BridgeNets: Student-Teacher Transfer Learning Based on Recursive Neural Networks and its Application to Distant Speech Recognition
Despite the remarkable progress achieved on automatic speech recognition, recognizing far-field speeches mixed with various noise sources is still a challenging task. In this paper, we introduce novel student-teacher transfer learning, BridgeNet whic…
Authors: Jaeyoung Kim, Mostafa El-Khamy, Jungwon Lee
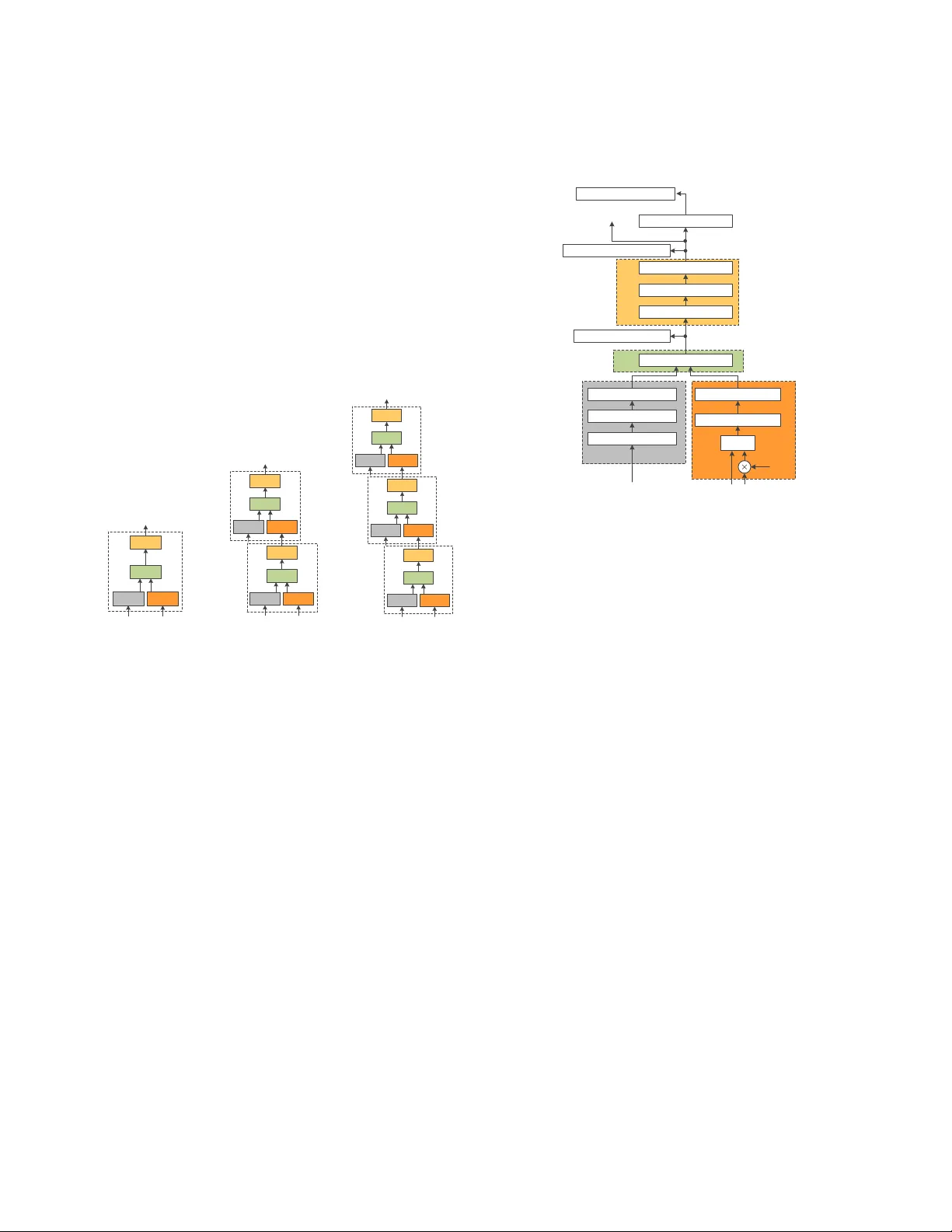
BRIDGENETS: STUDENT -TEA CHER TRANSFER LEARNING B ASED ON RECURSIVE NEURAL NETWORKS AND ITS APPLICA TION T O DIST ANT SPEECH RECOGNITION J aeyoung Kim, Mostafa El-Khamy , J ungwon Lee Samsung Semiconductor , Inc. USA Emails: { jaey1.kim, mostaf a.e, jungwon2.lee } @samsung.com ABSTRA CT Despite the remarkable progress achiev ed on automatic speech recognition, recognizing far-field speeches mixed with various noise sources is still a challenging task. In this paper , we introduce nov el student-teacher transfer learning, BridgeNet which can provide a solution to improv e distant speech recognition. There are two key features in BridgeNet. First, BridgeNet e xtends traditional student-teacher frame- works by providing multiple hints from a teacher network. Hints are not limited to the soft labels from a teacher net- work. T eacher’ s intermediate feature representations can better guide a student network to learn how to denoise or derev erberate noisy input. Second, the proposed recursiv e architecture in the BridgeNet can iterati vely impro ve denois- ing and recognition performance. The experimental results of BridgeNet showed significant improvements in tackling the distant speech recognition problem, where it achiev ed up to 13.24% relative WER reductions on AMI corpus compared to a baseline neural network without teacher’ s hints. Index T erms — distant speech recognition, student- teacher transfer learning, recursiv e neural networks, AMI 1. INTRODUCTION Distant speech recognition (DSR) is to recognize human speeches in the presence of noise, re verberation and interfer- ence caused mainly by the large distance between speakers and microphones. DSR is a challenging task especially due to unav oidable mismatches in signal quality between nor- mal close-talking and far-field speech signals. T raditional speech recognizers trained with speech samples from close- talking microphones show significant performance drops in recognizing far -field signals. There have been great efforts to improve DSR perfor- mance. T raditional front-end approaches interconnect multi- ple independent components such as speech enhancer [1, 2], acoustic speech detector [3, 4], speaker identification [5, 6] and many other blocks before a speech recognition module. The interconnected components denoise and derev erberate far -field speeches to generate enhanced data. A major issue in these approaches is the mismatch between combined com- ponents because they are independently optimized without consideration of each other . Many end-to-end methods are proposed to overcome the issue of front-end approaches by jointly optimizing multiple components in the unified framew ork. Among them, we dis- cuss two popular approaches rele vant to our method. Multi-task denoising [7, 