BridgeNet 학생 교사 전이 학습 기반 재귀 신경망으로 원거리 음성 인식 향상
BridgeNet은 교사 네트워크의 소프트 라벨뿐 아니라 중간 층 특징을 힌트로 제공하고, 재귀 구조를 통해 반복적으로 노이즈 제거와 인식 성능을 개선한다. AMI 데이터셋에서 최대 13.24% 상대 WER 감소를 달성하였다.
저자: Jaeyoung Kim, Mostafa El-Khamy, Jungwon Lee
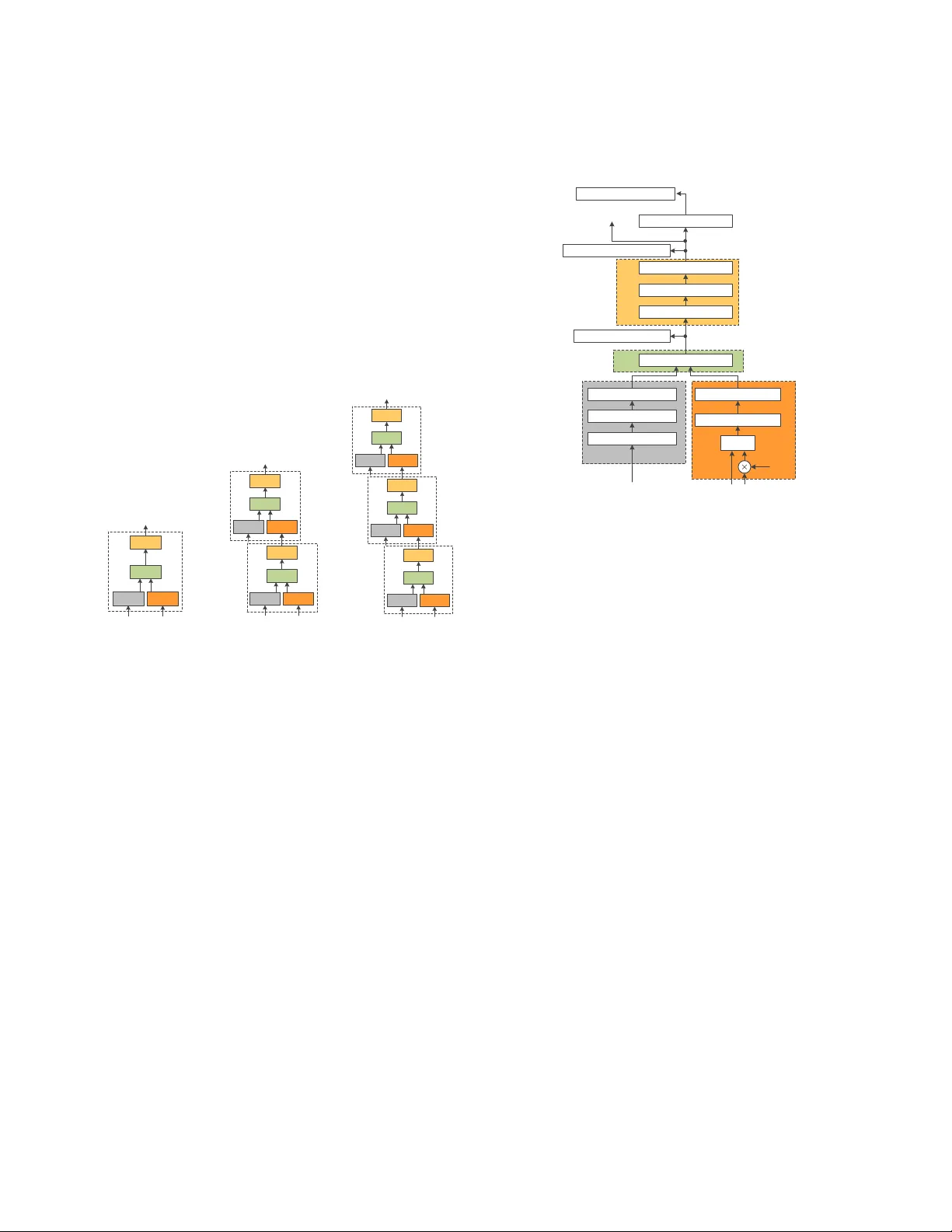
본 논문은 원거리 음성 인식(Distant Speech Recognition, DSR)의 핵심 과제인 노이즈와 리버브에 대한 강인성을 향상시키기 위해 ‘BridgeNet’이라는 새로운 학생‑교사 전이 학습 프레임워크를 제안한다. 기존의 지식 증류(Knowledge Distillation, KD)와 일반화 증류(Generalized Distillation, GD)는 교사의 소프트 라벨만을 학생에게 전달하는데, 이는 학생이 교사의 고수준 일반화 능력을 모방하는 데는 도움이 되지만, 실제 입력 신호의 왜곡을 직접 정정하는 데는 한계가 있다. BridgeNet은 이 한계를 극복하고자, 교사의 중간 층 특징을 ‘힌트’(hint)로 제공하는 다중 지식 브리지를 도입한다. 이러한 힌트는 교사의 내부 표현을 직접 학생의 대응 층에 매핑함으로써, 학생이 노이즈가 섞인 입력을 보다 효과적으로 디노이징하고, 동시에 인식 성능을 높이는 방향으로 학습한다.
BridgeNet의 핵심 구조는 두 부분으로 나뉜다. 첫째, ‘지식 브리지’ 메커니즘이다. 교사 네트워크와 학생 네트워크는 각각 재귀 신경망 형태로 설계되며, 교사는 깨끗한 IHM(Individual Headset Microphone) 데이터를 사용해 학습한다. 교사의 각 중간 층에서 추출된 특징 h_i는 학생 네트워크의 대응 층 q_i와 MSE 손실(또는 소프트맥스 출력의 경우 교차 엔트로피 손실)로 정규화된다. 전체 손실은 각 브리지 손실에 가중치 α_i를 곱한 합으로 정의되어, 학생이 다중 힌트를 동시에 학습하도록 유도한다.
둘째, ‘재귀 신경망’(Recursive Neural Network) 설계이다. 이 구조는 네 개의 서브 블록(I, F, M, L)으로 구성된다. I 블록은 원시 음향 특징을 처리하고, F 블록은 이전 재귀 단계에서 전달된 피드백 음소 상태를 받아들인다. 두 입력은 M 블록에서 차원 축소와 병합을 거쳐, L 블록(Residual LSTM)으로 전달된다. 재귀 단계 R이 증가함에 따라 동일한 입력 x_t가 매 단계마다 재사용되며, 이는 전역 쇼트컷 역할을 수행해 깊은 네트워크 학습 시 기울기 소실을 방지한다. 또한, Residual LSTM을 적용해 각 서브 블록 내부에 스킵 연결을 삽입, 학습 안정성을 강화하였다.
실험은 AMI 코퍼스의 세 가지 데이터 유형을 사용한다. IHM은 깨끗한 라벨링을 제공하고, SDM은 원거리 마이크, MDM은 8채널 빔포밍을 통해 얻은 다채널 데이터이다. 베이스라인으로는 동일 구조의 CNN‑LSTM 모델을 사용했으며, 특징은 9×9 및 3×1 커널을 가진 두 개의 CNN 레이어와 1024 메모리 셀·512 히든 노드를 가진 Residual LSTM이다.
먼저, 다중 작업 디노이징(Multi‑Task Denoising) 실험에서는 기존 연구와 달리 큰 성능 향상이 관찰되지 않았다. 이는 고성능 CNN‑LSTM 모델이 이미 충분히 강력해 추가적인 디노이징 손실이 오히려 과적합을 초래할 수 있음을 시사한다.
다음으로 BridgeNet의 다양한 변형을 평가하였다. 비재귀 모델(R0)에서 KD만 적용하면 베이스라인 대비 약 4%~5%의 상대 WER 감소를 보였으며, DR(디멘션‑리덕션)과 LSTM3 브리지를 추가하면 최대 6.9%까지 개선되었다. 재귀 구조를 도입한 모델(R1)에서는 학생이 한 번 재귀하고 교사는 두 번 재귀하는 설정으로, KD+DR+LSTM3 조합이 가장 큰 효과를 나타냈다. SDM 데이터에 대해 전체 WER이 13.24% 감소하고, 메인 스피커 WER은 10.88% 감소하였다. MDM 데이터에서도 유사한 경향이 관찰되어, 재귀 구조와 다중 힌트가 원거리·다채널 음성 인식 모두에서 일관된 이점을 제공한다는 것을 확인했다.
결론적으로, BridgeNet은 (1) 교사의 중간 특징을 활용한 다중 지식 브리지, (2) 재귀적 피드백을 통한 단계별 디노이징·인식 상호 강화라는 두 축을 결합함으로써, 기존 KD 기반 전이 학습보다 월등히 높은 성능을 달성한다. 특히, 재귀 구조는 동일 입력을 여러 단계에 걸쳐 재사용함으로써 깊은 네트워크 학습의 효율성을 높이고, 지식 브리지는 학생이 교사의 고수준 표현을 직접 모방하도록 유도한다. 이러한 설계는 향후 다양한 잡음 환경 및 다채널 마이크 배열에 적용 가능한 범용적인 원거리 음성 인식 프레임워크로 확장될 가능성을 보여준다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기