RNN의 용량과 학습 가능성: 파라미터와 유닛 별 한계 분석
본 논문은 다양한 RNN 구조가 파라미터당 약 5비트, 유닛당 약 1실수 정도의 저장 용량을 공유한다는 실험적 증거를 제시한다. 아키텍처 간 성능 차이는 주로 학습 난이도 차이에서 비롯되며, 저자는 새로운 두 가지 RNN 변형을 제안해 깊은 네트워크에서도 효율적인 학습을 가능하게 한다.
저자: Jasmine Collins, Jascha Sohl-Dickstein, David Sussillo
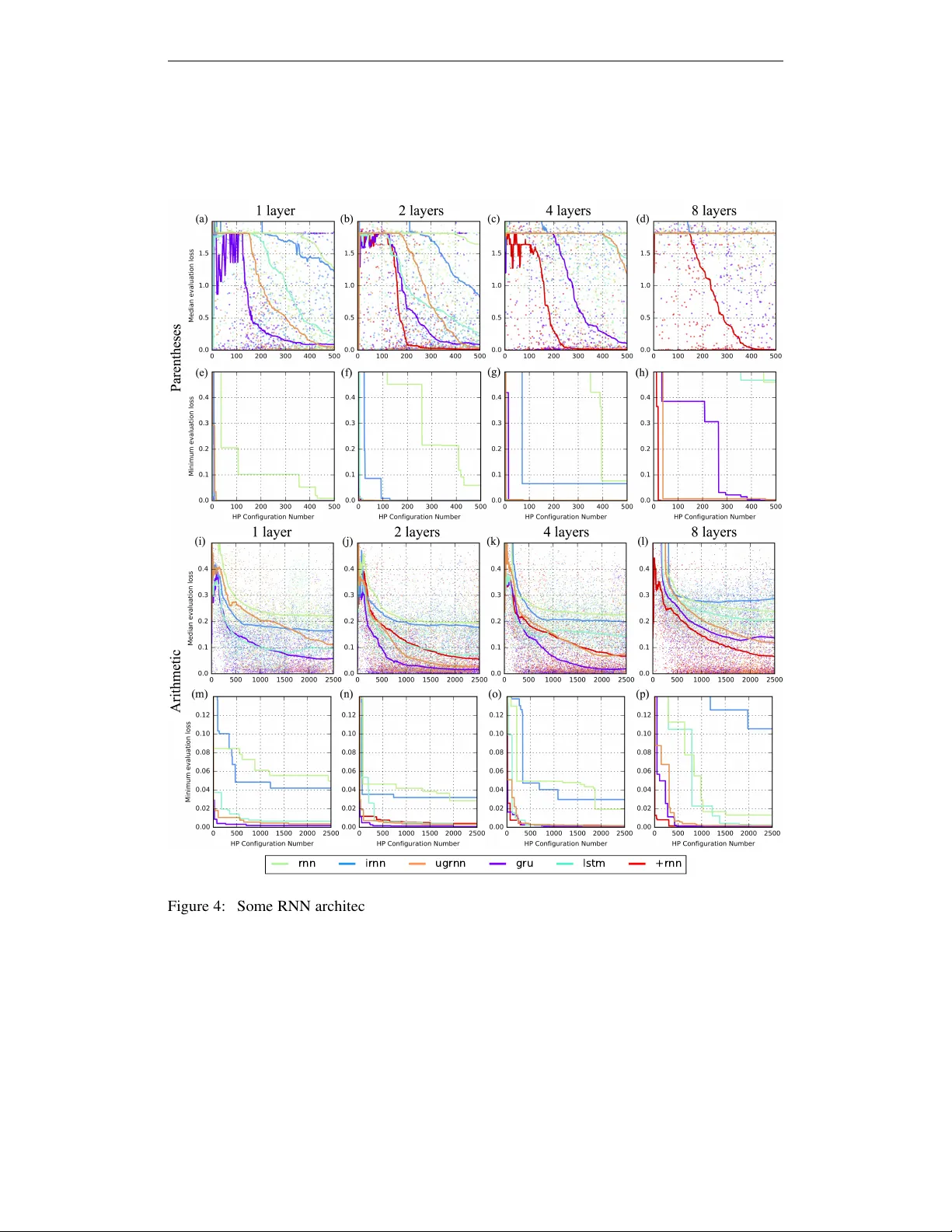
본 논문은 2017년 ICLR에 발표된 “Capacity and Trainability in Recurrent Neural Networks”를 기반으로, 다양한 RNN 아키텍처가 실제로 어느 정도의 정보를 파라미터와 유닛에 저장할 수 있는지를 정량적으로 조사한다. 연구자는 두 가지 주요 용량 제한을 정의한다. 첫 번째는 “파라미터 용량”으로, 이는 네트워크가 학습 과제에 대한 정보를 가중치와 편향에 얼마만큼 저장할 수 있는지를 의미한다. 두 번째는 “유닛 용량”으로, 이는 각 숨김 유닛이 입력 시퀀스의 히스토리를 얼마나 정확히 기억할 수 있는지를 나타낸다.
