선형 회귀 기반 스피커 검증 백엔드와 다양한 프론트엔드 결합 연구
본 논문은 스피커 검증의 백엔드로 선형 회귀(LR) 모델을 도입하고, 이를 GMM‑i‑vector, DNN‑i‑vector, d‑vector 등 세 가지 프론트엔드와 결합한다. LR은 발화별 정답 인디케이터 벡터를 목표로 최소 제곱 오차를 최소화하는 폐쇄형 해를 제공하며, 학습된 변환 행렬을 통해 얻은 스피커 모델을 코사인 유사도 점수기로 비교한다. NIST 2006·2008 SRE 데이터셋에서 WCCN, LDA, PLDA와 비교했을 때 모든 …
저자: Xiao-Lei Zhang
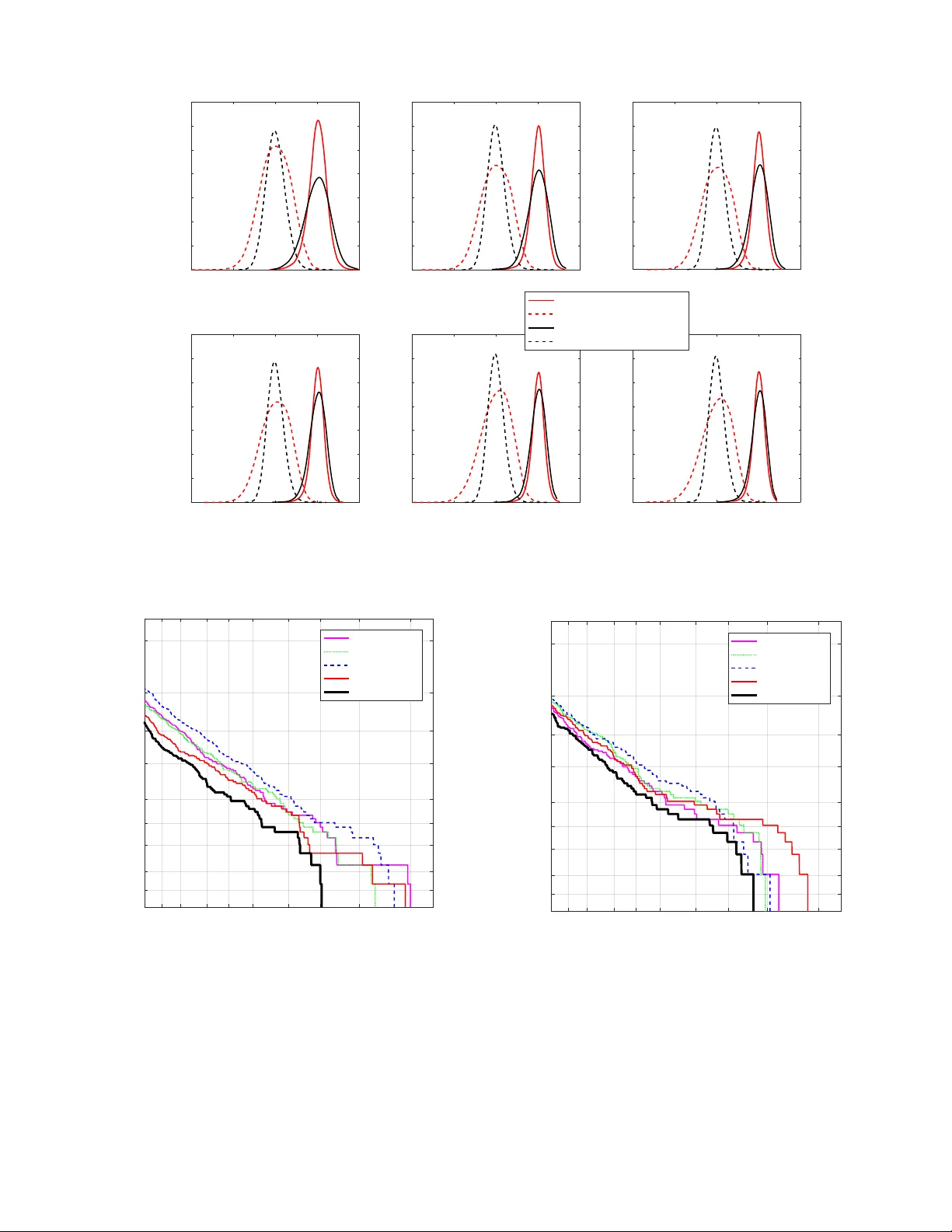
본 논문은 스피커 검증 시스템의 백엔드에 선형 회귀(LR) 모델을 도입하고, 이를 기존의 세 가지 주요 프론트엔드와 결합하여 성능을 평가한다. 서론에서는 텍스트‑독립 스피커 검증의 일반적인 구조를 소개하고, 프론트엔드로는 GMM‑i‑vector, DNN‑i‑vector, d‑vector가 널리 사용됨을 언급한다. 기존 백엔드인 WCCN, LDA, PLDA는 각각 공분산 정규화, 클래스 간 분산 최대화, 확률적 LDA 기반의 스코어링을 사용하지만, 복잡한 파라미터 추정과 학습 비용이 존재한다.
