Stochastic Averaging for Constrained Optimization with Application to Online Resource Allocation
Existing approaches to resource allocation for nowadays stochastic networks are challenged to meet fast convergence and tolerable delay requirements. The present paper leverages online learning advances to facilitate stochastic resource allocation ta…
Authors: Tianyi Chen, Aryan Mokhtari, Xin Wang
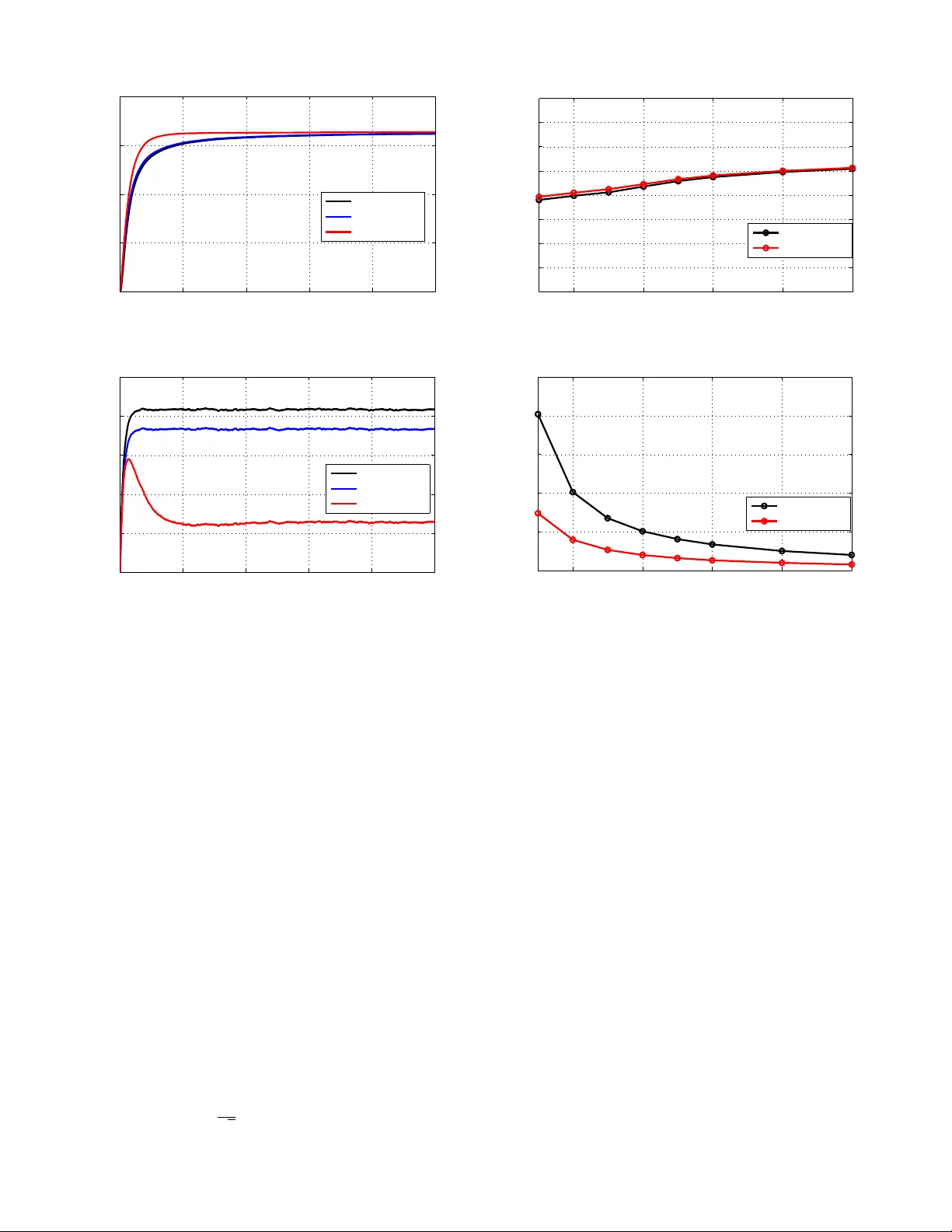
1 Stochastic A v eraging for Constrained Optimization with Application to Online Resource Allocation T ianyi Chen, Aryan Mokhtari, Xin W ang, Alejandro Ribeiro, and Georgios B. Giannakis Abstract —Existing resour ce allocation approaches for nowadays stochastic networks are challenged to meet fast con vergence and tolerable delay r equirements. The pr esent paper le verages online learning advances to facilitate online resour ce allocation tasks. By recognizing the central role of Lagrange multipliers, the underlying constrained optimization problem is f ormulated as a machine learning task in volving both training and operational modes, with the goal of lear ning the sought multipliers in a fast and efficient manner . T o this end, an order-optimal offline learning approach is developed first for batch training, and it is then generalized to the online setting with a pr ocedure termed learn-and-adapt. The novel resource allocation protocol permeates benefits of stochastic approximation and statistical learning to obtain low-complexity online updates with learning errors close to the statistical accuracy limits, while still preserving adaptation performance, which in the stochastic network optimization context guarantees queue stability . Analysis and simulated tests demonstrate that the proposed data- driven approach impro ves the delay and con vergence perf ormance of existing resour ce allocation schemes. Index T erms —Stochastic optimization, statistical learning, stochastic approximation, netw ork r esource allocation. I . I N T RO D U C T I O N Contemporary cloud data centers (DCs) are proliferating to provide major Internet services such as video distribution, and data backup [2]. T o fulfill the goal of reducing electricity cost and improving sustainability , adv anced smart grid features are now adays adopted by cloud networks [3]. Due to their inher- ent stochasticity , these features challenge the overall network design, and particularly the network’ s resource allocation task. Recent approaches on this topic mitigate the spatio-temporal uncertainty associated with ener gy prices and renew able av ail- ability [4]–[8]. Interestingly , the resultant algorithms reconfirm the critical role of the dual decomposition framework, and its renewed popularity for optimizing modern stochastic networks. Howe ver , slow con vergence and the associated network delay of existing resource allocation schemes hav e recently motiv ated W ork in this paper was supported by NSF 1509040, 1508993, 1423316, 1514056, 1500713, 1509005, 0952867 and ONR N00014-12-1-0997; National Natural Science Foundation of China grant 61671154. Part of the results in this paper were presented at IEEE Global Conference on Signal Information Processing, W ashington, DC, USA, December 7-9, 2016 [1]. T . Chen and G. B. Giannakis are with the Department of Electrical and Com- puter Engineering and the Digital T echnology Center, University of Minnesota, Minneapolis, MN 55455 USA. Emails: { chen3827, georgios } @umn.edu A. Mokhtari and A. Ribeiro are with the Department of Electrical and Systems Engineering, Univ ersity of Pennsylvania, Philadelphia, P A 19104 USA. Emails: { aryanm, aribeiro } @seas.upenn.edu X. W ang is with the Ke y Laboratory for Information Science of Elec- tromagnetic W aves (MoE), the Department of Communication Science and Engineering, Fudan University , Shanghai, China, and also with the Department of Computer and Electrical Engineering and Computer Science, Florida Atlantic Univ ersity , Boca Raton, FL 33431 USA. Email: xwang11@fudan.edu.cn improv ed first- and second-order optimization algorithms [9]– [12]. Y et, historical data have not been exploited to mitigate future uncertainty . This is the k ey nov elty of the present paper , which permeates benefits of statistical learning to stochastic resource allocation tasks. T argeting this goal, a critical observ ation is that renowned network optimization algorithms (e.g., back-pressure and max- weight) are intimately linked with Lagrange’ s dual theory , where the associated multipliers admit pertinent price interpre- tations [13]–[15]. W e contend that learning these multipliers can benefit significantly from historical relationships and trends present in massiv e datasets [16]. In this context, we re visit the stochastic network optimization problem from a machine learning v antage point, with the goal of learning the Lagrange multipliers in a fast and efficient manner . W orks in this direction include [17] and [18], but the methods there are more suitable for problems with two featur es : 1) the network states belong to a distribution with finite support; and, 2) the feasible set is discrete with a finite number of actions. W ithout these two features, the in volv ed learning procedure may become intractable, and the advantageous performance guarantee may not hold. Overall, online resource allocation capitalizing on data-driven learning schemes remains a largely uncharted territory . Motiv ated by recent advances in machine learning, we sys- tematically formulate the resource allocation problem as an online task with batch training and operational learning-and- adapting phases. In the batch training phase, we vie w the empirical dual problem of maximizing the sum of finite concave functions, as an empirical risk maximization (ERM) task, which is well-studied in machine learning [16]. Le veraging our specific ERM problem structure, we modify the recently de veloped stochastic average gradient approach (SAGA) to fit our train- ing setup. SA GA belongs to the class of fast incremental gradient (a.k.a. stochastic variance reduction) methods [19], which combine the merits of both stochastic gradient, and batch gradient methods. In the resource allocation setup, our offline SA GA yields empirical Lagrange multipliers with order-optimal linear con vergence rate as batch gradient approach, and per- iteration complexity as lo w as stochastic gradient approach. Broadening the static learning setup in [19] and [20], we further introduce a dynamic resource allocation approach (that we term online SA GA) that operates in a learn-and-adapt fashion. Online SAGA fuses the benefits of stochastic approximation and statistical learning: In the learning mode, it preserves the simplicity of offline SA GA to dynamically learn from streaming data thus lowering the training error; while it also adapts by incorporating attributes of the well-appreciated stochastic dual (sub)gradient approach (SDG) [4]–[7], [21], in order to track 2 queue v ariations and thus guarantee long-term queue stability . In a nutshell, the main contrib utions of this paper can be summarized as follows. c1) Using stochastic network management as a motiv ating application domain, we take a fresh look at dual solvers of constrained optimization problems as machine learning iterations in volving training and operational phases. c2) During the training phase, we considerably broaden SA GA to efficiently compute Lagrange multiplier iterates at order -optimal linear con vergence, and computational cost comparable to the stochastic gradient approach. c3) In the operational phase, our online SAGA learns-and- adapts at low complexity from streaming data. For allo- cating stochastic network resources, this leads to a cost- delay tradeoff [ µ, (1 / √ µ )log 2 ( µ )] with high probability , which mark edly improv es SDG’ s [ µ, 1 /µ ] tradeof f [21]. Outline . The rest of the paper is organized as follows. The system models are described in Section II. The motiv ating resource allocation setup is formulated in Section III. Section IV deals with our learn-and-adapt dual solvers for constrained optimization. Con ver gence analysis of the nov el online SA GA is carried out in Section V. Numerical tests are provided in Section VI, followed by concluding remarks in Section VII. Notation . E ( P ) denotes e xpectation (probability); 1 denotes the all-one vector; and k x k denotes the ` 2 -norm of vector x . Inequalities for v ectors x > 0 , are defined entry wise; [ a ] + := max { a, 0 } ; and ( · ) > stands for transposition. O ( µ ) denotes big order of µ , i.e., O ( µ ) /µ → 1 as µ → 0 ; and o ( µ ) denotes small order of µ , i.e., o ( µ ) /µ → 0 as µ → 0 . I I . N E T W O R K M O D E L I N G P R E L I M I N A R I E S This section focuses on resource allocation ov er a sustainable DC network with J := { 1 , 2 , . . . , J } mapping nodes (MNs), and I := { 1 , 2 , . . . , I } DCs. MNs here can be authoritativ e DNS servers as used by Akamai and most content deliv ery networks, or HTTP ingress proxies as used by Google and Y ahoo! [22], which collect user requests over a geographical area (e.g., a city or a state), and then forward workloads to one or more DCs distributed across a lar ge area (e.g., a country). Notice though, that the algorithms and their performance analysis in Sections V and IV can be applied to general resource allocation tasks, such as ener gy management in po wer systems [23], cross-layer rate-power allocation in communication links [24], and traffic control in transportation netw orks [25]. Network constraints . Suppose that interactiv e workloads are allocated as in e.g., [22], and only delay-tolerant workloads that are deferrable are to be scheduled across slots. T ypical examples include system updates and data backup, which provide ample optimization opportunities for workload allocation based on the dynamic variation of energy prices, and the random av ailability of rene wable energy sources. Suppose that the time is indexed in discrete slots t , and let T := { 0 , 1 , . . . } denote an infinite time horizon. W ith reference to Fig. 1, let v j,t denote the amount of delay-tolerant w orkload arriving at MN j in slot t , and ˜ x j,t := [ ˜ x 1 ,j,t , . . . , ˜ x I ,j,t ] > the I × 1 vector collecting the w orkloads routed from MN j to all DCs in slot t . With the fraction of unserved workload b uffered MN 1 MN J DC 1 DC I Ă Ă Fig. 1. Diagram depicting components and variables of the MN-DC network. in corresponding queues, the queue length at each mapping node j at the beginning of slot t , obeys the recursion q mn j,t +1 = h q mn j,t + v j,t − P i ∈I j ˜ x i,j,t i + , ∀ j, t (1) where I j denotes the set of DCs that MN j is connected to. At the DC side, x i,t denotes the workload processed by DC i during slot t . Unserved portions of the workloads are buf fered at DC queues, whose length obeys (cf. (1)) q dc i,t +1 = h q dc i,t − x i,t + P j ∈J i ˜ x i,j,t i + , ∀ i, t (2) where q dc i,t is the queue length in DC i at the beginning of slot t , and J i denotes the set of MNs that DC i is linked with. The per-slot workload is bounded by the capacity D i for each DC i ; that is, 0 ≤ x i,t ≤ D i , ∀ i, t. (3) Since the MN-to-DC link has bounded bandwidth B i,j , it holds that 0 ≤ ˜ x i,j,t ≤ B i,j , ∀ i, j, t. (4) If MN j and DC i are not connected, then B i,j = 0 . Operation costs . W e will use the strictly con ve x function G d i,j ( · ) to denote the cost for distributing workloads from MN j to DC i , which depends on the distance between them. Let P r i,t denote the ener gy provided at the beginning of slot t by the rene wable generator at DC i , which is constrained to lie in [0 , P r i ] . The power consumption P dc i by DC i is taken to be a quadratic function of the demand [6]; that is P dc i ( x i,t ) = e i,t x 2 i,t , where e i,t is a time-varying parameter capturing en vironmental factors, such as humidity and temper - ature [8]. The energy transaction cost is modeled as a linear function of the power imbalance amount | P dc i ( x i,t ) − P r i,t | to capture the cost in real time power balancing; that is, G e i,t ( x i,t ) := α i,t e i,t x 2 i,t − P r i,t , where α i,t is the buy/sell price in the local power wholesale market. 1 Clearly , each DC should buy energy from external energy markets in slot t at price α i,t if P dc i ( x i,t ) − P r i,t > 0 , or , sell energy to the markets with the same price, if P dc i ( x i,t ) − P r i,t < 0 . The aggr egate cost for the considered MN-DC network per slot t is a con vex function, gi ven by Ψ t ( { x i,t } , { ˜ x j,t } ) := X i ∈I G e i,t ( x i,t ) + X i ∈I X j ∈J G d i,j ˜ x j,t . (5) When (5) is assumed under specific operating conditions, our analysis applies to general smooth and strong-con ve x costs. 1 When the prices of buying and selling are not the same, the transaction cost is a piece-wise linear function of the power imbalance amount as in [6]. 3 Building on (1)-(5), the next section will deal with allocation of resources { x i,t , ˜ x j,t } per slot t . The goal will be to minimize the long-term average cost, subject to operational constraints. I I I . M OT I V A T I N G A P P L I C A T I O N : R E S O U R C E A L L O C A T I O N For notational brevity , collect all random v ariables at time t in the (2 I + J ) × 1 state vector s t := { α i,t , e i,t , P r i,t , v j,t , ∀ i, j } ; the optimization variables in the ( I J + I ) × 1 vec- tor x t := [ ˜ x > 1 ,t , . . . , ˜ x > J,t , x 1 ,t , . . . , x I ,t ] > and let q t := { q mn j,t , q dc i,t , ∀ i, j } ∈ R I + J . Considering the scheduled x i,t as the outgoing amount of workload from DC i , define the ( I + J ) × ( I J + I ) “node-incidence” matrix with ( i, e ) entry giv en by A ( i,e ) := 1 , if link e enters node i − 1 , if link e leav es node i 0 , else. W e assume that each ro w of A has at least one − 1 entry , and each column of A has at most one − 1 entry , meaning that each node has at least one outgoing link, and each link has at most one source node. Further, collect the instantaneous workloads across MNs in the zero-padded ( I + J ) × 1 vector c t := [ v 1 ,t , . . . , v J,t , 0 , . . . , 0] > , as well as the link and DC capacities in the ( I + J ) × 1 vector ¯ x := [ B 1 , 1 , . . . , B i,j , D 1 , . . . , D I ] > . Hence, the sought scheduling is the solution of the following long-term netw ork-optimization problem Ψ ∗ := min { x t , ∀ t } lim T →∞ 1 T T X t =1 E [Ψ t ( x t )] (6a) s. t. 0 ≤ x t ≤ ¯ x , ∀ t (6b) q t +1 = [ q t + Ax t + c t ] + , ∀ t (6c) lim T →∞ 1 T P T t =1 E [ q t ] < ∞ (6d) where (6b) and (6c) come from concatenating (3)-(4) and (1)- (2), while (6d) ensures strong queue stability as in [21, Defini- tion 2.7]. The objecti ve in (6a) considers the entire time horizon, and the expectation is o ver all sources of randomness, namely the random vector s t , and the randomness of the v ariables x t and q t induced by the sample path of s 1 , s 2 , . . . , s t . For the problem (6), the queue dynamics in (6c) couple the optimization variables x t ov er the infinite time horizon. For practical cases where the kno wledge of s t is causal, finding the optimal solution is generally intractable. Our approach to circumventing this obstacle is to replace (6c) with limiting a verage constraints, and employ dual decomposition to separate the solution across time, as elaborated next. A. Pr oblem r eformulation Substituting (6c) into (6d), we will ar gue that the long-term aggregate (endogenous plus e xogenous) workload must satisfy the follo wing necessary condition lim T →∞ 1 T T X t =1 E [ Ax t + c t ] ≤ 0 . (7) Indeed, (6c) implies q t +1 ≥ q t + Ax t + c t that after summing ov er t = 1 , . . . , T and taking expectations yields E [ q T +1 ] ≥ E [ q 1 ]+ P T t =1 E [ Ax t + c t ] . Since both q 1 and q T +1 are bounded under (6d), dividing both sides by T and taking T → ∞ , yields (7). Using (7), we can write a relax ed version of (6) as ˜ Ψ ∗ := min { x t , ∀ t } lim T →∞ 1 T T X t =1 E [Ψ t ( x t )] s.t. (6b) and (7) . (8) Compared to (6), the queue v ariables q t are not present in (8), while the time-coupling constraints (6c) and (6d) are replaced with (7). As (8) is a relaxed version of (6), it follows that ˜ Ψ ∗ ≤ Ψ ∗ . Hence, if one solves (8) instead of (6), it will be prudent to deriv e an optimality bound on Ψ ∗ , provided that the schedule obtained by solving (8) is feasible for (6). In addition, using arguments similar to those in [21] and [5], it can be shown that if the random process { s t } is stationary , there exists a stationary control policy χ ( · ) , which is only a function of the current s t ; it satisfies (6b) almost surely; and guarantees that E [Ψ t ( χ ( s t ))] = ˜ Ψ ∗ , and E [ A χ ( s t ) + c t ( s t )] ≤ 0 . This implies that the infinite time horizon problem (8) is equiv alent to the following per slot con vex program ˜ Ψ ∗ := min χ ( · ) E Ψ χ ( s t ); s t (9a) s.t. E [ A χ ( s t ) + c t ( s t )] ≤ 0 (9b) χ ( s t ) ∈ X := { 0 ≤ χ ( s t ) ≤ ¯ x } , ∀ s t (9c) where we interchangeably used χ ( s t ) := x t and Ψ( x t ; s t ) := Ψ t ( x t ) , to emphasize the dependence of the real-time cost Ψ t and decision x t on the random state s t . Note that the optimization in (9) is w .r .t. the stationary policy χ ( · ) . Hence, there is an infinite number of variables in the primal domain. Observe though, that there is a finite number of constraints coupling the realizations (cf. (9b)). Thus, the dual problem contains a finite number of variables, hinting that the problem is perhaps tractable in the dual space [12], [24]. Furthermore, we will demonstrate in Section V that after a careful algorithmic design in Section IV , our online solution for the relaxed problem (9) is also feasible for (6). B. Lagr ange dual and optimal solutions Let λ := [ λ mn 1 , . . . , λ mn J , λ dc 1 , . . . , λ dc I ] > denote the ( I + J ) × 1 Lagrange multiplier vector associated with constraints (9b). Upon defining x := { x t , ∀ t } , the partial Lagrangian function of (8) is L ( x , λ ) := E L t ( x t , λ ) , where the instantaneous Lagrangian is given by L t ( x t , λ ) :=Ψ t ( x t ) + λ > ( Ax t + c t ) . (10) Considering X as the feasible set specified by the instantaneous constraints in (9c), which are not dualized in (10), the dual function D ( λ ) can be written as D ( λ ) := min { x t ∈X , ∀ t } L ( x , λ ) := E h min x t ∈X L t ( x t , λ ) i . (11) Correspondingly , the dual problem of (8) is max λ ≥ 0 D ( λ ) := E [ D t ( λ )] (12) where D t ( λ ) := min x t ∈X L t ( x t , λ ) . W e henceforth refer to (12) as the ensemble dual problem. Note that similar to Ψ t , here D t and L t are both parameterized by s t . 4 If the optimal Lagrange multipliers λ ∗ were known, a suf- ficient condition for the optimal solution of (8) or (9) would be to minimize the Lagrangian L ( x , λ ∗ ) or its instantaneous versions {L t ( x t , λ ∗ ) } over the set X [26, Proposition 3.3.4]. Specifically , as formalized in the ensuing proposition, the op- timal routing { ˜ x ∗ j,t , ∀ j } and workload { x ∗ i,t , ∀ i } schedules in this MN-DC network can be e xpressed as a function of λ ∗ associated with (9b), and the realization of the random state s t . Proposition 1. Consider the strictly con vex costs ∇ G d i,j and ∇ G e i,t in (5) . Given the realization s t in (9) , and the Lagrange multipliers λ ∗ associated with (9b) , the optimal instantaneous workload r outing decisions are ˜ x ∗ i,j,t ( s t ) = ( ∇ G d i,j ) − 1 ( λ mn j ) ∗ − ( λ dc i ) ∗ B i,j 0 (13a) and the optimal instantaneous workload scheduling decisions ar e given by [with G e i ( x t ; s t ) := G e i,t ( x t ) ] x ∗ i,t ( s t ) = ∇ G e i ( s t ) − 1 ( λ dc i ) ∗ D i 0 (13b) wher e ( ∇ G d i,j ) − 1 and ∇ G e i ( s t ) − 1 denote the in verse func- tions of ∇ G d i,j and ∇ G e i,t , r espectively . W e omit the proof of Proposition 1, which can be easily deriv ed using the KKT conditions for constrained optimization [26]. Building on Proposition 1, it is interesting to observe that the stationary policy we are looking for in Section III-A is expressible uniquely in terms of λ ∗ . The intuition behind this solution is that the Lagrange multipliers act as interfaces between MN-DC and workload-po wer balance, capturing the av ailability of resources and utility information which is relev ant from a resource allocation point of view . Howe ver , to implement the optimal resource allocation in (13), the optimal multipliers λ ∗ must be known. T o this end, we first outline the celebrated stochastic approximation-based and corresponding L yapunov approaches to stochastic network optimization. Subsequently , we dev elop a no vel approach in Section IV to learn the optimal multipliers in both of fline and online settings. C. Stochastic dual (sub-)gradient ascent For the ensemble dual problem (12), a standard (sub)gradient iteration in volv es taking the expectation over the distribution of s t to compute the gradient [24]. This is challenging because the underlying distribution of s t is usually unknown in prac- tice. Even if the joint probability distribution functions were av ailable, finding the expectations can be non-trivial especially in high-dimensional settings ( I 1 and/or J 1 ). T o circumv ent this challenge, a popular solution relies on stochastic approximation [6], [21], [27]. The resultant stochastic dual gradient (SDG) iterations can be written as (cf. (12)) ˇ λ t +1 = ˇ λ t + µ ∇D t ( ˇ λ t ) + (14) where the stochastic (instantaneous) gradient ∇D t ( ˇ λ t ) = Ax t + c t is an unbiased estimator of the ensemble gradient giv en by E [ ∇D t ( ˇ λ t )] . The primal variables x t can