파라미터 용량을 측정하기 위해, 저자는 무작위 이진 입력‑출력 매핑을 생성하고, RNN이 이를 학습하도록 한다. 학습 과정에서 교차 엔트로피 손실을 최소화하면서, 최종 출력과 실제 레이블 사이의 상호정보량(I(Y;Ŷ))을 계산한다. 이 상호정보량을 파라미터 수로 나누면 “비트 per 파라미터”라는 지표가 얻어지며, 이는 각 파라미터가 평균적으로 몇 비트의 과제 정보를 저장했는지를 나타낸다. 실험 결과, 모든 아키텍처—vanilla RNN, IRNN, GRU, LSTM, UGRNN, +RNN—가 파라미터 수가 증가함에 따라 거의 선형적으로 용량이 증가했고, 3~6비트/파라미터, 평균 약 5비트/파라미터에 수렴했다. 이는 기존 이론적 상한(V C 차원)보다 훨씬 높은 실용적 한계이며, 파라미터 수가 충분히 크면 아키텍처 간 차이가 사라진다는 중요한 통찰을 제공한다.
유닛 용량 측정은 단일 입력 벡터를 일정 시간(예: 10~20 타임스텝) 후에 정확히 복원하도록 훈련시킨다. 결과적으로 각 숨김 유닛은 평균적으로 하나의 실수값을 정확히 기억할 수 있었으며, 이는 “one real number per hidden unit”이라는 직관과 일치한다. 또한, 깊이(1,2,4,8 레이어)와 아키텍처에 관계없이 이 용량은 크게 변하지 않아, 복잡한 시계열 과제에서 메모리 자체가 병목이 되지 않음을 보여준다.
학습 난이도(Trainability) 측면에서는, 동일한 파라미터 예산 하에 각 모델을 광범위한 하이퍼파라미터 탐색(Gaussian Process 기반 튜너)으로 최적화하였다. vanilla RNN은 가장 높은 파라미터 용량을 보였지만, 수렴이 매우 느리고 종종 발산했다. 반면, GRU와 LSTM은 학습이 비교적 안정적이었으며, 특히 깊은 네트워크(8‑layer)에서도 성능 저하가 적었다. 새로 제안된 두 아키텍처는 다음과 같다.
1. **UGRNN (Update Gate RNN)**: 최소한의 게이팅 구조로, 기존 vanilla RNN에 업데이트 게이트만 추가한다. 이 구조는 LSTM/GRU와 비슷한 학습 안정성을 제공하면서도 파라미터 효율성이 높다.
2. **+RNN (Intersection RNN)**: 순환 차원과 깊이 차원 모두에 게이트를 결합한 구조로, 깊은 스택에서도 그래디언트 흐름을 원활하게 유지한다. 실험에서는 8‑layer 이상에서도 손실이 급격히 증가하지 않아, 깊은 모델 설계에 유리함을 확인했다.
학습 난이도 비교 결과, 동일한 파라미터 수에서 LSTM/GRU가 vanilla RNN보다 훨씬 빠르게 최적점에 도달했으며, UGRNN은 LSTM에 근접한 학습 속도를 보였다. +RNN은 특히 깊은 스택에서 LSTM/GRU보다 더 안정적인 학습 곡선을 나타냈다.
이러한 실험을 통해 저자는 다음과 같은 결론을 도출한다. 첫째, 다양한 RNN 아키텍처가 동일한 파라미터 용량(≈5비트/파라미터)과 유닛 용량(≈1실수/유닛)을 공유한다는 점에서, “아키텍처 자체가 갖는 근본적인 용량 차이”는 거의 없다고 본다. 둘째, 실제 성능 차이는 주로 “학습 가능성”에 기인한다. 즉, 최적화 과정에서 그래디언트 소실·폭발, 초기화, 학습률 스케줄링 등과 같은 요인이 아키텍처 선택에 더 큰 영향을 미친다. 셋째, 새로운 게이팅 메커니즘을 도입하기보다는, 기존 구조를 보다 효율적으로 학습시키는 방법(예: 초기 게이트 바이어스 조정, 적절한 하이퍼파라미터 탐색)이 실용적이다.
마지막으로, 파라미터 용량이 5비트/파라미터, 유닛 용량이 1실수/유닛이라는 경험적 법칙을 제시함으로써, 모델 압축, 메모리 제한 임베디드 시스템, 그리고 초소형 RNN 설계 시 용량 한계를 명시적으로 고려할 수 있는 가이드라인을 제공한다. 이는 앞으로 RNN 기반 시스템을 설계하거나 최적화할 때, “용량”과 “학습 가능성”을 별도로 평가하고, 두 요소를 균형 있게 조정하는 전략이 필요함을 시사한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기