8, 9] jointly optimizes denoising and recognition sub-networks using synchronized clean data. It minimizes the weighted sum of two loss functions: cross- entropy loss from recognition sub-network output and mean square error (MSE) loss between denoising sub-network out- put and clean data. Although multi-task denoising showed some improvements on DNN acoustic models, minimizing MSE between ra w acoustic data and high-le vel abstracted fea- tures is often unsuccessful. Its performance depends heavily on the underlying acoustic models. Knowledge distillation (KD) [10, 11] transfers the gen- eralization ability of a bigger teacher network to a typically much smaller student network. It provides soft-target infor- mation computed by the teacher network, in addition to its hard-targets, so the student network can learn to generalize similarly . Generalized distillation (GD) [12, 13, 14] extends distillation methods by training a teacher network with sep- arate clean data. A student network is trained on noisy data and, at the same time, guided by the soft-labels from a teacher which has access to synchronized clean speech. The gen- eralized distillation methods showed decent performance on CHiME4 and Aurora2 corpora. In this paper , we propose novel student and teacher trans- fer learning, BridgeNet which further extends kno wledge dis- tillation [10]. There are two key features in BridgeNet. • BridgeNet provides multiple hints from a teacher net- work. KD and GD methods utilize only teacher’ s soft labels. BridgeNet provides teacher’ s intermediate feature representations as additional hints, which can properly regularize a student network to learn signal denoising. • The proposed recursiv e architecture in the BridgeNet can iteratively refine recognition and denoising perfor- mance. As ASR performance can be enhanced by sig- nal denoising, signal denoising can be also improved by reference to ASR output. The proposed recursiv e ar- chitecture enables bi-directional information flo ws be- tween signal denoising and speech recognition func- tions by simple network cascading. The experimental results confirm the effecti veness of BridgeNet by showing that BridgeNet with multiple hints presented up to 10.88% accurac y improvements on the distant speech AMI corpus. With a recursi ve architecture, BridgeNet achiev ed up to 13.24% improv ements. 2. BRIDGENETS 2.1. Network Description BridgeNet provides novel student-teacher transfer learning based on a new recursiv e architecture to deploy the learning- from-hints paradigm [15]. Figure 1 presents a high-lev el block diagram of BridgeNet. Both student and teacher net- works are constructed from a recursive network. They don’t need to have the same recursion number . T ypically , a teacher network can hav e more recursions because its complexity only matters during training stage. BridgeNet uses a collection of triplets as training data: ( x ∗ t , x t , y t ) . x ∗ t is enhanced or less noisy data, x t and y t are noisy data and their labels. A teacher network is trained with x ∗ t and y t pairs. The trained teacher network provides its in- ternal feature representations as hints to a student network. Knowledge bridges are connections between teacher’ s hints and student’ s