다국어 CTC 기반 음성인식: 음소와 문자 통합 접근
본 논문은 RNN‑CTC 모델을 다국어 환경에 적용하기 위해 전 세계 음소 집합과 문자 집합을 동시에 활용한 시스템을 제안한다. 언어 특징 벡터(LFV)를 추가해 다국어 음소 모델의 성능 격차를 줄였으며, 영어·프랑스어·독일어·터키어 4개 언어에 대해 실험을 수행해 TER와 WER 모두에서 기존 단일언어 대비 개선을 확인하였다.
저자: Markus M"uller, Sebastian St"uker, Alex Waibel
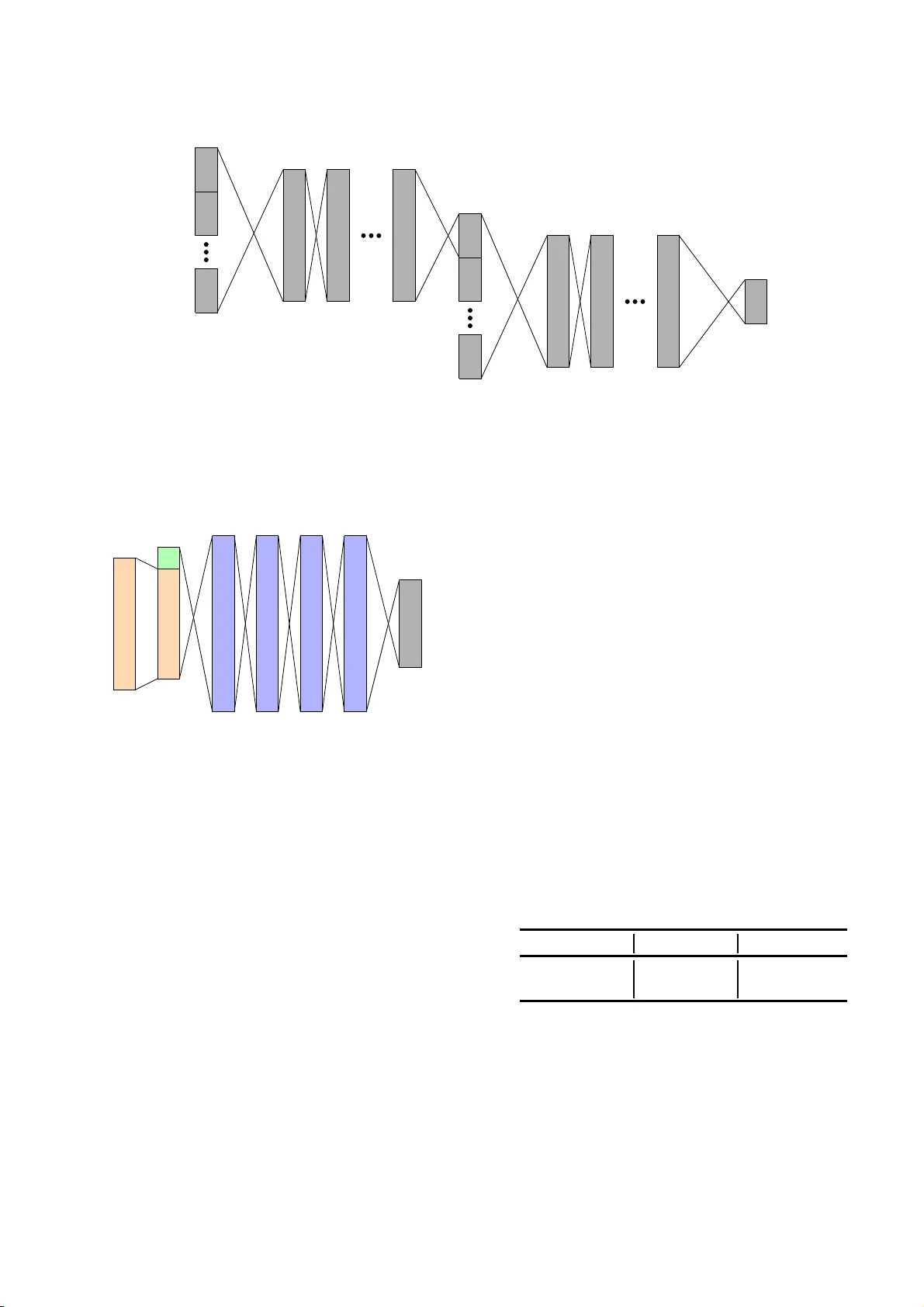
본 연구는 대규모 학습 데이터가 확보되지 않은 언어들을 위한 다국어 자동 음성인식(ASR) 시스템을 설계하고 평가한다. 기존의 GMM/HMM 기반 시스템은 다국어 학습 시 음소 클러스터링 등 복잡한 적응 절차가 필요했지만, RNN‑CTC 모델은 컨텍스트 독립적인 타깃을 사용하므로 다국어 환경에서도 비교적 간단히 적용할 수 있다. 저자들은 이전 연구에서 제안한 단일 추가 언어 기반 음소 CTC 모델을 확장하여, 최대 4개의 언어(영어, 프랑스어, 독일어, 터키어)를 동시에 학습하는 구조를 구축하였다.