be found by solving “on-the-fly” the instantaneous problems, one per slot t x t ∈ arg min x t ∈X L t ( x t , ˇ λ t ) (15) where the operator ∈ accounts for cases that the Lagrangian has multiplier minimizers. The minimization in (15) is not difficult to solve. For a number of relev ant costs and utility functions in Proposition 1, closed-form solutions are av ailable for the primal variables. Note from (14) that the iterate ˇ λ t +1 depends only on the probability distribution of s t through the stochastic gradient ∇D t ( ˇ λ t ) . Consequently , the process { ˇ λ t } is Markov with transition probability that is time inv ariant since s t is stationary . In the conte xt of L yapunov optimization [5], [13] and [21], the Markovian iteration { ˇ λ t } in (14) is interpreted as a virtual queue recursion; i.e., ˇ λ t = µ q t . Thanks to their lo w complexity and ability to cope with non- stationary scenarios, SDG-based approaches are widely used in v arious research disciplines; e.g., adaptiv e signal processing [28], stochastic network optimization [13], [17], [21], [29], and energy management in po wer grids [5], [23]. Unfortunately , SDG iterates are known to con verge slo wly . Although simple, SDG does not exploit the often sizable number of historical samples. These considerations motiv ate a systematic design of an offline-aided-online approach, which can significantly im- prov e online performance of SDG for constrained optimization, and can ha ve major impact in e.g., network resource allocation tasks by utilizing streaming big data, while preserving its lo w complexity and fast adaptation. I V . L E A R N - A N D - A D A P T R E S O U R C E A L L O C AT I O N Before developing such a promising approach that we view as learn-and-adapt SDG scheme, we list our assumptions that are satisfied in typical network resource allocation problems. (as1) State pr ocess { s t } is independent and identically dis- tributed (i.i.d.), and the common probability density function (pdf) has bounded support. (as2) The cost Ψ t ( x t ) in (5) is non-decreasing w .r .t. x t ∈ X := { 0 ≤ x t ≤ ¯ x } ; it is a σ -str ongly conve x function 2 ; and its gradient is Lipschitz continuous with constant ˜ L for all t . (as3) Ther e exists a stationary policy χ ( · ) satisfying 0 ≤ χ ( s t ) ≤ ¯ x , for all s t , and E [ A χ ( s t ) + c t ( s t )] ≤ − ζ , where ζ > 0 is the slack constant ; and (as4) The instantaneous dual function D t ( λ ) in (12) is - str ongly concave, and its gradient ∇D t ( λ ) is L -Lipschitz con- tinuous with condition number κ = L/ , for all t . Although (as1) can be relaxed if ergodicity holds, it is typically adopted by stochastic resource allocation schemes for simplicity in exposition [13], [17], [30]. Under (as2), the objectiv e function is non-decreasing and strongly conv ex, which is satisfied in practice with quadratic/e xponential utility or cost functions [30]. The so-called Slater’ s condition in (as3) ensures the existence of a bounded Lagrange multiplier [26], which is necessary for the queue stability of (6); see e.g., [17], [31]. If (as3) cannot be satisfied, one should consider reducing the workload arri val rates at the MN side, or , increasing the link and facility capacities at the DC side. The L -Lipschitz continuity of ∇D t ( λ ) in (as4) directly follows from the strong-con ve xity of the primal function in (as2) with L = ρ ( A > A ) /σ , where ρ ( A > A ) is the spectral radius of the matrix A > A . The strong 2 W e say that a function f : dom( f ) → R is σ -strongly conv ex if and only if f ( x ) − σ 2 k x k 2 is conv ex for all x ∈ dom( f ) , where dom( f ) ⊆ R n [26]. 5 concavity in (as4) is frequently assumed in network optimiza- tion [9], and it is closely related to the local smoothness and the uniqueness of Lagrange multipliers assumed in [13], [17], [30]. For pessimistic cases, (as4) can be satisfied by subtracting an ` 2 - regularizer from the dual function (11), which is typically used in machine learning applications (e.g., ridge regression). W e quantify its sub-optimality in Appendix A. Note that Appendix A implies that the primal solution x ∗ t will be O ( √ ) -optimal and feasible for the regularizer ( / 2) k λ k 2 . Since we are after an O ( µ ) -optimal online solution, it suf fices to set = O ( µ ) . A. Batch learning via of fline SA GA based tr aining Consider that a training set of N historical state samples S := { s n , 1 ≤ n ≤ N } is av ailable. Using S , we can find an empirical v ersion of (11) via sample a veraging as ˆ D S ( λ ) := 1 N N X n =1 ˆ D n ( λ ) = 1 N N X n =1 h min x n ∈X L n ( x n , λ ) i . (16) Note that t has been replaced by n to differentiate training (based on historical data) from operational (a.k.a. testing or tracking) phases. Consequently , the empirical dual problem can be e xpressed as max λ ≥ 0 1 N N X n =1 ˆ D n ( λ ) . (17) Recognizing that the objectiv e is a sum of finite concave functions, the task in (17) in the machine learning parlance is termed empirical risk maximization (ERM) [16], which is carried out using the batch gradient ascent iteration λ k +1 = " λ k + η N N X n =1 ∇ ˆ D n ( λ k ) # + (18) where the inde x k represents the batch learning (iteration) inde x, and η is the stepsize that controls the learning rate. While iteration (18) e xhibits a decent conv ergence rate, its compu- tational complexity will be prohibitiv ely high as the data size N grows large. A typical alternative is to employ a stochastic gradient (SG) iteration, which uniformly at random selects one of the summands in (18). Howe ver , such an SG iteration relies only on a single unbiased gradient correction, which leads to a sub-linear con ver gence rate. Hybrids of stochastic with batch gradient methods are popular subjects recently [19], [32]. 3 Lev eraging our special problem structure, we will adapt the recently dev eloped stochastic average gradient approach (SA GA) to fit our dual space setup, with the goal of efficiently computing empirical Lagrange multipliers. Compared with the original SA GA that is developed for unconstr ained optimization [19], here we start from the constrained optimization problem (6), and derive first a projected form of SA GA. Per iteration k , of fline SAGA first ev aluates at the current iterate λ k , one gradient sample ∇ ˆ D ν ( k ) ( λ k ) with sample in- dex ν ( k ) ∈ { 1 , . . . , N } selected uniformly at random . Thus, the computational complexity of SA GA is that of SG, and 3 Stochastic iterations for the empirical dual problem are different from that in Section III-C, since stochasticity is introduced by the randomized algorithm itself, in oppose to the stochasticity of future states in the online setting. Algorithm 1 Of fline SA GA iteration for batch learning 1: Initialize: λ 0 , k [ n ] = 0 , ∀ n , and stepsize η . 2: f or k = 0 , 1 , 2 . . . do 3: Pick a sample index ν ( k ) uniformly at random from the set { 1 , . . . , N } . 4: Evaluate ∇ ˆ D ν ( k ) ( λ k ) , and update λ k +1 as in (19). 5: Update the iteration index k [ n ] = k for ν ( k ) = n . 6: end f or markedly less than the batch gradient ascent (18), which re- quires N such ev aluations. Unlike SG howe ver , SA GA stores a collection of the most recent gradients ∇ ˆ D n ( λ k [ n ] ) for all samples n , with the auxiliary iteration index k [ n ] denoting the most recent past iteration that sample n was randomly drawn; i.e., k [ n ] := sup { k 0 : ν ( k 0 ) = n, 0 ≤ k 0 < k } . Specifically , SAGA ’ s gradient g k ( λ k ) combines linearly the gradient ∇ ˆ D ν ( k ) ( λ k ) randomly selected at iteration k with the stored ones {∇ ˆ D n ( λ k [ n ] ) } N n =1 to update the multipliers. The resultant gradient g k ( λ k ) is the sum of the difference between the fresh gradient ∇ ˆ D ν ( k ) ( λ k ) and the stored one ∇ ˆ D ν ( k ) ( λ k [ ν ( k )] ) at the same sample, as well as the av erage of all gradients in the memory , namely g k ( λ k ) = ∇ ˆ D ν ( k ) ( λ k ) − ∇ ˆ D ν ( k ) ( λ k [ ν ( k )] ) + 1 N N X n =1 ∇ ˆ D n ( λ k [ n ] ) . (19a) Therefore, the update of the offline SA GA can be written as λ k +1 = [ λ k + η g k ( λ k )] + (19b) where η denotes the stepsize. The steps of offline SA GA are summarized in Algorithm 1. T o expose the merits of SA GA, recognize first that since ν ( k ) is drawn uniformly at random from set { 1 , . . . , N } , we hav e that P { ν ( k ) = n } = 1 / N , and thus the e xpectation of the corresponding gradient sample is gi ven by E [ ∇ ˆ D ν ( k ) ( λ k )] := N X n =1 P { ν ( k ) = n }∇ ˆ D n ( λ k ) = 1 N N X n =1 ∇ ˆ D n ( λ k ) . (20) Hence, ∇ ˆ D ν ( k ) ( λ k ) is an unbiased estimator of the em- pirical gradient in (18). Likewise, E [ ∇ ˆ D ν ( k ) ( λ k [ ν ( k )] )] = (1 / N ) P N n =1 ∇ ˆ D n ( λ k [ n ] ) , which implies that the last two terms in (19a) disappear when taking the mean w .r .t. ν ( k ) ; and thus, SA GA ’ s stochastic averaging gradient estimator g k ( λ k ) is unbiased, as is the case with SG that only emplo ys ∇ ˆ D ν ( k ) ( λ k ) . W ith regards to variance, SG’ s gradient estimator has ˜ σ 2 k := v ar( ∇ ˆ D ν ( k ) ( λ k )) , which can be scaled down using decreasing stepsizes (e.g., η k = 1 / √ k ), to ef fect con vergence of { λ k } iterates in the mean-square sense [27]. As can be seen from the correction term in (19a), SAGA ’ s gradient estimator has lower variance than ˜ σ 2 k . Indeed, the sum term of g k ( λ k ) in (19a) is deterministic, and thus it has no effect on the variance. Howe ver , representing gradients of the same drawn sample ν ( k ) , the first two terms are highly correlated, and their dif ference has v ariance considerably smaller than ˜ σ 2 k . More importantly , the variance of stochastic gradient approximation vanishes as λ k approaches the optimal argument λ ∗ S for (17); 6 0 5000 10000 15000 Iteration 10 -8 10 -6 10 -4 10 -2 10 0 10 2 Dual variable suboptimality Offline SAGA SG SG-const Fig. 2. The dual sub-optimality k λ k − λ ∗ S k / k λ ∗ S k vs. number of iterations for SA GA with η = 1 / (3 L ) , and SG with constant stepsize η = 0 . 