guided layers. The connected two layers at the knowledge bridges should have similar le vel of abstraction. For example, the student’ s knowledge bridge of LSTM3 in Figure 3 should be connected to the similar LSTM output at the teacher network. An error measure e i of how a feature representation q i from a student network agrees with the hint h i is computed at the knowledge bridge as a MSE loss, e i ( φ S ) = L X t =1 k h i ( x ∗ t ) − q i ( x t ; φ S ) k 2 (1) where φ S is the learnable parameters of a student network. Since h 1 and q 1 are softmax probabilities of teacher and stu- dent networks, the cross-entropy loss is used for e 1 instead. e 1 ( φ S ) = − L X t =1 ( P T ( x ∗ t ; φ T )) T log P S ( x t ; φ S ) (2) The parameters of the student network are then optimized by minimizing a weighted sum of all corresponding loss func- tions, L ( φ S ) = N X i =1 α i e i ( φ S ) (3) ℎ 1 Knowledge Bridge N Knowledge Bridge i Knowledge Bridge 1 Student Network Teacher Network ℎ 𝑁 ℎ 𝑖 𝑒 1 𝑒 𝑖 𝑒 𝑁 Loss Function 𝑞 𝑁 𝑞 𝑖 𝑞 1 𝜙 𝑇 Student Network Teacher Network Teacher Network Student Network 𝑥 𝑡 ∗ 𝑥 𝑡 𝑠 𝑡 ∗𝑀 − 1 𝜙 𝑆 𝑠 𝑡 ∗𝑀 − 2 𝑠 𝑡 ∗𝑀 − 3 𝑠 𝑡 𝑁 − 1 𝑠 𝑡 𝑁 − 2 𝑠 𝑡 𝑁 − 3 𝜙 𝑆 𝜙 𝑆 𝜙 𝑇 𝜙 𝑇 N N-1 N-2 M M-1 M-2 𝑃 𝑆 ( 𝑥 𝑡 ; 𝜙 𝑆 ) 𝑃 𝑇 ( 𝑥 𝑡 ∗ ; 𝜙 𝑇 ) Fig. 1 . Conceptual Diagram of BridgeNet where α i is a predetermined weighting factor for e i . Since student and teacher networks have multiple recur- sions, the same kno wledge bridges can be repeatedly con- nected for every recursion. Howe ver , any knowledge bridge added at the intermediate recursion always degraded perfor- mance. BridgeNet adds knowledge bridges only at the last recursion as shown in Figure 1. 2.2. Recursive Ar chitecture In this section, we present a ne w recursi ve architecture. A re- cursiv e neural network is popularly used in sentence parsing, sentimental analysis, sentence paraphrase and many other ar- eas. It applies the same set of weights recursi vely over a struc- ture. Its concept is similar to a recurrent network but there is a clear dif ference in that a recursi ve neural network can traverse a giv en structure in any topological order . Figure 2 (a) shows building blocks of a proposed recur- siv e architecture. It is composed of four sub-blocks: I and F take acoustic features and feedback states as their input, M merges I and F outputs and L produces recognized phone states. Each block can be any type of network. i n t , f n t , m n t and s n t represents output for the corresponding sub-blocks. n indicates the recursion number . l init is a zero vector used as input for the zero recursion. The advantage of this sub-block division enables a net- work to recurse with heterogeneous input and output types. For example, a typical acoustic model has context-dependent phones as a network output. This output cannot be fed into an input for the next recursion because the network input is an acoustic signal that is totally different from phone states. The proposed architecture provides two dif ferent input paths. They are processed independently and merged later at the M . Figure 2 presents ho w to unroll the proposed recursi ve network in the depth direction. R implies the number of re- cursion. The same input x t is applied to the network for each