Phonemic and Graphemic Multilingual CTC Based Speech Recognition
Training automatic speech recognition (ASR) systems requires large amounts of data in the target language in order to achieve good performance. Whereas large training corpora are readily available for languages like English, there exists a long tail …
Authors: Markus M"uller, Sebastian St"uker, Alex Waibel
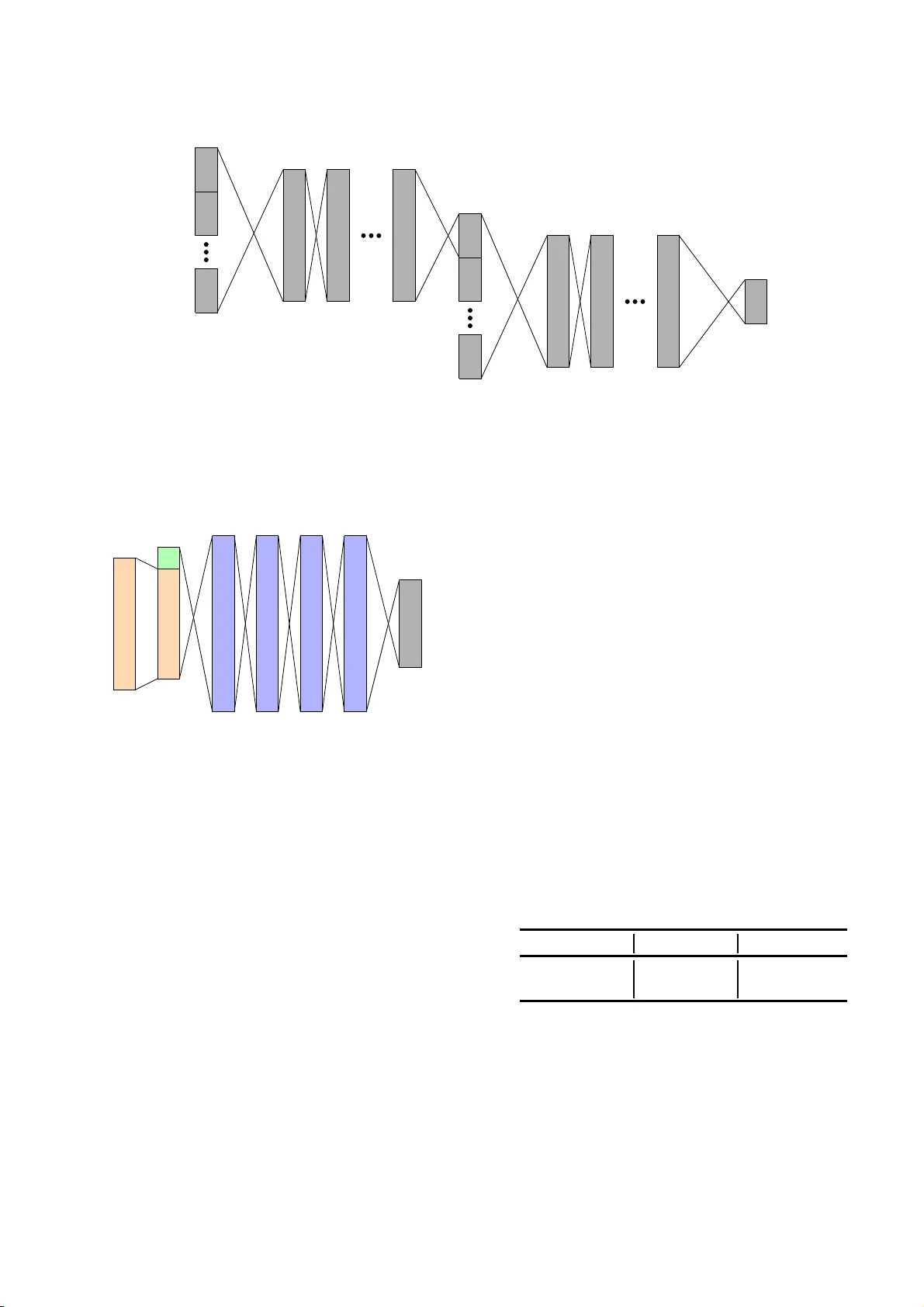
Phonemic and Graphemic Multilingual CTC Based Speech Recognition Markus M ¨ uller 1 , Sebastian St ¨ uker 1 , Alex W aibel 1 , 2 1 Interactiv e Systems Lab, Institute for Ant hropomatics and Robo t ics Karlsruhe Insti tute of T echnology , Karlsruhe, Germany 2 Carnegie Mellon Univ ersity , Pittsbur gh P A, USA m.mueller@kit .edu Abstract T raining automatic speech recognitio n (ASR) systems re- quires large amoun ts o f d ata in the target lan guage in or der to achieve good performance. Whereas large training corpora are readily available for langua g es lik e E n glish, ther e exists a lo ng tail of lan g uages wh ich do suf fer f r om a lack o f r e- sources. One meth od to handle data s parsity i s to use data from additional sour ce lan guages and build a m u ltilingual system. Recently , ASR systems based on recurrent neural networks (RNNs) train ed with co nnection ist tempo ral classi- fication (CTC) have gained su bstantial research interest. In this work, we extended our pr evious ap proach tow ards train- ing CTC-based systems multilingually . Our systems feature a global phone set, based on the jo int phone sets of each source language. W e e valuated the use o f different lang uage combinatio ns as well as the addition of Language Feature V ecto rs (L FVs). As contrasti ve experiment, we built sys- tems based on gr aphemes as well. Systems h aving a mul- tilingual phone set are known to suffer in per forman ce co m- pared to their mono lingual co u nterpar ts. W ith our proposed approa c h , we cou ld redu ce the g ap between these mono - and multilingua l setups, usin g eithe r graphemes or phonemes. 1. Intr oduction Automatic sp eech recogn ition systems h av e matured dramat- ically in recent years, lately with reported recog nition accu- racies similar to th ose of hu m ans on certain tasks [1, 2]. A large amount of carefu lly prepared training data is requir ed to achieve this lev el of perf ormance . While such d a ta is av ail- able for well-researched and -resour ced lan g uages like En- glish, ther e e xists a long ta il of lang uages fo r which such training material does not exist. V ar ious methods ha ve b e en propo sed to handle data sparsity . In this work, we foc u s on multilingua l sy stem s: A c ommon approach is to incorporate data fro m supplementary sourc e lan guages in add ition to data from the target languag e . Lately , systems b ased o n RNNs trained with co nnection - ist tempo ral classification (CTC) [3] h ave be come popu lar . In this work we focu s on building multilingu al RNN/CTC systems, instead of systems based o n either GMM/HMM or DNN/HMM, with th e g oal of applyin g them in a multi- lingual manner and are p la n ning crosslingu al experim ents in the fu ture. For this futu r e crosslingual case, the multilingual RNN a c ts as a network that can be adapted to multiple lan- guages f o r which only very little adaptation data is av ailable. In the multiling ual scenario of this paper, we have one multi- lingual model that is able to re c o gnize speech from multiple languag e s simultane o usly , while for all langu ages a co mpar- ativ ely large am o unt of train ing da ta is available. This is par- ticular useful in en v ironmen ts with fast langua ge ch anges. Recently , we demonstrated the use of a second language in addition to the target language when building a p h oneme based CTC system [4]. W e now extend this appro ach by us- ing data f rom u p to 4 languag e s ( English, Fr e nch, German and T u rkish). Building systems using phones as acoustic modeling unit requires a pronu n ciation dictio n ary . But, cre- ating these dictio naries is a time-consu ming, resource intense process and