2 and diminishing stepsize η k = 1 / √ k . W e consider 100 state samples { s n } 100 n =1 for a cloud network with 4 DCs and 4 MNs. The details about the distribution for generating s n := { α i,n , e i,n , P r i,n , v j,n , ∀ i, j } are provided in Section VI. SA GA is the only method that conv erges linearly to the optimal argument. see e.g., [19]. This is in oppose to SG where the v ariance of stochastic approximation remains even if the iterates are close to the optimal solution. This variance r eduction property allows SA GA to achiev e a linear con vergence with constant stepsizes, which is not achiev able for the SG method. In the following theorem, we use the result in [19] to show that the offline SA GA method is linearly con ver gent. Theorem 1. Consider the offline SA GA iteration in (19) , and assume that the conditions in (as2)-(as4) are satisfied. If λ ∗ S denotes the unique optimal ar gument in (17) , and the stepsize is chosen as η = 1 / (3 L ) with Lipschitz constant L as in (as4), then SA GA iterates initialized with λ 0 satisfy E ν k λ k − λ ∗ S k 2 ≤ (Γ N ) k C S ( λ 0 ) (21a) wher e Γ N := 1 − min( 1 4 N , 1 3 κ ) with κ denoting the condition number in (as4), the expectation E ν is over all choices of the sample inde x ν ( k ) up to iter ation k , and constant C S ( λ 0 ) is C S ( λ 0 ) := k λ 0 − λ ∗ S k 2 (21b) − 2 N 3 L h ˆ D S ( λ 0 ) − ˆ D S ( λ ∗ S ) − h∇ ˆ D S ( λ ∗ S ) , λ 0 − λ ∗ S i i . Pr oof. See Appendix B. Since Γ N < 1 , Theorem 1 asserts that the sequence { λ k } generated by SAGA con ver ges exponentially to the empirical optimum λ ∗ S in mean-square. Similar to D t ( λ ) in (as4), if { ˆ D n ( λ ) } N n =1 in (16) are L -smooth, then so is ˆ D S ( λ ) , and the sub-optimality gap induced by ˆ D S ( λ k ) can be bounded by E ν [ ˆ D S ( λ ∗ S ) − ˆ D S ( λ k )] ≤ L E ν k λ k − λ ∗ S k 2 ≤ (Γ N ) k LC S ( λ 0 ) . (22) Remarkably , our offline SA GA based on training data is able to obtain the order-optimal con ver gence rate among all first- order approaches at the cost of only a single gradient ev aluation per iteration. W e illustrate the con ver gence of of fline SA GA with two SG variants in Fig. 2 for a simple example. As we observe, SA GA conv erges to the optimal argument linearly , while the SG method with diminishing stepsize has a sublinear con vergence rate and the one with constant stepsize con ver ges to a neighborhood of the optimal solution. Remark 1. The stepsize in Theorem 1 requires knowing the Lipschitz constant of (16). In our context, it is giv en by L = ρ ( A > A ) /σ , with ρ ( A > A ) denoting the spectral radius of the matrix A > A , and σ defined in (as2). When L can be properly approximated in practice, it is worth mentioning that the linear con vergence rate of offline SAGA in Theorem 1 can be established under a wider range of stepsizes, with slightly different constants Γ N and C S ( λ 0 ) [19, Theorem 1]. B. Learn-and-adapt via online SA GA Offline SA GA is clearly suited for learning from (ev en massiv e) training datasets available in batch format, and it is tempting to carry over our training-based iterations to the operational phase as well. Howe ver , different from common machine learning tasks, the training-to-testing procedure is no longer applicable here, since the online algorithm must also track system dynamics to ensure the stability of queue lengths in our network setup. Motiv ated by this observation, we introduce a novel data-driven approach called online SAGA, which incorporates the benefits of batch training to mitigate online stochasticity , while preserving the adaptation capability . Unlike the offline SA GA iteration that relies on a fixed training set, here we deal with a dynamic learning task where the training set grows in each time slot t . Running sufficiently many SA GA iterations for each empirical dual problem per slot could be computationally expensi ve. Inspired by the idea of dynamic SA GA with a fixed training set [20], the crux of our online SAGA in the operational phase is to learn from the dynamically growing training set at an affordable computational cost. This allo ws us to obtain a reasonably accurate solution at an affordable computational cost - only a few SA GA iterations. T o start, it is useful to recall a learning performance metric that uniformly bounds the difference between the empirical loss in (16) and the ensemble loss in (11) with high probability (w .h.p.), namely [16] sup λ ≥ 0 |D ( λ ) − ˆ D S ( λ ) | ≤ H s ( N ) (23) where H s ( N ) denotes a bound on the statistical error induced by the finite size N of the training set S . Under proper (so- termed mixing) conditions, the law of large numbers guarantees that H s ( N ) is in the order of O ( p 1 / N ) , or , O (1 / N ) for specific function classes [16, Section 3.4]. That the statement in (23) holds with w .h.p. means that there e xists a constant δ > 0 such that (23) holds with probability at least 1 − δ . In such case, the statistical accuracy H s ( N ) depends on ln(1 /δ ) , but we keep that dependenc y implicit to simplify notation [16], [33]. Let λ K N be an H o ( K N ) -optimal solution obtained by the offline SA GA ov er the N training samples, where H o ( K N ) will be termed optimization error emerging due to e.g., finite iterations say on a verage K per sample; that is, ˆ D S ( λ ∗ S ) − ˆ D S ( λ K N ) ≤ H o ( K N ) , where λ ∗ S is the optimal ar gument in (17). Clearly , the overall learning err or , defined as the 7 Algorithm 2 Online SA GA for learning-while-adapting 1: Offline initialize: batch training set S off := { s n } N off n =1 ; initial iterate λ 0 (0) ; iteration index k [ n ] = 0 , ∀ n , and stepsize η = 1 / (3 L ) . 2: Offline learning: run offline SAGA in Algorithm 1 for K N off iterations using historical samples in S off . 3: Online initialize: hot start with λ 0 (1) = λ K N off (0) , {∇ ˆ D n ( λ k [ n ] (0)) } N off n =1 from the of fline SA GA output using S 0 = S off ; queue length q 0 ; control variables µ > 0 , and b := [ √ µ log 2 ( µ ) , . . . , √ µ log 2 ( µ )] > . 4: f or t = 1 , 2 . . . do 5: Online adaptation: 6: Compute effecti ve multiplier using (25); acquire s t ; and use γ t to obtain x t as in (13a)-(13b), or by solving (26). 7: Update q t +1 using (1) and (2). 8: Online learning: 9: Form S t := S t − 1 ∪ s t with cardinality N t = N t − 1 + 1 , and initialize the gradient entry for s t . 10: Initialized by λ t and stored gradients, run K of fline SA GA iterations in Algorithm 1 with sample randomly drawn from set S t with N t samples, and output λ t +1 . 11: end f or difference between the empirical loss with λ = λ K N and the ensemble loss with λ = λ ∗ , is bounded abov e w .h.p. as D ( λ ∗ ) − ˆ D S ( λ K N ) = D ( λ ∗ ) − ˆ D S ( λ ∗ ) + ˆ D S ( λ ∗ ) − ˆ D S ( λ K N ) ≤D ( λ ∗ ) − ˆ D S ( λ ∗ ) + ˆ D S ( λ ∗ S ) − ˆ D S ( λ K N ) ≤H s ( N ) + H o ( K N ) (24) where the bound superimposes the optimization error with the statistical error . If N is relati vely small, H s ( N ) will be large, and keeping the per sample iterations K small is reasonable for reducing complexity , but also because H o ( K N ) stays com- parable to H s ( N ) . W ith the dynamically growing training set S t := S t − 1 ∪ s t in the operational phase, our online SAGA will aim at a “sweet-spot” between affordable complexity (controlled by K ), and desirable overall learning error that is bounded by H s ( N t ) + H o ( K N t ) with N t = |S t | . The proposed online SA GA method consists of two com- plementary stages: offline learning and online learning and adaptation . In the offline training-based learning, it runs K N off SA GA iteration (19) (cf. Algorithm 1) on a batch dataset S off with N off historical samples, and on average K iterations per sample. In the online operational phase, initialized with the offline output λ 0 (1) = λ K N off (0) , 4 online SA GA continues the learning process by storing a “hot” gradient collection as in Algorithm 1, and also adapts to the queue length q t that plays the role of an instantaneous multiplier estimate analogous to ˇ λ t = µ q t in (14). Specifically , online SAGA keeps acquiring data s t and growing the training set S t based on which it learns λ t online by running K iterations (19) per slot t . The last iterate of slot t − 1 initializes the first one of slot t ; that is, λ 0 ( t ) = λ K ( t − 1) . The learned λ 0 ( t ) captures a priori information S t − 1 . T o account for instantaneous state 4 T o differentiate offline and online iterations, let λ k (0) denote k -th iteration in the offline learning, and λ k ( t ) , t ≥ 1 denote k -th iteration during slot t . information as well as actual constraint violations which are valuable for adaptation, online SAGA will superimpose λ 0 ( t ) to the queue length (multiplier estimate) q t . T o av oid possible bias b ∈ R I + in the steady-state, this superposition is bias- corrected, leading to an ef fectiv e multiplier estimate (with short- hand notation λ t := λ 0 ( t ) ) γ t | {z } effective multiplier = λ t | {z } statistical learning + µ q t − b | {z } stochastic appro x . (25) where scalar µ tunes emphasis on past versus present state information, and the value of constant b will be specified in Theorem 4. Based on the ef fectiv e dual variable, the primal variables are obtained as in (13) with λ ∗ replaced by γ t ; or , for general constrained optimization problems, as x t ( γ t ) := arg min x t ∈X L t ( x t , γ t ) . (26) The necessity of combining statistical learning and stochastic approximation in (25) can be further understood from obeying feasibility of the original problem (6); e.g., constraints (6c) and (6d). Note that in the adaptation step of online SAGA, the variable q t is updated according to (6c), and the primal variable x t is obtained as the minimizer of the Lagrangian using the effecti ve multiplier γ t , which accounts for the queue variable q t via (25). Assuming that q t is approaching infinity , the v ariable γ t becomes large, and, therefore, the primal allocation x t ( γ t ) obtained by minimizing online Lagrangian (26) with λ = γ t will make the penalty term Ax t + c t negati ve. Therefore, it will lead to decreasing q t +1 through the recursion in (6c). This mechanism ensures that the constraint (6d) will not be violated. 5 The online SAGA is listed in Algorithm 2. Remark 2 ( Connection with existing algorithms ) . Online SA GA has similarities and dif ferences with common schemes in machine learning, and stochastic network optimization. (P1) SDG in [6], [24] can be viewed as a special case of online SA GA, which purely relies on stochastic estimates of multipliers or instantaneous queue lengths, meaning γ t = µ q t . In contrast, online SAGA further learns by stochastic av eraging ov er (possibly big) data to impro ve con vergence of SDG. (P2) Several schemes have been developed for statistical learning via large-scale optimization, including SG, SA G [32], SA GA [19], dynaSA GA [20], and AdaNewton [34]. Howe ver , these are generally tailored for static large-scale optimization, and are not suitable for dynamic resource allocation, because having γ t = λ t neither tracks constraint violations nor adapts to state changes, which is critical to ensure queue stability (6d). (P3) While online SA GA shares the learning-while-adapting attribute with the methods in [17] and [18], these approaches generally require using histogram-based pdf estimation, and solve the resultant empirical dual problem per slot exactly . Howe ver , histogram-based estimation is not tractable for our high-dimensional continuous random vector; and when the dual problem cannot be written in an explicit form, solving it exactly per iteration is computationally e xpensiv e. 5 W ithout (25), for a finite time t , λ t is always near-optimal for the ensemble problem (12), and the primal variable x t ( λ t ) in turn is near-feasible w .r .t. (9b) that is necessary for (6d). Since q t essentially accumulates online constraint violations of (9b), it will gro w linearly with t and ev entually become unbounded. 