제2장에서는 LR 기반 백엔드의 수학적 정의를 제시한다. 학습 데이터는 프론트엔드가 추출한 특성 벡터 x와 해당 발화의 스피커 라벨을 원‑핫 인코딩한 y로 구성된다. 선형 회귀식 y = Aᵀx + ε에서 A는 (F×S) 크기의 가중치 행렬이며, 최소 제곱 오차를 최소화하면 A = (XXᵀ)⁻¹XYᵀ라는 폐쇄형 해를 얻는다. 학습이 끝난 후, 새로운 발화는 ˆy = Aᵀx 로 변환되고, 동일 스피커의 여러 ˆy를 평균해 스피커 모델 m을 만든다. 두 스피커 모델 간 유사도는 코사인 스코어(score = (m₁·m₂)/‖m₁‖‖m₂‖)로 계산되며, 임계값 θ와 비교해 수락/거부를 결정한다.
프론트엔드 설명에서는 GMM‑i‑vector가 UBM과 총 변동성 행렬 T를 이용해 초벡터를 저차원 i‑vector로 압축하는 과정을 상세히 서술한다. DNN‑i‑vector는 ASR용 DNN을 통해 senone posterior를 추정하고, 이를 기반으로 UBM을 재구성해 i‑vector를 생성한다. d‑vector는 DNN의 최상위 은닉층 출력을 평균해 직접 스피커 레벨 임베딩을 만든다. 각 프론트엔드의 구현 세부 사항(UBM 가우시안 수, 총 요인 차원, DNN 구조 및 학습 파라미터 등)도 구체적으로 제시한다.
제3장 실험에서는 NIST 2006·2008 SRE 데이터셋의 8‑conv 조건을 사용한다. 개발 셋은 2006년 데이터를, 평가 셋은 2008년 데이터를 활용한다. 발화는 15 s 단위로 분할하고, 등록 길이를 15 s부터 225 s까지 6가지 조건으로 변형한다. 평가 지표는 EER, DCF08, DCF10이며, 실험은 각 조건을 100번 반복해 평균값을 보고한다.
결과는 LR+코사인 백엔드가 모든 프론트엔드와 모든 등록 길이에서 WCCN+코사인, LDA+코사인, LDA+PLDA보다 낮은 EER과 DCF를 기록함을 보여준다. 특히 짧은 등록(15 s) 상황에서 기존 백엔드가 크게 성능 저하를 보이는 반면, LR 기반 방법은 비교적 안정적인 성능을 유지한다. DET 곡선에서도 LR+코사인이 원점에 가장 가깝게 위치해 전반적인 오류율이 최소임을 확인한다.
논의에서는 LR의 장점인 폐쇄형 해와 파라미터 튜닝 최소화를 강조한다. 또한 원‑핫 목표 벡터 차원이 스피커 수에 비례해 커지는 메모리 부담과, 코사인 스코어만을 사용함으로써 스케일링 정보가 무시되는 점을 한계로 제시한다. 향후 연구 방향으로는 차원 축소 기법과 결합한 효율적 구현, 다중 클래스 로지스틱 회귀나 신경망 기반 비선형 변환을 통한 확장 가능성을 제안한다.
결론적으로, 선형 회귀를 이용한 백엔드는 복잡한 통계적 정규화 없이도 강력한 스피커 구분 능력을 제공하며, 다양한 프론트엔드와의 호환성을 통해 실용적인 스피커 검증 파이프라인을 구축할 수 있음을 입증한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기