often a bottle-neck wh en building speech recog- nition systems for new langu ages. While au tomatic meth - ods to create pro nunciation s for new words given an existing dictionary exist [ 5, 6], such appro aches are based o n an ex- isting seed dictionary . Using graphemes as aco ustic mod- eling units, instead has the adv antage of loo sing the need for a pron unciation dictiona r y at the c ost that graphemes might not a lways be a go od mo deling unit, depen ding o n the g raphem e-to-ph oneme r elation of the target lang uage. [7, 8, 9] This is p articularly cha llenging in a mu ltilingual set- ting, because different lan guages, altho ugh they might share the same writing system, d o feature d ifferent pro nunciation rules [10, 11, 12]. This paper is organized as follows: Next, in Section (2), we provide an overvie w of related w ork in the field. In Sec- tion 3, we d escribe our p roposed appro ach, followed by the experimental setu p in Section 4. Th e results are p resented in Section 5 . This p aper con cludes with Section 6, wher e we also provide an ou tlo ok to future work. 2. Related W ork 2.1. Multi- a nd Crosslingual Speech Recog nition Sys- tems Using GMM/HMM based systems was consider ed state of the art p rior to the emergen ce of systems with neural n et- works. Data sparsity has been addressed in th e past, by training systems multi- and crosslingu ally [13, 14]. Meth- ods for crosslingua l adap tation exist [15], but also me thods for adapting the cluster tr e e w e r e pro posed [1 6]. Traditional systems ty p ically use context-dependen t p hones. When trained multi- or crosslingually , the clustering of phon es into context-depe ndent p hones needs to b e adapted [17]. But when using an RNN, the sy stem is trained on context-indep endent targets, so th at in th e mu ltilingual case this kind of ad aptation is un necessary , as the network learn s the context-dep endency du ring train ing. 2.2. Multilingual Bottleneck Features Deep Neur al Network s (DNNs) ar e a data-d riven m ethod with m any param e te r s to be tr ained, failing to gen eralize if train ed on only a limited d a ta set. Different methods have been pr oposed to tr a in networks on d ata from multi- ple so urce lan g uages. Training DNNs ty p ically inv olves a pre-train in g and a fine-tun in g step. I t has been shown, th at the p re-trainin g is langu age indepe ndent [18]. Sev eral ap- proach e s exist to fine- tune a network u sing da ta from mul- tiple lan guages. One method is to share h idden layer s be- tween langua g es, but to use langua g e spec ific o u tput layer s [19, 2 0, 21, 22]. Combining la n guage specific output lay- ers into one layer is also possible [2 3]. By dividing the o ut- put layer in to languag e specific blocks, the setup uses lan - guage dep endent pho ne sets. Training DNNs simultaneou sly on data fro m multiple languages on the other hand can th en be consider ed a form of multi-task le a rning [ 24, 25]. 2.3. Neural Network Adaptation By supplyin g additional input features, neu ral networks can be adap te d to various conditions. One o f the mo st common methods is to adap t n eural nets to different speakers by pro- viding a lo w dimen sional co de representing speaker charac- teristics. The se so called i- V ectors [2 6] allow to train speaker adaptive neu ral n etworks [2 7]. An alternative metho d for adaptation are Bottlen eck Sp eaker V ectors (BSVs) [28]. Similar to BSVs, we proposed an adaptation method for adapting n e ural network s to different lang u ages when trained on multip le langu ages. W e first proposed u sing the lang uage identity info rmation v ia one-ho t enco ding [29]. On e of the shortcomin gs of this approach is that it does not supply lan- guage chara c teristics to th e network. T o address this is- sue, we prop osed Lan guage Feature V ecto rs (LFVs) [ 30, 31] which have shown to enco d e langu age pro perties, even if the LFV net was no t trained on the target langu age. 2.4. CTC Based ASR Systems Recently , RNN-based systems trained u sing the C TC loss function [3] have become popular . Sim ilar to tr a d itional ASR systems, CTC based one s are trained using either p hones, graphe m es, or bo th [3 2]. T rain ing o n units larger than char- acters is a lso possible [33]. This meth o d, called Byte Pair Encodin g (BP E), derives larger units based o n the transcr ip ts. Giv en enou gh train ing data, even training o n whole words is possible [34]. Multi-task learning has also been prop osed [35, 36, 37]. C TC based systems are able to ou tperfor m HMM based setups o n certain tasks [38]. 