8 Remark 3 ( Computational complexity ) . Considering the di- mension of λ as ( I + J ) × 1 , the dual update in (14) has the computational complexity of O (( I + J ) · max { I , J } ) , since each row of A has at most max { I , J } non-zero entries. As the dimension of x t is ( I J + I ) × 1 , the primal update in (15), in general, requires solving a con ve x program with the worst- case comple xity of O ( I 3 . 5 J 3 . 5 ) using a standard interior-point solver . Overall, the per-slot computational complexity of the L yapunov optimization or SDG in [21], [24] is O ( I 3 . 5 J 3 . 5 ) . Online SA GA has a comparable complexity with that of SDG during online adaptation phase, where the effecti ve multiplier update, primal update and queue update also incur a worst-case complexity O ( I 3 . 5 J 3 . 5 ) in total. Although the online learning phase is composed of additional K updates of the empirical multiplier λ t through (19), we only need to compute one gradient ∇ ˆ D ν ( λ t ) at a randomly selected sample s ν . Hence, per-iteration comple xity is determined by that of solving (15), and it is independent of the data size N t . Clearly , subtracting stored gradient ∇ ˆ D n ( λ k [ n ] ) only incurs O ( I + J ) computations, and the last summand in (19a) can be iterati vely computed using running averages. In addition, for each new s t per slot, finding the initial gradient requires another O ( I 3 . 5 J 3 . 5 ) computations. Therefore, the overall complexity of online SA GA is still O ( I 3 . 5 J 3 . 5 ) , but with a (hidden) multiplicativ e constant K + 2 . V . O P T I M A L I T Y A N D S TA B I L I TY O F O N L I N E S AG A Similar to existing online resource allocation schemes, ana- lyzing the performance of online SA GA is challenging. In this section, we will first pro vide performance analysis for the online learning phase, upon which we assess performance of our novel resource allocation approach in terms of av erage cost and queue stability . For the online learning phase of online SA GA, we establish an upper-bound for the optimization error as follo ws. Lemma 1. Consider the pr oposed online SAGA in Algorithm 2, and suppose the conditions in (as1)-(as4) are satisfied. Define the statistical err or bound H s ( N ) = dN − β wher e d > 0 and β ∈ (0 , 1] . If we select K ≥ 6 and N off = 3 κ/ 4 , the optimization err or at time slot t is bounded in the mean by E h ˆ D S t ( λ ∗ S t ) − ˆ D S t ( λ t ) i ≤ c ( K ) H s ( N t ) + ξ e K/ 5 3 κ 4 N t K 5 (27) wher e the expectation is over all sour ce of r andomness during the optimization; constants are defined as N t := N off + t and c ( K ) := 4 / ( K − 5) ; and ξ is the initial err or of λ 0 in (21a) , i.e., ξ := E [ C S off ( λ 0 )] with expectation over the choice of S off . Pr oof. See Appendix C. As intuiti vely expected, Lemma 1 confirms that for N off fixed, increasing K per slot will lower the optimization error in the mean; while for a fixed K , increasing N off implies improv ed startup of the online optimization accuracy . Howe ver , solely increasing K will incur higher computational complexity . Fortunately , the ne xt proposition ar gues that online SAGA can afford low-comple xity operations. Proposition 2. Consider the assumptions and the definitions of ξ , H s ( N ) and β as those in Lemma 1. If we choose the averag e number of SAGA iterations per-sample K = 1 , and the batch size N off = 3 κ/ 4 , the mean optimization err or satisfies that E h ˆ D S t ( λ ∗ S t ) − ˆ D S t ( λ t ) i ≤ c (1) H s ( N t ) + ξ 6 κ eN t 8 5 (28) with the constant defined as c (1) := 8 β × 11 / 6 + 4 β / 2 + 2 β − 1 . Pr oof. See Appendix D. Proposition 2 shows that when N t is sufficiently large, the optimization accuracy with only K = 1 iteration per slot (per new datum) is on the same order of the statistical accuracy provided by the current training set S t . Note that for other choices of K ∈ { 2 , . . . , 5 } , constant c ( K ) can be readily obtained by follo wing the proof of Proposition 2. In principle, online SA GA requires N off batch samples and K iterations per slot to ensure that the optimization error is close to statistical accuracy . In practice, one can ev en skip the batch learning phase since online SAGA can operate with a “cold start. ” Simulations in Section VI will validate that without offline learning, online SA GA can still markedly outperform e xisting approaches. Before analyzing resource allocation performance, con ver - gence of the empirical dual variables is in order . Theorem 2. Consider the pr oposed online SA GA in Algorithm 2, and suppose the conditions in (as1)-(as4) ar e satisfied. If N off ≥ 3 κ/ 4 , and K ≥ 1 per sample, the empirical dual variables of online SA GA satisfy lim t →∞ λ t = λ ∗ , w . h . p . (29) wher e λ ∗ denotes the optimal dual variable for the ensemble minimization in (12) , and w .h.p. entails a pr obability arbitrarily close b ut strictly less than 1 . Pr oof. Since the deriv ations for K ∈ { 1 , . . . , 5 } follow the same steps with only different constant c ( K ) , we focus on K ≥ 6 . Recalling the Markov’ s inequality that for any non- negati ve random variable X and constant δ > 0 , we ha ve P ( X ≥ 1 /δ ) ≤ E [ X ] δ . W e can re write (27) as E " ˆ D S t ( λ ∗ S t ) − ˆ D S t ( λ t ) c ( K ) H s ( N t ) + (3 κ/ (4 N t )) K/ 5 ξ /e K 5 # ≤ 1 . (30) Since the random variable inside the expectation of (30) is non- negati ve, applying Markov’ s inequality yields P ˆ D S t ( λ ∗ S t ) − ˆ D S t ( λ t ) ≥ 1 δ c ( K ) H s ( N t ) + ξ e K 5 3 κ 4 N t K 5 ≤ δ (31) thus with probability at least 1 − δ , it holds that ˆ D S t ( λ ∗ S t ) − ˆ D S t ( λ t ) ≤ c ( K ) H s ( N t ) + ξ e K/ 5 3 κ 4 N t K 5 (32) where the RHS of (32) scales by the constant 1 /δ , but again we k eep that dependenc y implicit to simplify notation. W ith the current empirical multiplier λ t , the optimality gap in terms of the ensemble objectiv e (11) can be decomposed by D ( λ ∗ ) − D ( λ t ) = D ( λ ∗ ) − ˆ D S t ( λ t ) | {z } R 1 + ˆ D S t ( λ t ) − D ( λ t ) | {z } R 2 . (33) 9 Note that R 1 can be bounded abov e via (24) by R 1 ( a ) ≤ ˆ D S t ( λ ∗ S t ) − ˆ D S t ( λ t ) + H s ( N t ) ( b ) ≤ (1 + c ( K )) H s ( N t ) + ξ e K/ 5 3 κ 4 N t K 5 (34) where (a) uses (24) and the definition of H o ( K N t ) ; (b) follows from (32); and both (a) and (b) hold with probability 1 − δ so that (34) holds with probability at least (1 − δ ) 2 ≥ 1 − 2 δ . In addition, R 2 can be bounded via the uniform con ver gence in (23) with probability 1 − δ by R 2 ≤ sup λ ≥ 0 |D ( λ ) − ˆ D S t ( λ ) | ≤ H s ( N ) (35) where the RHS scales by ln(1 /δ ) . Plugging (34) and (35) into (33), with probability at least 1 − 3 δ , it follows that D ( λ ∗ ) − D ( λ t ) ≤ h ( δ ) h 2 + c ( K ) i H s ( N t ) + h ( δ ) ξ e K/ 5 3 κ 4 N t K 5 (36) where the multiplicative constant h ( δ ) = O ( 1 δ ln 1 δ ) in the RHS is induced by the hidden constants in (34) and (35), that is independent of t but increasing as δ decreases. Note that the strong concavity of the ensemble dual function D ( λ ) implies that 2 k λ ∗ − λ t k 2 ≤ D ( λ ∗ ) − D ( λ t ) ; see [35, Corollary 1]. T ogether with (36), with probability at least 1 − 3 δ , it leads to lim t →∞ 2 k λ ∗ − λ t k 2 ≤ lim t →∞ D ( λ ∗ ) − D ( λ t ) ≤ lim t →∞ h ( δ ) [2 + c ( K )] H s ( N t ) + h ( δ ) ξ e K/ 5 3 κ 4 N t K 5 ( c ) = 0 (37) where (c) follows since h ( δ ) is a constant, lim t →∞ H s ( N t ) = 0 , and lim t →∞ 1 /N t = 0 . Theorem 2 asserts that λ t learned through online SA GA con verges to the optimal λ ∗ w .h.p., ev en for small N off and K . T o increase the confidence of Theorem 2, one should decrease the constant δ to ensure a lar ge 1 − 3 δ . Although a small δ will also enlarge the multiplicati ve constant h ( δ ) in the RHS of (36), the result in (37) still holds since H s ( N t ) and 1 / N t deterministically conv erge to null as t → ∞ . Therefore, Theorem 2 indeed holds with arbitrary high probability with δ small enough. For subsequent discussions, we only use w .h.p. to denote this high probability 1 − 3 δ to simplify the exposition. Considering the trade-off between learning accuracy and storage requirements, a remark is due at this point. Remark 4 ( Memory complexity ) . Con vergence to λ ∗ in (29) requires N t → ∞ , but in practice datasets are finite. Suppose that N off ∈ [3 κ/ 4 , W ] , and online SA GA stores the most recent W ≤ N t samples with their associated gradients from S t . Following Lemma 1 and [34, Lemma 6], one can show that the statistical error term at the RHS of (36) will stay at O ( H s ( W )) for a suf ficiently large W ; thus, λ t will conv erge to a O ( H s ( W )) -neighborhood of λ ∗ w .h.p. Howe ver , since we ev entually aim at an O ( √ µ ) -optimal effecti ve multiplier (cf. (41)), it suffices to choose W such that H s ( W ) = o ( √ µ ) . Having established conv ergence of λ t , the next step is to show that γ t also con verges to λ ∗ , and being a function of γ t the online resource allocation x t is also asymptotically optimal (cf. Proposition 1). T o study the trajectory of γ t , consider the iteration of successive differences (cf. (25)) γ t +1 − γ t = ( λ t +1 − λ t ) + µ ( q t +1 − q t ) . (38) In view of (29) and (38), to establish conv ergence of γ t it is prudent to study the asymptotic behavior of ( q t +1 − q t ) . T o this end, let ˜ b t := λ ∗ − λ t + b denote the error λ ∗ − λ t of the statistically learned dual v ariable plus a bias-control variable b . Theorem 2 guarantees that lim t →∞ ˜ b t = b , w . h . p Next, we show that q t is attracted towards ˜ b t /µ . Lemma 2. Consider the online SA GA in Algorithm 2, and the conditions in (as1)-(as4) are satisfied. Ther e e xists a constant B = Θ(1 / √ µ ) and a finite time T B < ∞ , such that for all t ≥ T B , if k q t − ˜ b t /µ k > B , it holds w .h.p. that queue lengths under online SAGA satisfy E h q t +1 − ˜ b t /µ q t i ≤ q t − ˜ b t /µ − √ µ. (39) Pr oof. See Appendix E. Lemma 2 reveals that when q t deviates from ˜ b t /µ , it will bounce back towards ˜ b t /µ at the next slot. W ith the drift behavior of q t in (39), we are on track to establish the desired long-term queue stability . Theorem 3. Consider the online SA GA in Algorithm 2, and the conditions in (as1)-(as4) are satisfied. W ith constants b and µ defined in (25) , the steady-state queue length