시스템은 크게 네 부분으로 구성된다. 첫 번째는 다국어 병목 특징(BNF) 추출 네트워크로, 로그 멜 및 톤 피처를 입력으로 하여 42차원의 병목 레이어를 거쳐 BNF를 생성한다. 이 BNF는 5개 언어(프랑스어, 독일어, 이탈리아어, 러시아어, 터키어)에서 훈련된 DNN/HMM 모델의 6000개 컨텍스트‑의존 음소 상태를 목표로 학습된다. 두 번째는 언어 특징 벡터(LFV) 추출 네트워크이다. BNF를 입력으로 하여 6개의 은닉층(각 1600유닛)과 42유닛 병목을 가진 네트워크를 훈련하고, 긴 시간 컨텍스트(+/-33프레임)에서 언어 식별을 수행한다. 이렇게 얻어진 LFV는 저차원(42)으로, 각 언어의 발음·음운 특성을 압축한다.
세 번째는 실제 CTC 기반 음성인식 네트워크이다. 입력으로는 두 가지 옵션이 있다. (1) 전통적인 로그 멜·톤 피처, (2) 앞서 만든 다국어 BNF. 네트워크 구조는 Baidu DeepSpeech2를 참고해 두 개의 TDNN/CNN 레이어와 그 뒤에 양방향 LSTM 층을 배치했으며, 두 번째 TDNN/CNN 레이어 출력 직후에 LFV를 연결한다. 마지막으로 전결합층을 통해 목표 음소 혹은 문자 시퀀스를 예측한다. 학습은 SGD와 Nesterov 모멘텀(0.9), 학습률 0.0003으로 진행되며, 배치 사이즈 20, 배치 정규화를 적용한다.
실험 데이터는 유로뉴스 코퍼스에서 각 언어당 약 50시간을 추출하고, 화자 기준으로 45시간을 훈련, 5시간을 테스트로 분할하였다. 음소 기반 실험에서는 Mary TTS를 이용해 자동 발음 사전을 생성했으며, 문자 기반 실험에서는 원본 스크립트를 그대로 사용했다. 평가 지표는 토큰 오류율(TER)과 영어에 한정된 단어 오류율(WER)이다.
첫 번째 실험에서는 다국어 BNF를 사용했을 때 로그 멜·톤 대비 영어 TER가 13.0%→10.2%, 독일어 TER가 10.8%→7.8%로 개선됨을 확인했다. 특히 독일어는 BNF 훈련에 포함된 언어이기 때문에 더 큰 이득을 보였다. 두 번째 실험에서는 4개 언어를 동시에 학습한 다국어 음소 모델에 LFV를 추가했을 때, 기본 다국어 모델(TER 9.9%~14.1%) 대비 LFV 적용 모델(TER 8.9%~12.9%)로 전반적인 오류율이 감소하였다. 다국어와 단일언어 모델 간 격차도 LFV 적용으로 약 1~2%p 정도 좁혀졌다.
문자 기반 실험 결과는 논문에 완전히 제시되지 않았지만, 동일한 다국어 설정에서 문자 모델이 음소 모델에 비해 약간 높은 TER을 보였으나, 발음 사전 구축 비용이 없다는 실용적 장점을 강조한다. 또한, 영어에 대해 별도로 훈련한 문자 기반 언어 모델을 이용해 WER을 측정했으며, CTC‑only 모델의 개선이 실제 단어 수준에서도 긍정적인 영향을 미침을 확인했다.
결론적으로, 다국어 BNF와 LFV를 결합한 CTC 기반 ASR 시스템은 기존 다국어 음소 모델 대비 성능 격차를 효과적으로 줄이며, 문자 기반 접근과 비교했을 때도 경쟁력 있는 결과를 보인다. 이는 언어 적응을 위한 저차원 특징(LFV)과 언어 간 공유 표현(BNF)이 다국어 음성인식에서 중요한 역할을 할 수 있음을 시사한다. 향후 연구에서는 더 많은 언어와 방대한 비라벨 데이터에 대한 확장, 그리고 LFV를 이용한 메타‑학습이나 어댑터 모듈 도입을 통해 언어별 특성을 더욱 정교하게 반영하는 방안을 탐색할 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기