3. Language Adaptiv e Multilingual CTC Based Systems T raditional speech r e c ognition systems typica lly rely on a pronu nciation diction ary which maps words to p hone se- quences. It is also p ossible to train systems on gra p hemes as acoustic un its, b ut this af fects the perf ormance depen d- ing on th e language. While there are languages with a close mapping betwe e n letters and sounds, e. g ., Spanish, th is d oes not ho ld for every la n guage. Pronunciatio n rules are qu ite complex, with grou ps of charac te r s being m apped to differ - ent sound s b ased on the ir context. An example of such com - plex mapp ings would be English. T he string “oug h” has 8 different acoustic realizations, dep ending on the context, as in, e.g., “rou gh”, “o ught” or “thr ough” . 3.1. Multilingual Systems Speech r ecognition systems are typically built to recogn ize speech of a single lang uage. Training traditional systems multilingua lly inv olves a hyb r id DNN/HMM setup wher e the hidden layers o f the DNN are shar e d between langu ages an d the o utput lay ers ar e kept langu age dep endent. Such sys- tems can be seen as individual, langu a g e depen dent systems, trained jointly . T raining lang uage u niv ersal systems u sing a g lo bal ph ones set is po ssible, however HM M based sy s- tems do not generalize well when being trained on m ulti- ple lan guages. In this work, we pro pose an ap proach using RNN based systems trained u sin g CTC on data fro m multi- ple langua ges, with a glob al set of units modeling the aco us- tics (g rapheme s o r ph ones). The main advantage of such a system is the ab ility to recog nize speech fro m multiple lan- guages simultaneo usly , withou t knowledge o f the input lan - guage’ s identity . In the past, we propo sed a setup for training CTC-based systems multilingu ally using a u niversal ph o ne set [4]. In this work, we extended o ur previous work in three ways: 1) we incre ased the n umber of languages used 2 ) we used mul- tilingually trained bo ttleneck feature s (BNFs) 3) in add ition to ph o nes, we evaluated the u se of gr a phemes. In the past, we demonstrate d the use o f LFVs u sing DNN/HMM-based systems for m u ltilingual speech recognitio n. W e now a pply this techn ique to CTC-based speech recognition. 3.2. Language Feature V ectors LFVs are a low dimension al r epresentation of languag e pro p- erties, extracted using a n eural network. The setup consisted of two networks, Figure 1 shows the n etwork architectur e. The first network was used to extrac t BNFs f rom acoustic input featur es. It was tra in ed using a co mbination o f lMel and tonal featu r es as inpu t and p hone states as targets. The second network was trained for languag e iden tification using BNFs as inp ut features. In co ntrast to network s tr ained for speech r ecognitio n , we used a much larger in put co ntext be- cause o f the languag e infor mation b eing lon g-term in nature . This network was trained to d etect languages and featur e d a bottleneck layer, wh ich was u sed to extract the LFVs af ter training. 3.3. Input Features Using BNFs as input features is c o mmon for tradition al speech recog nition systems. By forc in g th e infor mation to pa ss throu gh a bottleneck, the network creates a low- dimensiona l rep resentation of features relevant to discrim- inate between p hones. D N N/HM M or GMM/HMM based systems benefit from using such features over p lain features like, e. g., MFCCs. W e ev aluated training o ur CTC systems on multiling ual BNFs. 3.4. Network Architecture The network architecture chosen was based o n Baidu’ s Deep- speech2 [3 9]. As shown in Figu re 2, the n etwork consists of two T DNN / CNN lay ers. W e add LFVs to th e output o f the second TDNN / CNN layer as input to th e bi-directional LSTM layers. W e u se a feed- forward outp ut lay er to m ap the output of the last LSTM lay er to the targets. 