satisfies lim T →∞ 1 T T X t =1 E [ q t ] = b µ + O ( 1 √ µ ) , w . h . p . (40) wher e the pr obability is close but strictly less than 1 . Pr oof. See Appendix F. Theorem 3 entails that the online solution for the relaxed problem in (9) is a feasible solution for the original problem in (6), which justifies ef fectiv eness of the online learn-and-adapt step (25). Theorem 3 also points out the importance of the parameter b in (25), since the steady-state queue lengths will hov er around b /µ with distance O (1 / √ µ ) . Using Theorem 2, it suf fices to sho w that γ t con verges to a neighborhood of λ ∗ , lim t →∞ γ t = λ ∗ + µ q t − b = λ ∗ + O ( √ µ ) · 1 , w . h . p . (41) Qualitativ ely speaking, online SA GA behav es similar to SDG in the steady state. Howe ver , the main difference is that through more accurate empirical estimate λ t , online SAGA is able to accelerate the con vergence of γ t , and reduce network delay by replacing q t = ˇ λ t /µ in SDG, with λ t in (25). On the other hand, since a smaller b corresponds to lower av erage delay , it is tempting to set b close to zero (cf. (40)). Though attracti ve, a small b ( ≈ 0 ) will contrib ute to an ef fective multiplier γ t (= λ t + µ q t ) always larger than λ ∗ , since λ t con verges to λ ∗ and q t ≥ 0 . This introduces bias to the ef fectiv e multiplier γ t , which means a larger rew ard in the context of resource allocation. This in turn encourages “ov er-allocation” of resources, and thus leads to a larger optimality loss due to the non-decreasing property of the primal objecti ve in (as2). Using arguments similar to those in [13] and [17], we formally 10 establish next that by properly selecting b , online SA GA is asymptotically near -optimal. Theorem 4. Under (as1)-(as4), let Ψ ∗ denote the optimal objective value in (6) under any feasible schedule even with futur e information available. Choosing b = √ µ log 2 ( µ ) · 1 with an appr opriate µ , the online SAGA in Algorithm 2 yields a near- optimal solution for (6) in the sense that lim T →∞ 1 T T X t =1 E [Ψ t ( x t ( γ t ))] ≤ Ψ ∗ + O ( µ ) , w . h . p . (42) wher e x t ( γ t ) denotes the r eal-time schedules obtained fr om the Lagrangian minimization (26) , and again this pr obability is arbitr arily close but strictly less than 1 . Pr oof. See Appendix G. Combining Theorems 3 and 4, and selecting b = √ µ log 2 ( µ ) · 1 , online SA GA is asymptotically near-optimal with average queue length O (log 2 ( µ ) / √ µ ) . This implies that in the context of stochastic network optimization [21], the nov el approach achie ves a near-optimal cost-delay tradeoff [ µ, log 2 ( µ ) / √ µ ] with high probability . Comparing with the standard tradeoff [ µ, 1 /µ ] under SDG [21], [24], the proposed offline-aided-online algorithm design proposed significantly im- prov es the online performance in terms of delay in most cases. This is a desired performance trade-off under the current setting in the sense that the “optimal” tradeoff [ µ, log 2 ( µ )] in [17] is derived under the local polyhedral assumption, which is typically the case when the primal feasible set contains a finite number of actions. The performance of online SA GA under settings with local polyhedral property is certainly of practical interest, but this goes beyond the scope of the present work, and we leave for future research. Remark 5. The learning-while-adapting attribute of online SA GA amounts to choosing a scheduling policy , or equiv alently effecti ve multipliers, satisfying the follo wing criteria. C1) The effecti ve dual variable is initiated or adjusted online close to the optimal multiplier enabling the online algorithm to quickly reach an optimal resource allocation strategy (cf. Prop. 1). Unlike SDG that relies on incremental updates to adjust dual v ariables, online SA GA attains a near-optimal ef fective multiplier much faster than SDG, thanks to the stochastic av eraging that accelerates con ver gence of statistical learning. C2) Online SA GA judiciously accounts for queue dynamics in order to guarantee long-term queue stability , which becomes possible through instantaneous measurements of queue lengths. Building on C1) and C2), the proposed data-driv en con- strained optimization approach can be extended to incorporate second-order iterations in the learning mode (e.g., AdaNe wton in [34]), or momentum iterations in the adaptation mode [9]. V I . N U M E R I C A L T E S T S This section presents numerical tests to confirm the analytical claims, and demonstrate the merits of the proposed approach. The network considered has I = 4 DCs, and J = 4 MNs. 0 2 4 6 8 10 x 10 4 0 2 4 6 8 x 10 5 Time slot Time−average network costs SDG SDG+ Online SAGA Fig. 3. Comparison of time-av erage costs ( I = J = 4 , N off = 1 , 000 , K = 2 ) 0 2 4 6 8 10 x 10 4 0 1 2 3 4 5 x 10 4 Time slot Instantaneous queue length SDG SDG+ Online SAGA Fig. 4. Comparison of queue lengths ( I = J = 4 , N off = 1 , 000 , K = 2 ) Performance is tested in terms of the time-a verage instantaneous network cost Ψ t ( x t ) := X i ∈I α i,t e i,t x 2 i,t − P r i,t + X i ∈I X j ∈J c d i,j ˜ x 2 i,j,t (43) where the energy transaction price α i,t is uniformly distributed ov er [10 , 30] $/kWh; the energy efficienc y factors are time- in variant taking values { e i,t } = { 1 . 2 , 1 . 3 , 1 . 4 , 1 . 5 } ; samples of the renewable supply { P r i,t } are generated from a uniform distribution with support [10 , 50] kWh; and the bandwidth cost is set to c d i,j = 40 /B i,j , with bandwidth limits { B i,j } generated from a uniform distribution with support [10 , 100] . DC computing capacities are { D i } = { 200 , 150 , 100 , 100 } , and uniformly distributed over [10 , 150] workloads { v j,t } arrive at each MN j . Unless specified otherwise, default parameter v alues are chosen as b = √ µ log 2 ( µ ) · 1 , and µ = 0 . 1 . Online SA GA is compared with two alternati ves: a) the standard stochastic dual subgradient (SDG) algorithm in e.g., [6], [21]; and b) a ‘hot-started’ version of SDG that we term SDG+, in which initialization is provided using offline SAGA with N off training samples. Note that the approaches in [17] and [18] rely on histogram-based pdf estimation to approximate the ensemble dual problem (12). F or our setting howe ver , directly estimating the pdf of a multiv ariate continuous random state s t ∈ R 3 I + J is a considerably cumbersome work. Even if we only discretize each entry of s t into 10 lev els, the number of possible network states can be 10 16 or 10 80 in our simulated settings ( I = J = 4 , or , I = J = 20 ), thus the y are not simulated for comparison. 11 0 2 4 6 8 10 x 10 4 0 1 2 3 4 x 10 6 Time slot Time−average network costs SDG SDG+ Online SAGA Fig. 5. Comparison of time-average costs ( I = J = 20 , N off = 1 , 000 , K = 2 ) 0 2 4 6 8 10 x 10 4 0 1 2 3 4 5 x 10 4 Time slot Intantaneous queue lengths SDG SDG+ Online SAGA Fig. 6. Comparison of queue lengths ( I = J = 20 , N off = 1 , 000 , K = 2 ) Performance is first compared with moderate size N off = 1 , 000 in Figs. 3-4. For the network cost, the three algorithms con verge to the same v alue, with the online SA GA exhibit- ing fastest con vergence since it quickly achieves the optimal scheduling by learning from training samples. In addition, lev eraging its learning-while-adapting attribute, online SA GA incurs considerably lower delay as the average queue size is only 40% of that under SDG+, and 20% of that under SDG. Clearly , of fline training improves also delay performance of SDG+, and online SA GA further improv es relati ve to SDG+ thanks to online (in addition to offline) learning. These two metrics are further compared in Figs. 5-6 o ver a larger network with I = 20 DCs and J = 20 MNs. While the three algorithms exhibit similar performance in terms of network cost, the av erage delay of online SA GA stays noticeably lower than its alternativ es. The delay performance of SDG+ approaches that of SDG (cf. the gap in Fig. 4), which indicates that N off = 1 , 000 training samples may be not enough to obtain a sufficiently accurate initialization for SDG+ over such a large netw ork. For f airness to SDG, the ef fects of tuning µ and K are studied in Figs. 7-10 without training ( N off = 0 ). F or all choices of µ , the online SA GA attains a much smaller delay at network cost comparable to that of SDG (cf. Fig. 7), and its delay increases much slo wer as µ decreases (cf. Fig. 8), thanks to a better delay-cost tradeof f [ µ, 1 √ µ log 2 ( µ )] . As sho wn by Lemma 1, the per -slot learning error decreases as the number of learning iterations K increases. Finally , Figs. 9 and 10 delineate the 0.2 0.4 0.6 0.8 1 6.1 6.15 6.2 6.25 6.3 6.35 6.4 6.45 6.5 x 10 5 Control variable µ Steady−state network cost SDG Online SAGA Fig. 7. Network cost as a function of µ ( I = J = 4 , N off = 0 , K = 2 ) 0.2 0.4 0.6 0.8 1 0 1 2 3 4 5 x 10 4 Control variable µ Steady−state network delay SDG Online SAGA Fig. 8. Network delay as a function of µ ( I = J = 4 , N off = 0 , K = 2 ) performance versus learning complexity tradeof f as a function of K . Increasing K slightly improves con vergence speed, and significantly reduces the av erage delay at the expense of higher computational comple xity . V I I . C O N C L U D I N G R E M A R K S A comprehensi ve approach was de veloped, which perme- ates benefits of stochastic av eraging to considerably improve gradient updates of online dual variable iterations in volv ed in constrained optimization tasks. The impact of integrating offline and online learning while adapting was demonstrated in a stochastic resource allocation problem emerging from cloud networks with data centers and renewables. The considered stochastic resource allocation task was formulated with the goal of learning Lagrange multipliers in a fast and ef ficient manner . Casting batch learning as maximizing the sum of finite concav e functions, machine learning tools were adopted to lev erage training samples for of fline learning initial multiplier estimates. The latter provided a “hot-start” of nov el learning- while-adapting online SA GA. The nov el scheduling protocol of- fers low-complexity yet efficient learning, and adaptation, while guaranteeing queue stability . Finally , performance analysis - both analytical and simulation based - demonstrated that the nov el approach markedly improv es network resource allocation performance, at the cost of affordable extra memory to store gradient v alues, and just one extra sample ev aluation per slot. This nov el of fline-aided-online optimization frame work opens up some new research directions, which include studying 12 0 2 4 6 8 10 x 10 4 0 2 4 6 8 x 10 5 Time slot Time−average network costs SDG Online SAGA (K=2) Online SAGA (K=3) Online SAGA (K=5) Online SAGA (K=10) Fig. 9. Network cost versus K ( I = J = 4 , N off = 0 ) how to further endow performance improvements under other system configurations (e.g., local polyhedral property), and how to establish performance guarantee in the almost sure sense. Fertilizing other emer ging cyber-physical systems (e.g., power networks) is a promising research direction, and accounting for possibly non-stationary dynamics is also of practical interest. A P P E N D I X A. Sub-optimality of the r egularized dual pr oblem W e first state the sub-optimality brought by subtracting an ` 2 -regularizer in (11). Lemma 3. Let { x ∗ t } and λ ∗ denote the optimal ar guments of the primal and dual pr oblems in (9) and (12) , r espectively; and corr espondingly { ˆ x ∗ t } and ˆ λ ∗ for the primal and the ` 2 - r e gularized dual pr oblem max λ ≥ 0 D ( λ ) − 2 k λ k 2 . (44) F or > 0 , it then holds under (as1) and (as2) that E [ k x ∗ t − ˆ x ∗ t k 2 ] ≤ 2 σ k λ ∗ k 2 − k ˆ λ ∗ k 2 , ∀ λ ∗ ∈ Λ ∗ (45) wher e Λ ∗ denotes the set of optimal dual variables for the original dual pr oblem (12) . Pr oof. Follo ws the steps in [36, Lemma 3.2]. Lemma 3 provides an upper bound on the expected dif ference between the optimal arguments of the primal (9) and that for (44), in terms of the difference between the corresponding dual arguments. Clearly , by choosing a relatively small , the gap between x ∗ t and ˆ x ∗ t closes. Using the con ve xity of k · k 2 , Lemma 3 implies readily the following bound E [ k x ∗ t − ˆ x ∗ t k ] ≤ p / (2 σ ) max λ ∗ ∈ Λ ∗ k λ ∗ k , which in turn implies that with the regularizer present in (44), { x ∗ t } will be O ( √ ) -optimal and feasible. The sub-optimality in terms of the objective v alue can be easily quantified using the Lipschitz gradient condition in (as2). Clearly , the gap v anishes as → 0 , or , as the primal strong con vexity constant σ → ∞ . As we ev entually pursue an O ( µ ) -optimal solution in Theorem 4, it suffices to set = O ( µ ) . 0 2 4 6 8 10 x 10 4 0 1 2 3 4 5 x 10 4 Time slot Instantaneous queue lengths SDG Online SAGA (K=2) Online SAGA (K=3) Online SAGA (K=5) Online SAGA (K=10) Fig. 10. Queue length averaged over all nodes versus K ( I = J = 4 , N off = 0 ) B. Pr oof sketc h of Theorem 1 The SA GA in [19] is originally designed for unconstrained optimization problem in machine learning applications. Observe though, that it can achieve linear con ver gence rate when the objectiv e is in a composite form min x ∈ R d f ( x ) + h ( x ) , where f ( x ) is a strongly-con ve x and smooth function, and h ( x ) is a con vex and possibly non-smooth regularizer . T o tackle this non-smooth term, instead of pursuing a subgradient direction, the SAGA iteration in [19] performs a stochastic-averaging step w .r .t. f ( x ) , follo wed by a proximal step, gi ven by Pro x h η ( x ) := arg min y ∈ R d h ( y ) + 1 2 η k y − x k 2 . (46) For the constrained optimization problem (17), we can vie w the regularizer as an indicator function, namely h ( x ) := 0 , x ≥ 0 ; ∞ , otherwise , which penalizes the argument outside of the feasible re gion x ≥ 0 . In this case, one can sho w that the proximal operator reduces to the projection operator , namely Pro x h η ( x ) = arg min y ≥ 0 1 2 k y − x k 2 = [ x ] + . (47) T o this end, the proof of linear conv ergence for the offline SA GA in Algorithm 1 can follo w the steps of that in [19]. C. Pr oof of Lemma 1 T o formally bound the optimization error of online SA GA at each time slot, it is critical to understand the quality of using the iterate learned from a small dataset (e.g., S t − 1 ) as a hot-start for the learning process in a larger set (e.g., S t ). Intuiti vely , if the iterate learned from a small dataset can perform reasonably well in an ERM defined by a bigger set, then a desired learning performance of online SA GA can be e xpected. T o achieve this goal, we first introduce a useful lemma from [20, Theorem 3] to relate the sub-optimality on an arbitrary set S to the sub-optimality bound on its subset ˇ S , where ˇ S ⊆ S . Lemma 4. Consider the definitions m := | ˇ S | , n = |S | , with m < n , and suppose that λ ˇ S is an ω -optimal solution for the training subset ˇ S satisfying E [ ˆ D ˇ S ( λ ∗ ˇ S ) − ˆ D ˇ S ( λ ˇ S )] ≤ ω . Under (as1), the sub-optimality gap when using λ ˇ S in an ERM defined by S is given by E h ˆ D S ( λ ∗ S ) − ˆ D S ( λ ˇ S ) i ≤ ω + n − m n H s ( m ) , (48) 13 wher e e xpectation is o ver all source of r andomness; ˆ D ˇ S ( λ ) and ˆ D S ( λ ) ar e the empirical functions in (16) appr oximated by sample sets ˇ S and S , r espectively; λ ∗ ˇ S and λ ∗ S ar e the corr esponding two optimal multipliers; and, H s ( m ) is the statistical err or induced by the m samples defined in (23) . Lemma 4 states that if the set ˇ S gro ws to S , then the optimization error on the larger set S is bounded by the original error ω plus an additional “growth cost” (1 − m/n ) H s ( m ) . Note that Lemma 4 considers a general case of increasing training set from ˇ S to S , but the dynamic learning steps of online SA GA in Algorithm 2 is a special case when ˇ S = S t − 1 and S = S t . Building upon Lemma 4 and Theorem 1, we are ready to deriv e the optimization error of online SAGA. T o achiev e this goal, we first define a sequence U o ( k ; n ) , which will prov e to provide an upper -bound for the optimization error by incr ementally running k offline SAGA iterations within a dataset S with n = |S | ; i.e., E [ ˆ D S ( λ ∗ S ) − ˆ D S ( λ k )] ≤ U o ( k ; n ) . Note that inde x k is used to differentiate from time index t , since it includes the SAGA iterations in both offline and online phases. Considering a dataset S with n = |S | , running an additional SA GA iteration (19) will reduce the error by a factor of Γ n defined in (22). Hence, if U o ( k − 1; n ) giv es an upper-bound of E [ ˆ D S ( λ ∗ S ) − ˆ D S ( λ k − 1 )] , it follows that E [ ˆ D S ( λ ∗ S ) − ˆ D S ( λ k )] ≤ Γ n U o ( k − 1; n ) . (49) On the other hand, the error of running k iterations within n data should also satisfy the inequality (48) in Lemma 4 which holds from any m < n . Thus, if given U o ( k ; m ) , it follo ws that E h ˆ D S ( λ ∗ S ) − ˆ D S ( λ k ) i ≤ min m 0 , p > q > 0 , which for (e1) implies that 4 N t +1 4 N t + 3 5 = 1 + 5 5(4 N t + 3) 5 ( f ) ≥ 1 + 5 4 N t + 3 ( g ) ≥ N t +1 N t (57) where (f) uses Bernoulli’ s inequality with p = 5 and q = 1 , and (g) holds for N t ≥ 3 . Building upon (57), the inequality (d1) follows since N t N t +1 · H s ( N t ) H s ( N t +1 ) = N t N t +1 1 − β ≤ 1 , ∀ β ∈ [0 , 1] . (58) For (e2), since 4 N t +3 4 N 4 / 5 t +1 N 1 / 5 t K = ( N t +3 / 4) 5 N t ( N t +1) 4 K/ 5 , it suffices to sho w that ( N t +3 / 4) 5 N t ( N t +1) 4 ≤ 1 , which implies that ( N t + 3 / 4) 5 N t ( N t + 1) 4 = N t + 3 / 4 N t 1 + 1 / 4 N t +3 / 4 4 ( h ) ≤ N t + 3 / 4 N t 1 + 1 N t +3 / 4 = ( N t + 3 / 4) 2 N t ( N t + 7 / 4) = 1 − N t / 4 − 9 / 16 N t ( N t + 7 / 4) ( i ) ≤ 1 where (h) uses Bernoulli’ s inequality with p = 4 and q = 1 , and (i) again holds for N t ≥ N off ≥ 3 , which is typically satisfied in batch training scenarios. Hence, inequality (56) holds. Building upon (56), we will show ne xt that 4 N t + 3 4 N t +1 K − 5 c ( K ) + 1 N t +1 ≤ c ( K ) (59) 14 from which we can conclude that (52) holds for t + 1 , namely U o ( K N t +1 ; N t +1 ) ≤ c ( K ) H s ( N t +1 ) + ξ e K/ 5 3 κ 4 N t +1 K/ 5 . (60) By rearranging terms, (59) is equiv alent to c ( K ) ≥ 4 N t +1 4 N t + 3 K − 5 − 1 ! N t +1 ! − 1 ( j ) = K − 6 X k =0 4 N t +1 4 N t + 3 k ! 4 N t +1 4 N t + 3 − 1 N t +1 ! − 1 = 1 4 K − 5 X k =1 4 N t +1 4 N t + 3 k ! − 1 (61) where (j) follows from the sum of a geometric sequence. Observe that the RHS of (61) is increasing with t , thus we hav e that c ( K ) := 4 K − 5 = lim t →∞ 1 4 K − 4 X k =1 4 N t +1 4 N t + 3 k ! − 1 ≥ 1 4 K − 4 X k =1 4 N t +1 4 N t + 3 k ! − 1 , ∀ t (62) from which (59) holds and so does inequality (60). This completes the proof of Lemma 1. D. Pr oof of Pr oposition 2 Using Lemma 1 and selecting K = 8 , we hav e that (cf. the definition of U o ( k ; n ) in Appendix C) U o (8 N t ; N t ) ≤ 4 3 H s ( N t ) + ξ 3 κ 4 eN t 1 . 6 . (63) It further follows from Lemma 4 that U o (8 N t ; 2 N t ) ( a ) ≤ U o (8 N t ; N t ) + 1 2 H s ( N t ) (64) ≤ 11 6 H s ( N t ) + ξ 3 κ 4 eN t 1 . 6 ( b ) = 11 6 · 2 β H s (2 N t ) + ξ 3 κ 4 eN t 1 . 6 where (a) follows from (51b), and (b) uses the definition of H s ( N ) such that H s (2 N t ) = 2 − β H s ( N t ) . By setting N t = N t / 2 , we have U o (4 N t ; N t ) ≤ 11 6 · 2 β H s ( N t ) + ξ 3 κ 2 eN t 1 . 6 . (65) Follo wing the steps in (64), we can also deduce that U o (2 N t ; N t ) ≤ 11 6 · 4 β + 1 2 · 2 β H s ( N t ) + ξ 3 κ eN t 1 . 6 (66) and lik ewise we hav e U o ( N t ; N t ) ≤ 11 × 8 β 6 + 4 β 2 + 2 β 2 H s ( N t ) + ξ 6 κ eN t 1 . 6 (67) which completes the proof. E. Pr oof of Lemma 2 T o prove Lemma 2, we first state a simple but useful property of the primal-dual problems (9) and (12), which can be easily deriv ed based on the KKT conditions [26]. Proposition 3. Under (as1)-(as3), for the constrained optimiza- tion (9) with the optimal policy χ ∗ ( · ) and its optimal Lagrang e multiplier λ ∗ , it holds that E [ Ax ∗ t + c t ] = 0 with x ∗ t = χ ∗ ( s t ) , and accor dingly that ∇D ( λ ∗ ) = 0 . Based on Proposition 3, we are ready to prove Lemma 2. Since λ t con verges to λ ∗ whp , and b > 0 , there exists a finite T b such that for t > T b , we have k λ ∗ − λ t k ≤ k b k and thus ˜ b t ≥ 0 by definition. Hence, k q t +1 − ˜ b t /µ k 2 ( a ) ≤ k q t + Ax t + c t − ˜ b t /µ k 2 ( b ) ≤ k q t − ˜ b t /µ k 2 + M + 2( q t − ˜ b t /µ ) > ( Ax t + c t ) ( c ) = k q t − ˜ b t /µ k 2 + M + 2 γ t − λ ∗ µ > ( Ax t + c t ) ( d ) ≤ k q t − ˜ b t /µ k 2 + 2 µ ( D t ( γ t ) − D t ( λ ∗ )) + M (68) where (a) comes from the non-expansi ve property of the projection operator; (b) uses the upper bound M := max t max x t ∈X k Ax t + c t k 2 ; equality (c) uses the definitions of ˜ b t and λ t ; and (d) follows because Ax t + c t is a subgradient of the concave function D t ( λ ) at λ = γ t (cf. (26)). Using the strong concavity of D ( λ ) at λ = λ ∗ , it holds that D ( γ t ) ≤D ( λ ∗ ) + ∇D ( λ ∗ ) > ( γ t − λ ∗ ) − 2 k γ t − λ ∗ k 2 ( e ) ≤ D ( λ ∗ ) − 2 k γ t − λ ∗ k 2 (69) where (e) follows from ∇D ( λ ∗ ) = 0 (cf. Proposition 3). Then using (69), and taking expectations on (68) ov er s t conditioned on q t , we have E h k q t +1 − ˜ b t /µ k 2 i ≤ k q t − ˜ b t /µ k 2 − µ k q t − ˜ b t /µ k 2 + M (70) where we used D ( λ ) := E [ D t ( λ )] , and γ t − λ ∗ = µ q t − ˜ b t . Hence, based on (70), if we hav e − µ k q t − ˜ b t /µ k 2 + M ≤ − 2 √ µ k q t − ˜ b t /µ k + µ (71) it holds that E k q t +1 − ˜ b t /µ k 2 ≤ k q t − ˜ b t /µ k − √ µ 2 , and by the conv exity of the quadratic function, we ha ve E h k q t +1 − ˜ b t /µ k i 2 ≤ k q t − ˜ b t /µ k − √ µ 2 (72) which implies (39) in the lemma. V ieta’ s formulas for second- order equations ensure existence of B = Θ( 1 √ µ ) so that (71) is satisfied for k q t − ˜ b t /µ k > B , and thus the lemma follows. F . Pr oof sketc h for Theorem 3 Lemma 2 assures that q t always tracks a time-varying target ˜ b t /µ . As lim t →∞ ˜ b t /µ = b /µ w . h . p . , q t will ev entually track b /µ and deviate by a distance B = Θ( 1 √ µ ) , which based on the Foster -L yapunov Criterion implies that the steady state of Markov chain { q t } exists [37]. A rigorous proof of this claim follows the lines of [17, Theorem 1], which is omitted here. 15 G. Pr oof of Theor em 4 Letting ∆( q t ) := 1 2 ( k q t +1 k 2 − k q t k 2 ) denote the L yapunov drift, and squaring the queue update, yields k q t +1 k 2 = k q t k 2 + 2 q > t ( Ax t + c t ) + k Ax t + c t k 2 ( a ) ≤ k q t k 2 + 2 q > t ( Ax t + c t ) + M where (a) follows from the upper bound of k Ax t + c t k 2 . Multiplying both sides by µ/ 2 , and adding Ψ t ( x t ) , leads to µ ∆( q t )+Ψ t ( x t ) = Ψ t ( x t ) + µ q > t ( Ax t + c t ) + µM / 2 ( b ) = Ψ t ( x t ) + ( γ t − λ t + b ) > ( Ax t + c t ) + µM / 2 ( c ) = L t ( x t , γ t ) + ( b − λ t ) > ( Ax t + c t ) + µM / 2 where (b) uses the definition of γ t and (c) is the definition of the instantaneous Lagrangian. T aking expectations ov er s t conditioned on q t , we arrive at µ E [∆( q t )] + E [Ψ t ( x t )] ( d ) = D ( γ t ) + E ( b − λ t ) > ( Ax t + c t ) + µM / 2 ( e ) ≤ Ψ ∗ + E ( b − λ t ) > ( Ax t + c t ) + µM / 2 (73) where (d) follo ws from the definition (11), while (e) uses the weak duality and the fact that ˜ Ψ ∗ ≤ Ψ ∗ . T aking e xpectations on both sides of (73) over q t , summing both sides o ver t = 1 , . . . , T , dividing by T , and letting T → ∞ , we arrive at lim T →∞ (1 /T ) P T t =1 E [Ψ t ( x t )] ( f ) ≤ Ψ ∗ + lim T →∞ (1 /T ) P T t =1 E ( b − λ t ) > ( Ax t + c t ) + µM 2 + lim T →∞ µ k q 1 k 2 2 T ( g ) ≤ Ψ ∗ + lim T →∞ (1 /T ) P T t =1 E ( b − λ t ) > ( Ax t + c t ) + µM 2 (74) where (f) comes from E [ k q T +1 k 2 ] ≥ 0 , and (g) follows because k q 1 k is bounded. What remains to show is that the second term in the RHS of (74) is O ( µ ) . Since λ t con verges to λ ∗ w . h . p . , there always exists a finite T ρ such that for t > T ρ , we hav e k λ ∗ − b − ( λ t − b ) k ≤ ρ, w . h . p . , and thus lim T →∞ (1 /T ) P T t =1 E ( b − λ t ) > ( Ax t + c t ) = lim T →∞ (1 /T ) P T t =1 E h b − λ ∗ + ( λ ∗ − b − λ t + b ) > ( Ax t + c t ) i ( h ) ≤ lim T →∞ (1 /T ) P T t =1 E ( λ ∗ − b ) > ( − Ax t − c t ) + O ( ρ ) ( i ) ≤ k λ ∗ − b k · lim T →∞ (1 /T ) P T t =1 E [ Ax t + c t ] + O ( ρ ) (75) where (h) holds since T ρ < ∞ and k Ax t + c t k is bounded, and (i) follows from the Cauchy-Schwarz inequality . Note that Ax t + c t can be regarded as the service residual per slot t . Since the steady-state queue lengths exist according to Theorem 3, it follo ws readily that there exist constants D 1 = Θ(1 /µ ) , D 2 = Θ( √ µ ) and ˜ B = Θ(1 / √ µ ) , so that 0 ( j ) ≤ lim T →∞ 1 T T X t =1 E [ − Ax t − c t ] ( k ) ≤ 1 · √ M P q t < 1 · √ M ( l ) ≤ 1 · √ M D 1 e − D 2 ( b /µ − ˜ B − √ M ) (76) where (j) holds because all queues are stable (cf. Theorem 3); (k) follo ws since the maximum queue variation is √ M := max t max x t ∈X k Ax t + c t k , and negati ve accumulated service residual may happen only when the queue length q t < √ M ; and (l) comes from the lar ge de viation bound of q t in [17, Lemma 4] and [13, Theorem 4] with the steady-state queue lengths b /µ in Theorem 3. Setting b = √ µ log 2 ( µ ) · 1 , there exists a sufficiently small µ such that − D 2 ( 1 √ µ log 2 ( µ ) − ˜ B − √ M ) ≤ 2 log( µ ) , which implies that lim T →∞ 1 T P T t =1 E [ − Ax t − c t ] ≤ k 1 k · √ M D 1 µ 2 = O ( µ ) . Setting ρ = o ( µ ) , we ha ve [cf. (75)] lim T →∞ 1 T T X t =1 E ( b − λ t ) > ( Ax t + c t ) = O ( µ ) (77) and the proof is complete. R E F E R E N C E S [1] T . Chen, A. Mokhtari, X. W ang, A. Ribeiro, and G. B. Giannakis, “ A data-driv en approach to stochastic network optimization, ” in Proc. IEEE Global Conf. on Signal and Info. Process. , W ashington, DC, Dec. 2016. [2] J. Whitney and P . Delforge, “Data center efficienc y assessment, ” Issue P aper , 2015. [Online]. A vailable: http://www .nrdc.org/energy/ data- center- ef ficiency- assessment.asp [3] P . X. Gao, A. R. Curtis, B. W ong, and S. Keshav , “It’ s not easy being green, ” in Pr oc. ACM SIGCOMM , vol. 42, no. 4, Helsinki, Finland, Aug. 2012, pp. 211–222. [4] Y . Guo, Y . Gong, Y . Fang, P . P . Khargonekar , and X. Geng, “Energy and network a ware w orkload management for sustainable data centers with thermal storage, ” IEEE T rans. P arallel and Distrib. Syst. , vol. 25, no. 8, pp. 2030–2042, Aug. 2014. [5] R. Urgaonkar , B. Urgaonkar , M. Neely , and A. Siv asubramaniam, “Opti- mal power cost management using stored energy in data centers, ” in Proc. ACM SIGMETRICS , San Jose, CA, Jun. 2011, pp. 221–232. [6] T . Chen, X. W ang, and G. B. Giannakis, “Cooling-aware energy and workload management in data centers via stochastic optimization, ” IEEE J. Sel. T opics Signal Process. , vol. 10, no. 2, pp. 402–415, Mar . 2016. [7] Y . Y ao, L. Huang, A. Sharma, L. Golubchik, and M. Neely , “Data centers power reduction: A two time scale approach for delay tolerant workloads, ” in Proc. IEEE INFOCOM , Orlando, FL, Mar . 2012, pp. 1431–1439. [8] T . Chen, Y . Zhang, X. W ang, and G. B. Giannakis, “Rob ust workload and energy management for sustainable data centers, ” IEEE J. Sel. Ar eas Commun. , vol. 34, no. 3, pp. 651–664, Mar . 2016. [9] J. Liu, A. Eryilmaz, N. B. Shrof f, and E. S. Bentley , “Heavy-ball: A new approach to tame delay and conv ergence in wireless network optimization, ” in Pr oc. IEEE INFOCOM , San Francisco, CA, Apr . 2016. [10] B. Li, R. Li, and A. Eryilmaz, “On the optimal conver gence speed of wireless scheduling for fair resource allocation, ” IEEE/ACM T rans. Networking , vol. 23, no. 2, pp. 631–643, Apr . 2015. [11] M. Zargham, A. Ribeiro, and A. Jadbabaie, “ Accelerated backpressure algorithm, ” arXiv preprint:1302.1475 , Feb . 2013. [12] A. Ribeiro, “Ergodic stochastic optimization algorithms for wireless communication and networking, ” IEEE T rans. Signal Pr ocessing , vol. 58, no. 12, pp. 6369–6386, Jul. 2010. [13] L. Huang and M. J. Neely , “Delay reduction via Lagrange multipliers in stochastic network optimization, ” IEEE T rans. Automat. Contr . , v ol. 56, no. 4, pp. 842–857, Apr . 2011. [14] ——, “Utility optimal scheduling in energy-harvesting networks, ” IEEE/ACM T rans. Networking , vol. 21, no. 4, pp. 1117–1130, Aug. 2013. [15] V . V alls and D. J. Leith, “Descent with approximate multipliers is enough: Generalising max-weight, ” arXiv preprint:1511.02517 , Nov . 2015. 16 [16] V . V apnik, The Nature of Statistical Learning Theory . Berlin, Germany: Springer Science & Business Media, 2013. [17] L. Huang, X. Liu, and X. Hao, “The power of online learning in stochastic network optimization, ” in Pr oc. ACM SIGMETRICS , vol. 42, no. 1, New Y ork, NY , Jun. 2014, pp. 153–165. [18] T . Zhang, H. Wu, X. Liu, and L. Huang, “Learning-aided scheduling for mobile virtual network operators with QoS constraints, ” in Pr oc. W iOpt , T empe, AZ, May 2016. [19] A. Defazio, F . Bach, and S. Lacoste-Julien, “SAGA: A fast incremental gradient method with support for non-strongly con vex composite objec- tiv es, ” in Pr oc. Advances in Neural Info. Pr ocess. Syst. , Montreal, Canada, Dec. 2014, pp. 1646–1654. [20] H. Daneshmand, A. Lucchi, and T . Hofmann, “Starting small - learning with adaptiv e sample sizes, ” in Pr oc. Intl. Conf. on Mach. Learn. , New Y ork, NJ, Jun. 2016, pp. 1463–1471. [21] M. J. Neely , “Stochastic netw ork optimization with application to com- munication and queueing systems, ” Synthesis Lectures on Communication Networks , vol. 3, no. 1, pp. 1–211, 2010. [22] H. Xu and B. Li, “Joint request mapping and response routing for geo- distributed cloud services, ” in Pr oc. IEEE INFOCOM , Turin, Italy , Apr . 2013, pp. 854–862. [23] S. Sun, M. Dong, and B. Liang, “Distributed real-time power balancing in renew able-integrated power grids with storage and flexible loads, ” IEEE T rans. Smart Grid , vol. 7, no. 5, pp. 2337–2349, Sep. 2016. [24] N. Gatsis, A. Ribeiro, and G. B. Giannakis, “ A class of conver gent algorithms for resource allocation in wireless fading networks, ” IEEE T rans. Wir eless Commun. , vol. 9, no. 5, pp. 1808–1823, May 2010. [25] J. Gregoire, X. Qian, E. Frazzoli, A. de La Fortelle, and T . W ongpirom- sarn, “Capacity-aware backpressure traf fic signal control, ” IEEE T rans. Contr ol of Network Systems , vol. 2, no. 2, pp. 164–173, June 2015. [26] D. P . Bertsekas, Nonlinear Pr ogramming . Belmont, MA: Athena scientific, 1999. [27] H. Robbins and S. Monro, “ A stochastic approximation method, ” Annals of Mathematical Statistics , vol. 22, no. 3, pp. 400–407, Sep. 1951. [28] V . K ong and X. Solo, Adaptive Signal Processing Algorithms . Upper Saddle River , NJ: Prentice Hall, 1995. [29] T . Chen, A. G. Marques, and G. B. Giannakis, “DGLB: Distributed stochastic geographical load balancing over cloud networks, ” IEEE T rans. P arallel and Distrib. Syst. , to appear, 2017. [30] A. Eryilmaz and R. Srikant, “Joint congestion control, routing, and MA C for stability and fairness in wireless networks, ” IEEE J. Sel. Areas Commun. , vol. 24, no. 8, pp. 1514–1524, Aug. 2006. [31] L. Georgiadis, M. Neely , and L. T assiulas, “Resource allocation and cross- layer control in wireless networks, ” F ound. and T rends in Networking , vol. 1, pp. 1–144, 2006. [32] N. L. Roux, M. Schmidt, and F . R. Bach, “ A stochastic gradient method with an exponential conv ergence rate for finite training sets, ” in Proc. Advances in Neural Info. Pr ocess. Syst. , Dec. 2012, pp. 2663–2671. [33] O. Bousquet and L. Bottou, “The tradeoffs of lar ge scale learning, ” in Pr oc. Advances in Neural Info. Process. Syst. , Dec. 2008, pp. 161–168. [34] A. Mokhtari, H. Daneshmand, A. Lucchi, T . Hofmann, and A. Ribeiro, “ Adaptive Newton method for empirical risk minimization to statistical accuracy , ” in Proc. Advances in Neural Info. Pr ocess. Syst. , Barcelona, Spain, Dec. 2016, pp. 4062–4070. [35] H. Y u and M. J. Neely , “ A low complexity algorithm with O ( √ T ) regret and constraint violations for online conve x optimization with long term constraints, ” arXiv preprint:1604.02218 , Apr . 2016. [36] J. Koshal, A. Nedic, and U. V . Shanbhag, “Multiuser optimization: distributed algorithms and error analysis, ” SIAM J. Optimization , vol. 21, no. 3, pp. 1046–1081, Jul. 2011. [37] S. P . Meyn and R. L. T weedie, Markov Chains and Stochastic Stability . Berlin, Germany: Springer Science & Business Media, 2012.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment