Fast Bayesian Optimization of Machine Learning Hyperparameters on Large Datasets
Bayesian optimization has become a successful tool for hyperparameter optimization of machine learning algorithms, such as support vector machines or deep neural networks. Despite its success, for large datasets, training and validating a single conf…
Authors: Aaron Klein, Stefan Falkner, Simon Bartels
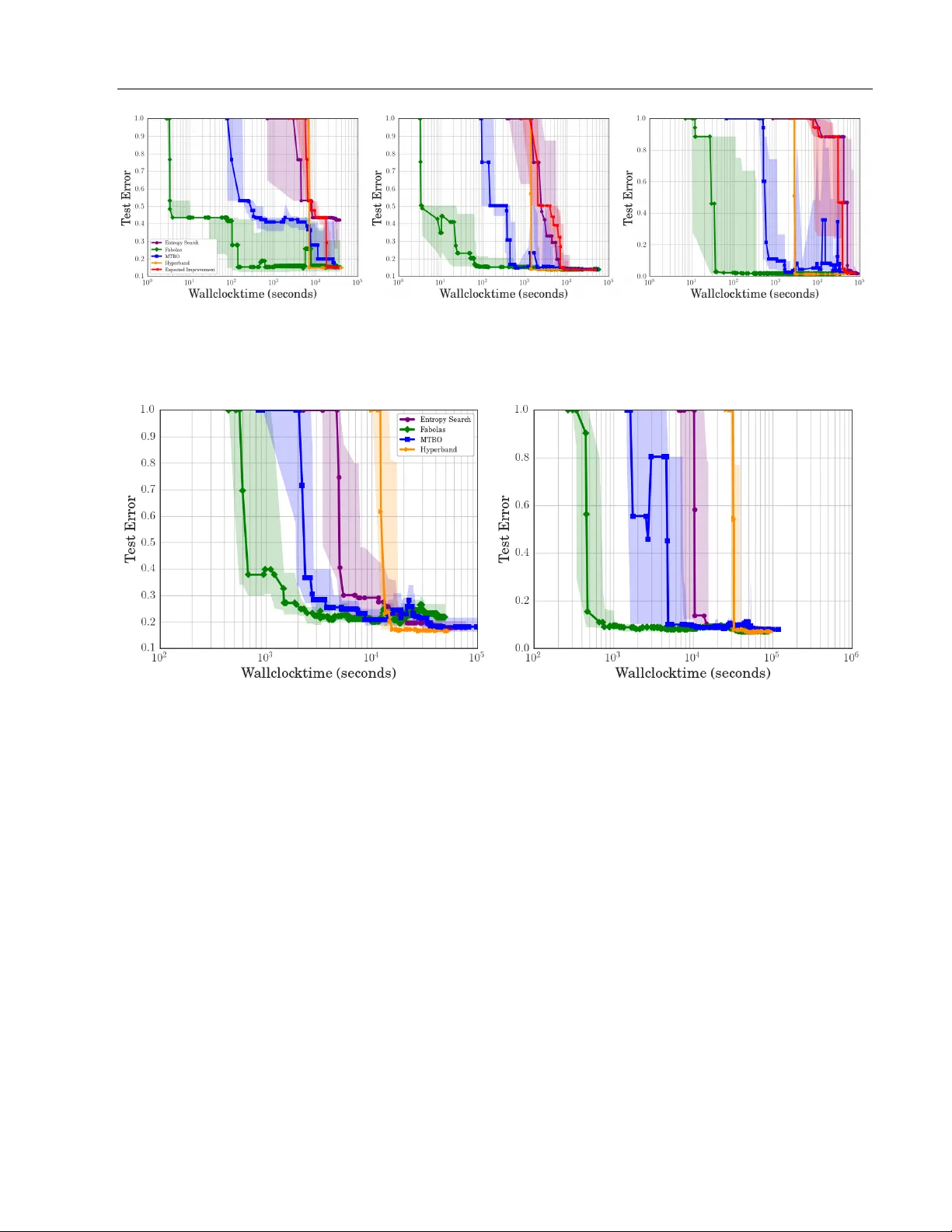
F ast Bayesian Optimization of Machine Lear ning Hyperparameters on Large Datasets Aaron Klein 1 Stefan Falkner 1 Simon Bartels 2 Philipp Hennig 2 Frank Hutter 1 1 {kleinaa, sfalkner , fh}@cs.uni-freib urg.de Department of Computer Science Univ ersity of Freibur g 2 {simon.bartels, phennig}@tuebingen.mpg.de Department of Empirical Inference Max Planck Institute for Intelligent Systems Abstract Bayesian optimization has become a successful tool for hyperparameter optimization of machine learning algorithms, such as support vector ma- chines or deep neural networks. Despite its suc- cess, for large datasets, training and v alidating a single configuration often takes hours, days, or ev en weeks, which limits the achievable perfor- mance. T o accelerate hyperparameter optimiza- tion, we propose a generative model for the valida- tion error as a function of training set size, which is learned during the optimization process and al- lo ws exploration of preliminary configurations on small subsets, by extrapolating to the full dataset. W e construct a Bayesian optimization procedure, dubbed F A B O L A S , which models loss and train- ing time as a function of dataset size and auto- matically trades of f high information gain about the global optimum against computational cost. Experiments optimizing support vector machines and deep neural networks show that F A B O L A S often finds high-quality solutions 10 to 100 times faster than other state-of-the-art Bayesian opti- mization methods or the recently proposed bandit strategy Hyperband. 1 Introduction The performance of many machine learning algorithms hinges on certain hyperparameters. For example, the pre- diction error of non-linear support vector machines depends on regularization and kernel hyperparameters C and γ ; and modern neural networks are sensitiv e to a wide range of hy- perparameters, including learning rates, momentum terms, Proceedings of the 20 th International Conference on Artificial In- telligence and Statistics (AIST A TS) 2017, Fort Lauderdale, Florida, USA. JMLR: W&CP volume 54. Copyright 2017 by the author(s). number of units per layer , dropout rates, weight decay , etc. (Montav on et al., 2012). The poor scaling of naïve methods like grid search with dimensionality has driv en interest in more sophisticated hyperparameter optimization methods ov er the past years (Bergstra et al., 2011; Hutter et al., 2011; Bergstra and Bengio, 2012; Snoek et al., 2012; Bardenet et al., 2013; Ber gstra et al., 2013; Swersky et al., 2013, 2014; Snoek et al., 2015). Bayesian optimization has emerged as an efficient framework, achieving impressiv e successes. For example, in se veral studies, it found bet- ter instantiations of conv olutional network hyperparameters than domain experts, repeatedly improving the top score on the CIF AR-10 (Krizhevsk y, 2009) benchmark without data augmentation (Snoek et al., 2012; Domhan et al., 2015; Snoek et al., 2015). In the traditional setting of Bayesian hyperparameter op- timization, the loss of a machine learning algorithm with hyperparameters x ∈ X is treated as the “black-box” prob- lem of finding arg min x ∈ X f ( x ) , where the only mode of interaction with the objective f is to ev aluate it for inputs x ∈ X . If indi vidual ev aluations of f on the entire dataset re- quire days or weeks, only very few e v aluations are possible, limiting the quality of the best found value. Human experts instead often study performance on subsets of the data first, to become familiar with its characteristics before gradually increasing the subset size (Bottou, 2012; Montavon et al., 2012). This approach can still outperform contemporary Bayesian optimization methods. Motiv ated by the experts’ strate gy , here we lev erage dataset size as an additional degree of freedom enriching the repre- sentation of the optimization problem. W e treat the size of a randomly subsampled dataset N sub as an additional input to the blackbox function, and allo w the optimizer to activ ely choose it at each function ev aluation. This allows Bayesian optimization to mimic and improv e upon human experts when exploring the hyperparameter space. In the end, N sub is not a hyperparameter itself, b ut the goal remains a good performance on the full dataset, i.e. N sub = N . Hyperparameter optimization for large datasets has been explored by other authors before. Our approach is similar to F A B O L A S : Fast Bayesian Optimization of Machine Learning Hyperparameters on Large Datasets Multi-T ask Bayesian optimization by Swersky et al. (2013), where knowledge is transferred between a finite number of correlated tasks. If these tasks represent manually-chosen subset-sizes, this method also tries to find the best config- uration for the full dataset by evaluating smaller , cheaper subsets. Ho wev er , the discrete nature of tasks in that ap- proach requires e valuations on the entire dataset to learn the necessary correlations. Instead, our approach exploits the regularity of performance across dataset size, enabling gen- eralization to the full dataset without ev aluating it directly . Other approaches for hyperparameter optimization on large datasets include work by Nickson et al. (2014), who es- timated a configuration’ s performance on a lar ge dataset by ev aluating several training runs on small, random sub- sets of fixed, manually-chosen sizes. Krueger et al. (2015) showed that, in practical applications, small subsets can suffice to estimate a configuration’ s quality , and proposed a cross-validation scheme that sequentially tests a fixed set of configurations on a gro wing subset of the data, discarding poorly-performing configurations early . In parallel work 1 , Li et al. (2017) proposed a multi-arm ban- dit strategy , called Hyperband, which dynamically allocates more and more resources to randomly sampled configura- tions based on their performance on subsets of the data. Hyperband assures that only well-performing configura- tions are trained on the full dataset while discarding bad ones early . Despite its simplicity , in their experiments the method was able to outperform well-established Bayesian optimization algorithms. In §2, we revie w Bayesian optimization, in particular the Entropy Search algorithm and the related method of Multi- T ask Bayesian optimization. In §3, we introduce our new Bayesian optimization method F A B O L A S for hyperparame- ter optimization on large datasets. In each iteration, F A B O - L A S chooses the configuration x and dataset size N sub pre- dicted to yield most information about the loss-minimizing configuration on the full dataset per unit time spent . In §4, a broad range of experiments with support vector machines and v arious deep neural networks sho w F A B O L A S often identifies good hyperparameter settings 10 to 100 times faster than state-of-the-art Bayesian optimization methods acting on the full dataset as well as Hyperband. 2 Bayesian optimization Giv en a black-box function f : X → R , Bayesian opti- mization 2 aims to find an input x ? ∈ arg min x ∈ X f ( x ) that globally minimizes f . It requires a prior p ( f ) ov er the func- tion and an acquisition function a p ( f ) : X → R quantifying 1 Hyperband was first described in a 2016 arXi v paper (Li et al., 2016), and F AB O L A S was first described in a 2015 NIPS workshop paper (Klein et al.) 2 Comprehensiv e tutorials are presented by Brochu et al. (2010) and Shahriari et al. (2016). the utility of an ev aluation at any x . W ith these ingredi- ents, the follo wing three steps are iterated (Brochu et al., 2010): (1) find the most promising x n +1 ∈ arg max a p ( x ) by numerical optimization; (2) e v aluate the expensi ve and often noisy function y n +1 ∼ f ( x n +1 ) + N (0 , σ 2 ) and add the resulting data point ( x n +1 , y n +1 ) to the set of obser- vations D n = ( x j , y j ) j =1 ...n ; and (3) update p ( f | D n +1 ) and a p ( f |D n +1 ) . T ypically , ev aluations of the acquisition function a are cheap compared to ev aluations of f such that the optimization effort is ne gligible. 2.1 Gaussian Processes Gaussian processes (GP) are a prominent choice for p ( f ) , thanks to their descriptive power and analytic tractability (e.g. Rasmussen and W illiams, 2006). Formally , a GP is a collection of random variables, such that e very finite subset of them follows a multiv ariate normal distribution. A GP is identified by a mean function m (often set to m ( x ) = 0 ∀ x ∈ X ), and a positiv e definite covariance function (kernel) k . Gi ven observations D n = ( x j , y j ) j =1 ...n = ( X , y ) with joint Gaussian likelihood p ( y | X , f ( X )) , the posterior p ( f |D n ) follows another GP , with mean and cov ariance functions of tractable, analytic form. The cov ariance function determines how observ ations influ- ence the prediction. For the hyperparameters we wish to optimize, we adopt the Matérn 5 / 2 kernel (Matérn, 1960), in its Automatic Relev ance Determination form (MacKay and Neal, 1994). This stationary , twice-dif ferentiable model constitutes a relati vely standard choice in the Bayesian op- timization literature. In contrast to the Gaussian kernel popular else where, it makes less restricti ve smoothness as- sumptions, which can be helpful in the optimization setting (Snoek et al., 2012): k 5 / 2 ( x , x 0 ) = θ 1 + √ 5 d λ ( x , x 0 ) + 5 / 3 d 2 λ ( x , x 0 ) e − √ 5 d λ ( x , x 0 ) . (1) Here, θ and λ are free parameters—hyperparameters of the GP surrogate model—and d λ ( x , x 0 ) = ( x − x 0 ) T diag( λ )( x − x 0 ) is the Mahalanobis distance. For the dataset size dependent performance and cost, we construct a custom kernel in 3.1. An additional hyperparameter of the GP model is a overall noise cov ariance needed to handle noisy observations. For clarity: These GP hyperparameters are internal hyperparameters of the Bayesian optimizer , as opposed to those of the tar get machine learning algorithm to be tuned. Section 3.4 sho ws how we handle them. 2.2 Acquisition functions The role of the acquisition function is to trade of f exploration vs. exploitation. Popular choices include Expected Improv e- ment (EI) (Mockus et al., 1978), Upper Confidence Bound Aaron Klein, Stefan Falkner , Simon Bartels, Philipp Hennig, Frank Hutter (UCB) (Sriniv as et al., 2010), Entropy Search (ES) (Hen- nig and Schuler, 2012), and Predicti ve Entropy Search (PES) (Hernández-Lobato et al., 2014). In our experiments, we will use EI and ES. W e found EI to perform robustly in most applications, pro- viding a solid baseline; it is defined as a EI ( x |D n ) = E p [max( f min − f ( x ) , 0)] . (2) where f min is the best function value kno wn (also called the incumbent ). This expected drop ov er the best known v alue is high for points predicted to hav e small mean and/or large variance. ES is a more recent acquisition function that selects ev alua- tion points based on the predicted information gain about the optimum, rather than aiming to ev aluate near the opti- mum. At the heart of ES lies the probability distribution p min ( x | D ) := p ( x ∈ arg min x 0 ∈ X f ( x 0 ) | D ) , the belief about the function’ s minimum given the prior on f and ob- serv ations D . The information gain at x is then measured by the expected K ullback-Leibler div ergence (relati ve entropy) between p min ( · | D ∪ { ( x , y ) } ) and the uniform distribution u ( x ) , with e xpectations taken o ver the measurement y to be obtained at x : a ES ( x ) : = E p ( y | x , D ) Z p min ( x 0 | D ∪ { ( x , y ) } ) · log p min ( x 0 | D ∪ { ( x , y ) } ) u ( x 0 ) d x 0 . (3) The primary numerical challenge in this framew ork is the computation of p min ( · | D ∪ { ( x , y ) } ) and the integral abov e. Due to the intractability , sev eral approximations hav e to be made. W e refer to Hennig and Schuler (2012) for details, as well as to the supplemental material (Section A), where we also provide pseudocode for our implementation. Despite the conceptual and computational comple xity of ES, it offers a well-defined concept for information gained from function ev aluations, which can be meaningfully traded off against other quantities, such as the e valuations’ cost. PES refers to the same acquisition function, but uses dif- ferent approximations to compute it. In Section 3.4 we describe why , for our application, ES was the more direct choice. 2.3 Multi-T ask Bayesian optimization The Multi-T ask Bayesian optimization (MTBO) method of Swersky et al. (2013) refers to a general framew ork for optimizing in the presents of dif ferent, but correlated tasks. Giv en a set of such tasks T = { 1 , . . . , T } , the objectiv e function f : X × T → R corresponds to ev aluating a gi ven x ∈ X on one of the tasks t ∈ T . The relation between points in X × T is modeled via a GP using a product kernel: k MT (( x , t ) , ( x 0 , t 0 )) = k T ( t, t 0 ) · k 5 / 2 ( x , x 0 ) . (4) The kernel k T is represented implicitly by the Cholesky decomposition of k ( T , T ) whose entries are sampled via MCMC together with the other hyperparameters of the GP . By considering the distribution ov er the optimum on the target task t ∗ ∈ T , p t ∗ min ( x | D ) := p ( x ∈ arg min x 0 ∈ X f ( x 0 , t = t ∗ ) | D ) , and computing any in- formation w .r .t. it, Swersky et al. (2013) use the information gain per unit cost as their acquisition function 3 : a MT ( x , t ) : = 1 c ( x , t ) E p ( y | x ,t, D ) Z p t ∗ min ( x 0 | D 0 ) · log p t ∗ min ( x 0 | D 0 ) u ( x 0 ) d x 0 , (5) where D 0 = D ∪ { ( x , t, y ) } . The expectation represents the information gain on the target task av eraged ov er the possible outcomes of f ( x , t ) based on the current model. If the cost c ( x , t ) of a configuration x on task t is not kno wn a priori it can be modelled the same way as the objectiv e function. This model supports machine learning hyperparameter op- timization for large datasets by using discrete dataset sizes as tasks. Swersky et al. (2013) indeed studied this approach for the special case of T = { 0 , 1 } , representing a small and a large dataset; this will be a baseline in our e xperiments. 3 F ast Bayesian optimization for large datasets Here, we introduce our new approach for F Ast Bayesian Optimization on LArge data Sets ( F A B O L A S ). While tradi- tional Bayesian hyperparameter optimizers model the loss of machine learning algorithms on a giv en dataset as a black- box function f to be minimized, F A B O L A S models loss and computational cost acr oss dataset size and uses these mod- els to carry out Bayesian optimization with an extra degree of freedom. The blackbox function f : X × R → R now takes another input representing the data subset size; we will use relativ e sizes s = N sub / N ∈ [0 , 1] , with s = 1 representing the entire dataset. While the ev entual goal is to minimize the loss f ( x , s = 1) for the entire dataset, ev aluating f for smaller s is usually cheaper , and the func- tion v alues obtained correlate across s . Unfortunately , this correlation structure is initially unkno wn, so the challenge is to design a strategy that trades off the cost of function ev aluations against the benefit of learning about the scaling behavior of f and, ultimately , about which configurations work best on the full dataset. Follo wing the nomenclature of 3 In fact, Swersk y et al. (2013) de viated slightly from this for - mula (which follo ws the ES approach of Hennig and Schuler (2012)) by considering the difference in information gains in p t ∗ min ( x | D ) and p t ∗ min ( x | D ∪ { ( x , y ) } ) . They stated this to work better in practice, but we did not find evidence for this in our experiments and thus, for consistency , use the variant presented here throughout. F A B O L A S : Fast Bayesian Optimization of Machine Learning Hyperparameters on Large Datasets W illiams et al. (2000), we call s ∈ [0 , 1] an en vir onmental variable that can be changed freely during optimization, b ut that is set to s = 1 (i.e., the entire dataset size), at ev aluation time. W e propose a principled rule for the automatic selection of the next ( x , s ) pair to e v aluate. In a nutshell, where standard Bayesian optimization would always run configurations on the full dataset, we use ES to reason about, how much can be learned about performance on the full dataset from an ev aluation at any s . In doing so, F A B O L A S automatically determines the amount of data necessary to (usefully) ex- trapolate to the full dataset. For an initial intuition on how performance changes with dataset size, we e valuated a grid of 400 configurations of a support vector machine (SVM) on subsets of the MNIST dataset (LeCun et al., 2001) ; MNIST has N = 50 000 data points and we ev aluated relativ e subset sizes s ∈ { 1 / 512 , 1 / 256 , 1 / 128 , . . . , 1 / 4 , 1 / 2 , 1 } . Figure 1 visualizes the validation error of these configurations on s = 1 / 128 , 1 / 16 , 1 / 4 , and 1 . Evidently , just 1 / 128 of the dataset is quite repre- sentativ e and sufficient to locate a reasonable configuration. Additionally , there are no deceiving local optima on smaller subsets. Based on these observ ations, we expect that rel- ativ ely small fractions of the dataset yield representativ e performances and therefore vary our relati ve size parameter s on a logarithmic scale. 3.1 Ker nels for loss and computational cost T o transfer the insights from this illustrativ e example into a formal model for the loss and cost across subset sizes, we extend the GP model by an additional input dimension, namely s ∈ [0 , 1] . This allo ws the surrogate to extrapolate to the full data set at s = 1 without necessarily ev aluating there. W e chose a factorized kernel, consisting of the standard stationary kernel over hyperparameters, multiplied with a finite-rank (“degenerate”) co variance function in s : k (( x , s ) , ( x 0 , s 0 )) = k 5 / 2 ( x , x 0 ) · φ T ( s ) · Σ φ · φ ( s 0 ) . (6) Since any choice of the basis function φ yields a positiv e semi-definite covariance function, this provides a flexible language for prior kno wledge relating to s . W e use the same form of kernel to model the loss f and cost c , respecti vely , but with dif ferent basis functions φ f and φ c . The loss of a machine learning algorithms usually decreases with more training data. W e incorporate this behavior by choosing φ f ( s ) = (1 , (1 − s ) 2 ) T to enforce monotonic predictions with an extremum at s = 1 . This kernel choice is equi valent to Bayesian linear re gression with these basis functions and Gaussian priors on the weights. T o model computational cost c , we note that the complexity usually grows with relati ve dataset size s . T o fit polynomial complexity O ( s α ) for arbitrary α and simultaneously en- force positiv e predictions, we model the log-cost and use φ c ( s ) = (1 , s ) T . As abov e, this amounts to Bayesian linear regression with sho wn basis functions. In the supplemental material (Section B), we visualize scal- ing of loss and cost with s for the SVM example abov e and show that our kernels indeed fit them well. W e also e valuate the possibility of modelling the heteroscedastic noise in- troduced by subsampling the data (supplementary material, Section C). 3.2 Formal algorithm description F A B O L A S starts with an initial design, described in more detail in Section 3.3. Afterwards, at the be ginning of each iteration it fits GPs for loss and computational cost across dataset sizes s using the kernel from Eq. 6. Then, capturing the distribution of the optimum for s = 1 using p s =1 min ( x | D ) := p ( x ∈ arg min x 0 ∈ X f ( x 0 , s = 1) | D ) , it selects the maximizer of the following acquisition function to trade off information gain versus cost: a F ( x , s ) : = 1 c ( x , s ) + c overhead E p ( y | x ,s, D ) Z p s =1 min ( x 0 | D ∪ { ( x , s, y ) } ) · (7) log p s =1 min ( x 0 | D ∪ { ( x , s, y ) } ) u ( x 0 ) d x 0 . Algorithm 1 shows pseudocode for F A B O L A S . W e also provide an open-source implementation at https://github .com/automl/RoBO. Algorithm 1 Fast BO for Lar ge Datasets (F A B O L A S ) 1: Initialize data D 0 using an initial design. 2: for t = 1 , 2 , . . . do 3: Fit GP models for f ( x , s ) and c ( x , s ) on data D t − 1 4: Choose ( x t , s t ) by maximizing the acquisition func- tion in Equation 7. 5: Ev aluate y t ∼ f ( x t , s t ) + N (0 , σ 2 ) , also measuring cost z t ∼ c ( x t , s t ) + N (0 , σ 2 c ) , and augment the data: D t = D t − 1 ∪ { ( x t , s t , y t , z t ) } 6: Choose incumbent ˆ x t based on the predicted loss at s = 1 of all { x 1 , x 2 , . . . , x t } . 7: end f or Our proposed acquisition function resembles the one used by MTBO (Eq. 5), with two differences: First, MTBO’ s discrete tasks t are replaced by a continuous dataset size s (allowing to learn correlations without e v aluations at s = 1 , and to choose the appropriate subset size automatically). Second, the prediction of computational cost is augmented by the overhead of the Bayesian optimization method. This inclusion of the reasoning overhead is important to appropri- ately reflect the information gain per unit time spent: it does Aaron Klein, Stefan Falkner , Simon Bartels, Philipp Hennig, Frank Hutter (a) s = 1 / 128 (b) s = 1 / 16 (c) s = 1 / 4 (d) s = 1 Figure 1: V alidation error of a grid of 400 SVM configurations (20 settings of each of the re gularization parameter C and kernel parameter γ , both on a log-scale in [ − 10 , 10] ) for subsets of the MNIST dataset (LeCun et al., 2001) of various sizes N sub . Small subsets are quite representati ve: The validation error of bad configuration (yello w) remains constant at around 0 . 9 , whereas the region of good configurations (blue) does not change drastically with s . not matter whether the time is spent with a function ev alua- tion or with reasoning about which ev aluation to perform. In practice, due to cubic scaling in the number of data points of GPs and the computational complexity of approximating p s =1 min , the additional ov erhead of F A B O L A S is within the or- der of minutes, such that dif ferences in computational cost in the order of seconds become negligible in comparison. 4 Being an anytime algorithm, F A B O L A S keeps track of its incumbent at each time step. T o select a configuration that performs well on the full dataset, it predicts the loss of all ev aluated configurations at s = 1 using the GP model and picks the minimizer . W e found this to w ork more robustly than globally minimizing the posterior mean, or similar approaches. 3.3 Initial design It is common in Bayesian optimization to start with an initial design of points chosen at random or from a Latin hyper- cube design to allo w for reasonable GP models as starting points. T o fully lev erage the speedups we can obtain from ev aluating small datasets, we bias this selection towards points with small (cheap) datasets in order to improv e the prediction for dependencies on s : W e draw k random points in X ( k = 10 in our experiments) and ev aluate them on dif ferent subsets of the data (for instance on the support vec- tor machine experiments we used s ∈ { 1 / 64 , 1 / 32 , 1 / 16 , 1 / 8 } ). This provides information on scaling beha vior , and, assum- ing that costs increase linearly or superlinearly with s , these k function ev aluations cost less than k 8 function ev aluations on the full dataset. This is important as the cost of the initial design, of course, counts tow ards F A B O L A S ’ runtime. 4 The same is true for standard ES and MTBO, but w as nev er exploited as no emphasis was put on the total wall clock time spent for the hyperparameter optimization. W e want to emphasize that we express b udgets in terms of wall clock time (not function ev aluations) since this is natural in most practical applications. 3.4 Implementation details The presentation of F A B O L A S abov e omits some details that impact the performance of our method. As it has be- come standard in Bayesian optimization (Snoek et al., 2012), we use Marko v-Chain Monte Carlo (MCMC) integration to marginalize over the GPs hyperparameters (we use the emcee package (F oreman-Mackey et al., 2013)). T o accel- erate the optimization, we use hyper -priors to emphasize meaningful v alues for the parameters, chiefly adopting the choices of the S P E A R M I N T toolbox (Snoek et al., 2012): a uniform prior between [ − 10 , 2] for all length scales λ in log space, a lognormal prior ( µ a = 0 , σ 2 a = 1 ) for the covari- ance amplitude θ , and a horseshoe prior with length scale of 0 . 1 for the noise variance σ 2 . W e used the original formulation of ES by Hennig and Schuler (2012) rather than the recent reformulation of PES by Hernández-Lobato et al. (2014). The main reason for this is that the latter prohibits non-stationary kernels due to its use of Bochner’ s theorem for a spectral approximation. PES could in principle be extended to work for our particular choice of kernels (using an Eigen-expansion, from which we could sample features); since this would complicate making modifications to our kernel, we leave it as an a venue for future work, but note that in any case it may only further improv e our method. T o maximize the acquisition function we used the blackbox optimizer DIRECT (Jones, 2001) and CMAES (Hansen, 2006). 4 Experiments For our empirical ev aluation of F A B O L A S , we compared it to standard Bayesian optimization (using EI and ES as acquisition functions), MTBO, and Hyperband. For each method, we track ed wall clock time (counting both optimiza- tion overhead and the cost of function e v aluations, including the initial design), storing the incumbent returned after e v- ery iteration. In an of fline validation step, we then trained models with all incumbents on the full dataset and measured F A B O L A S : Fast Bayesian Optimization of Machine Learning Hyperparameters on Large Datasets Figure 2: Evaluation on SVM grid on MNIST . (Left) Baseline comparison of test performance of the methods’ selected incumbents o ver time. (Middle) T est performance over time for variants of MTBO with different dataset sizes for the auxiliary task. (Right) Dataset size F A B O L A S and MTBO pick in each iteration to trade off small cost and high information gain; unlike else where in the paper , this right plot shows mean ± 1 / 4 stddev of 30 runs (medians would only take two v alues for MTBO). their test error . W e plot these test errors throughout. 5 T o obtain error bars, we performed 10 independent runs of each method with dif ferent seeds (except on the grid e x- periment, where we could af ford 30 runs per method) and plot medians, along with 25 th and 75 th percentiles for all experiments. Details on the hyperparameter ranges used in ev ery experiment are gi ven in the supplemental material (Section D). W e implemented Hyperband following Li et al. (2017) using the recommended setting for the parameter η = 3 that con- trols the intermediate subset sizes. For each experiment, we adjusted the b udget allocated to each Hyperband iteration to allow the same minimum dataset size as for F A B O L A S : 10 times the number of classes for the support vector machine benchmarks and the maximum batch size for the neural network benchmarks. W e also followed the prescribed in- cumbent estimation after each iteration as the configuration with the best performance on the full dataset size. 4.1 Support vector machine grid on MNIST First, we considered a benchmark allowing the comparison of the various Bayesian optimization methods on ground truth: our SVM grid on MNIST (described in Section 3), for which we had performed all function ev aluations be- forehand, measuring loss and cost 10 times for each con- figuration x and subset size s to account for performance variations. (In this case, we computed each method’ s wall clock time in each iteration as its summed optimization over - heads so far , plus the summed costs for the function v alues it queried so far .) MTBO requires choosing the number of data points in its auxiliary task. Figure 2 (middle) e v aluates MTBO vari- 5 The residual network in Section 4.4 is an exception: here, we trained networks with the incumbents on the full training set (50000 data points, augmented to 100000 as in the original code) and then measured and plotted performance on the validation set. ants with a single auxiliary task with a relativ e size of 1 / 4 , 1 / 32 , and 1 / 512 , respectively . W ith auxiliary tasks at either s = 1 / 512 or 1 / 32 , MTBO improv ed quickly , but con v erged more slowly to the optimum; we believe small correlations between the tasks cause this. Figure 2 (right) shows the dataset sizes chosen by the dif ferent algorithms during the optimization; all methods slowly increased the av erage sub- set size used ov er time. An auxiliary task with s = 1 / 4 worked best and we used this for MTBO in the remaining experiments. At first glance, one might expect many tasks (e.g., with a task for each s ∈ { 1 / 512 , 1 / 256 , . . . , 1 / 2 , 1 } ) to work best, but quite the opposite is true. In preliminary experiments, we ev aluated MTBO with up to 3 auxiliary tasks ( s = 1 / 4 , 1 / 32 , and 1 / 512 ), but found performance to strongly de grade with a gro wing number of tasks. W e suspect that the | T | 2 kernel parameters that hav e to be learned for the discrete task kernel for | T | tasks are the main reason. If the MCMC sampling is too short, the correlations are not appropriately reflected, especially in early iterations, and an adjusted sam- pling creates a large computational o verhead that dominates wall-clock time. W e therefore obtained best performance with only one auxiliary task. Figure 2 (left) shows results using EI, ES, random search, MTBO and FA B O L A S on this SVM benchmark. EI and ES perform equally well and find the best configuration (which yields an error of 0 . 014 , or 1 . 4% ) after around 10 5 sec- onds, roughly fiv e times faster than random search. MTBO achiev es good performance faster , requiring only around 2 × 10 4 seconds to find the global optimum. F A B O L A S is roughly another order of magnitude faster than MTBO in finding good configurations, and finds the global optimum at the same time. Aaron Klein, Stefan Falkner , Simon Bartels, Philipp Hennig, Frank Hutter Figure 3: SVM hyperparameter optimization on the datasets cov ertype (left), vehicle (middle) and MNIST(right). At each time, the plots show test performance of the methods’ respectiv e incumbents. F A B O L A S finds a good configuration between 10 and 1000 times faster than the other methods. Figure 4: T est performance of a con volutional neural netw ork on CIF AR10 (left) and SVHN (right). 4.2 Support vector machines on various datasets For a more realistic scenario, we optimized the same SVM hyperparameters without a grid constraint on MNIST and two other prominent UCI datasets (gathered from OpenML (V anschoren et al., 2014)), vehicle registration (Siebert, 1987) and forest co ver types (Blackard and Dean, 1999) with more than 50000 data points, now also comparing to Hyperband. T raining SVMs on these datasets can take se v- eral hours, and Figure 3 shows that F A B O L A S found good configurations for them between 10 and 1000 times faster than the other methods. Hyperband required a relativ ely long time until it recom- mended its first hyperparameter setting, but this first recom- mendation was already v ery good, making Hyperband sub- stantially faster to find good settings than standard Bayesian optimization running on the full dataset. Howe ver , F A B O - L A S typically returned configurations with the same quality another order of magnitude faster . 4.3 Con volutional neural networks on CIF AR-10 and SVHN Con volutional neural networks (CNNs) hav e shown supe- rior performance on a variety of computer vision and speech recognition benchmarks, b ut finding good hyperparameter settings remains challenging, and almost no theoretical guar- antees exist. Tuning CNNs for modern, large datasets is often infeasible via standard Bayesian optimization; in fact, this motiv ated the de velopment of F A B O L A S . W e experimented with hyperparameter optimization for CNNs on two well-established object recognition datasets, namely CIF AR10 (Krizhevsk y, 2009) and SVHN (Netzer et al., 2011). W e used the same setup for both datasets (a CNN with three con v olutional layers, with batch normal- ization (Iof fe and Szegedy, 2015) in each layer, optimized using Adam (Kingma and Ba, 2014)). W e considered a total of fi ve hyperparameters: the initial learning rate, the batch size and the number of units in each layer . For CIF AR10, we used 40000 images for training, 10000 to estimate validation error , and the standard 10000 hold-out images to estimate F A B O L A S : Fast Bayesian Optimization of Machine Learning Hyperparameters on Large Datasets Figure 5: V alidation performance of a residual network on CIF AR10. the final test performance of incumbents. For SVHN, we used 6000 of the 73257 training images to estimate vali- dation error , the rest for training, and the standard 26032 images for testing. The results in Figure 4 show that—compared to the SVM tasks—F A B O L A S ’ speedup was smaller because CNNs scale linearly in the number of datapoints. Nev ertheless, it found good configurations about 10 times faster than va nilla Bayesian optimization. For the same reason of linear scaling, Hyperband was substantially slo wer than vanilla Bayesian optimization to make a recommendation, but it did find good hyperparameter settings when gi ven enough time. 4.4 Residual neural network on CIF AR-10 In the final experiment, we ev aluated the performance of our method further on a more expensiv e benchmark, optimizing the validation performance of a deep residual netw ork on the CIF AR10 dataset, using the original architecture from He et al. (2015). As hyperparameters we exposed the learning rate, L 2 regularization, momentum and the factor by which the learning rate is multiplied after 41 and 61 epochs. Figure 5 sho ws that F A B O L A S found configurations with reasonable performance roughly 10 times f aster than ES and MTBO. Note that due to limited computational capacities, we were unable to run Hyperband on this benchmark: a sin- gle iteration took longer than a day , making it prohibitiv ely expensi ve. (Also note that by that time all other methods had already found good hyperparameter settings.) W e want to emphasize that the runtime could be improv ed by adapting Hyperband’ s parameters to the benchmark, but we decided to keep all methods’ parameters fixed throughout the e xperi- ments to also show their rob ustness. 5 Conclusion W e presented F A B O L A S , a new Bayesian optimization method based on entropy search that mimics human ex- perts in ev aluating algorithms on subsets of the data to quickly gather information about good hyperparameter set- tings. F A B O L A S extends the standard way of modelling the objective function by treating the dataset size as an additional continuous input v ariable. This allows the incor - poration of strong prior information. It models the time it takes to e valuate a configuration and aims to ev aluate points that yield—per time spent—the most information about the globally best hyperparameters for the full dataset. In vari- ous hyperparameter optimization experiments using support vector machines and deep neural networks, F A B O L A S of- ten found good configurations 10 to 100 times faster than the related approach of Multi-T ask Bayesian optimization, Hyperband and standard Bayesian optimization. Our open- source code is a vailable at https://github .com/automl/RoBO, along with scripts for reproducing our experiments. In future work, we plan to expand our algorithm to model other en vironmental variables, such as the resolution size of images, the number of classes, and the number of epochs, and we expect this to yield additional speedups. Since our method reduces the cost of indi vidual function e valuations but requires more of these cheaper ev aluations, we expect the cubic complexity of Gaussian processes to become the limiting factor in many practical applications. W e therefore plan to extend this work to other model classes, such as Bayesian neural networks (Neal, 1996; Hernández-Lobato and Adams, 2015; Blundell et al., 2015; Springenberg et al., 2016; Klein et al., 2017), which may lower the computa- tional ov erhead while having similar predicti ve quality . References G. Montav on, G. Orr, and K.-R. Müller , editors. Neural Networks: T ric ks of the T rade - Second Edition . LNCS. Springer , 2012. J. Bergstra, R. Bardenet, Y . Bengio, and B. Kégl. Algorithms for hyper-parameter optimization. In Proc. of NIPS’11 , 2011. F . Hutter , H. Hoos, and K. Leyton-Bro wn. Sequential model-based optimization for general algorithm configuration. In Proc. of LION’11 , 2011. J. Bergstra and Y . Bengio. Random search for hyper -parameter optimization. JMLR , 2012. J. Snoek, H. Larochelle, and R. P . Adams. Practical Bayesian opti- mization of machine learning algorithms. In Pr oc. of NIPS’12 , 2012. R. Bardenet, M. Brendel, B. Kégl, and M. Sebag. Collaborativ e hyperparameter tuning. In Pr oc. of ICML’13 , 2013. J. Bergstra, D. Y amins, and D. Cox. Making a science of model search: Hyperparameter optimization in hundreds of dimensions for vision architectures. In Pr oc. of ICML’13 , 2013. K. Swersky , J. Snoek, and R. Adams. Multi-task Bayesian opti- mization. In Pr oc. of NIPS’13 , 2013. K. Swersk y , J. Snoek, and R. Adams. Freeze-thaw Bayesian optimization. CoRR , 2014. J. Snoek, K. Swersky , R. Zemel, and R. Adams. Input warping for Aaron Klein, Stefan Falkner , Simon Bartels, Philipp Hennig, Frank Hutter Bayesian optimization of non-stationary functions. In Pr oc. of ICML ’14 . J. Snoek, O. Rippel, K. Swersky , R. Kiros, N. Satish, N. Sundaram, M. M. A. P atwary , Prabhat, and R. P . Adams. Scalable Bayesian optimization using Deep Neural Networks. In Pr oc. of ICML ’15 , 2015. A. Krizhe vsky . Learning multiple layers of features from tiny images. T echnical report, University of T oronto, 2009. T . Domhan, J. T . Springenberg, and F . Hutter . Speeding up auto- matic hyperparameter optimization of deep neural networks by extrapolation of learning curv es. In Proc. of IJCAI’15 , 2015. L. Bottou. Stochastic gradient tricks. In Grégoire Montav on, Genevie ve B. Orr , and Klaus-Robert Müller , editors, Neural Networks, T ricks of the T r ade, Reloaded . Springer, 2012. T . Nickson, M. A Osborne, S. Reece, and S. Roberts. Automated machine learning on big data using stochastic algorithm tuning. CoRR , 2014. T . Krueger , D. Panknin, and M. Braun. Fast cross-v alidation via sequential testing. JMLR , 2015. L. Li, K. Jamieson, G. DeSalvo, A. Rostamizadeh, and A. T al- walkar . Efficient hyperparameter optimization and infinitely many armed bandits. 2016. A. Klein, S. Bartels, S. Falkner , P . Hennig, and F . Hutter . T o- wards ef ficient Bayesian optimization for big data. In Pr oc. of BayesOpt’15 . L. Li, K. Jamieson, G. DeSalvo, A. Rostamizadeh, and A. T al- walkar . Hyperband: Bandit-based configuration e valuation for hyperparameter optimization. In Pr oc. of ICLR’17 , 2017. E. Brochu, V . Cora, and N. de Freitas. A tutorial on Bayesian optimization of expensiv e cost functions, with application to activ e user modeling and hierarchical reinforcement learning. CoRR , 2010. B. Shahriari, K. Swersky , Z. W ang, R. Adams, and N. de Fre- itas. T aking the human out of the loop: A Revie w of Bayesian Optimization. Pr oc. of the IEEE , (1), 12/2015 2016. C. Rasmussen and C. W illiams. Gaussian Pr ocesses for Machine Learning . The MIT Press, 2006. B. Matérn. Spatial v ariation. Meddelanden fran Statens Skogs- forskningsinstitut , 1960. D.J.C. MacKay and R.M. Neal. Automatic rele vance detection for neural networks. T echnical report, University of Cambridge, 1994. J. Mockus, V . T iesis, and A. Zilinskas. The application of Bayesian methods for seeking the extremum. T owards Global Optimiza- tion , (117-129), 1978. N. Sriniv as, A. Krause, S. Kakade, and M. Seeger . Gaussian process optimization in the bandit setting: No regret and experi- mental design. In Pr oc. of ICML’10 , 2010. P . Hennig and C. Schuler . Entropy search for information-efficient global optimization. JMLR , (1), 2012. J. Hernández-Lobato, M. Hoffman, and Z. Ghahramani. Predicti ve entropy search for efficient global optimization of black-box functions. In Pr oc. of NIPS’14 , 2014. B. W illiams, T . Santner , and W . Notz. Sequential design of com- puter e xperiments to minimize integrated response functions. Statistica Sinica , 2000. Y . LeCun, L. Bottou, Y . Bengio, and P . Haffner . Gradient-based learning applied to document recognition. In S. Haykin and B. K osko, editors, Intelligent Signal Pr ocessing . IEEE Press, 2001. D. Foreman-Mackey , D. W . Hogg, D. Lang, and J. Goodman. emcee : The MCMC Hammer. P ASP , 2013. D. R. Jones. A taxonomy of global optimization methods based on response surfaces. JGO , 2001. N. Hansen. The CMA evolution strategy: a comparing revie w . In J.A. Lozano, P . Larranaga, I. Inza, and E. Bengoetx ea, ed- itors, T owards a ne w evolutionary computation. Advances on estimation of distribution algorithms . Springer, 2006. J. V anschoren, J. van Rijn, B. Bischl, and L. T orgo. OpenML: Net- worked science in machine learning. SIGKDD Explor . Newsl. , (2), June 2014. J.P . Siebert. V ehicle Recognition Using Rule Based Methods . Tur - ing Institute, 1987. J A Blackard and D J Dean. Comparative accuracies of artificial neural networks and discriminant analysis in predicting forest cov er types from cartographic v ariables. Comput. Electr on. Agric. , 1999. Y . Netzer, T . W ang, A. Coates, A. Bissacco, B. W u, and A. Y . Ng. Reading digits in natural images with unsupervised feature learning. In NIPS W orkshop on Deep Learning and Unsuper- vised F eatur e Learning 2011 , 2011. S. Ioffe and C. Szegedy . Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Pr o- ceedings of the 32nd International Confer ence on Machine Learning,ICML 2015, Lille, F rance, 6-11 J uly 2015 , 2015. D. P . Kingma and J. Ba. Adam: A method for stochastic optimiza- tion. CoRR , 2014. K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. CoRR , 2015. R. Neal. Bayesian learning for neural networks. PhD thesis, University of T or onto , 1996. J. Hernández-Lobato and R. Adams. Probabilistic backpropagation for scalable learning of Bayesian neural networks. In Proc. of ICML ’15 , 2015. C. Blundell, J. Cornebise, K. Kavukcuoglu, and D. Wierstra. W eight uncertainty in neural networks. In Proc. of ICML’15 , 2015. J. T . Springenberg, A. Klein, S. F alkner , and F . Hutter . Bayesian optimization with robust Bayesian neural networks. In Pr oc. of NIPS’16 , 2016. A. Klein, S. F alkner , J. T . Springenberg, and F . Hutter . Learning curve prediction with Bayesian neural networks. In Pr oc. of ICLR’17 , 2017.
Original Paper
Loading high-quality paper...
Comments & Academic Discussion
Loading comments...
Leave a Comment