대용량 새 소리 데이터 전처리의 확장 가능한 병렬 처리
본 연구는 새 소리 녹음의 전처리 과정을 하나의 파이프라인으로 통합하고, 마스터‑슬레이브 구조와 데이터 병렬화를 이용해 8대 가상 머신(32코어)에서 21.76배 가속을 달성한 시스템을 제안한다. 고주파 차단, MMSE‑STSA 잡음 감소, 강우·매미 검출·제거 등 여러 단계의 순서를 최적화하고, 분할 길이에 따른 처리 시간과 검출 정확도를 실험적으로 분석하였다.
저자: Alex, er Brown, Saurabh Garg
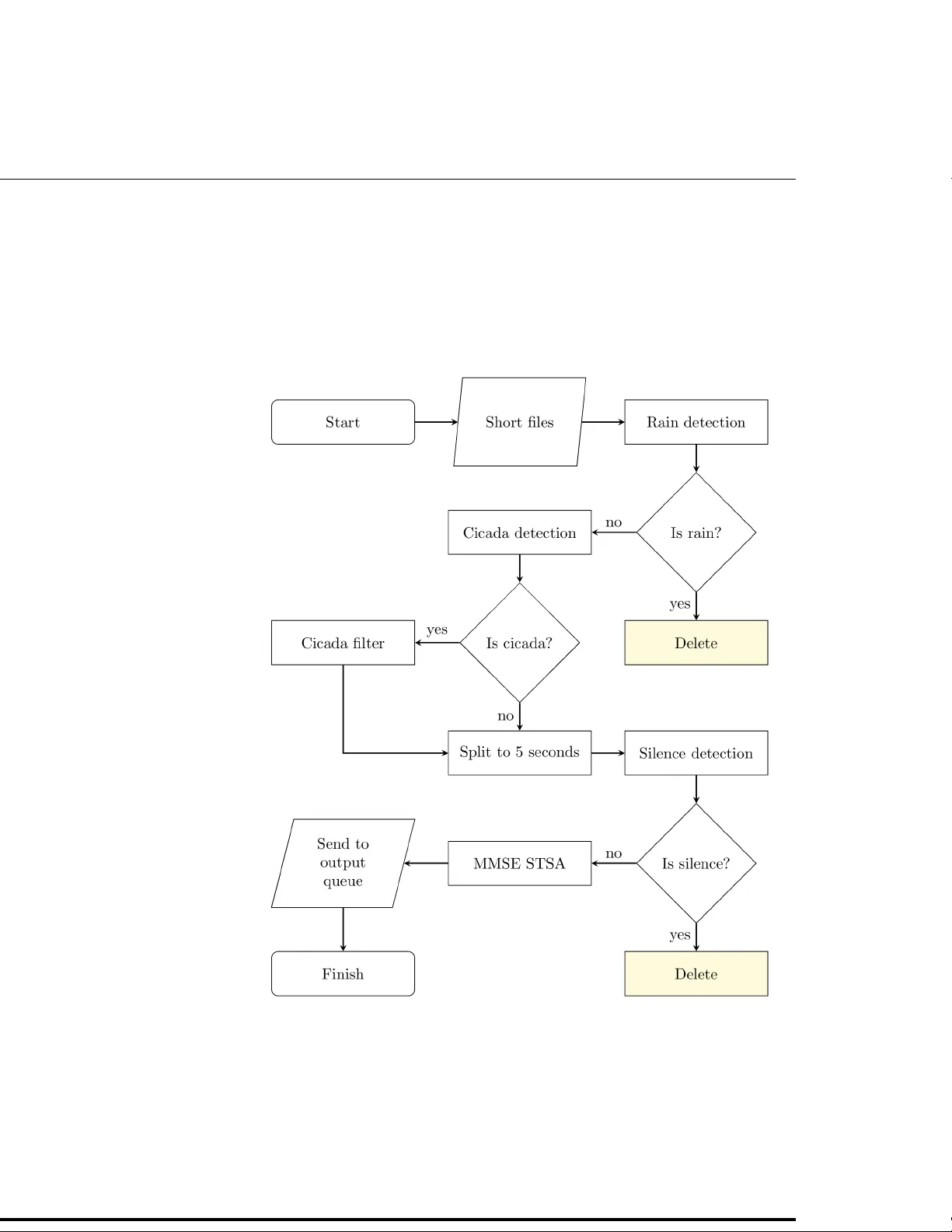
본 논문은 급증하는 생태 음향 데이터의 양을 효율적으로 전처리하기 위한 시스템을 설계·구현하고, 그 성능을 정량적으로 평가한다. 연구 배경으로는 새 소리 녹음이 생태계 모니터링, 이동 경로 추적, 개체 수 추정 등 다양한 연구에 활용되지만, 잡음(배경 소음, 비, 매미 등)으로 인해 분석 정확도가 저하되고, 데이터 양이 방대해 전통적인 수동·반자동 전처리 방식으로는 처리 속도가 한계에 봉착한다는 점을 들었다.
전처리 파이프라인은 다음과 같은 단계로 구성된다. 첫째, 오디오 파일을 일정 길이의 청크로 분할한다. 이는 메모리 사용을 최소화하고, 이후 데이터 병렬화에 필수적인 전처리이다. 둘째, 샘플링 레이트를 22.05 kHz로 다운샘플링하고, 스테레오 채널을 모노로 변환한다. 새 소리의 주요 주파수 대역이 11.025 kHz 이하이므로 정보 손실이 없으며, 파일 크기를 크게 줄일 수 있다. 셋째, 1 kHz 이하 고주파 차단 필터를 적용해 인간 및 환경 소음 등 저주파 성분을 제거한다. 넷째, 정적 배경 잡음을 감소시키기 위해 Minimum Mean Square Error Short Time Spectral Amplitude(MMSE‑STSA) 필터를 적용한다. 이 필터는 잡음 감소 효과가 뛰어나지만 연산 비용이 매우 높다. 다섯째, 256 샘플 윈도우와 50 % 오버랩을 갖는 Hamming 윈도우를 사용해 빠른 푸리에 변환(FFT)을 수행한다. FFT 결과는 이후 강우·매미 검출에 필요한 주파수 기반 지표를 계산하는 데 사용된다.
강우 검출은 C4.5 분류기로부터 도출된 규칙 집합을 적용한다. 여기에는 스펙트럼 기반 신호대잡음비와 전력 스펙트럼 밀도 등이 포함된다. 강우가 검출된 청크는 즉시 삭제하거나 별도 저장해 후속 분석에서 제외한다. 매미 검출 역시 유사한 규칙 기반 접근을 사용하며, 검출된 경우 해당 주파수 대역을 밴드패스 필터링해 매미 소리를 제거한다.
파이프라인 단계의 실행 순서는 실험을 통해 최적화되었다. 고주파 차단과 매미 필터는 청크가 길수록 SoX 라이브러리 호출 횟수가 감소해 실행 시간이 크게 단축된다. 반면 MMSE‑STSA 필터는 청크 길이에 관계없이 높은 연산량을 요구한다. 따라서 전체 파이프라인에서 가장 비용이 큰 단계이므로, 앞선 단계에서 가능한 많은 청크를 삭제하거나 스킵하도록 설계하였다. 특히 강우 검출은 잡음 감소 이전에 수행함으로써, 비가 포함된 청크를 조기에 배제해 MMSE‑STSA 연산을 절감한다.
분산 처리 아키텍처는 마스터‑슬레이브 모델을 채택한다. 마스터 노드는 전체 오디오 파일을 청크 단위로 분할하고, 각 슬레이브에게 작업을 할당한다. 슬레이브는 할당된 청크에 대해 전체 파이프라인을 순차적으로 실행하고, 결과를 마스터에게 반환한다. 데이터 병렬화 방식을 선택한 이유는 청크 간 독립성이 보장되고, 각 청크에 대한 처리 시간이 크게 차이 나지 않아 부하 균형이 용이하기 때문이다. 기능 병렬화는 각 단계의 실행 시간이 상이하고, 일부 단계는 앞 단계 결과에 따라 스킵될 수 있어 구현 복잡도가 높아 배제하였다.
성능 평가에서는 2시간(1.2 GB) 길이의 녹음을 대상으로 5 초에서 30 초까지 다양한 청크 길이에서 각 단계별 평균 실행 시간을 측정하였다. 고주파 차단, 매미 필터, MMSE‑STSA 필터는 청크가 길수록 호출 오버헤드가 감소해 실행 시간이 크게 단축되었으며, 특히 MMSE‑STSA는 청크가 30 초일 때 약 923 초로 가장 빠른 결과를 보였다. 다운샘플링과 FFT는 청크 길이에 크게 민감하지 않았다.
분산 시스템 실험에서는 8대 가상 머신(각 4코어)에서 총 32코어를 활용했으며, 단일 코어 기반 직렬 실행 대비 21.76배의 속도 향상을 달성하였다. 코어 수를 4, 8, 16, 32로 증가시켰을 때 거의 선형에 가까운 가속 비율을 보였으며, 마스터의 작업 분배 오버헤드가 제한적임을 확인하였다. Hadoop이나 Spark와 같은 기존 빅데이터 프레임워크와 비교했을 때, 저수준 데이터 제어와 맞춤형 작업 순서 최적화가 가능함을 강조한다.
결론적으로, 본 연구는 새 소리 데이터 전처리의 전 과정을 하나의 통합 파이프라인으로 구현하고, 마스터‑슬레이브 기반 데이터 병렬화를 통해 대규모 음향 데이터의 처리 시간을 실질적으로 단축시켰다. 향후 연구에서는 실시간 스트리밍 데이터 처리, 클라우드 환경에서의 자동 장애 복구, 그리고 파이프라인에 딥러닝 기반 잡음 감소 모듈을 추가하는 방안을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기