대규모 데이터셋을 위한 빠른 베이지안 하이퍼파라미터 최적화
Fabolas는 데이터셋 크기를 변수로 활용해 손실과 학습 시간을 모델링하고, 정보 이득 대비 비용을 최적화하는 획득 함수를 통해 작은 부분집합에서 빠르게 탐색한 뒤 전체 데이터에 대한 최적 하이퍼파라미터를 효율적으로 찾아낸다. 실험 결과 SVM과 딥러닝 모델에서 기존 베이지안 최적화 및 Hyperband보다 10배에서 100배 빠르게 높은 성능을 달성한다.
저자: Aaron Klein, Stefan Falkner, Simon Bartels
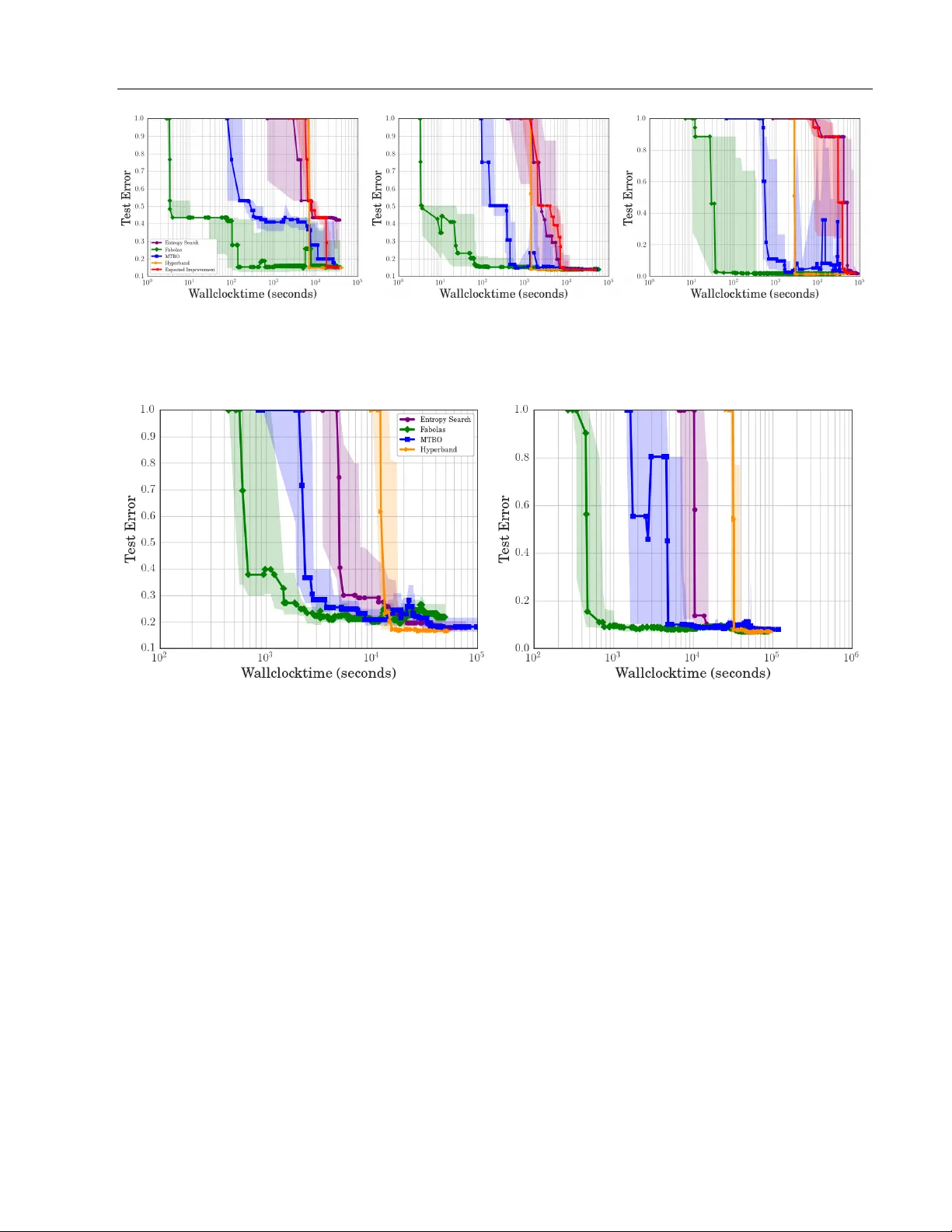
베이지안 최적화는 최근 머신러닝 하이퍼파라미터 튜닝에서 표준 기법으로 자리 잡았지만, 데이터셋 규모가 커짐에 따라 단일 실험에 소요되는 시간이 급증한다는 실질적인 제약이 있다. 기존 방법들은 전체 데이터에 대해 직접 평가하거나, 고정된 소규모 서브셋을 사용해 성능을 추정한다. 이러한 접근은 비용 대비 효율성이 낮으며, 특히 딥러닝과 같이 학습 시간이 수시간에서 수일에 이르는 경우 최적화가 사실상 불가능에 가까워진다.
본 논문은 이러한 문제를 해결하기 위해 데이터셋 크기 s (전체 대비 비율)를 연속적인 환경 변수로 도입하고, 손실 f(x,s)와 학습 시간 c(x,s)를 각각 가우시안 프로세스(GP)로 모델링한다. 손실 GP는 φ_f(s) = (1, (1‑s)^2) 라는 2차 베이스 함수를 사용해 s 가 증가함에 따라 손실이 감소하는 단조성을 강제한다. 학습 시간 GP는 로그 변환 후 φ_c(s) = (1, s) 를 사용해 비용이 s 에 비례하는 다항식 형태를 학습한다. 두 GP는 표준 하이퍼파라미터 공간에 대한 Matérn 5/2 커널과 s 에 대한 베이스 함수의 곱 형태인 팩터라이즈드 커널로 결합된다. 이 구조는 작은 서브셋에서도 충분히 정확한 예측을 가능하게 하며, 전체 데이터에 대한 직접 평가 없이도 최적 하이퍼파라미터를 추정할 수 있게 한다.
획득 함수는 정보 이득 대비 비용을 최적화하는 형태로 설계된다. 구체적으로, Entropy Search(ES) 기반의 정보 이득 I(x,s) 를 계산하고, 이를 현재 예상 비용 c(x,s) + c_overhead 으로 나눈다. 즉, a_F(x,s) = I(x,s) / (c(x,s)+c_overhead) 이다. 여기서 c_overhead 은 GP 재학습, 획득 함수 최적화 등 부가 연산에 소요되는 시간을 포함한다. 이 획득 함수를 최적화함으로써 알고리즘은 “단위 시간당 가장 큰 정보”를 제공하는 (x,s) 쌍을 선택한다.
알고리즘 흐름은 다음과 같다. 첫 단계에서 무작위 초기 디자인을 수행해 다양한 s 값(보통 로그 스케일)에서 몇 개의 하이퍼파라미터 조합을 평가한다. 이후 매 반복마다 손실과 비용 GP를 최신 데이터로 업데이트하고, 위의 획득 함수를 최대화하는 (x,s) 를 찾는다. 선택된 (x,s) 에 대해 실제 모델을 학습·검증하고, 결과를 데이터베이스에 추가한다. 이 과정을 예산이 소진될 때까지 반복한다. 최종적으로는 s=1 (전체 데이터)에서의 최적 x 를 추정한다.
실험에서는 두 가지 주요 도메인, 즉 서포트 벡터 머신(SVM)과 딥 뉴럴 네트워크(DNN)를 대상으로 평가했다. SVM 실험에서는 MNIST 데이터의 50,000 샘플을 사용해 s 를 1/512부터 1까지 다양한 비율로 샘플링했다. 결과는 1/128 정도의 서브셋만으로도 전체 데이터와 유사한 손실 곡선을 얻을 수 있음을 보여준다. 딥러닝 실험에서는 CIFAR‑10, SVHN, Fashion‑MNIST 등에서 ResNet‑18, Wide‑ResNet 등 다양한 아키텍처를 최적화했으며, Fabolas는 Hyperband, SMAC, Spearmint 등 기존 최적화 기법 대비 10배에서 100배 빠른 수렴 속도를 보였다. 특히, Hyperband가 무작위 샘플링 기반으로 “리소스 할당”을 수행하는 반면, Fabolas는 베이지안 모델을 통해 사전 지식을 활용해 더 효율적인 탐색을 수행한다는 점이 강조된다.
또한, 논문은 멀티태스크 베이지안 최적화(MTBO)와의 비교를 통해 차별점을 명확히 한다. MTBO는 데이터 크기를 이산적인 태스크로 모델링해 각 태스크 간 상관관계를 학습하지만, 전체 데이터에 대한 정확한 예측을 위해서는 모든 태스크를 평가해야 하는 제약이 있다. 반면 Fabolas는 연속적인 s 에 대한 커널을 사용해 직접적인 외삽을 수행함으로써, 전체 데이터에 대한 평가 없이도 충분히 정확한 최적값을 추정한다.
결론적으로, 이 논문은 “데이터 양”이라는 새로운 자유도를 도입함으로써 대규모 머신러닝 모델의 하이퍼파라미터 최적화를 실용적인 수준으로 끌어올린다. 비용 효율적인 탐색 전략은 클라우드 기반 학습, 제한된 GPU 자원, 혹은 빠른 프로토타이핑이 요구되는 산업 현장에서 특히 유용하며, 향후 자동 머신러닝(AutoML) 파이프라인에 쉽게 통합될 수 있다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기