4. Experimental Setup W e built our systems u sing a fram ew ork based on PyT orch [40], as well as warp-ctc [4 1] fo r computin g the CTC loss during n etwork training. T o extract acoustic featu res from the d ata, we u sed th e Janus Reco gnition T oolkit (JR Tk) [4 2], which features the I BIS single-pass de c oder [43]. 4.1. Dataset W e condu cted ou r experiments using data f rom the E uronews Corpus [ 4 4], a dataset conta in ing recor d ings of TV br oadcast news from 10 different languages (Arab ic, En glish, French , German, Italian, Polish, Portuguese, Russian, Spanish, T urk- ish), w ith orthograph ic tra n scripts at u tterance level. The ad- vantage of this dataset is that the cha nnel con ditions do not differ be tween languages, ensuring that we are adapting our systems to different lan guages instead of different c h annel condition s, like, e.g., different en vironmen tal noises p r esent in dif ferent lang uages. W e filtered the available data, retain- ing on ly utterances with a len gth of at least 1s and a tran script length of at most 639 symb ols, becau se of an intern al limita- tion within CUDA 1 . Noises were anno ta te d in a very basic way , consisting of o nly one generic noise marker covering bo th h uman an d non-h uman no ises. W ith noises accoun ting f or a quite large amount of utteran ces, we only selected a small subset of them to acc ount for a m ore balanced set o f training data. After ap- 1 see: https://g ithub . com/baidu-research/w arp-ctc, accesse d 2017-10-09 plying all filtering steps, app r oximately 50h of data per lan- guage was av ailable. W e split the av ailable d ata o n a spe aker basis into a 4 5h trainin g an d 5 h test set. 4.2. Acoustic Units W e co n ducted experiments usin g both phones and grap hemes as acoustic un its. As gra phemes we used the p rovided tran- scripts, wh ile we used Mary TTS [45] to generate a pronun - ciation dictionary automatically to map words to ph ones. In addition, we inclu ded a marker to ind icate word b ounda ries. 4.3. Input Features As input features, we used log Mel an d tonal featu r es (FFV [46] and pitch [ 47]), extracted using a 32 ms win dow with a 10ms f rame-shift. W e included tonal f eatures as par t of our stan dard p re-pro cessing pip eline because previous exper- iments showed a reductio n in the word erro r rate (WER) o f speech reco gnition sy stem s, ev en if the lan guage is no t tonal [48]. Based on these f e atures, we trained a network f or e x- tracting multiling ual bottlen eck features (BNFs). The net- work featured 5 feed-forward layers, with 1 ,000 neur ons per layer, with the seco nd last layer b eing the bottleneck with only 42 neuro ns. The a coustic fe a tures were fed with a con- text of + / − 6 fram es into the ne twork. Wh ile the hid den layers were shared b etween languag es, we used lang uage d e- penden t outpu t layers. 6,000 context-d ependen t p hone states were used as targets, with data f rom 5 langua ges ( Fr ench, German, Italian, Russian, T urkish) . T o o btain phon e state labels, DNN/HMM systems for each lan guage were trained . After training, all laye r s after the bottleneck were discard ed and the o u tput activ ations of this lay er we r e taken as BNFs. 4.4. LFV Network T raining T raining the n etwork f or the extractio n o f L FVs is a two step process. Fir st, BNFs are b eing traine d (see Section 4 .3), and then based o n these BNFs, a seco nd network is tra ined to recogn ize the lan guage. Th is network featur es 6 laye r s with 1,600 neu rons per layer , except for the bottlenec k layer with only 4 2 neuro ns. I n co ntrast to networks trained fo r speech recogn itio n, this n etwork featu red a large con text spanning + / − 3 3 fr ames. T o reduce the dim ensionality of th e inp ut, only e very th ird f rame was taken. F or training this ne twork, we used data f r om 9 languag es( a ll av ailable languag es in the corpus except English). 4.5. CTC RNN Network T raining The RNN network was traine d using e ith er log M e l / tonal features or BNFs. As targets, we used both grap hemes and p honem e s as acoustic un its, with an ad ditional symb ol added fo r separatin g words. The n etworks were trained u sing stochastic grad ient descent (SGD) with Nesterov momentu m [49] o f 0 .9 and a learning rate of 0 .0003 . Mini-batch upd ates AF stack BNF BNF stack LFV Languag e Feature Network Figure 1: Ov erview o f the network architecture used to extract language feature vectors (LFV). The acou stic features (AF) are being pr e -processed in a DBNF in o rder to extract BNFs. These BNFs are being stacked and f ed into th e second network to extract LFVs. 2D Con volution Layers Bi-directional LSTM Layers Output Layer LFV Figure 2: Network lay o ut, based o n Baidu’ s De e pspeech2 [39]. LFVs are bein g ad d ed after the final co n volution layer . with a batch size o f 20 and batch no rmalization were used. During the first epoch , the n etwork was train ed with utter- ances sorted ascen ding by len gth to stabilize the training, as shorter utterance s are easier to alig n. 4.6. Evaluation T o evaluate our setu p, w e used the same decoding proced ure as in [3] and gree d ily search the best p ath without a n external languag e mo del and ev aluated our system s by computin g the token error ra te (TER) as primary measu r e. I n additio n , we trained a character based neural network lang uage mo del for English on the training utter ances, as de scr ibed in [50], so that f or the recognition of English we could also measure a word error rate (WER) by decod ing the ne twork o utputs with this lang uage mo del. As the langu age mo d el is only trained on only a sma ll a m ount of data, the word erro r rate obtained with it should indicate whether the impr ovements in TER of the pure CTC model measured on English also lead to a be tter w ord level speech r e c ognition system. 5. Results W e first e valuated using multilingual BNFs over plain log Mel / tone features. Next, w e used multilingual BNFs to train systems using a comb ination o f 4 lang uages (English, French, German , T urkish) . 5.1. Multilingual BNFs First, we ev aluated the use of multilingually trained BNFs as input featur es. T o assess the perfor mance, we trained sys- tems for Eng lish and Germ an m onoling ually on all a vailable data. The r esults are sh own in T able 1. The gain by the ad di- tion of BNFs is larger for German wh ich can be explained by German b eing among the lang uages the BNF n et was tra ined on (see Sectio n 4.3). But the BNFs also show an imp r ove- ment for Eng lish, although they did not see this lang uage during training. Condition English TER G erman TER log Mel + T one 13.0% 10.8% ML BNF 10.2% 7.8% T ab le 1: Comparison of using ML-BNFs over log Mel + ton e features 5.2. Multilingual Phoneme Based Systems Next, we ev aluated the perfor mance using 4 language s (E n- glish, Frenc h , German , Turkish). W e ev aluated add ing th e LFVs after the TDNN / CNN lay ers. As baseline , we did not apply o ur langu age a d aptation techniqu e an d used o nly multilingua l BNFs. As shown in T able 2, add ing LFVs after the TDNN / CNN layer sho ws improvements over the base- line. T he relative improvements vary and wh ile the lan guage adapted systems are no t en p ar with the mo nolingu al on es, the adaptation does decrease the gap b etween th e multi- and monolin gual setup. Condition DE EN FR TR Monoling ual 7.8% 10 . 2% 8.3% 7.1% ML 9.9% 14.1% 1 2.8% 8.4 % ML + LFV 8.9% 12.9% 1 0.7% 7.6 % T ab le 2: T erm Error Rate ( TER ) of multiling ual ( ML ) phone m e CTC based sy stems, trained on 4 languages. 5.3. Multilingual Grapheme Based Systems In add ition to u sing pho nes, we also evaluated the perfor- mance using only the transcripts, w ith out a pronu nciation dictionary . As sho wn in T able 3, using LFVs improves the per forman ce in this con dition as well. For Eng lish and French, the TER is higher co mpared to their phon eme coun- terpart, where a s lower TERs could be observed f or both Ger- man and T urk ish. One explanation could be th a t En glish and Fren ch feature m ore com plex pron unciation rules that are b etter reflected by Ma ryTTS’ lan guage definitio ns. The generated pronun ciations fo r German and T urkish appear to worsen the p erforma n ce. The RNN seems to capture the let- ter to sou nd rules for these languages better . Condition DE EN FR TR Monoling ual 7.5% 12 . 9% 11.5 % 6.6% ML 9.1% 15.6% 1 3.4% 7.9 % ML + LFV 7.9% 14.3% 1 2.5% 7.3 % T ab le 3: T erm Er ror Rate (TE R) of multiling ual ( ML ) graphe m e CTC based sy stems, trained on 4 languages. For En glish, we also trained a ba sic ch aracter based lan- guage model to d ecode the network ou tput and compute th e WER. As sho wn in T able 4 , similar improvements can be observed b y adding LFVs. Condition Mono ML ML + LFV English 25.2% 30 .8% 28.1% T ab le 4: W ord Erro r Rate ( WER ) of English ph oneme CTC based systems. Adding LFVs imp roves the mu ltilingual per- forman ce. 6. Conclusion W e have presented an app r oach to ad apt recurren t neur a l net- works to mu ltiple lan guages. Using multiling u al BNFs im - proved the perform ance, as well as providin g LFVs for lan- guage ada p tation. These langu age ad aptive networks are able to capture langu age specific peculiarities in a multilingu a l setup which r esults in an incr eased p e rforman ce. Such mul- tilingual systems are a ble to reco gnize speech from multip le languag e s simultane o usly . Future work includes the use of d ifferent languag e combinatio ns and working towards cross-ling ual k nowledge transfer . W e aim at fu rther closing the gap between m ono- and mu ltilingual systems using ad ditional adaptatio n tech- niques. 7. Refer ences [1] W . Xiong, J. Dro ppo, X. Huang, F . Seide, M. Seltzer, A. Sto lcke, D. Y u , and G. Zweig , “ Achieving Human Parity in Co nversational Speech Recog nition, ” arXiv pr eprint arXiv:161 0.052 56 , 201 6 . [2] ——, “The micro soft 2 016 con versational speech recogn itio n system, ” in Acou stics, S peech and S ignal Pr o cessing (ICASSP), 2 017 IEEE International Con - fer ence on . IEEE, 20 17, p p . 5255 –5259 . [3] A. Graves , S. Fern ´ andez, F . G o mez, and J. Schm idhu- ber, “Connec tionist temporal classification: lab elling unsegmented sequence data with recu rrent neural ne t- works, ” in P r oc eedings of the 23r d inte rnational con- fer ence on Ma chine learning . A CM, 2006 , pp. 369– 376. [4] M. M ¨ uller , S. St ¨ uker , and A. W aibel, “Multilingual ctc speech recogn itio n, ” in SP ECOM , 2017. [5] M. Bisani and H. Ney , “Joint-sequen c e m odels fo r graphe m e-to-ph oneme conversion, ” Speech co mmuni- cation , vol. 50, no. 5, p p. 434–4 51, 2008 . [6] J. R. Novak, D. Y ang , N. Minematsu, and K. Hirose, “Phonetisaur u s: A wfst-driven pho neticizer, ” Th e Uni- versity of T o kyo, T okyo In stitute o f T echn ology , pp . 221– 222, 201 1 . [7] C. Schillo, G. A. Fink, and F . Kumme r t, “Gr apheme based speech recog nition fo r large v ocabularies, ” in Pr o ceedings o f the Six th I nternationa l Conference on Spoken Language P r oc essing (ICSLP 2000) . B eijing, China: I SCA, October 20 0 0, pp . 584– 587. [8] S. Kanth ak and H. Ne y , “Context-depend ent acoustic modeling using graph emes for large vocab ulary speech recogn itio n, ” in P r oc eedings the 2002 IEEE Interna- tional Conference on A coustics, Speech, an d Sig nal Pr o cessing (ICASSP’02 ) , v ol. 1. Orlando, Florida, USA: IEEE, 20 02, pp. 845– 848. [9] M. Killer, S. St ¨ uker , and T . Schultz, “ Grapheme based speech recognition, ” in P r oce edings of the 8th Eu r o - pean Con fer ence on S peech Commun ication and T ech- nology EUR OSPEECH’03 . Genev a, Switzerlan d : ISCA, September 200 3, pp. 3141– 3144 . [10] S. Kanthak an d H. Ney , “Multilingual acoustic model- ing u sin g graphem s, ” in Pr oceedin gs of th e 8 th Eur o- pean Con fer ence on S peech Commun ication and T ech- nology EUR OSPEECH’03 . Genev a, Switzerlan d : ISCA, September 200 3, pp. 1145– 1148 . [11] S. St ¨ uker , “Mod ified polyph one decision tree spec ia l- ization for po rting multilingual graph eme based asr sy s- tems to new lan g uages, ” in Pr oceedin gs of the 2008 IEEE In ternationa l Conference o n Acou stics, Spe ech, and Sign al Pr ocessing . Las V egas, NV , USA: IEEE, April 200 8, pp. 4249–425 2. [12] ——, “In tegrating thai grap heme based aco ustic mod- els into th e ml-m ix f ramework - fo r langu a g e in de- penden t and cross-languag e asr , ” in Pr oce edings o f the F irst International W orkshop on Spoken Languages T echnologies for Under -r esour ced lan guages (S L TU) , Hanoi, V ietnam , May 2008. [13] B. Wheatley , K. K on do, W . Ander son, and Y . Muth usamy , “ An evaluation of c r oss-languag e adaptation fo r rapid hmm development in a new languag e , ” in Acoustics, Sp eech, a nd Sig nal Pr o- cessing, 19 94. ICAS SP-94 ., 1994 IEEE Interna tional Confer ence on , vol. 1 . IEEE, 199 4, pp. I–237 . [14] T . Schu ltz and A. W aibel, “Fast boo tstrap ping of lvcsr system s with multilingu al phon eme sets. ” in Eu - r osp eech , 19 97. [15] S. St ¨ uker , “ Acoustic mode llin g fo r und er-resourced lan- guages, ” Ph.D. dissertation, Karlsruhe, Univ ., Diss., 2009, 2009 . [16] T . Schultz and A. W aibel, “ L anguag e-indepe n dent and languag e -adaptive acou stic m o deling f or speech recog - nition, ” Sp eech Communication , vol. 35 , no. 1, pp. 31– 51, 2001 . [17] ——, “Polyp hone decision tree specialization for lan- guage ad a p tation, ” in Acou stics, Speech, a nd Sig - nal Pr ocessing, 2 000. ICASSP’ 00. Pr oceedin gs. 200 0 IEEE Interna tional Conference on , vol. 3. IEEE, 2 000, pp. 1707 – 1710 . [18] P . Swietojanski, A. Ghoshal, and S. Renals, “Unsuper- vised cross-lingu al k nowledge transfer in DNN- based L VCSR, ” in SLT , IEEE. IEEE, 20 12, pp. 24 6–25 1. [19] A. Gh oshal, P . Swietojanski, an d S. Ren als, “Multilin - gual training of Deep -Neural networks, ” in Pr oceeding s of the ICASSP , V a n couver, Canada, 20 13. [20] S. Scanzio , P . Laface, L. Fissore, R. Gem ello, an d F . Man a, “On the use of a mu ltilingual neural network front-e n d, ” in Pr oceeding s of the Interspeech , 2008 , pp. 2711– 2714 . [21] G. Heigold, V . V anh oucke, A. Senior, P . Nguyen, M. Ranzato, M. Devin, and J. Dean, “Multilingual Acoustic Models Using Distributed Deep Neural Net- works, ” in Pr oceed ings of the ICASSP , V an couver, Canada, May 201 3. [22] K. V esely , M. Karafiat, F . Grezl, M. Janda, and E. Ego rova, “The lang uage-ind epende n t bo ttleneck fea- tures, ” in Pr o ceedings of th e Spoken Lang uage T ech- nology W o rkshop (SLT), 2012 IEEE . I EEE, 2012, pp . 336–3 41. [23] F . Gr ´ ez l, M. Karafi ´ at, and K. V e sely , “ Adaptatio n o f multilingua l stacked b ottle-neck neural network struc- ture fo r new lang uage, ” in Acou stics, Sp eech and Signa l Pr o cessing (ICASSP), 2 014 IEEE International Con - fer ence on . IEEE, 20 14, p p . 7654 –7658 . [24] R. Caru ana, “Multitask learning, ” Machine learnin g , vol. 28 , n o. 1, pp . 4 1–75, 1997. [25] A. Mohan and R. Rose, “Mu lti-lingual speech recog - nition with low-rank multi-task deep neur al networks, ” in Acoustics, Spee ch and Sig nal Pr ocessing (ICAS SP), 2015 IEEE Interna tional Conference on . I EEE, 20 15, pp. 4994 – 4998 . [26] G. Saon, H. Soltau, D. Naha m oo, and M. Picheny , “Speaker Adap tation of Neu ral Ne twork Acoustic Models Using i-V ectors, ” in AS R U . IEEE, 20 1 3, pp . 55–59 . [27] Y . Miao , H. Zhang, and F . M e tz e , “T owards Speaker Adaptive Training o f D e e p Neural Netw ork Acou stic Models, ” 2014 . [28] H. H u ang and K. C. Sim, “An Investigation o f Aug- menting Speaker Repre sentations to Improve Speaker Normalisation fo r DNN-b ased Speech Recognition , ” in ICASSP . IEEE, 20 15, pp. 4610 –4613 . [29] M. M ¨ uller and A. W aibel, “U sin g Lan g uage Ad ap- ti ve Deep Neural Networks f or Imp roved Mu ltilingual Speech Recognition , ” IWS L T , 201 5 . [30] M. M ¨ uller, S. St ¨ uker , and A. W aibel, “Language Adap - ti ve DNNs fo r Impr oved Low Resour ce Speech Recog- nition, ” in Interspeech , 2016. [31] ——, “L a nguage Feature V ector s for Resou rce Con- straint Spee ch Recognitio n, ” in S peech Communica- tion; 1 2. ITG Symp osium; Pr oceedin gs of . VDE, 2016. [32] D. Chen, B. Mak, C.-C. Leu ng, an d S. Sivadas, “Joint acou stic modeling of tr iphones and trig r aphemes by multi-task lea rning deep n e u ral networks for low- resource speech recognition, ” in Aco ustics, Speech and Signal Pr o cessing (ICASS P), 2014 IEEE I nternationa l Confer ence on . IEEE, 201 4, pp. 5592– 5596 . [33] R. Sennrich, B. Had dow , and A. Birch , “Neural ma- chine translation of ra r e words with subword units, ” arXiv pr eprint arXiv:1508 .0790 9 , 2015 . [34] H. Soltau, H. Liao, an d H. Sak, “Ne u ral speech recogn ize r: Acoustic-to -word lstm model for lar ge vocab ulary speech recognition , ” arXiv pr eprint arXiv:161 0.099 75 , 201 6. [35] S. Kim, T . Hori, and S. W atanabe, “Join t ctc-atten tion based end-to -end sp e e ch r ecognitio n using multi-task learning, ” arXiv preprint arXiv:160 9.067 73 , 201 6. [36] L. Lu, L. Kong, C. Dyer, and N. A. Smith, “Multi-task learning with ctc and segmental crf fo r speech recog ni- tion, ” arXiv preprint arXiv:170 2.063 78 , 201 7. [37] H. Sak and K. Rao, “Mu lti-accent spe e ch recogn itio n with hierarch ical gr apheme based mod els, ” 20 17. [38] Y . M ia o , M. Gowayyed, X. Na, T . Ko, F . Metze, and A. W aibel, “ An empir ical exploration o f ctc acous- tic mod e ls, ” in Ac oustics, Sp eech and Signal Pr ocess- ing (ICASSP ), 201 6 IEEE Interna tional Con fer ence o n . IEEE, 2016 , p p . 2 623–2 627. [39] D. Am odei, S. Anantha n arayana n , R. Anubh a i, J. Bai, E. Battenberg, C. Case, J. Casper, B. Catanza ro, Q. Cheng, G. Ch e n , et al. , “Deep speech 2: End-to -end speech reco gnition in eng lish and mandar in, ” in Inter- nationa l Conference o n Machine Learning , 2 016, pp . 173–1 82. [40] “PyT orch , ” http://pytorc h.org, ac c e ssed: 201 7-04 - 13. [41] “warp-ctc , ” https://github.com/baidu- r esearch/warp- ctc, accessed: 2017-0 4-13. [42] M. W . et al., “J ANUS 93 : T owards Spon taneous Speech T ranslation, ” in Interna tional Confer ence on Acoustics, Speech, and Signa l Pr ocessing 19 94 , Adelaide, Aus- tralia, 1994 . [43] H. Soltau, F . Metze, C. Fugen, and A. W aibe l, “A One-Pass Decod er Based on Poly morph ic Linguistic Context Assignment, ” in Automatic Speech Recogni- tion a nd Understanding, 2001. ASR U’01. IEEE W ork- shop on . IEEE, 200 1, pp. 214– 2 17. [44] R. Gretter, “Euronews: A Multilingual Benchmark for ASR and LID, ” in F ifteenth Annu al Con fer ence of the Internation al Speech Com munication A ssociation , 2014. [45] M. Schr ¨ oder a n d J. Trouvain, “The German text-to- speech syn th esis system MAR Y : A tool for research, development and teaching, ” Internatio nal Journal o f Speech T echnology , vol. 6, no. 4, pp . 365– 377, 200 3. [46] K. Laskowski, M. Heldner, and J. Edlun d, “The Fun- damental Frequen cy V ar iation Sp ectrum, ” in Pr oceed- ings of the 21st Swedish Phon etics Confer ence (F onetik 2008) , Gothen burg, Sweden, June 2 008, pp. 29– 32. [47] K. Sch ubert, “Grund frequen zverfolgung und d eren An- wendun g in der Sprach erkennun g , ” M aster’ s th esis, Universit ¨ at Karlsruhe (TH), Germany , 1999, in Ger- man. [48] F . Metze, Z. Sheikh, A. W aibel, J. Gehr ing, K. Kil- gour, Q. B. Nguyen , V . H. Nguy en, et a l. , “Mo dels of T on e for T onal and Non- tonal Languages, ” in Auto- matic S peech Recognition and Understanding (ASR U), 2013 IEEE W orkshop on . IEEE, 2013, pp. 261 –266 . [49] I. Sutskev er, J. Mar tens, G. Dahl, a n d G. H in ton, “On the impor tance of in itialization and mom entum in deep learning, ” in Pr oceedin gs of th e 3 0th In ternationa l Confer ence on Machine Learn ing (ICML-13 ) , 2013, pp. 1139 – 1147 . [50] T . Zenkel, R. Sanab r ia, F . Metze, J. Niehues, M. Sper- ber, S. St ¨ uker , and A. W aibel, “Comparison of decod- ing strategies f or ctc acou stic mo dels, ” arXiv pr eprint arXiv:170 8.044 69 , 201 7.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment