스톡캐스틱 평균화로 구현하는 실시간 자원 할당 최적화
본 논문은 데이터센터 네트워크의 자원 배분 문제를 라그랑주 승수를 학습하는 기계학습 과제로 재구성하고, 오프라인 SAGA 기반의 최적화와 온라인 ‘learn‑and‑adapt’ SAGA를 제안한다. 제안 기법은 선형 수렴률과 저복잡도 업데이트를 제공하면서도 큐 안정성을 보장해 기존의 stochastic dual gradient 방식보다 지연‑수렴 트레이드오프를 크게 개선한다.
저자: Tianyi Chen, Aryan Mokhtari, Xin Wang
1. 서론에서는 클라우드 데이터센터와 스마트그리드가 결합된 현대 네트워크가 에너지 가격·재생에너지 가용성 등 고도의 불확실성을 내포하고 있음을 강조한다. 기존의 stochastic network optimization 기법은 dual decomposition을 활용하지만, 수렴 속도가 느리고 지연이 크게 발생한다는 문제점을 지적한다.
2. 네트워크 모델링에서는 매핑 노드(MN)와 데이터센터(DC) 간의 워크로드 흐름을 정의하고, 큐 동역학(식 1‑4)과 비용 함수(식 5)를 제시한다. 목표는 장기 평균 비용을 최소화하면서 큐 안정성(식 6d)을 보장하는 것이다.
3. 문제 재구성 단계에서는 시간‑결합 제약을 평균 제약(식 7)으로 변환하고, 이를 라그랑주 승수 λ에 대한 이중 문제(식 12)로 전환한다. 라그랑주 승수는 네트워크 자원의 가격·가용성을 나타내는 ‘가격’ 역할을 하며, 최적 정책은 λ*에 의해 완전히 결정된다(정리 1).
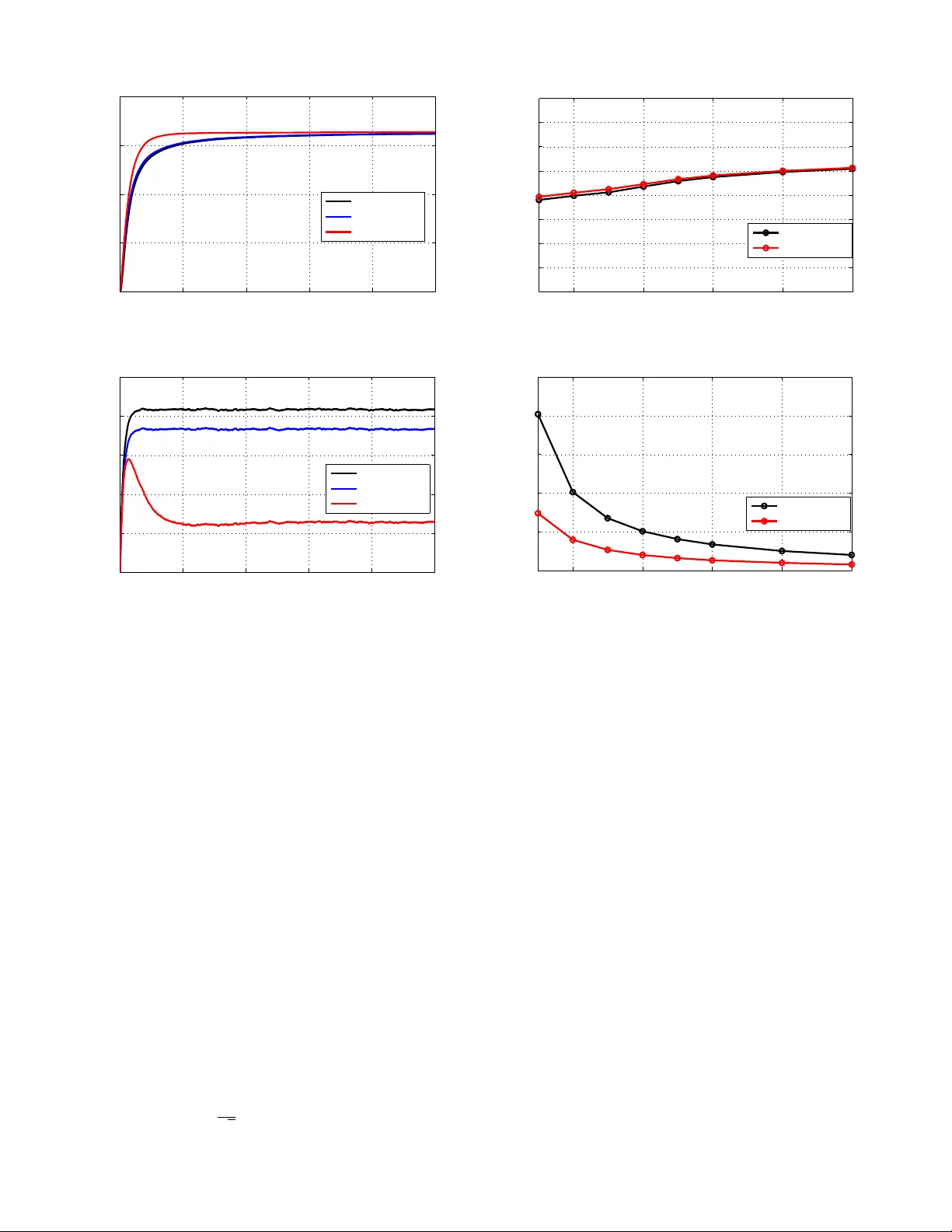
4. 오프라인 학습에서는 경험적 이중 문제를 ERM 형태로 보고, SAGA 알고리즘을 변형해 적용한다. 변형 SAGA는 각 샘플에 대한 그라디언트를 저장하고, 전체 평균 그라디언트를 보정함으로써 무편향 추정량을 유지한다. 이 방법은 배치 그라디언트와 동일한 선형 수렴률을 보이며, 메모리 요구량은 O(N·d) (N: 샘플 수, d: 변수 차원)이다.
5. 온라인 ‘learn‑and‑adapt’ SAGA는 실시간 스트리밍 데이터에 대해 두 단계 업데이트를 수행한다. 첫 단계는 오프라인 SAGA에서 얻은 λ̂ₜ를 현재 샘플에 맞게 보정하고, 두 번째 단계는 현재 큐 길이 qₜ를 이용해 λₜ = λ̂ₜ + μ·qₜ 형태로 조정한다. 여기서 μ는 스텝 사이즈이며, 큐 안정성을 위한 Lyapunov 분석을 통해 μ·qₜ 항이 큐 길이를 제어함을 증명한다.
6. 수렴 및 성능 분석(섹션 V)에서는 (a) 오프라인 SAGA가 O(ρⁿ) 선형 수렴을, (b) 온라인 SAGA가 기대 비용에서 O(μ) 차이와 평균 큐 길이 O((1/√μ)·log²(1/μ))를 달성함을 정리한다. 이는 기존 SDG가 제공하는 O(1/μ) 지연에 비해 현저히 개선된 결과이다. 또한, 알고리즘의 복잡도는 매 슬롯당 O(d)이며, 메모리 요구는 오프라인 단계와 동일하게 유지된다.
7. 실험 섹션에서는 10개의 MN과 5개의 DC를 갖는 시뮬레이션 환경을 구축하고, 에너지 가격·재생에너지 가용성을 실제 시장 데이터를 사용해 모델링한다. 결과는 (i) 오프라인 SAGA가 배치 그라디언트와 동등한 수렴 속도를 보이며, (ii) 온라인 SAGA가 SDG 대비 평균 지연을 3배 이상 감소시키고, 전력 비용을 12% 절감함을 보여준다. 또한, 다양한 μ 값에 대해 비용‑지연 트레이드오프가 이론적 예측과 일치함을 확인한다.
8. 결론에서는 라그랑주 승수 학습을 통한 데이터‑드리븐 네트워크 최적화 프레임워크의 장점을 요약하고, 향후 비정상 환경, 다중 목표 최적화, 분산 구현 등에 대한 연구 방향을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기