recursion. This repeated input acts as a global shortcut path that is critical to train a deep architecture. Our proposed re- cursiv e network can be formulated as follo ws: m n t = g W 1 · i n t ( x t ) + W 2 · f n t s n − 1 t + b (4) W 1 , W 2 and b are the internal parameters of M . T wo paths are affine-transformed and added together before going into non- linear function g . Compared with the recursi ve residual net- work proposed in [16], our model has two differences. First, the model in [16] can only recurse with homogeneous input and output. Second, a global shortcut path is always added with the output of the prior recursion in [16] but our model allows to fle xibly combine two heterogeneous inputs. Simple addition is a special case of Eq. 4. 𝑥 𝑡 𝐹 𝐿 𝑙 𝑖𝑛𝑖𝑡 𝐼 𝑀 𝑠 𝑡 0 𝑚 𝑡 0 𝑖 𝑡 0 𝑓 𝑡 0 (a) R = 0 𝐿 𝐿 𝑠 𝑡 1 𝐹 𝑀 𝐹 𝑀 𝑚 𝑡 1 𝑖 𝑡 1 𝑓 𝑡 1 𝑥 𝑡 𝑙 𝑖𝑛𝑖𝑡 𝑥 𝑡 𝐼 𝐼 (b) R = 1 𝐿 𝐿 𝐿 𝑠 𝑡 2 𝐹 𝑀 𝐹 𝑀 𝐹 𝑀 𝑚 𝑡 2 𝑖 𝑡 2 𝑓 𝑡 2 𝑥 𝑡 𝑙 𝑖𝑛𝑖𝑡 𝑥 𝑡 𝑥 𝑡 𝐼 𝐼 𝐼 (c) R = 2 Fig. 2 . Unrolling of a Recursi ve Network: R is the number of recursions. (a), (b) and (c) sho w ho w a recursive network is unrolled in the depth direction. The blocks with the same color share the same weights. Figure 3 shows how the Bridgenet concept is applied to the recursive network of Figure 2. It has four components: CNN layers ( I ), first LSTM layers ( F ), second LSTM lay- ers ( L ) and dimension reduction layer ( M ). Since feedback phone states and acoustic input don’ t ha ve correlations in fre- quency and time directions, they cannot be fed into the same CNN layers. Instead, feedback phones are separately pro- cessed in F controlled by a gate netw ork, g f b n . Its formulation is referred from [17], g f b n = σ w x x t + w s s n − 1 t + w h h n t − 1 (5) where s n − 1 t is a feedback state from the ( n − 1) th recursion, h n t is an the output of F at the n th recursion and w x , w s and w h are weights to be learned. T wo input paths are combined later at the dimension reduction layer . The dimension reduc- tion layer is a fully-connected one to merge them and reduce their dimensions for the second LSTM block, L . A residual LSTM [18] is used for F and L sub-blocks. It has a shortcut path between layers to avoid v anishing or exploding gradients commonly happening to deep networks. It was shown that residual LSTM outperforms plain LSTM for deep networks. 9x9 CNN Layer Max Pooling Layer 3x1 CNN Layer Dimension Reduction Residual LSTM Layer Residual LSTM Layer Residual LSTM Layer SoftMax Residual LSTM 𝑠 𝑡 , 𝑛 − 1 𝑔 𝑛 𝑓𝑏 𝑥 𝑡 Residual LSTM 𝑠 𝑡 𝑛 𝑥 𝑡 Knowledge Bridge: DR Knowledge Bridge:LSTM3 Knowledge Bridge: KD ℎ 𝑡 𝑛 𝐹 𝐼 𝑀 𝐿 Merge Fig. 3 . CNN-LSTM recursive network: knowledge bridges are added at the last recursion. 3. EXPERIMENTS 3.1. Experimental Setup AMI corpus [19] provides 100 hours meeting con versations recorded both by individual headset microphones (IHM) and single distant microphones (SDM). IHM data is cleanly recorded but SDM has high noise and other speaker’ s inter - ferences. SDM can be improved by beamforming multiple SDM channels, which becomes MDM data. Since IHM, SDM and MDM corpora are synchronously recorded, an alignment label generated by one corpus type can be used to train a network with any other corpus. BridgeNet is trained with a clean alignment from IHM. Kaldi [20] and Microsoft Cognitive T oolkit (CNTK) [21] are used to train and decode BridgeNet. Log filterbank am- plitudes with 80 dimensions are generated as feature vectors. They are stack ed as 9 frames to be fed into BridgeNet. Resid- ual LSTMs in BridgeNet has 1024 memory cells and 512 hidden nodes. The final softmax output has 3902 context- dependent phone classes. T wo CNN layers has 9x9 and 3x1 kernels with 256 feature maps, respecti vely . Since SDM or MDM corpus is a meeting con versation between multiple speakers, we pro vide two types of word er- ror rates (WER): all-speakers and main-speaker WERs. The all-speakers WER is to decode up to 4 concurrent speeches, which is a big challenge considering training procedure only focuses on a main speaker . The main-speaker WER is to de- code single main speaker at each time frame, which is more T able 1 . Multi-T ask Denoising on SDM: CNN-LSTM ∗ was trained with a clean alignment from IHM. Other models used a noisy alignment from SDM Acoustic Model WER (all) WER (main) DNN 59.1% 50.5% DNN, denoised 58.7% 50.2% CNN-LSTM 50.4% 41.6% CNN-LSTM, denoised 50.1% 41.4% CNN-LSTM ∗ 46.5% 37.7% CNN-LSTM ∗ , denoised 46.9% 38.2% realistic performance measure for SDM or MDM corpus. W e provides both WERs in the later e v aluations. 3.2. BridgeNet and Multi-T ask Denoising on AMI T able1 provides WER e valuation of multi-task denoising on SDM corpus. Multi-task denoising sho ws only 0.7% and 0.6% main-speaker WER reduction on DNN and CNN- LSTM, which is contrary to the bigger improvement observed in [7]. The trained DNN has 8 layers and each layer has 2048 neurons except bottleneck layers, which is the same as the model in [7]. The main difference is that our DNN model showed significantly lower WERs. It is conjectured that the gain from multi-task denoising decreases for better acoustic model. Next, CNN-LSTM is trained with a clean alignment from IHM corpus. The main-speaker WER of CNN-LSTM got improv ed more than 9% simply changing alignment labels. Howe ver , multi-task denoising on the improv ed CNN- LSTM degraded WER from 37.8% to 38.2%. T able 2 presented BridgeNet WER results on SDM cor- pus. A CNN-LSTM is a baseline network. KD, DR and LSTM3 are knowledge bridges shown in Figure 3. KD in T able 2 means a BridgeNet with only kno wledge distillation connection. Lik ewise, KD+DR and KD+DR+LSTM3 im- ply BridgeNets with corresponding knowledge bridges. Brid- geNets with R0 have no recursion both for student and teacher networks. For BridgeNets with R1, a student network has one recursion but a teacher network has two recursions, where knowledge bridges were only added to the last recursion. BridgeNet on the non-recursive network, R0, with KD, DR and LSTM3 sho wed 6.9% and 1.6% relativ e WER reduc- tion o ver CNN-LSTM and BridgeNet with KD, respecti vely . These results showed Knowledge bridges at the intermedi- ate layers further improved a student network by guiding student’ s feature representations. For R1, KD+DR+LSTM3 showed 3.7% relati ve WER reduction over KD+DR+LSTM3 without recursion. Compared with CNN-LSTM and KD, KD+DR+LSTM3 with R1 provided 10.34% and 5.04% im- prov ements, respectively . The recursiv e architecture signifi- cantly boosted the performance of a student network. T able 2 . BridgeNet: A teacher network is trained with IHM data and a student network is trained with SDM data. Rn means the network has n recursions. (e.g. baseline CNN- LSTM with R2 has two recursions) Acoustic Model WER (all) WER (main) CNN-LSTM (baseline), R0 46.5% 37.7% KD, R0 44.8% 35.7% KD+DR, R0 44.1% 35.3% KD+DR+LSTM3, R0 44.0% 35.1% CNN-LSTM, R2 45.8% 36.9% KD, R1 43.7% 34.7% KD+DR, R1 43.4% 34.7% KD+DR+LSTM3, R1 42.6% 33.8% T able 3 . BridgeNet: A teacher network is trained with clean IHM data and a student network is trained with MDM data. Acoustic Model WER (all) WER (main) CNN-LSTM (Baseline), R0 43.4% 34.0% KD, R0 42.8% 33.1% KD+DR, R0 42.3% 32.5% KD+DR+LSTM3, R0 41.8% 32.2% CNN-LSTM, R2 43.0% 33.3% KD, R1 40.4% 30.8% KD+DR, R1 39.5% 29.9% KD+DR+LSTM3, R1 39.3% 29.5% T able 3 presented BridgeNet WER results on MDM data. MDM data was formed by beamforming 8 channel SDM data using BeamformIt [22]. A student network is trained with beamformed MDM training data and also ev aluated with beamformed ev aluation data. Similar to the SDM re- sults, BridgeNet provides significant improvements. For R0, KD+DR+LSTM3 sho wed 5.29% and 2.72% relative WER reduction ov er CNN-LSTM and KD. W ith recursions, its gain increased as 13.24% and 10.88% compared with the baseline and KD. 4. CONCLUSION This paper proposes a nov el student-teacher transfer learn- ing, BridgeNet. BridgeNet introduces knowledge bridges that can provide a student network with enhanced feature representations at different abstraction lev els. BridgeNet is also based on the proposed recursive architecture, which en- ables to iterativ ely improve signal denoising and recognition. The experimental results confirmed training with multiple knowledge bridges and recursive architectures significantly improv ed distant speech recognition. 5. REFERENCES [1] Michael Brandstein and Darren W ard, Microphone ar- rays: signal pr ocessing techniques and applications , Springer Science & Business Media, 2013. [2] Shoji Makino, T e-W on Lee, and Hiroshi Sawada, Blind speech separation , vol. 615, Springer, 2007. [3] Jongseo Sohn, Nam Soo Kim, and W onyong Sung, “ A statistical model-based voice acti vity detection, ” IEEE signal pr ocessing letters , v ol. 6, no. 1, pp. 1–3, 1999. [4] Javier Ramırez, Jos ´ e C Segura, Carmen Benıtez, An- gel De La T orre, and Antonio Rubio, “Ef ficient voice activity detection algorithms using long-term speech in- formation, ” Speech communication , vol. 42, no. 3, pp. 271–287, 2004. [5] Douglas A Re ynolds, Thomas F Quatieri, and Robert B Dunn, “Speaker verification using adapted Gaussian mixture models, ” Digital signal pr ocessing , v ol. 10, no. 1-3, pp. 19–41, 2000. [6] Daniel Garcia-Romero and Carol Y Espy-W ilson, “ Analysis of i-vector length normalization in speaker recognition systems., ” in Interspeec h , 2011, vol. 2011, pp. 249–252. [7] Y anmin Qian, T ian T an, and Dong Y u, “ An in vestigation into using parallel data for f ar-field speech recognition, ” in Acoustics, Speech and Signal Processing (ICASSP), 2016 IEEE International Conference on . IEEE, 2016, pp. 5725–5729. [8] Mirco Ra vanelli, Philemon Brakel, Maurizio Omologo, and Y oshua Bengio, “Batch-normalized joint training for DNN-based distant speech recognition, ” in Spo- ken Langua ge T echnology W orkshop (SL T), 2016 IEEE . IEEE, 2016, pp. 28–34. [9] Mirco Ra vanelli, Philemon Brakel, Maurizio Omologo, and Y oshua Bengio, “ A network of deep neural net- works for distant speech recognition, ” arXiv preprint arXiv:1703.08002 , 2017. [10] Geoffrey Hinton, Oriol V in yals, and Jef f Dean, “Distill- ing the kno wledge in a neural network, ” arXiv preprint arXiv:1503.02531 , 2015. [11] Adriana Romero, Nicolas Ballas, Samira Ebrahimi Ka- hou, Antoine Chassang, Carlo Gatta, and Y oshua Ben- gio, “Fitnets: Hints for thin deep nets, ” arXiv pr eprint arXiv:1412.6550 , 2014. [12] David Lopez-Paz, L ´ eon Bottou, Bernhard Sch ¨ olkopf, and Vladimir V apnik, “Unifying distillation and pri v- ileged information, ” arXiv pr eprint arXiv:1511.03643 , 2015. [13] Konstantin Markov and T omok o Matsui, “Robust speech recognition using generalized distillation frame- work, ” Interspeech 2016 , pp. 2364–2368, 2016. [14] Shinji W atanabe, T akaaki Hori, Jonathan Le Roux, and John Hershey , “Student-teacher network learning with enhanced features, ” ICASSP’17 , pp. 5275–5279, 2017. [15] Y aser S Abu-Mostafa, “ A method for learning from hints, ” in Advances in Neural Information Processing Systems , 1993, pp. 73–80. [16] Y ing T ai, Jian Y ang, and Xiaoming Liu, “Image super- resolution via deep recursiv e residual network, ” in IEEE Confer ence on Computer V ision and P attern Recogni- tion (CVPR) W orkshops . IEEE, 2017. [17] Junyoung Chung, Caglar Gulcehre, K yunghyun Cho, and Y oshua Bengio, “Gated feedback recurrent neu- ral networks, ” in International Conference on Machine Learning , 2015, pp. 2067–2075. [18] Jaeyoung Kim, Mostafa El-Khamy , and Jungwon Lee, “Residual LSTM: Design of a deep recurrent architec- ture for distant speech recognition, ” in Interspeech , 2017. [19] Jean Carletta, Simone Ashby , Sebastien Bourban, Mike Flynn, Mael Guillemot, Thomas Hain, Jarosla v Kadlec, V asilis Karaiskos, W essel Kraaij, Melissa Kronen- thal, et al., “The AMI meeting corpus: A pre- announcement, ” in International W orkshop on Machine Learning for Multimodal Interaction . Springer , 2005, pp. 28–39. [20] Daniel Pov ey , Arnab Ghoshal, Gilles Boulianne, Lukas Burget, Ondrej Glembek, Nagendra Goel, Mirko Han- nemann, Petr Motlicek, Y anmin Qian, Petr Schwarz, Jan Silovsk y , Geor g Stemmer , and Karel V esely , “The Kaldi speech recognition toolkit, ” in IEEE 2011 W orkshop on Automatic Speech Recognition and Understanding . Dec. 2011, IEEE Signal Processing Society , IEEE Catalog No.: CFP11SR W -USB. [21] Dong Y u, Adam Eversole, Mike Seltzer, Kaisheng Y ao, Zhiheng Huang, Brian Guenter , Oleksii Kuchaiev , Y u Zhang, Frank Seide, Huaming W ang, et al., “ An introduction to computational networks and the compu- tational network toolkit, ” T ech. Rep., T echnical report, T ech. Rep. MSR, Microsoft Research, 2014, 2014. re- search. microsoft. com/apps/pubs, 2014. [22] Xavier Anguera, Chuck W ooters, and Javier Hernando, “ Acoustic beamforming for speak er diarization of meet- ings, ” IEEE T ransactions on Audio, Speech, and Lan- guage Processing , v ol. 15, no. 7, pp. 2011–2022, 2007.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment