes 13D MFCCs, zer o cr ossing rate (ZCR), energy , entropy of energy , spectral centroid, spectral spread, spectral entropy , spectral flux, spectral rolloff, 12D chroma v ector , chroma deviation, harmonic ratio and pitch. It is extracted from a 25 ms window . The window shifting step size is 10 ms. The weighted pooling is obtained by the Equation 1, where h T is the hidden v alue output from the long short-term memory (LSTM) layer at time T , and A T is the weight. T is from time step t 1 to tn (sequence length is n). A T is a scalar computed by Equation 2, where W is the weight to be learned. Equation 2 is a softmax-like equation which is simi- lar to attention model [24, 11]. By learning W , it is expected that segments of interest are assigned high weight, while segments of silence or pause are assigned low weight. This model is targeting at not only speech but also other acoustic ev ent, like voice fillers. In this model, we also use multi- task learning, which is e xpected to learn better representation from weighted pooling compared with single task. In this study , we used a new type of LSTM, which is named as advanced LSTM (A-LSTM). It is verified that it has better capability of modeling timing dependency . The A- LSTM architecture is proposed in [25]. This network has tw o hidden layers in the trunk part. The first one is fully connected layer with 256 RELU neurons. The second one is a bidir ectional LSTM (BLSTM) layer with 128 neurons. W eighted pooling is performed on top of the LSTM layer . The representation from weighted pooling is then sent to the branch part. In the branch part, each task has one fully connected layer with 256 RELU neurons. On top of that, there is a softmax layer performing classification. The dropout rate is 0.5. W eig htedP ool ing = tn X T = t 1 A T × h T (1) A T = exp( W · h T ) P tn T = t 1 exp( W · h T ) (2) 5. EXPERIMENTS AND RESUL TS The proposed approach is ev aluated on MEC 2017 corpus. W e build two baseline systems for comparison. One is ran- dom forest and the other one is a DNN with single task of emotion classification. Both of the baseline systems take IS10 feature set. The details of experiment settings and results are described in the following sections. 5.1. Experiments Setting The training data is 4.4 hours and testing data is 0.7 hour . The batch size for all the neural network training in this study is 32. The multi-task DNN was trained with SGD optimizer , Accepted by 2018 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing Fig. 4 . The attention based weighted pooling RNN. The LSTM layer is unrolled along the time axis (time t1 to tn). The trunk part has the layers that are shared by all the tasks. On top of the trunk part, there is branch part for tasks. The main task is emotion classification. The auxiliary tasks are speaker and gender classifications. T able 2 . The performance of varieties of systems in ev alua- tion experiments. MAF is macro average F-score. System Category Approach MAF Accuracy (%) Baseline 1 Random Forest 22.3 40.0 Baseline 2 DNN 26.4 40.2 Sub-system Multi-task DNN (IS10) 32.4 44.1 Multi-task DNN (iV ector) 27.4 38.0 Lexical SVM 17.7 30.1 W eighted Pooling RNN 23.2 39.7 Proposed Ensemble Fusion 34.2 41.0 while the RNN was trained with Adam optimizer . The task weights for emotion, speaker , gender classification were 1, 0.3, 0.6 respectively . The baseline DNN with single task has three hidden layers. There are 4096 RELU neurons in the first two, and 2048 RELU neurons in the last one. This is the same architecture as multi-task DNN except that it does not hav e the auxiliary tasks part. The baseline random forest has 100 trees with 10 depth. This is the setting provided by the challenge organizer [14]. The IS10 feature was z-normalized with the mean and variance of the training data. The sequen- tial feature was z-normalized within utterance. During train- ing, 10% of training data was set as validation data. The linear combination weight used in fusion was also trained from the validation set. In the e valuation, we use the metrics of macr o aver age F- scor e (MAF) (also called unweighted F-score) and accuracy . The MAF is computed by av eraging the F-score for each class detection. The accuracy is computed by dividing correctly de- tected sample number divided with the total sample number . Since the data is imbalance, accuracy may not be accurate to represent the system performance and MAF will be adopted as the main metric. 5.2. Evaluation Results The ev aluation results are sho wn in T able 2. The performance of baseline systems, sub-systems and proposed framework is listed. Comparing the baseline systems, it shows the DNN out- performs the random forest by 4.1% (absolute difference). This shows DNN has better modeling capability even with 4.4 hours training data. The multi-task DNN taking IS10 fea- ture has 6% absolute improv ement compared with the base- line DNN. It indicates that the speaker and gender classifica- tion tasks are helpful for emotion classification. The multi- task DNN taking iV ector feature also outperforms the base- line DNN with 1% absolute gain. This proves iV ector can also work well in emotion classification task. The perfor- mance of lexical SVM and weighted pooling RNN is lower than the baseline DNN. For the lexical SVM, it relies on the text information from ASR which may not be perfectly reli- able. For weighted pooling RNN, the shortage of training data is a key issue. 4.5 hours training to train RNN may not be suf- ficient. The performance from fusion achieve highest MAF . It shows the sub-systems in the ensemble framew ork are com- plementing each other . Compared with the best baseline sys- tem, which is the single task DNN, the ensemble framew ork offers 7.8% absolute improvement (about 29.5% relativ e im- prov ement). 6. CONCLUSION AND FUTURE WORK In this study , we proposed an ensemble framework for cat- egorical emotion recognition. The proposed framework was ev aluated on MEC 2017 corpus, whose data was close to real world scenarios. W e found multi-task learning with auxil- iary tasks of speak er and gender classification was helpful for emotion classification. Labels for these tasks are normally easily obtained. Fusion of dif ferent sub-systems achieved bet- ter performance. It indicates capturing different aspects of features from input audio can improve the modeling capabil- ity . Since the e valuation w as done on acted data in this paper , the proposed framework need be ev aluated on the data from real world in the future. Besides, more data is needed for training, which may lead to better performance. 7. REFERENCES [1] C. Busso, Z. Deng, S. Y ildirim, M. Bulut, C.M. Lee, A. Kazemzadeh, S. Lee, U. Neumann, and S. Narayanan, “ Analysis of emotion recognition using facial expressions, speech and multimodal information, ” in Sixth International Confer ence on Multimodal Inter- faces ICMI 2004 , State College, P A, October 2004, pp. 205–211, A CM Press. [2] F . T ao and C. Busso, “Lipreading approach for isolated digits recognition under whisper and neutral speech., ” in INTERSPEECH 2014 , Singapore, Sep. 2014, pp. 1154– 1158. [3] F . T ao and C. Busso, “Bimodal recurrent neural network for audiovisual voice activity detection, ” in Interspeech 2017 , Stockholm, Sweden, Sep. 2017, pp. 1938–1942. Accepted by 2018 IEEE International Confer ence on Acoustics, Speech and Signal Pr ocessing [4] B. Schuller , G. Rigoll, and M. Lang, “Hidden Markov model-based speech emotion recognition, ” in ICASSP 2003 , Hong K ong, China, April 2003, vol. 2, pp. 1–4. [5] F . Dellaert and T . Polzin A. W aibel, “Recognizing emo- tion in speech, ” in (ICSLP 1996 , Philadelphia, P A, USA, October 1996, vol. 3, pp. 1970–1973. [6] C.M. Lee, S. Y ildirim, M. Bulut, A. Kazemzadeh, C. Busso, Z. Deng, S. Lee, and S.S. Narayanan, “Emo- tion recognition based on phoneme classes, ” in ICSLP 2004 , Jeju Island, K orea, October 2004, pp. 889–892. [7] J. Deng, X. Xu, Z. Zhang, S. Fr ¨ uhholz, D. Grandjean, and B. Schuller , “Fisher kernels on phase-based features for speech emotion recognition, ” in Dialogues with So- cial Robots , pp. 195–203. Springer , 2017. [8] B. Schuller , S. Steidl, A. Batliner , F . Burkhardt, L. Dev- illers, C. Muller , and S. Narayanan, “The INTER- SPEECH 2010 paralinguistic challenge, ” in Interspeec h 2010 , Makuhari, Japan, September 2010, pp. 2794– 2797. [9] Q. Jin, C. Li, S. Chen, and H. W u, “Speech emo- tion recognition with acoustic and lexical features, ” in ICASSP 2015 , Queensland, Australia, Apr . 2015, IEEE, pp. 4749–4753. [10] G. Hinton, S. Osindero, and Y . T eh, “ A fast learning algorithm for deep belief nets, ” Neural computation , vol. 18, no. 7, pp. 1527–1554, 2006. [11] S. Mirsamadi, E. Barsoum, and C. Zhang, “ Automatic speech emotion recognition using recurrent neural net- works with local attention, ” in ICASSP 2017 , New Or- leans, U.S.A., Mar . 2017, IEEE, pp. 2227–2231. [12] R. Xia and Y . Liu, “ A multi-task learning frame work for emotion recognition using 2d continuous space, ” IEEE T ransactions on Affective Computing , vol. 8, no. 1, pp. 3–14, 2017. [13] S. Parthasarathy and C. Busso, “Jointly predicting arousal, valence and dominance with multi-task learn- ing, ” in INTERSPEECH 2017 , Stockholm, Sweden, Aug. 2017. [14] Y . Li, J. T ao, B. Schuller, S. Shan, D. Jiang, and J. Jia, “MEC 2016: The multimodal emotion recognition chal- lenge of ccpr 2016, ” in Chinese Confer ence on P attern Recognition 2016 , pp. 667–678. Springer , 2016. [15] Niko Brummer , “Focal, ” https://sites.google.com/site/nikobrummer/focal, 2017, Retrie ved Aug 1st, 2017. [16] F . Eyben, M. W ¨ ollmer , A. Graves, B. Schuller , E. Douglas-Cowie, and R. Cowie, “On-line emotion recognition in a 3-D activ ation-valence-time continuum using acoustic and linguistic cues, ” Journal on Multi- modal User Interfaces , vol. 3, no. 1-2, pp. 7–19, March 2010. [17] N. Dehak, P .J. Kenn y , R. Dehak, P . Dumouchel, and P . Ouellet, “Front-end factor analysis for speaker ver- ification, ” IEEE T ransactions on Audio, Speech, and Language Pr ocessing , v ol. 19, no. 4, pp. 788–798, 2010. [18] R. Xia and Y . Liu, “Dbn-iv ector framew ork for acous- tic emotion recognition., ” in INTERSPEECH 2016 , San Francisco,U.S.A, Sept. 2016, pp. 480–484. [19] G. Liu, Q. Qian, Z. W ang, Q. Zhao, T . W ang, H. Li, J. Xue, S. Zhu, R. Jin, and T . Zhao, “The opensesame NIST 2016 speaker recognition ev aluation system, ” in Interspeech 2017 , Stockholm, Sweden, Sep. 2017, pp. 2854–2858. [20] V . Peddinti, D. Pov ey , and S. Khudanpur , “ A time de- lay neural network architecture for ef ficient modeling of long temporal contexts., ” in INTERSPEECH 2015 , Dresden, Germany , Sept. 2015, pp. 3214–3218. [21] H. Y u, C. Ho, Y . Juan, and C. Lin, “Libshorttext: A li- brary for short-te xt classification and analysis, ” Rapport interne, Department of Computer Science , National T ai- wan University . Software available at http://www . csie. ntu. edu. tw/˜ cjlin/libshorttext , 2013. [22] G. Parascandolo, H. Huttunen, and T . V irtanen, “Re- current neural networks for polyphonic sound e vent detection in real life recordings, ” arXiv pr eprint arXiv:1604.00861 , 2016. [23] E. Cakir , G. Parascandolo, T . Heittola, H. Huttunen, and T . V irtanen, “Con volutional recurrent neural networks for polyphonic sound event detection, ” IEEE/ACM T ransactions on Audio, Speech, and Languag e Pr ocess- ing , vol. 25, no. 6, pp. 1291–1303, 2017. [24] Dzmitry D. Bahdanau, J. Chorowski, D. Serdyuk, and Y oshua Y . Bengio, “End-to-end attention-based large vocab ulary speech recognition, ” in ICASSP 2016 , Shanghai, China, Apr . 2016, IEEE, pp. 4945–4949. [25] F . T ao and G. Liu, “ Advanced LSTM: A study about bet- ter time dependency modeling in emotion recognition, ” in ICASSP 2018 , Calgary , Canada, Apr . 2017.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment